
中文分词交叉型歧义消解算法
2018-11-24 02:33甘蓉
西华大学学报(自然科学版) 2018年6期
甘 蓉
(陕西工业职业技术学院汽车工程学院, 陕西 咸阳 712000)
中文分词是自然语言处理的基础和关键[1]。中文分词已经有很多成熟的算法,但是歧义识别和未登录词识别仍是中文分词的2大难点。其中,歧义识别又分为交叉型歧义和组合型歧义[2]。对于歧义,许多研究者做了大量的工作。目前常用的歧义消解算法主要分为2种:规则型歧义消解算法和概率型歧义消解算法。规则型歧义消解算法主要采用语义、语法、词性等规则对歧义字段进行消歧。概率型歧义消解算法通常需要统计上下文信息[3](例如使用互信息、N元统计模型、t-测试原理、HMM模型、字标注统计等方法或模型[4]统计上下文信息)从而进行歧义消解。文献[4]提出了一种基于词频的中文分词歧义消解方法,该方法主要适用于没有上下文的歧义消解。文献[5]提出了一种针对交叉型歧义无监督的学习方法,并比较了卡方统计量、t-测试差在歧义处理中的效果。文献[6]提出了针对组合型歧义的消解方法,该方法考虑了词搭配的支持度,依据支持度度量因子进行歧义消解。文献[7]利用训练语料中歧义字段的上下文信息建立了规则库,然后利用统计方法C-SVM模型进行歧义消解。
本文提出了一种基于正向[8]、负向[9]最大匹配算法和passive aggressive(PA)算法[10-11]结合的交叉型歧义消解算法。该方法有3个优点:1)由于正向、负向最大匹配算法是基于字符串匹配的,所以速度快;2)PA算法能灵活添加任意特征模板,使得分词训练和解码都能尽可能获得多的信息;3)PA算法是一种在线学习算法[12],可以增量学习[13]分词模型,以利于自适应领域分词研究。
1 相关术语
1.1 歧义识别
歧义是指对于同一句话,可能有2种或者2种以上不同的切分方法[14]。例如句子“已结婚的和尚未结婚的青年都要实行计划生育”可能被切分成“已/结婚/的/和/尚未/结婚/的/青年”或者“已/结婚/的/和尚/未/结婚/的/青年”,计算机到底应该怎么选择最佳的符合人类逻辑的切分结果呢?这就是所谓的分词歧义问题。
歧义主要分为2种类型:交集型歧义和组合型歧义。假设汉字串AXB由汉字串A、X、B组成,同时AX和XB也分别能组成词语,则称汉字串AXB为交集型歧义字段。例如,句子“南京市长江大桥”可以切分为“南京市/长江大桥”和“南京/市长/江大桥”,其中,“南京市长江大桥”为交集型歧义字段。假设汉字串AB由汉字串A、B组成,同时A、B、AB都能组成词语,则称汉字串AB为组合型歧义字段。例如,句子“中华人民共和国”可以切分为“中华/人民/共/和/国”和“中华/人民/共和国”两种,其中,“共和国”为组合型歧义字段。
1.2 正向、负向最大匹配算法
在中文分词算法中,最大匹配算法[15]是一种基于字符串匹配的分词方法,即按照一定的策略将自然语言中的汉字串与词典中的词条进行匹配,如果在词典中找到这个字符串,则匹配成功,即分出了一个词,如果没有找到这个字符串,则按照一定的策略继续匹配。按照字符串匹配的方向,最大匹配算法可以细分为正向最大匹配法和负向最大匹配法。
正向最大匹配法:从左到右将待分词文本中的几个连续字符与词表匹配,如果匹配上,则切分出一个词,但要做到最大匹配,并不是第一次匹配到就可以切分的,最大匹配出的词必须保证下一个扫描不是词表中的词或词的前缀才可以结束。
