
套 合 流 域 流 量 关 系 研 究
——以韩江流域为例
2018-11-29 00:46郭博瀚周买春
中国农村水利水电 2018年11期
郭博瀚,周买春,刘 远
(华南农业大学水利与土木工程学院,广州 510642)
0 引 言
水文模型是对自然界中复杂的水文现象的简化,是水文水资源管理和决策的重要工具。随着计算机技术、地理信息系统(GIS)和遥感技术(RS)、水文学理论的发展,水文模型的发展也日渐成熟。水文模型经历了从系统模型、概念性模型到物理模型,从集总式模型、半分布式模型到分布式模型的演变。
水文模拟中通常以有水文观测的河流断面作为出口划分子流域,子流域与子流域之间是一种并行和套合的关系,通过河流水系进行水力联系,相互套合的流域,上游来水会贡献给下游的径流,且随着流域的相互套合,流域面积逐渐增大。一些学者研究发现流域面积和流域内的降水量对水文模拟效果会产生重要的影响[1,2]。目前对水文模拟的研究主要集中在子流域下垫面特征[3,4]、模型产汇流机制和结构[5,6]、空间和时间尺度的划分[2、7]、模型评价方法的比较[8]等方面,对于套合流域流量关系的研究很少。本文以SWAT模型为基础,韩江流域为研究对象,分析套合流域之间流量的关系,建立套合流域流量关系模型,为由大流域日径流量推求无资料小流域日径流量提供参考。
1 SWAT模型介绍
SWAT模型是由美国农业部Jeff Arnold博士开发的用于预测土壤类型、土地利用方式和管理措施条件下,土地管理对水分、泥沙和化学物质的长期影响,是一个以日为时间步长、基于GIS基础之上、具有较强物理机制的分布式水文模型。模型利用栅格DEM提取流域河网,根据河网水系将整个研究流域划分成若干个子流域,再按照土地利用、土壤面积和坡度阈值划分不同水文响应单元(Hydrologic Response Units, HRU),在水文响应单元上根据水量平衡原理进行水文模拟,最后进行汇流演算。模型提供了SCS径流曲线数法[9]和Green-Ampt入渗[10]方法来推求地面径流,潜在蒸散发计算方面有Penman-Montieth[11]法、Priestley-Taylor[12]法、Hargreaves[13]法可供选择,也可以在模型外部通过其他方法计算潜在蒸散发再导入模型中,河道汇流演算有特征河长法和马斯京根法[14]两种方法可选择。
2 研究区域概况与数据输入
