
基于本体的信息推送技术研究
2018-11-22 02:23沈阳理工大学信息科学与工程学院邹依彤
电子世界 2018年21期
沈阳理工大学信息科学与工程学院 邹依彤
引言:文章主要介绍个性化推送服务中的三个方面:本体、用户兴趣模型的建立和最后的推送机制,从而证明方法的有效性。
1 关于本体的建立
1.1 本体
本体是概念的集合,它的五个要素是概念、规则、属性、关系、实例。
因此,可将本体形式化的表示为:(C,AC,R,AR),其中:C是概念集合,表示的是对象的集合,包括概念的名称以及概念所表示的“事物”,也就是实例。AC表示的是每一个概念所具有的属性的集合。属性包括:名称、解释(定义)、值域、数据类型、举例。如:电影属性包括:电影代码、电影片名、上映时间、电影类型、导演、演员、适用对象。而电影类型的属性又包括:名称、解释、数据类型、实例。R是概念之间关系的集合,主要考虑概念之间的父类、子类、以及上下位等层次关系。类之间的关系一方面定义了类的公理:如:等价类、全不同、不相交等客观关系,另一方面定义了概念之间的相互作用:如:previous、hasPart、isPartof、requires,也可定义概念之间的特殊关系。AR是每个关系的属性集合。
1.2 本体的构件流程
构建领域本体时,流程如下:1)确定构建领域本体的应用范围;2)举出领域内的关键术语、概念;3)查找已有的相关本体进行复用;4)定义类并构建层次结构图;5)定义领域本体的相关规则;6)定义类的属性;7)创建实例;8)利用后续实验对本体的构建进行评价及推理检验,一旦出现问题,就需要对类的层次结构图及领域本体规则重新加以改进。
建立好本体模型之后,当用户想搜索某个主题时,就不仅得到了关于该主题的解释,而是把和该主题相关的内容、以及该主题的例子都推送给了用户,实现数据之间的关联。
2 用户的兴趣模型
主动推送服务的个性化主要体现在针对不同的用户提供最符合用户需求和最感兴趣的服务列表,主动推送的前提是对用户的需求进行语义分析,根据用户的偏好等因素选取并推荐服务,为了对各种类型的网络资源实现个性化的服务推荐,就必须了解用户的个性化需求,这就需要获取、分析用户信息,建立合适的用户兴趣模型。用户兴趣模型是服务推送的前提,是个性化服务的基础,直接涉及到服务的质量。
2.1 用户的兴趣模型的建立步骤
首先进行文档预处理,其目的是抽取特征词并计算各特征词的权重,步骤如下:①词汇分析:删除一些对文档校验无关的词,并处理一些特殊字符,比如数字、连字符以及字母大小写等;②词干提取:即词根化处理(在中文里就是分词过程);③训练文档聚类;④选取特征词。
下面介绍这一过程涉及到的几个重要算法:
步骤②中,传统的分词方法是逆向最大匹配分词法,但是由于该方法只能验证是否匹配成功,而无法对匹配成功的词条进行记录,因此从简单、减少歧义的角度出发,也便于后续工作,分词技术采用改进后的逆向最大匹配分词法,其基本过程为:首先计算出词表中最长的词,将其长度记为n,则循环从句首截取长度为n的字符串,让它去匹配此表中的字符串,如果此表中有候选词匹配成功,则在文档中删除该字符串,并记录下每一个匹配成功的字符串,循环上述步骤,设定循环结束的条件为句子长度为空,循环结束。当在此表中找不到任何一个词条与当前候选字符串匹配时,就将该字符串的首字符删去,用截取后的长度为n-1的字符串去和词表中的词条相比对,若仍匹配失败,则继续在其头部删除一个字符,用长度为n-2的字符串进行匹配,直至匹配成功。例如:若有这样一个句子:我爱北京天安门,假设词表中最长的词有四个字,则n=4,则第一次从句尾抽取长度为4的字符串,显然“京天安门”存在字符串的耦合,因此在词表中未查到该词,匹配失败。则需删除字符串首字符得到“天安门”,在词表中找到该词条,匹配成功,并将其记录下来,以此类推,最后句子被切分为由特征词构成的“我/爱/北京/天安门” 全部切分完毕,生成分词结果。之后将经过分词处理后的特征词,进行权重的计算,从而合理地筛选出有意义的特征词,减少冗余特征词对后续工作造成的干扰。
