
基于VDCNN与LSTM混合模型的中文文本分类研究
2018-11-20 06:09:06彭玉青宋初柏赵晓松
计算机工程 2018年11期
彭玉青,宋初柏,闫 倩,赵晓松,魏 铭
(河北工业大学 人工智能与数据科学学院,天津 300401)
0 概述
随着互联网技术和移动社交网络平台的发展,网络中的文本信息量呈爆发式增长,鉴于网络平台实时性较强的特点,这些文本信息虽然具有极大的潜在价值,但是在网络中以杂乱的形式存在,缺乏有效的信息组织和管理。而文本分类作为组织和管理文本信息的有效方法,能够解决信息杂乱问题,且在信息分拣、个性化新闻推荐、垃圾邮件过滤、用户意图分析等领域得到了广泛应用,也受到越来越多研究者的关注。
目前,常用的文本分类方法有朴素贝叶斯、K最近邻(K-Nearest Neighbor,KNN)、隐马尔科夫模型(Hidden Markov Model,HMM)、支持向量机(Support Vector Machine,SVM)等。在这些方法中,有些需要人工提取特征,有些由于随机向量的分量无关性,会引起主题之间不相关的问题。针对这些不足,越来越多的学者将神经网络应用到文本分类领域[1],目前常用于文本分类的神经网络结构包括BP神经网络、卷积神经网络(Convolution Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)等。
本文建立一种超深卷积神经网络(Very Deep Convolution Neural Network,VDCNN)和长短期记忆网络(Long Short-Term Memory network,LSTM)混合模型,使用词嵌入(Word Embedding)将文本转换为低维度向量,以提升对词向量化后的文本进行分类的精确率,然后通过实验验证该模型的分类效果。
1 相关工作
为提高当前文本分类方法的准确率,很多学者进行了研究。文献[2]提出一种基于文本加权的KNN算法,其利用文本加权提升KNN算法对文本进行分类时的准确率。文献[3]使用基于LSTM和门阀递归单元(Gated Recurrent Unit,GRU)计算节点的双向递归神经网络来提取文本特征,然后使用Softmax对文本特征进行分类。文献[4]提出一种结合卷积神经网络和KNN算法的分类方法,其能够有效提高短文本分类的效果。文献[5]提出一种基于事件卷积特征的文本分类方法,其利用事件的语义特性弥补已有模型的不足。文献[6]在LSTM模型中引入一种注意力机制,解决了特征向量在提取过程中信息丢失和信息冗余的问题。