2.1 研究区概况
韩江流域(115°13′~117°09′E,23°17′~26°05′N)位于粤东、闽西南,地跨广东、福建、江西三个省,是广东省除珠江流域外的第二大流域,发源于广东省紫金县七星岽的梅江,与发源于福建省宁化县武夷山的汀江在大浦三河坝汇合后始称韩江。汀江、梅江和韩江干流分别长470、285和307 km,流域总集雨面积为30 112 km2。韩江流域高程在20~1 500 m之间,主要地形有山地、丘陵、平原,面积分别占总面积的70%、 25%和5%。韩江流域属亚热带季风气候区,夏季高温多雨,冬季温和少雨,多年平均降雨量约为1 600 mm,4-6月为前汛期,以锋面雨为主,前汛期降雨量占全年降雨量的80%,7-9月为后汛期,以热带气旋雨为主。流域多年平均径流系数为0.51,年径流总量达245 亿m3[15]。
选取韩江流域内观音桥、杨家坊、上杭、溪口、宝坑、河口、水口、横山、潮安9个水文站和193个雨量站,以及4个蒸发站的数据,以这9个水文站为控制点分别提取子流域作为研究区。观音桥、杨家坊、上杭、溪口位于汀江流域,宝坑、河口、水口、横山分布在梅江流域,潮安水文站位于韩江干流。韩江流域的区域位置以及流域内水文站点、雨量站点、蒸发站点和子流域分块详见图1。

图1 韩江流域位置、水文站、蒸发站及雨量站分布Fig.1 Distribution of location, hydrological stations, evaporation stations and rainfall stations of Hanjiang River Basin
2.2 数据输入
DEM数据采用SRTM DEM[16],其原始分辨率为90 m。土地覆被数据来自USGS的IGBP(International Geosphere Biosphere Programme at United States Geological Survey),数据年份为1992年4月-1993年3月,分辨率为1 km。通过对图像的截取分析,确定韩江流域内有11种土地利用类型,以林地为主,其次是作物地和草地,土地利用类型分布详见图2。
土壤分类采用联合国粮农组织FAO提供的全球数字土壤数据,分辨率为1 km,再应用土壤三角形坐标转换成USDA土壤类型,转换后土壤类型包括:黏土、黏壤土和砂质黏壤土,具体分布如图3所示。
