
融合多元信任机制的协同过滤算法
2018-11-22 12:02:30时念云于镇涛
计算机技术与发展 2018年11期
时念云,于镇涛,马 力
(中国石油大学(华东) 计算机与通信工程学院,山东 青岛 266580)
1 概 述
随着Web技术的发展,网络数据量激增,高效地获取有价值的信息成为人们的迫切需求,因此推荐系统(recommender systems,RS)[1]应运而生。推荐系统的核心在于推荐技术,目前常用的推荐技术有协同过滤推荐(collaborative filtering recommendation)、基于内容的推荐(content-based recommendation)和混合推荐(hybrid recommendation)等[2]。其中,协同过滤推荐技术应用最为广泛[3]。
协同过滤算法的思想是通过用户-项目评分矩阵计算用户(或项目)间相似度发现最近邻,给出合理推荐[4]。协同过滤算法思想简单,容易实现,然而由于评分矩阵的稀疏性,导致算法推荐效果较差。原因是评分矩阵的稀疏性直接影响相似度的计算,进而影响了推荐效果。
为提高推荐效果,很多研究者试图将信任模型融合到协同过滤算法中,以用户间的信任度补充或者替代用户间的相似度。文献[5]将信任机制融合到协同过滤算法中,提出了融合信任和评分的推荐算法(fusing trust and ratings,FTRA);文献[6]将信任引入到基于模型的协同过滤推荐算法中,主要解决了冷启动问题;文献[7]借鉴社会学中信任关系的计算原理对信任进行计算和扩展,并且以信任值代替协同过滤算法中的相似度,明显改善了推荐效果;文献[8]将角色影响力考虑到用户间的信任中构建信任网络,从而基于用户信任网络进行推荐;文献[9]同时将用户人口统计特征和信任机制融合到协同过滤推荐中,提出一种混合推荐技术,解决了冷启动问题,但其由于信任计算来源于用户评分矩阵,对数据稀疏性改善不佳;文献[10]通过声明信任用户来构建信任网络,提出一种结合移动信任用户信任关系与项目特征的推荐算法。上述方法虽然将信任机制融入到协同过滤算法中,一定程度上提高了推荐性能,但缺乏对信任的合理定义与量化,无法对信任矩阵进行有效扩充。
针对上述问题,文中提出一种融合多元信任机制的协同过滤算法(multiple trust -collaborative filtering,MT-CF)。算法中综合考虑了影响信任的因素并将其量化,包括影响力、可靠度和自我取向,建立多元信任机制,利用信任的可传播性对信任进行传递,最终以用户间的信任度取代相似度,为用户进行推荐。
2 融合多元信任机制的协同过滤算法
在推荐系统中,人们更易接受来自信任用户的推荐,并且信任具有可传递性[11]。但由于信任难以量化,尚未形成统一定义[12]。文中在协同过滤算法的基础上,融合多元信任机制,提出融合多元信任机制的协同过滤算法。根据麦肯锡信任公式构建多元信任模型,然后根据信任传播机制对信任进行扩散,最终由信任度替换协同过滤算法中的相似度进行计算推荐。算法步骤如下:(1)构建多元信任模型;(2)信任传播;(3)以信任度代替相似度计算推荐。
2.1 构建多元信任模型
从信息推荐的角度出发,信任的概念不同于网络安全中的信任。GolBeck将信任定义为:如果用户A认定根据用户B的行为采取行动将带来好的结果,则A信任B。一般用信任度来衡量这种可信任程度[13]。