虽然上述改进的文本分类方法取得了较好的结果,但是与目前应用于图像处理和语音识别领域的优秀网络相比,模型的深度仍然较浅,分类的效果和准确率也较低,同时由于在自然语言中存在着上下文依赖的非连续关系,在传统神经网络结构中,卷积核大小难以确定的问题仍然没有得到解决。
针对上述方法存在的缺陷,受文献[7-8]在图像处理领域中提出的VDCNN的结构启发,以及LSTM作为循环神经网络的一种特殊类型,能够长期记住前文的有效信息并有效利用文本前后具有关联关系的特点,本文建立一种VDCNN和LSTM相结合的混合模型,然后通过实验验证该混合网络结构模型在文本分类上的效果。
2 词嵌入
如果将文本按照字面顺序以直接编码的方式转换为向量,会导致向量维度过高,同时也忽视了自然语言前后词句之间具有依存关系的特点。为解决该问题,并让LSTM网络能够更好地利用自然语言中的上下文关系,本文将词嵌入与混合模型相结合,将文本转换为低维度向量,并且文本中前后文的近义词在转化为低维度向量后其在向量空间中也是相邻的,从而将上下文中的近义词进行聚合。
2.1 相关定义
在自然语言处理中,一般将每个词作为基本单元进行向量表示。对词典D中的任意词w,指定一个固定长度的实值向量v(w)∈Rm,v(w)称为w的词向量,m为词向量的长度。
一种简单的词向量表示为独热表示,它通过一个很长的向量来表示一个词,词典D的大小N为向量的长度,向量的分量只有一个1,其他全为0,1的位置对应词在词典中的索引。由于深度学习领域存在海量数据,这种词向量会带来维度过高的问题。
为解决独热表示维度过高的问题并使向量能够刻画词与词之间的联系,本文使用分布表示进行词向量的表达。通过训练将文本中的每个词映射成一个长度固定且较短的向量,所有这些向量构成一个向量空间,每个向量之间的距离表示该向量所代表词之间的相似性。
2.2 Skip-gram模型
Skip-gram模型包含3层:输入层,投影层和输出层,其示意图如图1所示。
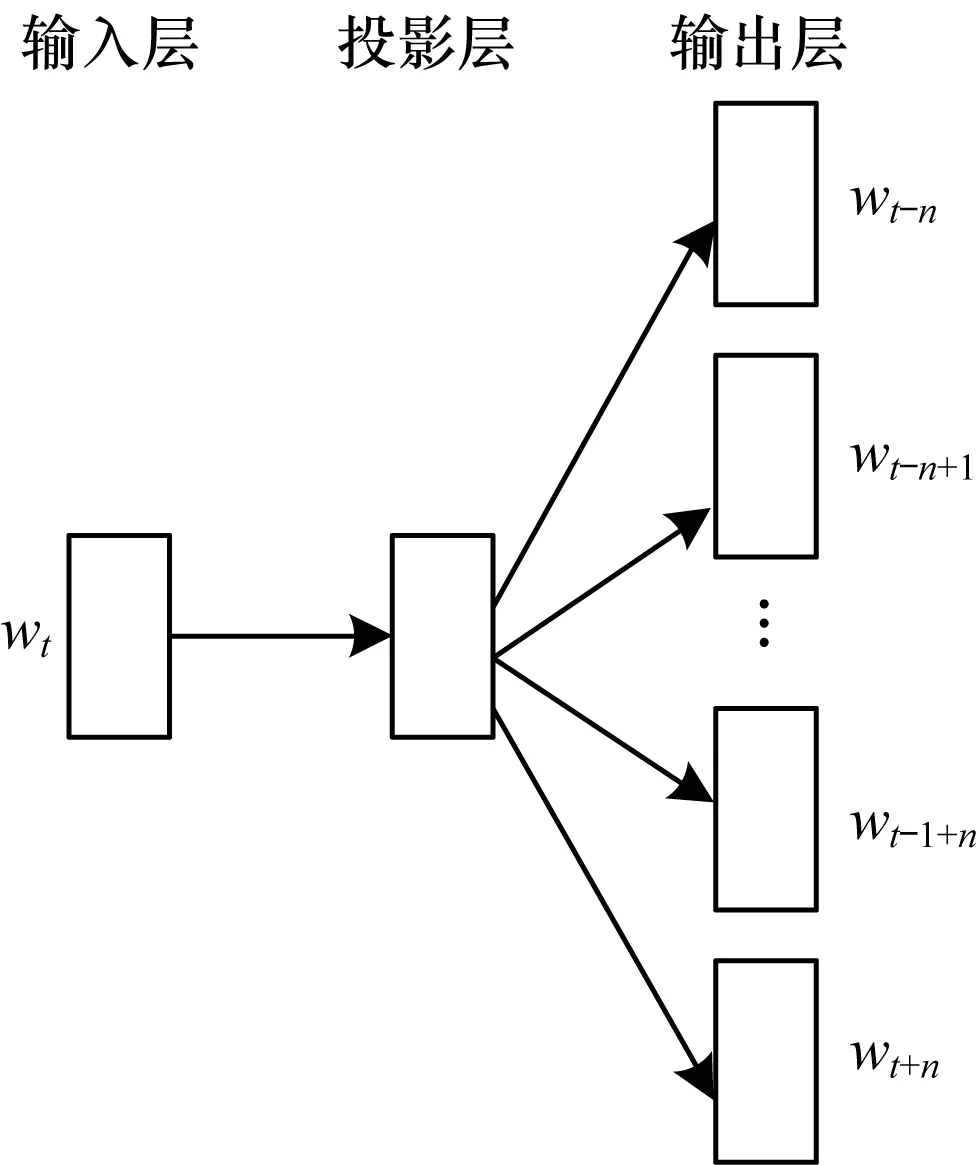
图1 Skip-gram模型
Skip-gram模型是一种利用某个词预测其周围词的概率的模型,即已知中间词wt,推导出周围2n个词wt-n,wt-n+1,…,wt-1+n,wt+n属于词典中某一个词的概率。wt周围词语的集合wt-n,wt-n+1,…,wt-1+n,wt+n表示wt的上下文语境,记为Context(w)。
该模型可以计算出周围词ci基于中间词wt的条件概率,定义为:
P(ci|wt)
(1)
其中,ci∈Context(w)。
对于某条语句S,利用Skip-gram模型可以计算出语句S为自然语言的概率,公式为:
(2)