步骤③中,训练文档的聚类,这一步骤的目的:一是要足够体现目标文档的特征,二是要能将目标文档与其他类文档区分开。因此需要对文档进行特征选择,常用的特征算法主要有:文档频率、信息增益、文本证据权等。其中,应用较广泛、各方面性能较好的是信息增益算法,该算法描述如下:
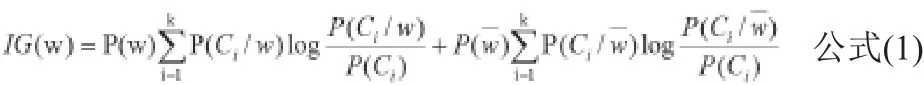
其中,P(w)是指词条w在文档集中出现的概率;P(ci)为第i类文档出现的概率,即此类型的文档数量与全部文档数量之比;P(Ci /w)为词条w与ci类文档共同发生的条件概率。从公式中可看出,虽然考虑某类文档中某些词条不出现的概率,具有其合理性,但它对分类造成的影响远小于文档中词条出现的概率,因此,对该公式加以改进,使其具备更好的合理性。由于本公式的第一项对分类结果是强相关的,因此引入文本证据权参数,文本证据权本身是用来增大P(Ci)和P(Ci/w)之间的差异,但是该参数加到该公式中,作用是增大P(ci/ w)和之间的差异,设定w和类别强相关,使第一项式子值增大,提高其权重,从而增大词条出现的概率对分类造成的影响。改进后的信息增益公式如下:

步骤④:选取特征词过程中,首先要对特征词项进行权重的计算,是指通过考察词条在文档中出现的次数等相关信息,确定其对文本内容的价值,这里采用归一化的TF-IDF权重计算法来求取特征词的权重。该算法的思想是:不同类别的文档中在特征项的出现频率上会有很大差异,因此文本分类时特征词的选择应该重要参考特征项的频率信息,得出这样一个判断:如果某个候选特征词在大多数文档中出现的频率都较高,那么这样的特征词就不如那些只在某些文档中出现的特征项重要。
2.2 访问兴趣度的计算
首先根据用户一次访问中形成的所有特征词的权重,建立访问向量,它是用户一次访问的形式化表示。将其描述为:

其中,Iim表示用户第m次访问的特征词Fi的权重大小,该向量可由文档集矩阵D生成,将文档集矩阵作行映射即得到用户的访问向量对于用户的任意一次访问,用户之前的所有访问历史由用户的前n次访问的访问向量构成。
经上述处理后,得到的矩阵就是降维后的用户访问历史矩阵,为了方便对后续工作的描述,将该矩阵称为初始用户兴趣矩阵。
接下来依据特征词分类规则,采用Rocchio分类器对用户兴趣初始矩阵中的特征词进行分类,其基本思想是使用训练集为每个类构造一个原型向量,给定一个类,训练集中所有属于这个类的特征词对应向量的分量用正数表示,所有不属于这个类的特征词对应向量的分量用负数表示,然后把所有的向量加起来,得到的和向量就是这个类的原型向量,定义两个向量的相似度为这两个向量夹角的余弦,逐一计算训练集中所有特征词和原型向量的相似度。
猜你喜欢
英语世界(2021年13期)2021-01-12
无线互联科技(2020年11期)2020-12-01
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
国家图书馆学刊(2016年2期)2016-10-09
中文信息学报(2015年4期)2015-04-21
燕山大学学报(2014年1期)2014-03-11
测绘科学与工程(2013年6期)2013-03-11
图书馆建设(2012年3期)2012-10-23
对联(2011年20期)2011-09-19
