
一种面向旅游评论的情感特征识别方法
2018-11-22 11:58陈耀东彭蝶飞
计算机技术与发展 2018年11期
陈耀东,彭蝶飞
(1.长沙师范学院 信息与工程系,湖南 长沙 410100; 2.长沙师范学院 科研与学科建设处,湖南 长沙 410100)
1 概 述
情感分析(sentiment analysis,又称极性分类)主要对主观性文本所表达的情感进行褒贬分类的问题进行研究。从应用场景的角度看,情感分析任务可分为无主题的分析方法和主题指定的分类方法。前者主要针对主题不明确的微博等篇章级文本进行情感极性分析[1],一般同时涉及主题的挖掘过程,偏重于统计模型的研究。后者是给定某个或者若干关联主题考虑句一级或者词一级文本的细粒度情感分类[2],偏重于计算语言学的方法。主题指定的情感分析方法主要依靠情感词集[3-4]、词性以及句子结构抽取N-Gram[5]、句法关系[6]等语法特征获得特征-主题的关系,再通过统计模型分类情感。语义角色标注(semantic role labeling,SRL)是一种区别于传统深层分析的浅层语义分析技术,旨在分析句子的语义框架(即谓词框架)。由于避免对句子的深层结构分析,角色标注的准确率远高于句子成份的识别。目前中文的语义角色标注库是PropBank[7]。文献[8]是对利用SRL进行情感分析进行研究,采用角色从在线新闻文本中提取观点(情感词)、观点持有者以及评价对象,文献[9]通过SRL抽取评论主题。但这些方法都只是利用角色关系提取主题,未考虑判断情感特征与主题的相关性。另外,文献[2]等面向金融领域通过SRL获取主题-特征项,而文中面向的游客评论存在大量句内多主题情况,基于游客评论库的角色标注特点与分布统计设计出更有效的分类方法。
主题是情感分析的基础,面向微博等的情感分析通常是考虑篇章的整体情感倾向,主题本身不明确或者是在情感分析的同时通过学习算法自动获取。这一方式不适于景区游客评论等一些需要明确主题或者主题预设的应用领域,特别是当前大数据驱动之下,国内的传统旅游向智慧旅游转变,通过识别、挖掘游客对于景区、景点等特点主题的情感倾向,能够及时发现景区管理的现行问题,有效改进管理质量。通过观察游客评论发现,评论语句通常涉及多个主题且交织在一起,大量的噪声特征可能导致分类器对某特定主题的情感误判,如例句A所示:
例句A:尽管这些简陋的餐馆卫生条件不大好,我还是被景区的美景打动了。
例句A是对某个景区的评论,情感分析时应首先明确美景是所描述的主题,餐馆和卫生条件均与文本主题无关,进一步可判定前两个特征词“简陋”、“不大好”为噪声(描述的对象不是主题),“打动”为真正有效的情感特征(描述主题美景)。由于噪声特征多于真正有效的情感特征,在传统篇章级情感分析方法下例句A将被错分为贬义。由此可见,只能采用细粒度的情感分析方法确定特征与主题的相关性,才能保证对游客评论情感判别的正确分类。