其中,P(S)表示句子S为自然语言的概率,w为语句S中的词。模型的训练目标就是使得P(S)的概率值得到最大化。
对于输入的文本T,可以得到文本的概率表示公式为:
(3)
为求其最大的条件概率,令Skip-gram的似然函数为:
(4)
其中,θ为待估参数。模型的求解目标就是求目标函数的最大值,故将似然函数转换成底数似然函数:
(5)
其中,V表示词典大小。
本文利用jieba分词和Word2Vec工具,使用Skip-gram模型对文本训练后即可得到词向量,这些向量是低维度的,且近义词的向量在向量空间中是相邻的。
3 VDCNN与LSTM混合模型
为提高中文文本分类的准确率,本文建立一种结合VDCNN与LSTM的混合模型并用于文本分类。该模型结构如图2所示。其中,FC(I,O)表示输入长度为I、输出长度为O的全连接层。

图2 VDCNN与LSTM混合模型
在图2中,词嵌入层(Embedding Layer)与10层卷积层(Conv)以及3层全连接层(FC)组成VDCNN网络结构,共计14层,同时将LSTM以融合的形式和VDCNN网络结构组成混合模型。
由于网络结构模型层数较深,为优化其对内存的占用,结合VGG以及ResNets模型[9],在定义VDCNN模型结构时设置如下2条规则:
1)如果卷积之后输出的向量不变,则卷积核数目和特征图像的大小保持不变。
2)如果输出向量减半,则卷积核数目和特征图像的大小增加一倍。
针对规则2),在VGG和ResNets模型中,深度的增加可以有效提升其分类的效果。但是由于深度增加,使其对内存的需求大幅提升,同时根据卷积神经网络的设计准则,在卷积过程中要保证卷积的空间尺寸和卷积数据量缓慢变小,因此,在本文所提出的混合模型中,会对输出向量进行减半。但是,如果只对输出向量进行减半,卷积核数目和特征图像的大小不变,这违背了使卷积的空间尺寸和卷积数据量缓慢变小的设计准则,势必会导致在卷积过程中损失大量卷积信息。因此,为在减轻内存压力的同时保证网络结构的容纳能力,避免损失过量信息,本文模型在对输出向量减半时,设置卷积核数目和特征图像的大小增加一倍。
该混合模型共计14层,第1层为词嵌入层,将输入的文本序列展开成词向量的序列并作为卷积层的输入,词嵌入层之后的VDCNN网络结构为:
1)第1个和第2个卷积层设置为64个大小为3的卷积核。
2)对卷积结果进行池化操作,并连接2个卷积层,设置其卷积核大小为3、数量为128个。
3)进行3次池化,每次池化操作连接2个卷积层。
4)再次进行池化操作,连接3个全连接层得出分类结果。