模型运行需要的气象资料包括降水、径流、气温、湿度、太阳辐射和风速等。降水数据采用1981-1988年韩江流域193个雨量站的实测降雨数据,径流数据采用流域内同年9个水文站的实测径流数据,数据来自广东省水文年鉴。由于韩江流域80到90年代地类数据变化很小,所以选取的降雨和实测径流量与下垫面数据能相互匹配。日平均气温、风速,日气温变化幅度等数据来自CRU TS2.0数据集,空间分辨率为0.5°×0.5°。
3 SWAT模型模拟与率定
韩江流域SWAT模拟与率定方法步骤如下:
(1)将韩江流域DEM数据输入到SWAT模型中,为了统一河网划分精度,设定统一的集水面积阈值,定义河网,设置流域出口,划分亚流域,完成各相关地形参数的计算。基于植被覆盖和土壤类型数据,设定优势地面覆被、优势土壤和坡度的面积阈值,生成水文响应单元。各个子流域的亚流域、HRU的划分结果如表1,表中亚流域和HRU的个数包含被套合的上一级子流域的个数。

图2 土地利用类型分布Fig.2 Distribution of land use types

图3 土壤类型分布Fig.3 Distribution of soil types
(2)输入气象数据,地表径流的计算采用SCS径流曲线数法,模拟时间步长以日为单位,潜在蒸散发计算采用Shuttleworth-Wallace模型[17]方法,河道汇流演算选用特征河长法[14]。构建韩江流域SWAT模拟模型。

表1 各个子流域的亚流域和HRU的划分Tab.1 Subbasin and HRU division of each basin
(3)以1981-1984年为模型率定期,1985-1988年为验证期,以选取的9个水文站逐日实测径流量作为径流数据进行参数率定。SWAT模型中参数较多,利用SWAT-CUP(SWAT Calibration and Uncertainty Program)中基于拉丁超立方采样(Latin Hypercube Sampling)多元回归敏感性分析选出对模型影响较大的参数进行率定。由于复合形重组(SCE-UA)算法被广泛应用于水文模型的校准,普遍被认为是高效有力的算法[18],所以利用SWAT-CUP程序包中以SCE-UA为核心的Parasol算法进行参数的自动率定。Parasol方法将残差平方和的目标函数结合进全局优化准则,利用复形重组(SCE-UA)使目标函数或全局优化准则最小。率定的运算步骤是:①首先选取p个优化参数,根据参数范围随机抽样选择初始“群”,将这些点分成几个复合型,每个复合型包括2p+1个点;②每个复合型根据单纯形法独立进化,定期洗牌重组形成新的复合型以便共享信息;③根据目标函数检查是否满足收敛要求,如果不满足重新划分种群进行计算。