负向最大匹配算法:从右往左将待分词文本中的几个连续字符与词表匹配。切分方向与正向最大匹配算法相反,但切分规则相同。
1.3 PA算法及基于PA算法的分词
PA算法可看作对平均感知器[10]的改进。平均感知器算法虽然最后收敛到一个线性分类面,但这个线性分类面到底有多好,却没有评判标准。在平均感知器中,每次调整参数总是移动一个固定步长,通常是1,在该算法中,移动的步长需要通过一个优化准则确定,即在满足调整后参数能产生正确预测的前提下,相对于调整前的参数w′做出最小调整:
s.t.ξ+wTΦ(x,y′)≥wTΦ(x,y)+l(y′,y),ξ≥0。
PA算法将分词任务建模为基于字的序列标注问题。对于输入句子的字序列,模型给句子中的每个字标注一个标识词边界的标记,采用的标记集如表1所示。

表1 标记集
以“我爱自然语言处理”为例,标注结果如表2所示。

表2 分词序列标注示例
对于分词模型,使用3种特征:基本模型特征、字符叠字特征、基于字的词典特征,如表3—5所示。在表3中,ch[0]表示当前字,ch[-1]表示当前字的前1个位置上的字,ch[-2]表示当前字的前2个位置上的字,ch[1]表示当前字后1个位置上的字,ch[2]表示当前字后2个位置上的字,故ch[-2]-ch[-1]表示的是当前字前2个位置上的字和前1个位置上的字的组合,ch[-1]-ch[0]表示当前字与前1个位置上的字的组合,ch[0]-ch[1]表示当前字与后1个位置上的字的组合,ch[1]-ch[2]表示当前字的后1个位置上的字和后2个位置上的字的组合。表4中ch[-1]=ch[0]?表示判断当前字与前1个位置上的字是否相同,ch[-2]=ch[0]?表示判断当前字与前2个位置上的字是否相同。当相同时,给出一个标记,例如名词形式的“T”;不同时,给出一个能区别于相同情况的标记,例如“F”。表5描述了基于字的词典特征,即这个字的位置在词语的开始、中间还是结尾,也就是说,这个字是词语的词首、词中还是词尾。

表3 基本特征模板
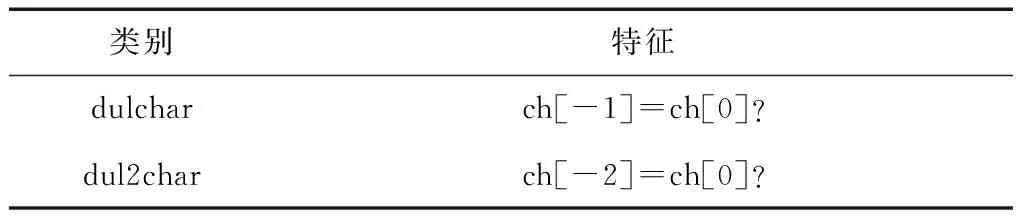
表4 字符叠字特征

表5 基于字词典特征
2 基于正向、负向最大匹配算法和PA算法结合的交叉型歧义消解方法
图1描述了基于正向、负向最大匹配算法和PA算法结合进行交叉型歧义消解的流程。由图1可看出,基于正向、负向最大匹配算法和PA算法结合进行交叉型歧义消解方法的主要步骤如下:1)基于PA算法在训练语料上训练分词模型; 2)基于正向最大匹配算法和负向最大匹配算法检测出存在交叉型歧义的部分; 3)把存在交叉型歧义的部分传递给分词模型,进行解码; 4)拼接基于正向、负向最大匹配算法分词结果中无歧义部分和解码结果,合成最终的分词结果。
2.1 基于PA算法训练分词模型
基于PA算法训练分词模型的整体流程主要包括以下步骤。
第1步,建立内部词典,把训练语料中的每个词按词频降序排序,从前到后依次添加到词典中,词典中的词只包括2字及以上的词,并且这些词的词频和小于等于总词频的90%。

图1 基于正向、负向最大匹配算法和PA算法 结合进行交叉型歧义消解的流程图