由图2可知,VDCNN与LSTM混合模型包括5次池化操作,前3次对输出进行平均值池化,后2次采用最大值池化操作。这里把模型中每2次池化操作之间的卷积层称为一个卷积块。在VDCNN网络结构中,第2个卷积块的详细结构如图3所示。

图3 VDCNN网络结构中的第2个卷积块
该混合模型为了防止过拟合现象,降低特征的维数并优化内存占用,在每次平均值池化操作时将下采样因子(strides)设置为2,对输出向量减半,根据前文2条规则,每个卷积块的卷积核数目和特征图像的大小也由64分别变为128、256和512,而在第4个、第5个卷积块之后进行k-max下采样策略,每次对采样区选取k个局部最优特征值,舍弃冗余特征,同时能够保证生成固定维度的特征向量。在进行最后一次最大值池化操作后,设置3个全连接层。最后,再通过Softmax函数得到分类结果。在本文Softmax回归中,将x分类为类别j的概率为:
(6)
在网络结构模型层数较多的情况下,为加快收敛速度,降低学习周期,在VDCNN卷积层和全连接层设置激活函数ReLU[10],其公式如下:
F(x)=max(0,x)
(7)
在VDCNN中,由于引入了批标准化[11]操作和捷径连接,可以解决传统卷积神经网络随着深度增加导致准确率下降的问题,而且正是由于VDCNN网络深度的增加,有效提高了它对文本特征的提取能力,因此,VDCNN在图像处理和语音识别领域具有很好的效果。但是,由于自然语言具有倒装、前置等表达手法,导致当前文本可能与前文有很强的上下文依赖关系,在文本训练的过程中,可能需要之前的某些历史信息,而VDCNN并不具有这种保留历史信息的能力。鉴于自然语言的这种特点以及VDCNN在这方面的不足,本文将LSTM与VDCNN进行结合以组成混合模型。
LSTM是循环神经网络的一种特殊形式,由于传统RNN展开后相当于多层的前馈神经网络,RNN保存的历史数据量越大,其层数会越多[12]。当训练大量文本时,就会引起梯度消失(爆炸)和历史信息损失的问题,因此,传统的RNN能够保留的历史信息数量非常有限,而LSTM单元结构能够解决RNN的梯度消失问题。LSTM单元结构如图4所示。

图4 LSTM单元结构
LSTM通过设计专门的记忆单元用于保存之前的历史信息,达到长期“记住”信息的目的。这些历史信息的更新和删除受三个门控制,分别为输入门、输出门和遗忘门。
输入门用来控制当前节层单元状态的输入,输出门用来控制当前LSTM单元的输出,遗忘门用来控制上一时刻单元中存储的历史信息。记t时刻输入门、输出门和遗忘门分别为it、ot、ft,则该神经元的状态更新计算方法可以表示为:
it=σ(Wi[ht-1,xt]+bi)
(8)
ot=σ(Wo[ht-1,xt]+bo)
(9)