模型率定以Nash-Sutcliffe效率系数为目标函数,同时以模拟与实测径流总量之比作为评价指标,见式(1)和式(2),SWAT模型在韩江流域的模拟结果评定见表2。
(1)
(2)


表2 SWAT模型在韩江流域的模拟结果评定Tab.2 Evaluation of the simulation results of the SWAT model in Hanjiang River Basin
率定期和验证期模拟结果NS系数均大于50%,且模拟与实测径流总量比Vol的误差在±20%以内,模拟结果可以接受[19]。在上游集水面积较小的子流域,NS系数较低,Vol的误差较大,下游集雨面积较大的子流域NS系数较高,Vol误差较小。这是由于在小流域水文的非线性较突出,随着流域面积增大,汇流过程趋于均匀非线性或线性化,SWAT模型的降雨产流关系存在线性比例关系[20],所以在非线性较强烈的小流域模拟效果偏差,在非线性较弱的流域模拟效果较好。
4 套合流域流量模型与验证
4.1 韩江流域套合关系
以选取的水文站点为出口,将韩江流域划分为9个子流域,见图1,子流域与子流域之间存在并行和套合关系,如果一个子流域为源头流域,即子流域不套合其他子流域则成为一级子流域,如观音桥、杨家坊、河口、宝坑。当一个子流域套合一级子流域时,即为二级子流域,如上杭、水口,以此类推。韩江流域9个子流域的套合关系见图4。

图4 子流域之间的套合关系Fig.4 The nested relationship between sub-basins
4.2 套合流域流量模型
以1981-1984年为模拟时间,选取上杭流域为研究对象。分别选取流域中主河段上的7个点,输出其径流量,其中G2、Y2、S3分别为观音桥、杨家坊、上杭流域的总出口,即水文站的位置,各个出水点位置详见图5。各个出水点的集雨面积、多年平均降雨量和SWAT模拟的日均径流量详见表3。

表3 上杭流域各出水点的集雨面积和日均径流量表Tab.3 Rainfall collection area and daily mean runoff for each outlet in Shanghang Basin