第2步,根据内部词典,利用正向最大匹配法给每个字加词典特征(词首?词中?词尾?),其中匹配的最大长度为5。
第3步,按照特征模板建立特征空间feature_space。
第4步,迭代学习,每轮对每个句子执行:
1)按照特征模板抽取特征,句子中每个字均有N个特征(N为模板个数),从特征空间中获取每个特征的索引idx;
2)根据_W[标签数*标签数+标签数*特征总数]计算发射概率矩阵和转移概率矩阵,其中,W初始化为0;
3)解码,得到预测的标签序列predict_tags;
4)收集特征,将正确的标签序列correct_features 和预测的标签序列predict_features分别转化成2个特征向量,即根据每个特征的索引idx给对应的vec[idx]加1,其中,vec[idx]初始化为0;
5)整合特征,把correct_features 和predict_features对应的向量整合到update_features中,即correct_features乘1,ctx.predict_features乘 (-1),然后相加;
6)利用PA算法学习新参数W, 更新方法为
idx=update_features.idx
elapsed=now-time[idx]
upd=scale*update_features.value
cur_val=W[idx]
W[idx]=cur_val+upd
sum[idx] += elapsed*cur_val+upd
time[idx]=now
其中,“*”表示乘法运算,update_features.idx表示待更新特征的索引idx, update_features.value表示整合特征后特征idx对应的值,now表示当前迭代的次数,time记录每个特征更新的次数,scale是更新的步长,在1.3节中给出了定义,sum记录每个特征所有更新的权重之和,W记录每个特征的权重。
2.2 交叉型歧义检测
正向、负向最大匹配算法分词都是根据词典进行切分,故正向和负向最大匹配算法切分出来的词一定是词典中的词;因此,本文认为正向和负向最大匹配算法分词结果一致的部分为正确切分结果,不一致的地方即产生歧义的位置。
2.3 解码
解码的整体流程主要包括以下步骤:
第1步,读取基于PA算法已经训练好的分词模型;
第2步,读取测试语料;
第3步,基于正向、负向最大匹配算法进行歧义检测;
第4步,根据训练阶段的模板抽取歧义部分的特征;
第5步,基于Viterbi算法[16]进行解码。Viterbi算法是一个成熟且有大量资料的算法,故此处不再赘述。
由于PA算法是考虑上下文特征的,因此检测出歧义部分后,把歧义部分及歧义的上下文传递给PA算法训练出来的分词模型进行解码。
2.4 合成分词结果
合成分词结果是指把基于正向、负向最大匹配算法切分结果和解码结果进行拼接生成最终分词结果。拼接的方法是把歧义部分的解码结果和正向、负向最大匹配算法切分一致部分进行拼接,形成最后的分词结果。
3 实验
实验包括3部分: 1)实验数据; 2)评测标准; 3)实验结果及分析。
3.1 实验数据
实验数据分为训练语料和测试语料,其中,训练语料为2014年2—12月份人民日报数据,共86 M,测试语料为2014年1月份人民日报数据,共8 M。
3.2 评测标准
本文选用的评测指标为准确率(P)、召回率(R)和综合评价指标F-score值。具体定义为:
3.3 实验及分析
图2描述了基于正向、负向最大匹配算法和PA算法结合进行交叉型歧义消解的实验流程。
第1步,基于训练语料和PA算法训练出分词模型。
第2步,基于正、负向最大匹配算法对测试语料进行分词,检测出测试语料中的歧义部分和无歧义部分。
第3步,基于分词模型对第2步中的歧义部分进行分词,得到分词结果。
第4步,将第3步的分词结果和无歧义部分组合形成最终分词结果。
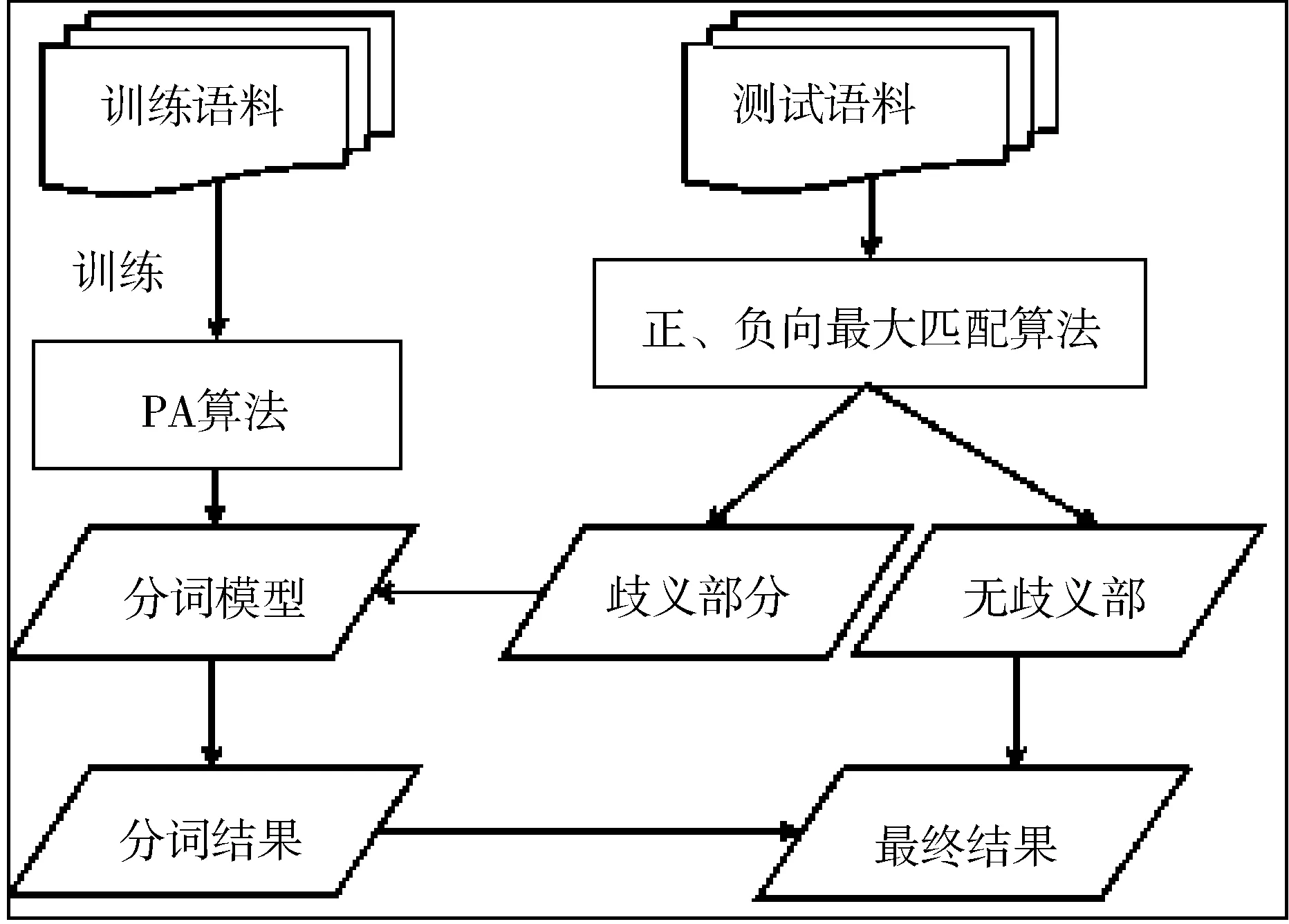
图2 基于正向、负向最大匹配算法和PA算法 结合进行交叉型歧义消解的实验流程
为验证本文提出的算法性能,进行了4种实验:第1种,基于正向最大匹配算法分词;第2种,基于负向最大匹配算法分词;第3种,基于PA算法分词;第4种,基于正向、负向最大匹配算法与PA算法结合分词。分别统计这4种分词结果中交叉型歧义的准确率、召回率和F-score值,结果如表6所示。
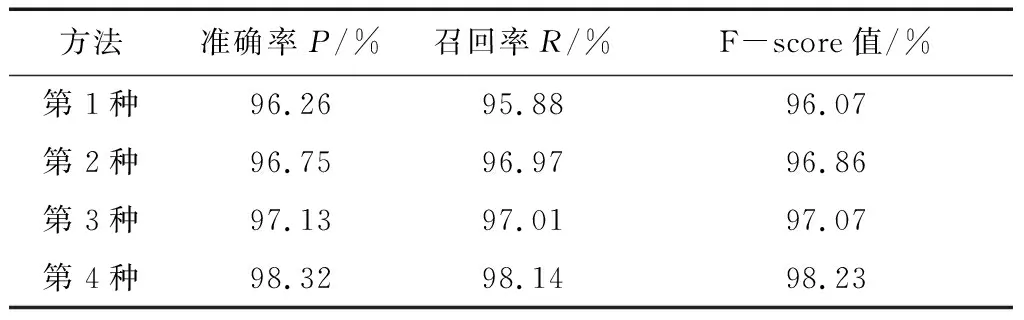
表6 交叉型歧义结果统计
从分词算法大类上讲,第1种和第2种分词方法属于基于字符串匹配的分词方法,第3种属于基于统计的分词方法,第4种是基于字符串匹配和统计结合的分词方法。从表6可以看出,相较于前3种方法,第4种方法的结果是最优的。其原因可以从分词方法的特点解释:基于字符串匹配的分词方法的优点是对于没有歧义的语句分词准确性高,缺点是没有歧义识别能力;基于统计的分词方法优点是有歧义识别能力,缺点是准确率不高;第4种方法结合基于字符串匹配和统计方法,既发挥了基于字符串匹配分词方法对于没有歧义的语句分词准确性高的优点,又利用了基于统计方法有歧义识别能力的特点。
从表6可以看出:第4种方法相比于第1种方法,准确率P、召回率R和F-score值分别提高了2.06%、2.26%和2.16%;第4种方法相比于第2种方法,准确率P、召回率R和F-score值分别提高了1.57%、1.17%和1.37%;第4种方法相比于第3种方法,准确率P、召回率R和F-score值分别提高了1.19%、1.13%和1.16%。该结果表明,基于正向、负向最大匹配算法与PA算法结合分词能在一定程度上解决交叉型歧义。
4 结论
本文提出一种基于正向、负向最大匹配算法和PA算法结合的交叉型歧义消解算法。该方法有3个优点:处理速度快;能灵活添加任意特征模板,使分词训练和解码都能尽可能多地获得更多的信息;可增量学习分词模型,可用于自适应领域的分词研究。实验证明了该方法在一定程度上解决了交叉型歧义。下一步工作将继续深入研究交叉型歧义的解决方法。另外,针对不同的分词要求,也将研究解决组合型歧义的方法。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
校园英语·月末(2021年13期)2021-03-15
暨南学报(哲学社会科学版)(2020年5期)2020-05-15
中国外汇(2019年19期)2019-11-26
中国外汇(2019年12期)2019-10-10
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
语文教学与研究(综合天地)(2018年10期)2018-12-24