在社会学中,麦肯锡信任公式取得广泛认可。文中根据麦肯锡信任公式,从信息推荐的角度出发,提出多元信任模型。
(1)
其中,DTu,v(DTu,v∈[0,1])表示用户u对用户v的综合信任度;tu,v(tu,v∈[0,1])表示用户u对用户v的基本信任度;Ru,v表示用户v对用户u的可靠程度;Iv表示用户v的影响力;Su表示用户u的自我取向程度。
(1)基本信任度t。
在信任网络中,信任值的表示形式分为二值信任和非二值信任。二值信任即通过信任或不信任表示信任度,Epinions是典型的二值信任网络;非二值信任通过信任等级表示信任度,比如FilmTrust将信任等级划分为1~10个等级。文中主要讨论二值信任网络,需要将二值信任转换成[0,1]之间的信任度。基本信任度tu,v定义如下:
(2)
其中,|tu·|表示被用户u信任的个数。
(2)可靠度R。
可靠度是指信任用户被其他用户信任的可靠程度,通过两个用户间共同评价的项目集合进行量化,公式如下:
(3)
其中,|ru∩rv|表示用户u对用户v共同评价过的项目数量;|ru∪rv|表示用户u对用户v评价过所有项目数量。
(3)影响力I。
影响力指在信任网络中个体对其他用户的影响力。参考文献[14]中对角色影响力的量化方式如下:
(4)
其中,iu表示节点u的入度;imax表示信任网络中节点的最大入度。
(4)自我取向S。
自我取向指用户愿意接受其他用户推荐的程度,自我取向程度越高,越不愿意接受他人建议。通过节点的入度与出度和入度的和之比量化自我取向,公式如下:
(5)
其中,iu表示节点u的入度;ou表示节点u的出度。
(5)综合信任度DT。
综合信任度是指综合考虑用户基本信任度、影响力、可靠度、自我取向等影响因素而计算得到的用户间的信任关系。文中借鉴麦肯锡信任公式定义形式给出如下综合信任度公式:
(6)
2.2 信任传播
利用信任可传递性,能够很好地对信任网络进行扩充。对于信任网络中没有信任关系的用户,可以通过信任的可传递性计算间接信任度PT。在信任网络中,用户u信任用户v,用户v信任用户w,而用户u与用户w之间不存在信任关系,那么可以通过中间信任关系v计算用户u对用户w的间接信任度。提出的间接信任度计算公式如下:
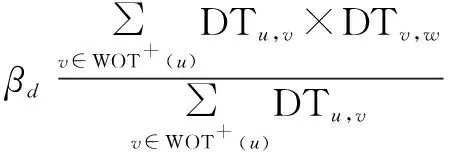
(7)
(8)
其中,PTu,w是用户u对用户w的间接信任度;βd是根据Massa和Avesanit[15]的简易间接信任计算公式提出的信任衰减因子;WOT+(u)表示MoleTrust中用户u的信任名单中信任度超过阈值max的用户群,根据经验,max一般为0.6[16]。
2.3 计算推荐
以信任度替代协同过滤算法中的相似度,选取目标用户最近邻,然后给出预测评分及推荐。
预测评分公式为:
(9)
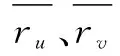
3 实 验
3.1 实验数据与度量标准
实验选取Epinions数据集,包含rating_data和trust_data。其中rating_data数据集包括49 290个users、139 738个items,评分值为1~5的数值,总共为664 825条评分记录,数据系数度为99.99%;trust_data数据集包括49 290个users,共487 184条信任记录,数据系数度为99.98%。
