
基于协同矩阵分解的单标签跨模态检索
2018-11-22 12:02:24李新卫荆晓远
计算机技术与发展 2018年11期
李新卫,吴 飞,荆晓远
(南京邮电大学 自动化学院,江苏 南京 210023)
0 引 言
随着互联网的迅速发展,社会步入了大数据时代。大数据通常以图像、文本等多种不同的模态表示,而模态间的数据并不是独立的,而是有着本质的联系,如何挖掘出数据之间的关联信息成为了人们关注的热点。跨模态检索[1-3]作为一种基本的相关技术,在机器学习、计算机视觉和数据挖掘等领域应用广泛,然而大数据具有数据量大、维度高以及模态间的语义鸿沟[4]等一系列特点,从而使得针对大数据的跨模态检索困难重重。
为了减轻模态间的差异性,相关学者提出了一系列方法,一部分关注于潜在子空间学习,主要是用来学习两个投影,将文本与图像数据投影到公共空间进行相关性分析,比如CCA[5]及其变形[6];而哈希算法[7-9]作为一种近似最近邻检索技术,具有存储量小、检索速度快等特点,典型方法有CVH[10]、IMH[11]和SCM[12]。然而,这些方法都有局限性,比如检索精度低、速度慢,因此设计更好的算法是相关工作者亟需解决的难题。基于此,文中提出一种基于协同矩阵分解的单标签跨模态检索方法。
1 方法描述
基于协同矩阵分解的单标签跨模态哈希检索方法由三部分构成:矩阵分解、哈希函数和图正则化项。矩阵分解学习训练集在低维潜在语义子空间的哈希码表示;哈希函数学习投影,将训练集外的样本表示成低维的哈希码;图正则化是用来保持原数据的局部几何结构的稀疏图[9]。
1.1 协同矩阵分解
协同矩阵分解主要用于低秩表示学习[13]。假设图像模态为X1,文本模态为X2,学习基矩阵U1∈Rd1×r、U2∈Rd2×r,将X1和X2投影到r维的二进制语义空间V∈{0,1}r×N。其中r为二进制哈希的长度,V表示不同模态的公共表示。一般来讲,该过程可以通过下列目标函数求得:
(1)
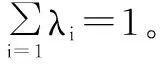
1.2 哈希函数
设训练集外的样本为x,学习两个哈希函数分别将x的图像x1∈Rd1和文本x2∈Rd2进行二进制编码。不妨假设采用简单的线性函数
h(xi)=sign(xiPi+bi)
(2)
其中,sign(x)为符号函数;Pi∈Rdi×r为映射矩阵;bi为用来保证哈希编码平衡的偏置向量。
通过哈希函数,原始的图像x1和对应的文本x2在低维的潜在语义空间分别表示为:
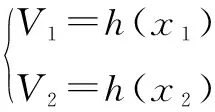
(3)
根据以上假设,相似的样本经过编码后的哈希距离应尽可能小,因此具有目标函数:
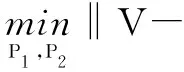
(4)
1.3 多模态图正则化项
图正则项[14-15]在机器学习、计算机视觉等领域取得了不错的发展,其用来维护局部几何结构,保证模态内相似性和模态间相似性。
模态间相似性:不同模态具有不同的特征表示,但是同一样本共享相同的语义表示。为了在低维语义中能够保持模态间的相似性,定义图像和文本的模态间相似性矩阵:
(5)
模态内相似性:单模态相似的实例投影到低维语义中应该保持近邻关系,即哈希码的关联性尽可能大。定义单模态KNN相似矩阵:
(6)
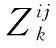
整体的相似性矩阵为:
(7)
其中,β为保证模态间相似性和模态内相似性平衡的参数;W1、W2分别为图像和文本的单模态相似性矩阵;W12、W21为模态间相似性矩阵,W12=W21。
1.4 整体目标函数
综上所述,整体目标函数为:
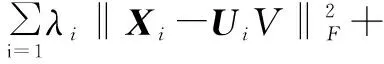
(8)
其中,α和γ分别为对应的权重因子。