文中从主题与情感特征的相关性展开研究,在明确主题条件下讨论对应情感特征是否是有效的判定标准,并提出了有效性的度量方法。在此基础上,以在线情感文本的元数据信息(metadata)为指示词,设计了一种有“针对性”的候选主题抽取算法以及一种有效情感特征的识别与抽取方法。图1展示了工作流程,分两个阶段,第一阶抽取段候选主题项,依据评论网站的元数据信息获取评论文本的候选主题集;第二阶段识别有效情感特征,通过候选主题项找到主题句并对其进行语义角色标注,根据角色的语义指向判断候选情感特征是否为主题相关的有效特征。

图1 研究流程
2 基于角色标注的情感特征识别
2.1 基于主题元数据的主题项抽取
对主题元数据进行研究发现,许多评论网站、论坛等通常会以格式化或半格式化的方式给出评论对象的介绍和相关说明,比如景区网站以统一格式列出景点、餐饮,影评网站展示每部影片的片名、演员、导演、剧情等。这些信息有些正是评论的对象,有些则与评论对象密切相关(如具有所属关系、上下位关系等),将这些具有一定结构化程度的信息统称为主题元数据(topic metadata)。主题元数据是经过加工的主题属性或其组成部分的名词性成分,在评论中有“针对性”地抽取与元数据相关的成分作为候选主题特征项。
当前主要考虑具有两种关系的成分:修饰关系和并列关系。
(1)修饰关系(modification/adjunction)。考虑句法树中的定中类短语,若指示词处于修饰词,那么将所修饰的中心名词作为特征项候选。文中主要考虑句法树中的名词短语以及嵌套名词短语形式。如例句B的名词短语“浔龙河的亲子营”,若浔龙河为指示词,且修饰亲子营,则亲子营为候选主题项。再如例句C中的名词短语“樱花园的便捷摆渡车”,尽管樱花园作为指示词不直接修饰摆渡车,仍将它所修饰的名词短语的中心词摆渡车作为主题项候选。
例句B:[Arg0浔龙河的亲子营] [ArgM-Adv太] [Predicate好玩]了。
例句C:[Arg0大家] [ArgM-Adv都很][Predicate认同][Arg1樱花园的便捷摆渡车]。
例句D:[Arg0这里的交通和路况]令人[predicate不大满意]。
(2)并列关系(coordination)。考虑句法树中的名词性的并列短语,若其中的一个名词成分是已知的主题项候选,则另一个名词成分也是候选。如例句D中,若交通是已获取的特征项,则路况也是候选主题项。
实际过程中采用bootstrap方式,即首先以景区评论库的metadata词为候选词,通过上述修饰关系规则与并列关系规则获取候选特征项,得到特征项集合后以此作为候选项再次遍历评论库,直至没有新特征项被发掘。bootstrap方式最后选取前K个高频特征项(实验过程经验性地选择K为200)作为最终的主题特征项集。
2.2 基于语义指向的情感特征识别
对于每个评论文本,经过主题项抽取步骤后,将包含主题项的句子作为主题句,通过HowNet情感词典抽取主题句的所有情感词,再通过情感特征识别算法形成有效特征集。
2.2.1 有效情感特征
定义1 有效情感特征(effective sentiment words):文本有效情感特征是指符合下面条件的预选情感词:该情感词处于主题句内;该情感词的语义指向是给定主题。
为描述方便,将文献[10-11]所识别的文本特征称为基本情感特征(也即词袋特征),文献[12-13]的特征表示称为主题情感特征。表1展示了有效情感特征与它们的异同。