文中利用MAE(mean absolute error)对预测结果进行度量。
3.2 实验及结果分析
实验1:确定信任传播步数dmax及邻居数量N。
信任传播步数dmax及邻居数量N对算法推荐结果有直接影响,实验在Epinions数据集上,dmax选取2、3、4、5、6五个值,N选取10、20、30、40、50、60、70七个值,进行对比实验,结果如图1所示。从图中可以看出,当dmax=5、N=60时MAE最小,即此时算法效果最好。
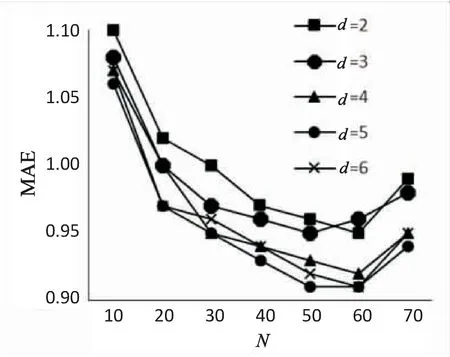
图1 不同dmax与N值时MAE值的变化
实验2:不同算法推荐结果比较。
为验证文中提出的融合多元信任网络的协同过滤推荐算法(MT-CF)的有效性,将其与传统的基于用户的协同过滤算法(User-CF)、基于项目的协同过滤算法(Item-CF)、基于信任的协同过滤算法(T-CF)进行对比实验。五次实验结果如图2所示。
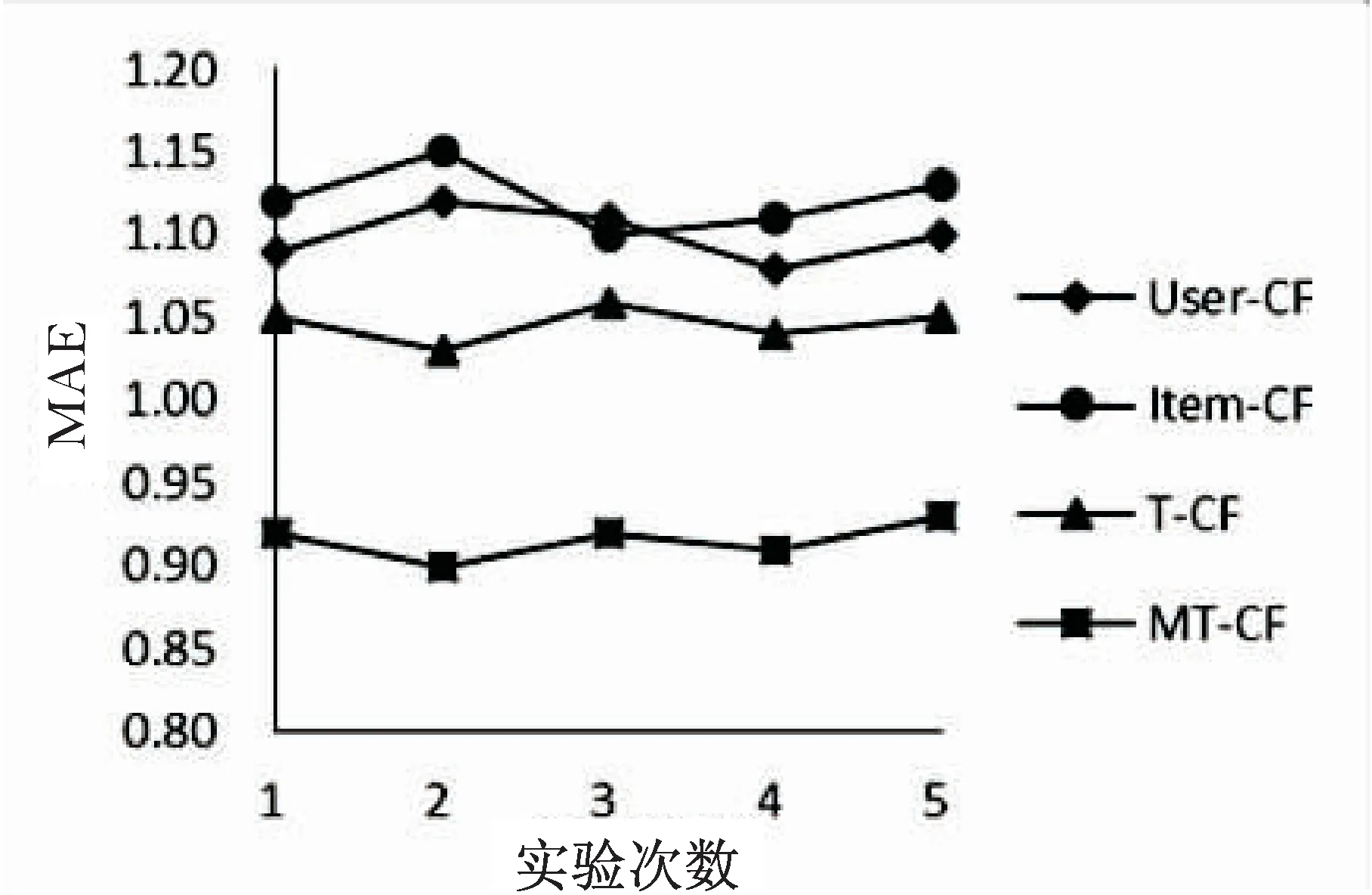
图2 不同算法的推荐效果对比
实验结果显示,传统的协同过滤算法(User-CF和Item-CF)的MAE值较低,性能较差,User-CF性能略优于Item-CF,原因是Epinions数据集中,用户数目远小于项目数据,平均每个用户评价13.49个项目,而平均每个项目被4.76个用户所评价。融合信任机制的协同过滤算法(T-CF)性能优于传统的协同过滤算法,目前影响推荐算法性能的主要因素是数据稀疏程度,利用信任的可传播性,T-CF算法能够对数据进行较好的扩充,从而提高算法性能。文中提出的MT-CF算法充分考虑了信任的影响因素,构建了更为合理的信任模型,对数据进行了更好的扩充,避免数据稀疏带来的推荐性能不佳。从图2中可看出其性能明显得到了提高。
4 结束语
将信任机制融合到协同过滤算法中,根据麦肯锡信任公式构建多元信任模型,并利用信任的可传递性对用户信任矩阵进行扩充。多元信任模型因综合考虑了多个影响因素,所以计算得到的信任值更为可靠,以此信任模型为基础的信任扩充更为有效。最终,以信任度代替相似度,发现用户的最近邻,从而获得推荐。实验结果表明,融合多元信任机制的协同过滤算法有效提高了推荐精度,避免了数据稀疏带来的推荐效果不佳的问题。
在推荐系统中,数据来源包括用户、项目及用户与项目之间的关系。一个有效的推荐算法应该是能够合理利用各方面数据信息的算法。所以之后应该继续研究如何综合利用多方面数据进行有效推荐。
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
汽车观察(2019年2期)2019-03-15 06:00:50
少年博览·小学高年级(2018年10期)2018-12-10 09:00:04
环球时报(2018-01-23)2018-01-23 05:25:53
桃之夭夭B(2017年2期)2017-02-24 17:32:43
知音海外版(上半月)(2016年12期)2017-01-13 13:10:09
中国卫生(2016年5期)2016-11-12 13:25:26
计算机工程(2015年4期)2015-07-05 08:27:45
高中生·青春励志(2014年11期)2014-11-25 10:07:54
生物进化(2014年2期)2014-04-16 04:36:26
