
浅谈基于大数据处理及文本相似度判断的信息服务工单分析工具
2018-11-20 09:28屈子梦
机电信息 2018年33期
屈子梦
(广东电网有限责任公司江门供电局,广东江门529000)
0 引言
基于文本挖掘技术的信息服务工单分析工具,解决了当前系统运维工作中定位根因繁琐、解决问题耗时等难题。同时,业界较为成熟的文本挖掘算法以及大数据处理引擎Spark也为该工具的可行性提供了有力的保障。本文将以信息工单数据的流向为依据,介绍服务工单分析工具中的主要模块,包括:Spark处理数据获取系统中的重要问题,文本相似度算法计算问题的相似度,生成知识库。在这当中,问题相似度判断的准确性将会是实现该工具的难点,同时也是其可用性的重要依据,较高的准确性将会很大程度上提高运维工作的效率。
1 生成系统重要问题
信息系统中包含大量的工单数据,也意味着这些数据中包含大量有价值的信息。使用Spark数据处理引擎可以有效且快速地对工单进行汇总、分类等各项操作。生成重要问题的数据处理流程如图1所示。
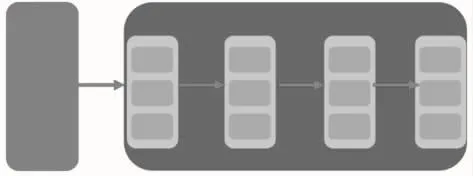
图1 工单数据处理流程
在展开数据处理的流程之前,先对Spark作简单的介绍:Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎,Spark是UC Berkeley AMP Lab(加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。其中,该计算框架最重要的抽象概念就是RDD(Resilient Distributed Dataset),弹性分布式数据集,即图1中的浅灰色部分。对RDD的操作共分为两大类:transformation(转换)和action(动作),本篇论文所讨论的数据操作过程也都是这两大类的子集。这其中蕴含的一个基本概念是,Spark的操作是延迟(lazy)的,即只有action才能真正触发数据处理流程。
具体地,工单数据的处理流程主要涉及Oracle和Spark两个组件。
(1)周期性(每月)地从Oracle读取系统工单数据生成RDD。
(2)对读取的工单数据做分组,将同类型的系统数据分为一组。在这个过程中涉及的转换操作是groupBy,一个简单的方法调用就能将大量的数据分组,这也正是Spark强大的地方。
(3)在这一步中,需要将(2)中的结果进行计数,即计算每个分组中包括的系统个数,需要用到RDD的一种动作count。
(4)对分组系统进行过滤,例如人们只关心当月被用户提的工单数大于1 000的系统有哪些,该过滤需要用到一种转换操作filter。到此,就生成了该月的重点系统。
对于每个重点系统中的重点问题,只需要重复上述的(2)(3)(4)三个过程就可以得到结果。读者这时可能会问,如果现在我关注的重点系统有50个,那上述(2)(3)(4)过程岂不是要执行50次?完全正确!但是,这又是强大的Spark发挥作用的时候,虽然要得到结果确实需要再执行50遍,但这50次执行过程是并发运行的,在资源充足的理想状态下,我们可以认为执行50次任务的时间和执行一次的时间相等!
Spark处理大数据量的高性能已经被大量的工业以及学术界实践所证明。针对每月信息系统中大概万级的工单条数,用三台虚拟机部署一个Spark环境就足以用分钟级的耗时将数据处理完毕。相比于人工逐条处理或是单纯地在Oracle中使用sql语句处理,效率和准确率都提升得非常明显!
2 挖掘工单的相似性
原始的工单数据在经过Spark的处理后具备了一定的类别性和规范性,但生成的重要问题中仍然存在很多重复的内容。虽然有些工单问题从标题上看并没有关联,然而通过将其内容进行比对后就不难发现往往一些工单所反映的是同一个或者同一类问题,这就导致了运维人员还是无法精准且快速地根据这些重要问题制定相应的解决方案。由此就引出了这篇论文所涉及的一个技术关键点:计算文本相似度。
2.1 文本相似度的概念
顾名思义,文本相似度就是表示两段文字相似的程度,是属于自然语言处理的一个重要的课题。实际上我们不难发现,人通过阅读会很容易发现两段文字分别表达的是什么内容,也就顺理成章地会给出一个相似度的高低。但这件事如果让机器自动化地去做的话就没有那么容易了。另外一个相似的例子是,人可以很容易地分辨出一只猫和一只狗,然而机器识别起来依旧很困难。回到文本相似度的问题上来,文本是一种高维的语义空间,如何对其进行抽象分解,从而能够站在数学角度去量化其相似性?下面主要对信息服务工单分析工具中使用到的两种度量方法进行说明。
2.2 杰卡德(Jaccard)相似系数
这种相似度计算方式相对简单,原理也易于理解,就是计算单词集合之间的交集和并集大小的比例,该值越大,表示两个文本越相似。在涉及大规模并行计算时,该方法在效率上有一定的优势。Jaccard相似度公式如下:

举例:
句子A:“我喜欢看电视,不喜欢看电影。”
句子B:“我不喜欢看电视,也不喜欢看电影。”
分词去噪后:A=(我,喜欢,看,电视,电影,不);B=(我,喜欢,看,电视,电影,也,不)。
那么根据公式可得:J(A,B)=(我,喜欢,看,电视,电影,不)/(我,喜欢,看,电视,电影,也,不)=6/7=0.86。
2.3 余弦相似性
余弦相似度即计算两个向量之间的夹角,夹角越小相似度越高。其公式为:
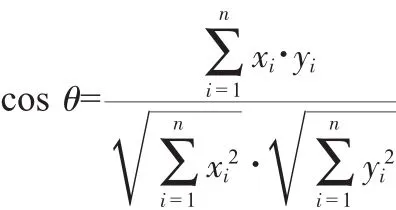
假定A和B是两个n维向量,A是[A1,A2,…,An],B是[B1,B2,…,Bn],则根据公式可以计算A与B的夹角余弦。沿用2.2中的例子,计算词频如下:
句子A:我1,喜欢2,看2,电视1,电影1,不1,也0。
句子B:我1,喜欢2,看2,电视1,电影1,不2,也1。
生成词频向量:句子A为[1,2,2,1,1,1,0],句子B为[1,2,2,1,1,2,1]。使用上述公式,我们便可得到句子A与句子B的夹角余弦,即两句话的文本相似度可以根据余弦的值去度量。
2.4 文本相似性度量的成果
信息工单数据在经过相似性度量的算法处理后,才能得到真正意义上的重要问题库,运维人员可以根据这份覆盖整个信息系统但又精简、精确的问题库生成相应的知识库。为避免重复计算,文本相似性的判断只是针对问题的主体,并没有对问题标题作相似性度量。可以说,文本相似性算法的运用是整个信息服务工单分析工具的核心价值。
3 结语
良好的信息系统建设,可以支撑电网企业业务发展。通过大数据分析与文本相似性算法,掌握信息系统功能缺陷与用户需求,可以更快、更好地改善系统可靠性、实用性,让电网企业信息系统运作更加高效,服务用户。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
电子测试(2022年7期)2022-04-22
高技术通讯(2021年6期)2021-07-28
河北画报(2020年8期)2020-10-27
中国核电(2017年1期)2017-05-17
中学数学杂志(高中版)(2016年6期)2017-03-01
浙江大学学报(工学版)(2016年2期)2016-06-05
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
职业技术(2015年8期)2016-01-05
中国科技信息(2015年23期)2015-11-07