表1 三种文本情感特征表示类型
有效情感特征实际上是主题情感特征的子集。有效情感特征的语义相关是建立在情感词与主题间的语义关联,这种相关主要通过语义指向(semantic orientation)来判定。语义指向[14-15]是一个汉语语言学问题,主要是指句法结构中句法成分之间所具有的带方向或目标的语义联系。由于普通语言学对语言现象的研究是描写性的,缺乏定量分析,因而文中借助语义角色来判断情感词的语义指向,即情感词的语义指向由所属的语义角色决定。
2.2.2 情感特征识别
利用语义角色标注器给每个主题句进行角色标注。对每个主题情感特征,计算该特征对应角色的语义指向,并判别该主题情感特征是否为有效情感特征。对景区评论库中情感词的语义角色分布情况进行统计(情感词共出现约36 000次)与研究,发现情感词在角色中的分布很不均衡:
(1)作为谓词出现的情形占有约45%,包括实义动词(如喜欢、晕倒)、形容词性谓词(不错、好吃、不堪)、名词性谓词(眼缘、好感,违和感)的情形,以及无谓词类句子;
(2)作为受事Arg1的情形占约30%;
(3)作为修饰类状语ArgM-ADV的情形占约9%。
然后进一步统计了情感词的语义指向,研究出现情感词的角色(简称为情感角色)的语义指向分布。统计基于一个事实:在一个谓词框架中,若某个角色含有主题特征项,则它是框架中情感角色的语义指向。基于以上统计分析,构建有效情感特征识别算法,如算法1所示。

算法1对名词性情感角色(Arg0~Arg4)和非名词性角色(谓词和非核心角色)分别进行处理。名词性角色简单地指定其自身作为语义指向(步骤4.1),而对于非名词角色,按角色优先规则进行分析(步骤3和4.2)。步骤5和6对有效情感特征进行识别,即当情感角色的语义指向(targetRole)存在且中心词为主题特征项,则认为该情感角色所含的情感词是有效情感特征,否则判别为非有效情感特征。
3 实验与分析
3.1 实验说明
(1)数据收集与处理。实验面向游客评论的情感分析问题。选取了湖南省两个代表性景区—长沙县浔龙河生态小镇和南岳衡山,通过携程、穷游、穷驴、驴妈妈等活跃网站以及本地旅游论坛社区,利用爬虫软件抓取了18 500余条评论信息,同时使用HTML分析器获取每个评论文本对应的元数据。对原始数据进行了预处理,包括去重(去除重复评论)、除噪(广告、无任何主题的评论)、剪枝(去除长度小于10个字的评论),最终得到10 523个有效评论文本。
(2)模型特征。文中主要研究的是实现情感特征的有效抽取,因此实验的关键是评估不同的特征选取方法对最终情感分类效果的影响。为此,将评论文本采用词袋方法(bag-of-words)描述,形式化定义如下:假设{w1,w2,…,wm}是一个预选情感词集,每个评论文本表示为v=(f1,f2,…,fm),其中fi∈{0,1},fi=1当且仅当wi在指定文本中出现,反之亦然。利用表1的三种特征表示,即wi在文本中出现;wi在文本主题句中有出现;wi是文本中出现的有效情感词,分别记为:基本特征词表示(basic sentiment words,BSW)、主题特征词表示(topic-relative sentiment words,RSW)、有效特征词表示(effective sentiment words,ESW)。选取SVM(支持向量机)作为训练和分类模型(具体使用SVMLight开源软件),SVM具有学习性能强、泛化性高、受样本规模影响较小等优点。