图5 上杭流域各出水点位置分布Fig.5 Distribution of outlets in Shanghang Basin
相互套合的出水口流量随着集雨面积的增大而增加,集雨面积与SWAT模拟日均径流量呈正比的线性关系,线性相关系数R2=0.999,各个出水口的集雨面积与SWAT模拟日均径流量关系见图6。
套合流域与被套合流域的日均径流量与集雨面积可拟合成一条直线,即流域的日均径流量与流域集雨面积之间存在一定的线性相关性。单纯用面积比推求套合流域的径流量,发现在年均降水量差别不大的区域,计算结果较好,在年均降水量差别较大的区域,计算结果较差。研究表明流域降雨量与径流深呈线性相关[2],因此,引入一个降雨量权重,用套合流域与被套合流域的面积比和年均降雨量比的乘积,作为衡量套合流域流量关系的一个系数,建立套合流域流量模型。
Qi=Qi-1ti
(3)
(4)
式中:Qi表示套合流域的日径流量,m3/s;Qi-1表示被套合流域的日径流量,m3/s;ti表示流域套合系数;Ai表示套合流域的集雨面积,km2;Ai-1表示被套合流域的集雨面积,km2;Pi表示套合流域的年均降雨量,mm;Pi-1表示被套合流域的年均降雨量,mm。
将上杭流域所选的7个研究点中,套合与被套合研究点之间的日径流过程做线性拟合,以S1和S3两个出口点为例做的线性拟合见图7,计算出拟合直线的斜率k,列于表4。上杭流域分为两条主要支流,西支流源于观音桥流域(分布点G1、G2、S1),东支流源于杨家坊流域(分布点Y1、Y2、S2)。源于观音桥流域的西支流其径流量线性拟合的相关系数R2比东支流低,只有0.7左右,这是由于西支流河网为树枝状[21],G1位于G2流域的一条支流上,G2位于S1流域的一条支流上,由于受其他同级支流流量的影响,套合与被套合流域流量的线性关系较弱,因此其直线拟合斜率k与t值误差较大。东支流河网呈树叶状,支流少,Y1位于Y2流域的干流上,Y2位于S2流域的干流上,径流量直线拟合相关性较高,因此直线拟合斜率k与t值误差较小。

图6 日均径流量与集雨面积的关系图Fig.6 Relationship between daily average runoff and rainfall collection area