ft=σ(Wf[ht-1,xt]+bf)
(10)
其中,σ表示Sigmoid函数,Wi、Wo、Wf分别表示输入门、输出门和遗忘门的权重矩阵,bi、bo、bf分别表示各个门所对应的偏置。
在图4中,遗忘门与输入门又共同构成了更新门[13],用ct表示,其计算公式为:
ct=ft⊗ct-1+it⊗tanh(Wc[ht-1,xt]+bc)
(11)
其中,ct-1表示上一个时刻c的值,Wc表示更新门的权重矩阵,bc表示更新门的偏置。
设ht为该LSTM单元的最终输出,其计算公式为:
ht=ot⊗tanh(ct)
(12)
由上面的分析可以得出,3个门并不提供额外的信息,只是起到限制信息量的作用,同时保证每个LSTM隐藏单元记住历史信息,这能够弥补RNN网络的不足。同时,3个门起到的只是过滤的作用,故激活函数使用Sigmoid。VDCNN超深的层数能够有效提取文本向量的特征,LSTM的记忆单元针对自然语言前后依赖的特点,在训练过程中保留了历史信息,弥补了VDCNN的不足。因此,将VDCNN与LSTM组建为混合模型进行文本分类,可以有效提升分类效果。
在图2中,全连接层FC(4 096,2 048)之前,本文使用Keras框架中的Merge融合层对VDCNN和LSTM进行融合。Merge层能够提供一系列用于融合2个层或2个模型的方法,其代码示例如下:
merged = Merge([model_left,model_right],mode=′concat′)
其中,concat将待合并层输出沿着最后一个维度进行拼接,因此,其要求待合并层输出只有最后一个维度不同。该方法的输出结果为返回一个与层结构相同的对象,即上述代码中的merged,它可以被当做普通层的输出进行使用。最后连接3个全连接层,利用Softmax输出分类结果,至此,VDCNN与LSTM完成融合,组成如图2所示的混合模型。
4 实验验证
4.1 实验数据
4.1.1 训练词向量的语料集
对于知识挖据领域,一般使用知识库语料训练得出词向量,但是对于文本分类领域,为能够对文本进行更好的分类,需要使用比较现代、能够反映出近期网络热点内容、具有较广覆盖面的文章。本文使用具有多领域的微信公众号文章,该语料集属于中文平衡语料,共计800万篇,总词数达到650亿,使用其进行训练可以得出高质量的词向量。
4.1.2 文本分类语料库
本文使用Sogou语料库与复旦大学文本分类语料库进行文本分类,以测试本文所提出的VDCNN与LSTM混合模型的分类效果。
Sogou语料库是搜狗实验室(Sogou Lab)提供的全网新闻数据,该数据集来自2012年6月—7月期间新浪、网易、腾讯以及凤凰资讯等若干个新闻站点,有国内、国际、体育、社会、娱乐等18个频道的新闻数据,提供URL和正文信息。