3.2 实验结果
从已标注的评论库中随机抽取不同数量的标注评论文本作为训练集,以另1 000篇文本作测试集,结果如表2所示(数据为F1值)。可以看到当标注文本小于500时,BSW的性能总优于RSW和ESW。通过分析认为,当标注样本较小时,ESW和RSW所获取的特征向量相对比较稀疏。当训练文本大于500时,RSW和ESW的性能显著提高,并超过了BSW。这说明了与主题相关的情感特征较好地反映了文本的真实情感。值得注意的是,ESW的效果在表中总低于RSW。对错分的文本进行深入观察,发现绝大多数情况是:一方面所含的句子较少(超过一半的文本仅含1到3个句子),导致在训练时未能获取足够的角色特征;另一方面这些文本具有明显的口语化色彩,这些不合语法规范的句子致使句法分析器和角色标注器的分析准确率严重下降。
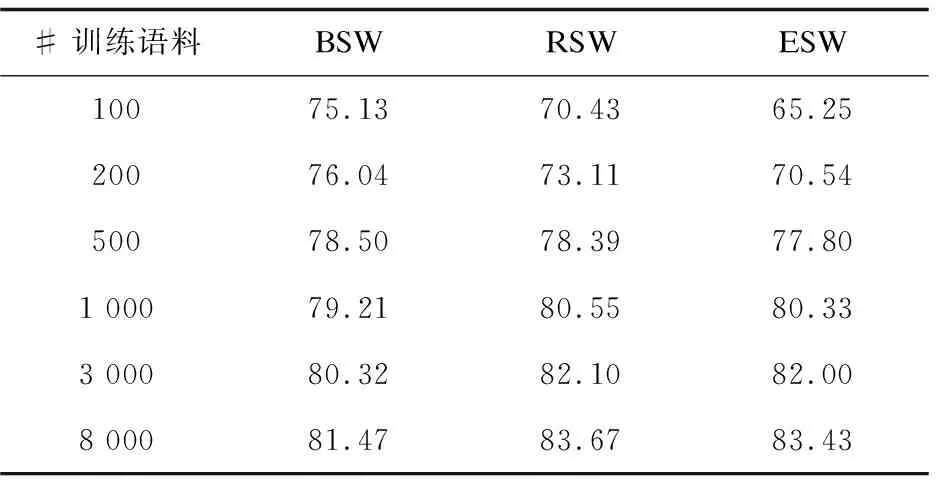
表2 有效情感特征评估结果(平均2句/文本)
为排除上述两个文本内在缺陷对评测造成的干扰,收集比较长的评论文本进行实验(每篇含6个以上的句子),结果见表3。
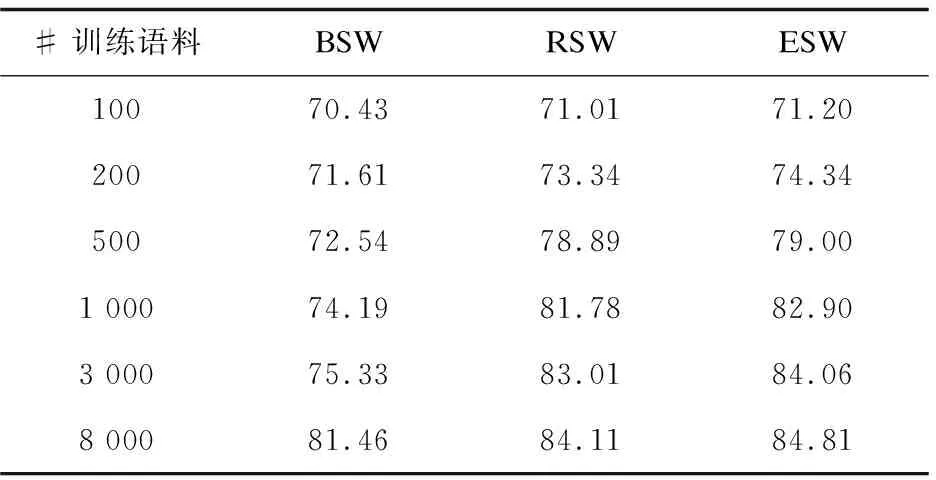
表3 有效情感特征评估结果(平均8句/文本)
这时,ESW的性能明显超过了RSW和BSW,即使是在标注集较小的环境下。这说明有效情感特征的选择对文本情感的分析具有重要影响。这一结论也可以从BSW的性能变化得到。比较表3和表2的第一列,当文本长度增加时BSW的性能反而有下降趋势。这可以解释为文本长度的增加带来了与主题无关的特征增多,由于BSW不区别情感特征与主题的相关性,因而造成分析的错误。
4 结束语
构建了一个基于语义角色的情感分析器,将角色标注任务提供的语义信息应用于情感分析,实验部分面向在线游客评论库。实验结果表明,对于较长的文本,通过基本角色的情感分析器所抽取的特征能有效地提高分类性能,但在短文本中,由于句法分析和语义分析处理口语化的非完整句子的能力较差,从而导致整体效果不如经典方法。因此得出结论:情感分析对语言的深层分析,尤其是语义分析的要求非常高;提高文本语义分析能力,建立合适的语义模型是解决这一问题值得研究的途径。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
小天使·一年级语数英综合(2016年4期)2016-11-19
小天使·一年级语数英综合(2016年8期)2016-05-14
小天使·一年级语数英综合(2016年6期)2016-05-14
长江学术(2016年4期)2016-03-11
小天使·一年级语数英综合(2015年10期)2015-10-14
人间(2015年21期)2015-03-11