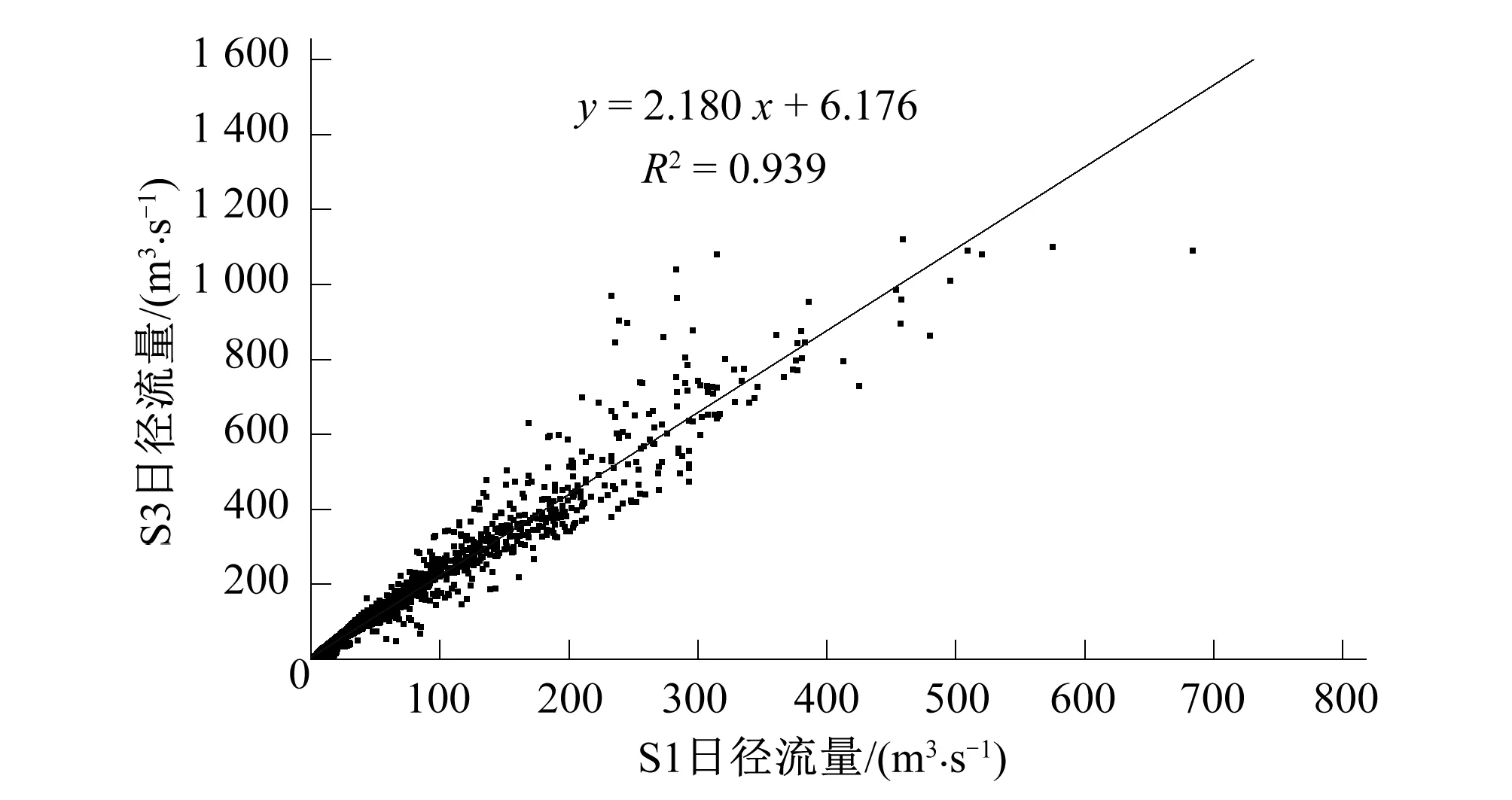
图7 点S1和S3日径流量关系Fig.7 Daily runoff between S1 and S3

表4 上杭流域7个研究点的流量线性拟合关系表Tab.4 Linear fitting relationship of flow in 7 research spots in Shanghang Basin

4.3 模型验算
以韩江流域9个水文站的日径流量对套合流域流量模型(公式3)进行验算,应用套合流域流量模型,分别使用SWAT模拟数据和水文站实测径流数据,推算被套合流域水文站的流量,并与该点的SWAT模拟值和水文站实测值做评定,评定方法采用NS效率系数(公式1)和Vol值(公式2),模拟时间为1981-1984年,流域套合模拟结果见表5和表6。选取汀江流域的溪口-上杭和梅江流域的横山-水口模拟流量过程线绘于图8和图9。
4.4 结果分析
(1)河网形状影响。根据斯特拉勒(Strahler)河流分级法划分河道等级,9个水文站所处河道等级见图10。
对于汀江流域,上杭站位于溪口流域的主干流上,属于同一级河流,溪口-上杭流域套合模拟的NS系数最高,分别为88.4%和91.6%,Vol值为100.1%和97.5%。上杭流域分为东支流和西支流,根据斯特拉勒(Strahler)河流分级法,东支流和西支流均为3级河流,东支流河网为树叶状,杨家坊位于东支流的主干流上,上杭-杨家坊流域套合模拟的NS系数为86.7%和79.3%,Vol值为100.0%和104.6%。西支流河网为树枝状,观音桥位于西支流,且为西支流上的一个2级支流,流域套合模拟流量受其他同级支流流量的影响,NS系数不到70%,模拟效果偏差。
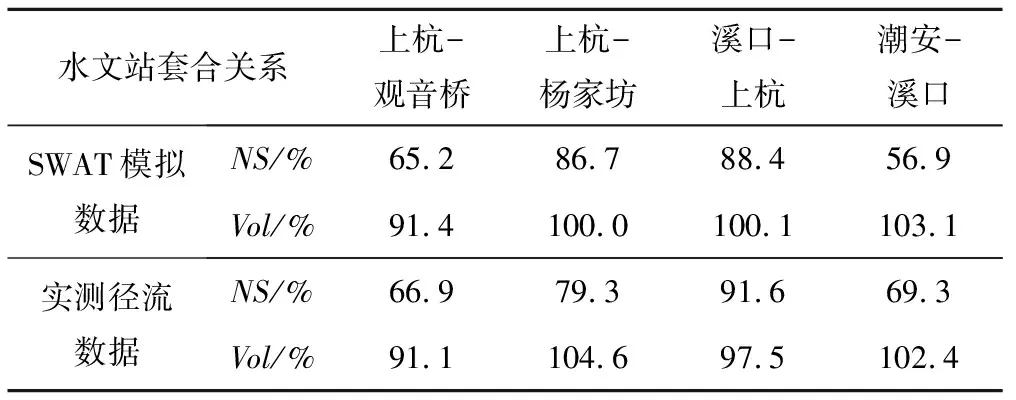
表5 汀江流域的套合模拟结果评定表Tab.5 Evaluation of nested simulation results in the Tingjiang River Basin
注:上杭-观音桥表示由上杭水文站推求被套合观音桥水文站的径流量,其他水文站套合关系同上。

表6 梅江流域的套合模拟结果评定表

图8 溪口-上杭模拟流量过程线Fig.8 Simulated flow process line between Xikou and Shanghang Basin