由于该数据集为XML格式,实验之前需要利用脚本将XML中新闻标题与新闻内容这两部分的数据解析到相应的类别中,在处理过程中,每一篇文章另存为一个txt文件,txt里为新闻标题和新闻内容,然后再对每篇文本进行分词处理,分词工具为jieba分词。处理完成后该数据集大小为1.43 G,使用处理完成后的数据集作为文本分类的训练和测试语料。由于完整的实验数据量过于庞大且受实验设备的限制,本文从中选取了12个类别,每个类别随机抽取全部数据的一部分进行实验。在实验中,Sogou语料库文本类别与数量分布如表1所示,其中,90%作为训练集,10%作为测试集。
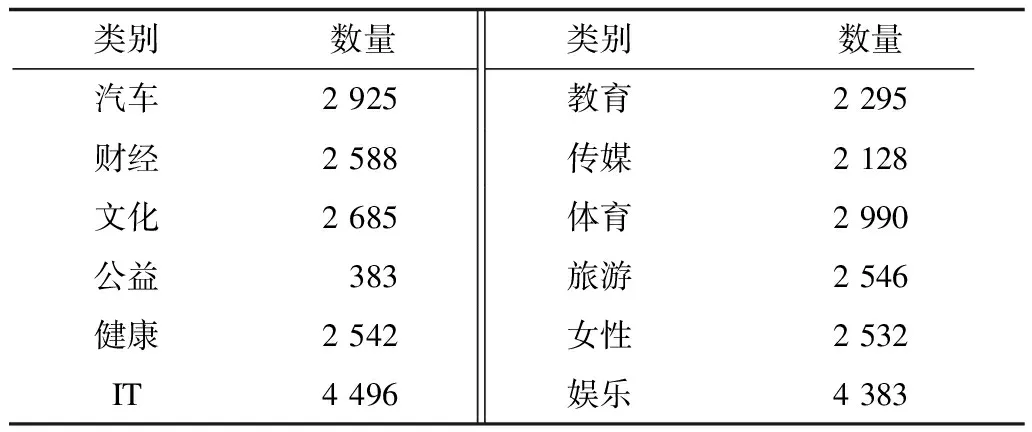
表1 Sogou语料库文本类别与数量
复旦大学文本分类语料库由该校李荣路老师整理并提供,分为20个类别,共包括9 000多个文档。其类别与文本数量分布如表2所示。
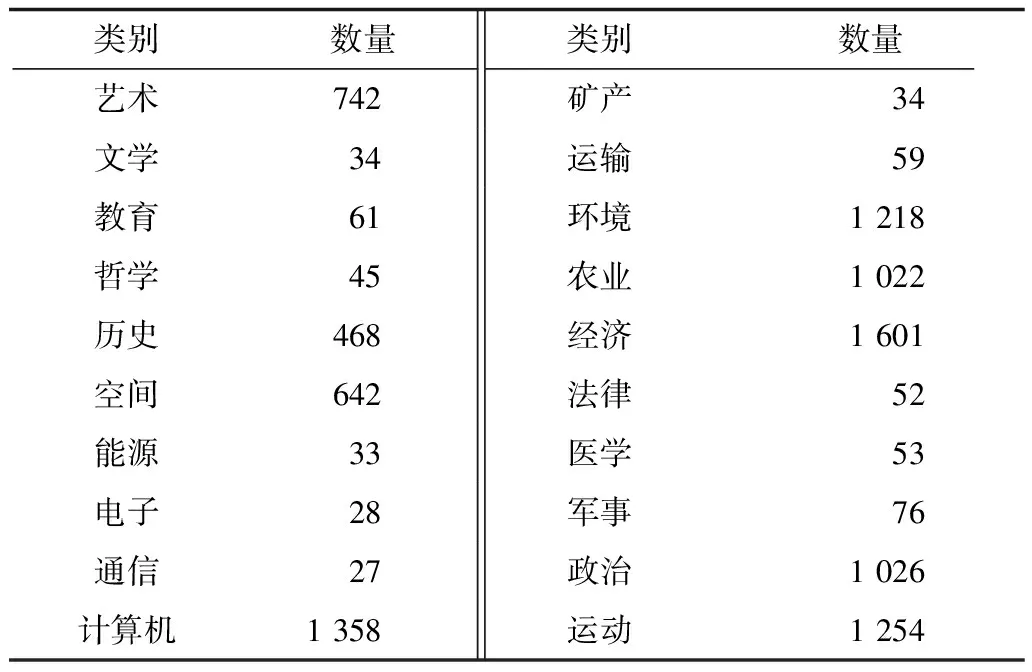
表2 复旦大学语料库文本类别与数量
由于法律、矿产等类别文本数量过少,在本次实验过程中删除了文本数量低于100的类别和文本。
4.2 实验准备与实验环境
4.2.1 词向量预训练
本次实验使用Gensim的Word2Vec进行词向量预训练,训练语料为上节所述的微信公众号文章。分词工具为jieba分词,jieba分词工具在分词过程中加入了50万词条的词典并且关闭了新词发现,该词典由网络上多个词典拼凑而成,并删除了不合理词汇。训练模型为本文第2节所述的Skip-gram,模型的词数共计352 196,基本为中文词,也包含基本的常见英文词,设置向量的维度为256,训练窗口大小为10,最小词频为64,共迭代10次,用时共计7 d,最后得出高质量的词向量。
4.2.2 模型构建环境
本次实验中的模型在Keras下进行搭建,Keras是一个高层神经网络应用程序接口(Application Program Interface,API),其由纯Python编写而成并基于TensorFlow、Theano以及CNTK后端实现。在图2中的混合模型中,可以将网络层、激活函数、损失函数以及训练过程中设定的优化器等看作一个个独立的模块,使用Keras的API即可构建图2中的模型。
4.2.3 实验环境与参数设置
本次实验的环境如表3所示,实验设置迭代次数为30。

表3 实验环境