2 算法求解步骤
目标函数Φ整体来说是非凸的,是个NP难问题,然而对于其中一个参数是可解的,因此可以采用迭代优化算法求解,具体步骤如下:
步骤1:更新U1、U2,固定V、P1和P2,通过拉格朗日乘子法可得:
(9)
步骤2:更新V,固定U1、U2、P1和P2,目标函数可以写成:
(10)
由于V是离散约束的,直接求解很棘手,故对其进行松弛变换,将V∈{0,1}r×N松弛为0≤V≤1,通过拉格朗日乘子法可得:
(11)
利用KKT条件,得到V的更新公式为:
Vij=
(12)
步骤3:更新P1、P2,由拉格朗日乘子法解得:
(13)
3 实验及结果分析
3.1 数据库及评价指标
为了验证该方法的有效性,在Wiki和Pascal VOC 2007数据集上与若干相关方法进行了对比,包括CCA[4]、IMH[11]、CVH[10]、SCM_orth和SCM_seq[12]。
Wiki数据集[16]包含2 866多媒体数据,分为10个主题,比如战争、艺术、天空等,其中每个样本是图像-文本对,图像是由128维的BOVW SIFT特征表示,文本是由10维的主题向量构成。
Pascal VOC 2007数据集[17]包含5 011/4 952图像文本对,分为20类。部分图像是多标签的,文中只研究单标签,因此对该数据集进行相应处理,图像由512维的Gist特征表示,文本对应319维的词频特征。
实验中进行了两种跨模态检索任务:以图检文,Img2Text,即用图像去检索相关的文本;以文检图,Text2Img,即用文本去检索对应的图像。为了评估检索精度,使用mAP[18]作为性能指标,其公式为:
(14)
其中,qi为一查询样本;N为查询样本量;AP()的计算公式为:
(15)
其中,T表示检索集中与q相关的总量;R表示检索到的样本量;ξ(r)为指示函数。
3.2 实验结果
实验1:在Wiki数据集上进行了Img2Text和Text2Img实验,随机抽取2 173个样本对作为训练集,其余的693个样本为测试集,实验结果如表1所示。

表1 Wiki数据集下各方法的mAP
实验2:在Pascal VOC 2007数据集上进行了Img2Text和Text2Img实验,训练集为2 808对样本,测试集为2 841对样本,实验结果如表2所示。
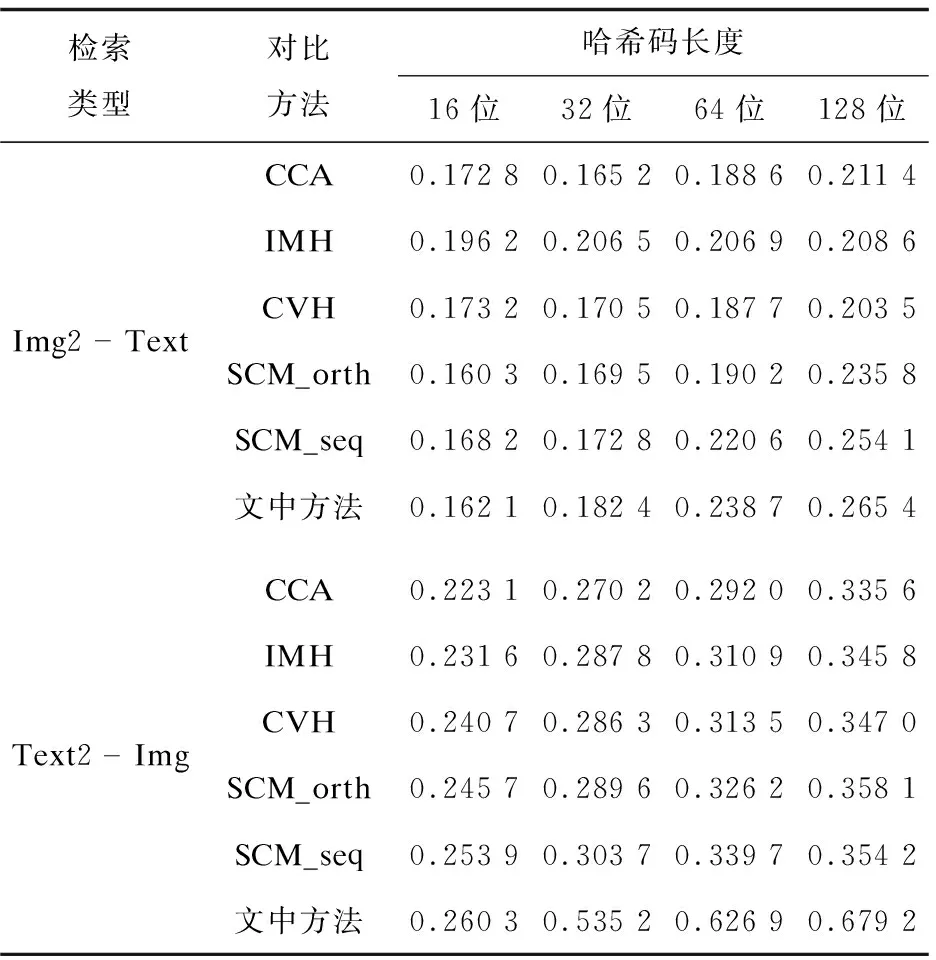
表2 Pascal VOC 2007数据集下各方法的mAP
由表1、表2可知,文中方法比其他方法效果好;随着哈希码变长,检索精度也越来越好,说明了长的哈希码更能够保持结构特征。
4 结束语
提出了一种基于协同矩阵分解的单标签跨模态哈希检索方法,目标函数由三部分构成,即矩阵分解、哈希函数和图正则化项。矩阵分解学习训练集在低维潜在语义子空间的哈希码;哈希函数用来学习投影,将训练集外的样本表示成低维空间上的哈希码,进行相似性搜索;图正则化用来保持原数据的局部流行几何结构。在两种常用的数据集上进行了大量的实验,结果证明了该方法的优越性。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
河北画报(2020年8期)2020-10-27 02:54:20
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
专利代理(2016年1期)2016-05-17 06:14:36
工业设计(2016年8期)2016-04-16 02:43:34
计算机工程(2015年8期)2015-07-03 12:20:04
计算机工程(2014年6期)2014-02-28 01:25:40
电子设计工程(2014年12期)2014-02-27 11:58:03
俄罗斯问题研究(2013年1期)2013-03-11 15:44:01