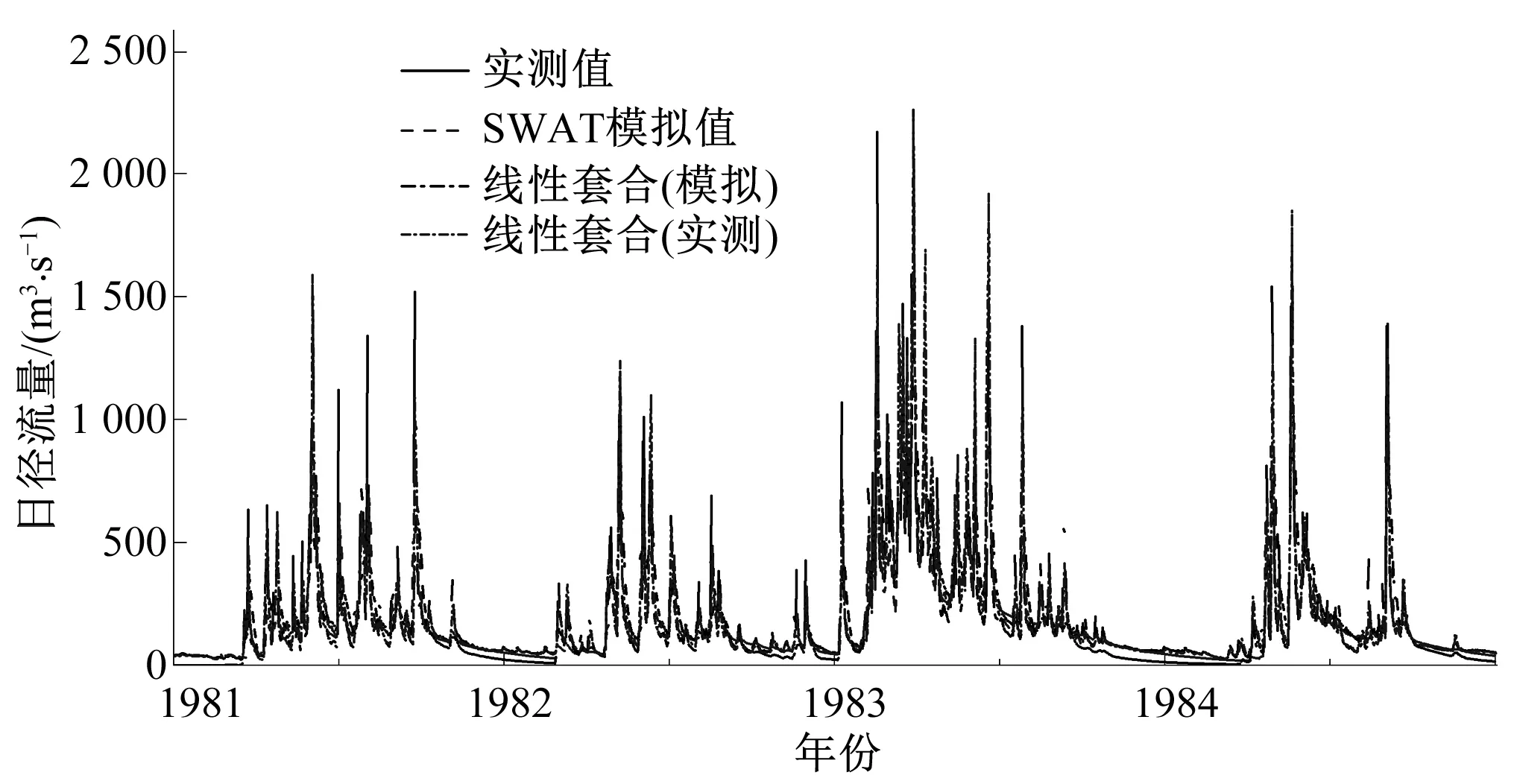
图9 横山-水口模拟流量过程线Fig.9 Simulated flow process line between Hengshan and Shuikou Basin
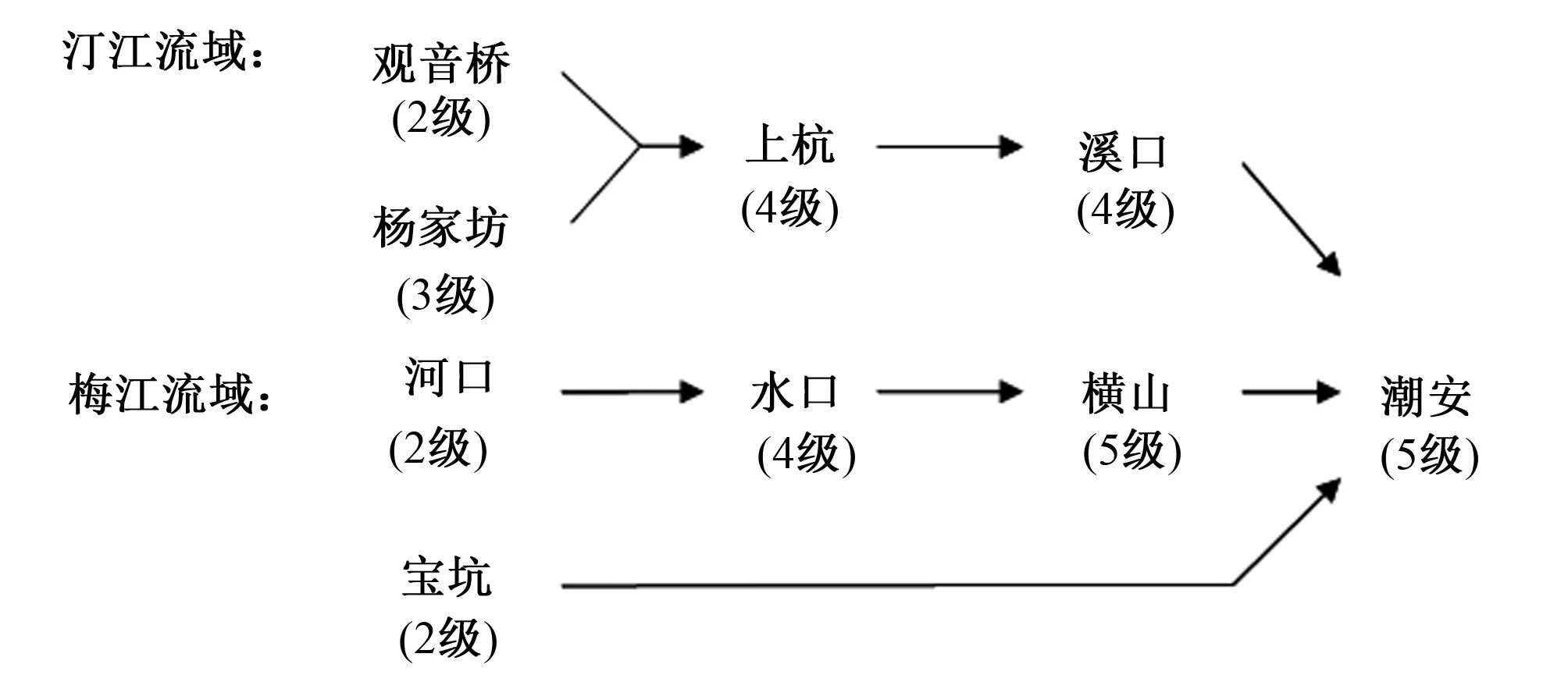
图10 各个水文站点所在河道的等级Fig.10 The series of rivers where each hydrological station is located
梅江流域上,横山流域分为两条4级支流,水口水文站位于其中一条4级支流的主干流上,横山-水口流域套合模拟的NS系数为80.2%和88.9%,Vol值为103.6%和100.3%,模拟效果较好。水口流域分为两条3级支流和一条2级支流,河口水文站位于2级支流上,水口-河口的流域套合模拟NS系数为73.9%和70.6%,Vol值只有93.0%和95.6%。
梅江和汀江在三河坝汇合后汇入韩江干流,潮安水文站位于韩江干流上,横山位于韩江干流的梅江分支上,溪口位于韩江干流的汀江分支上。横山水文站位于韩江5级河流上,与韩江干流属于同一级,即横山位于主干流上,流域套合模拟的NS系数为84.4%和85.5%,Vol值为107.0%和104.4%,溪口水文站位于韩江的4级河流上,属于支流,受其他支流以及干流流量的影响,流域套合模拟的NS系数较低,只有56.9%和69.3%。宝坑水文站位于梅江的小支流上,集雨面积仅437 km2,用潮安水文站推求宝坑的流量,NS系数和Vol值偏低。
套合关系不同模拟精度不同的原因是:该套合流域流量模型是一个线性模型,当被套合流域出水口位于套合流域主干流上时,两个出水口之间流量的非线性较弱,应用套合流域流量模型计算的NS系数较高,当被套合流域出水口位于其他支流上,两个出水口之间流量受到其他同级支流的影响,非线性较强烈,应用该套合流域流量模型计算的NS系数偏低。该套合流域流量模型应用于韩江流域,NS系数均大于50%,模拟与实测径流量的误差均在±10%以内,效果较理想。