实验设置损失函数为categorical crossentropy。为解决在学习过程中过早结束的问题,优化器设置为RMSProp,其通过引入一个衰减系数,使得每回合的衰减具有一定的比例,其参数更新规则如式(13)、式(14)所示:
Et(g2)=0.9Et-1(g2)+0.1g(θt)⊙g(θt)
(13)
(14)
其中,t=0,1,…表示迭代次数,g2表示梯度平方的向量,其每个元素为对应参数的梯度平方,取可调参数为0.9,⊙为元素乘积操作符,表示2个矩阵或向量对应位置的元素相乘,diag(v)是根据向量v生成对角矩阵的函数,d是非常小的整数,通常取值为10-8,I是单位矩阵。
4.2.4 实验评价标准
为评价本文提出的混合模型对文本分类的效果,采用文本分类领域中常用的度量标准——精确率来对模型进行检验。根据分类结果建立的混合矩阵如表4所示。

表4 分类结果混合矩阵
精确率是指正确分类的文本数与总文本数之比。一般进行分类性能评价时把精确率作为主要度量指标,其计算公式如下:
(15)
4.3 实验结果与分析
4.3.1 VDCNN与其他CNN类模型对比
在本次实验中,将本文提出的具有14层的VDCNN模型与其他CNN类模型进行文本分类效果对比,在表5中,模型使用的实验语料集均是Sogou语料库。其中,ConvNet(event)与ConvNet(event+bigram+trigram)都是改进的卷积神经网络[5],ConvNet(event)使用文本中的事件特征进行卷积,而ConvNet(event+bigram+trigram)在使用事件特征的同时,还利用二、三元词组信息进行卷积。这2种方式明确了特征提取时的特征出处,但是也易忽略同一文本中的其他特征信息,只专注于事件特征。文献[14]中的Lg.w2v Conv和Sm.w2v Conv都是对中文文本进行字符级的卷积操作,其中,w2v表示Word2Vec,Lg表示large,Sm表示small,这2种方式通过对中文进行字符级别的卷积操作进行特征提取,能有效提高分类的精确率,但是其结构和文献[5]一样,深度较浅。

表5 VDCNN与其他CNN类模型分类效果对比 %
VDCNN模型与应用于图像处理和语音识别领域的卷积神经网络类似,提高了卷积网络结构的深度(14层),并设置卷积核大小为3。但是,仅增加网络深度会导致梯度消失和准确性下降,于是本文在VDCNN中引入了捷径连接和批标准化以解决该问题。最终,VDCNN网络利用其深度优势和小的卷积核对文本中的特征进行有效提取,相对于其他方法,其能够有效提高分类精确率。
4.3.2 VDCNN与LSTM混合对文本分类的影响
在本次实验中,分别使用VDCNN模型、LSTM模型以及VDCNN和LSTM混合模型对Sogou语料库进行分类,分类效果对比如表6所示。从表6可以看出,将VDCNN与LSTM进行混合后其分类效果要优于单一的VDCNN模型和LSTM模型,这是因为在VDCNN对文本所对应的词向量进行卷积操作的过程中,忽略了一篇文章中的上下文依赖关系,而单一的LSTM模型虽然能够利用模型中的门对信息进行保存和控制,提升对上下文信息的利用,但是其层数没有VDCNN模型深,对词向量进行特征提取的能力不足。因此,将深层数、小卷积核的VDCNN模型和具有能够保存上下文信息的LSTM模型进行结合之后,能够使精确率得到提升。

表6 3种模型分类效果对比 %
4.3.3 本文混合模型和其他分类模型效果对比
在本次实验中,分别使用VDCNN与LSTM混合模型和其他分类模型对Sogou语料库和复旦大学语料库进行分类效果对比,结果分别如表7和表8所示。由表7和表8可以看出,对比模型中有些增加了注意力机制,有些在某种模型输入之前利用某种分布进行输入随机初始化,但是,这些方式只是在单一方面进行改进,对于分类效果的提升有限,而使用VDCNN与LSTM混合模型后,既利用了VDCNN超深度卷积的优势,同时也结合了LSTM模型具有保存上下文信息的优点,两者融合能够显著提高文本分类的精确率。在Sogou语料库中,文献[15]中的CLKNN模型的精确率达到96.50%,在复旦大学语料库中,LSTM模型的精确率达到91.30%,而VDCNN与LSTM混合模型在Sogou语料库和复旦大学语料库中的精确率分别达到了98.96%和93.10%,其精确率得到了明显提升。
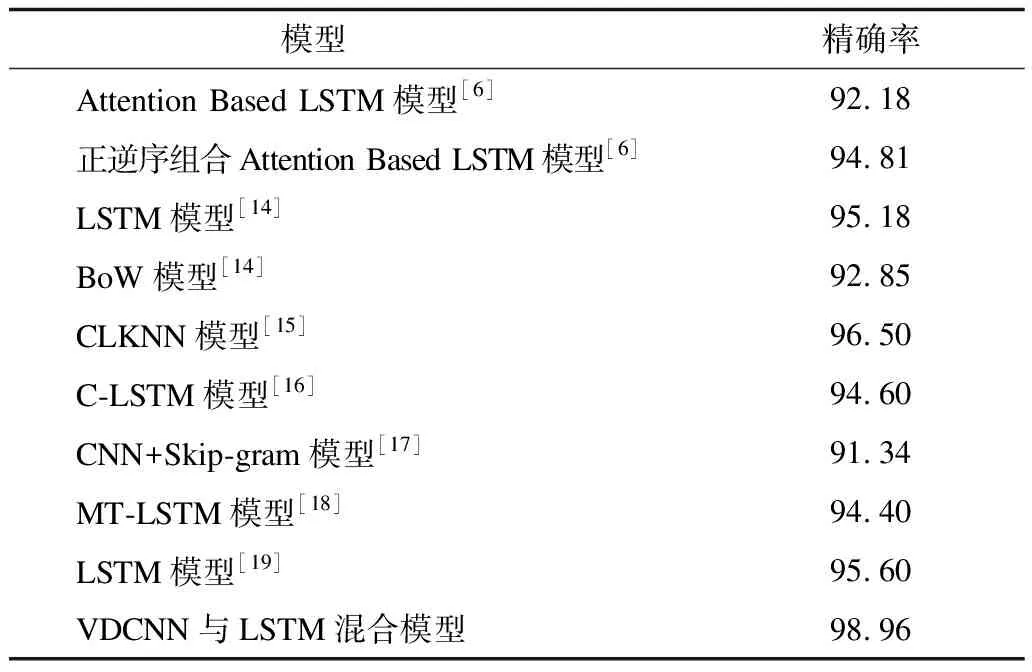
表7 不同模型在Sogou语料库中的分类效果对比 %

表8 不同模型在复旦大学语料库中的分类效果对比 %
5 结束语
本文利用词嵌入将文本转换为低维度的向量,且保证前后文中近义词的向量在向量空间中相邻,然后将VDCNN与LSTM相结合组成混合模型,以对词向量化后的文本进行分类。该混合模型既利用VDCNN超深度卷积的优势,同时也结合LSTM模型具有保存上下文信息的优点,使得其在特征提取过程中能有效提高文本分类的准确率。但本文提出的VDCNN与LSTM混合模型更注重对整篇文本进行操作,在实际文本中,根据文章的某一个中心段落或者某些关键词就可以得出文本的类别,因此,今后考虑将关键词或者注意力机制引入到本文混合模型中,以进一步提升该模型的文本分类效率和精确率。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
语言与翻译(2015年4期)2015-07-18 11:07:45