(2) 水文模型精度的影响。应用SWAT模拟的日径流量,与用水文站实测日径流模拟的套合流量比较,在一些套合流域模拟的NS系数和Vol值接近,如溪口-上杭、潮安-横山,上杭-观音桥,在一些套合流域模拟的NS系数和Vol值差别较大,如横山-水口、潮安-宝坑、潮安-溪口。这是因为水文系统是一个具有不确定性的时空耦合系统[22,23],参数率定和水文数据输入的不确定性导致了水文流量模拟的不确定性。且天然流域下垫面的复杂性、降水时空变化与径流非恒定流动的特性,都会增加水文模拟的不确定性和非线性[24],这些因素都会影响水文模拟的精度。
5 结 语
通过SWAT模型模拟流量和水文站实测径流量分析相互套合流域之间的流量关系,建立一个套合流域流量模型。该套合流域流量模型应用于韩江流域时,当被套合流域出水口位于套合流域主干流上时,由套合流域流量关系模型计算的流量,NS系数在84.4%~91.6%,Vol值在97.5%~107.0%。当被套合流域出水口位于套合流域干流的上一级支流,且位于该支流的主干上,NS系数在79.3%~88.9%,Vol值在100.0%~104.6%。当被套合流域出水口位于套合流域的其他支流上,NS系数在53.3%~73.9%,Vol值在89.6%~105.2%。该套合流域流量模型应用于韩江流域,当被套合流域出水口位于套合流域主干流上,或者被套合流域出水口位于套合流域干流的上一级支流,且位于该支流的主干上这两种情况下,模型模拟的效果较好。
水文模型模拟中参数率定和水文数据输入的不确定性,以及天然流域下垫面的复杂性、降水时空变化与径流非恒定流动的特性,都会影响水文模型的模拟精度。所以用SWAT模型模拟的流量数据,与用水文站实测流量数据做套合流域的流量模拟,其NS系数和Vol值不尽相同,但差别都在可接受范围内。
套合流域流量模型,可为由大流域推求被套合的无资料小流域流量提供参考,同时,对于套合流域流量模型,还需要再结合河网形状类型,如树枝状、树叶状、羽毛状等的分类做进一步的研究。
□
猜你喜欢
农业灾害研究(2022年2期)2022-05-31
陕西水利(2022年4期)2022-05-15
陕西水利(2021年8期)2021-09-15
黑龙江水利科技(2020年8期)2021-01-21
山西水利(2020年6期)2020-11-22
海洋通报(2020年3期)2020-10-20
中华建设(2020年5期)2020-07-24
黑龙江水利科技(2020年2期)2020-05-07
科学与财富(2018年13期)2018-06-13
安徽农学通报(2017年24期)2018-01-12
