
一种融合节点文本属性信息的网络表示学习算法
2018-11-20 06:09:02刘正铭刘树新杨奕卓
计算机工程 2018年11期
刘正铭,马 宏,刘树新,杨奕卓,李 星
(国家数字交换系统工程技术研究中心,郑州 450002)
0 概述
近年来,随着以智能终端和社交媒体为代表的各种信息渠道的出现,大数据分析技术越来越受到人们的重视[1]。社交网络、科学引文网络等复杂网络的规模不断扩大,网络数据类型复杂多样。现实网络数据的高维性、稀疏性和异质性等特点,对现有网络分析技术带来严重挑战,这使得对于网络数据的表示学习研究具有重要意义。
网络表示学习旨在将每个网络节点映射为一个低维空间的稠密向量,使得相似的网络节点在低维空间距离较近。网络表示学习通过对网络数据形式进行变换,一方面使其包含的数据信息能够更加容易提取和分析,即由人为的特征工程转化为机器的自动特征提取,另一方面有效缓解了网络数据表示的高维性、稀疏性等问题。
传统的网络表示学习模型主要是基于特定网络关系矩阵降维得到节点的向量表示[2-5],其复杂度通常是网络节点数量的二次方,同时难以融合网络节点文本属性等异质信息进行表示学习。近年来,大量研究者开始研究基于深度学习的网络表示学习方法[6-7]。文献[8]提出了DeepWalk算法,通过随机游走产生节点序列,并将节点序列看作特殊的“句子”作为Word2Vec算法[9]输入,学习节点的向量表示。文献[10]提出了LINE算法,对所有网络节点间的一阶相似性和二阶相似性进行概率建模,通过最小化该概率分布和经验分布的KL散度得到节点的向量表示。文献[11]提出了Node2Vec算法,在DeepWalk算法基础上,通过设定in、out超参数控制随机游走策略,挖掘网络结构的局部特性和全局特性。文献[12]提出了一个LsNet2Vec模型,针对大规模网络中的链路预测问题进行网络节点的表示学习。然而,上述方法都只利用了网络结构信息,忽略了网络节点属性信息。
现实的网络数据还包括丰富的网络节点属性信息,如科学引文网络中文献题目和摘要等信息。现有融合节点文本属性信息进行表示学习的算法主要有TADW算法[13],该算法将节点文本属性信息表示矩阵嵌入矩阵分解过程中实现融合表示学习。然而该算法利用TF-IDF[14]方法编码表示节点文本属性信息,忽略了文本中词的词序信息,难以有效挖掘深层语义信息。
针对上述方法的不足,本文提出一种融合节点文本属性信息的网络表示学习算法。首先,基于DeepWalk思想,将网络节点结构信息的表示学习问题转化为词的表示学习问题。其次,针对节点文本属性信息的表示学习问题,利用神经网络语言模型挖掘节点文本属性的深层语义信息。最后,为实现两方面信息的融合表示学习,提出基于参数共享机制的共耦神经网络模型进行联合训练。
1 相关概念
为更好地描述所提模型及其具体算法,首先给出相关定义及符号表示。
定义1(文本属性信息网络) 用G=(V,E,C)表示文本属性信息网络,V={v1,v2,…,vN}表示节点集合,N=|V|表示网络中的节点数量,E表示V中任意2个节点链接构成的集合E={eij|i,j=1,2,…,N},eij表示节点间的链接关系紧密程度,即链接权重,C={c1,c2,…,cN},ci表示与节点vi相关联的节点文本属性信息。

这里考虑网络节点相似性主要通过网络结构信息和网络节点文本属性信息进行刻画。也就是说在网络表示学习过程中,需要同时注意网络节点结构信息相似性保留和文本属性信息相似性保留,得到综合两方面信息的节点表示向量。
节点的表示向量φ(v)可以看作节点v的特征向量,可直接将其作为机器学习算法的输入用于后续网络分析任务,如节点分类、链路预测等。由于表示学习过程并不涉及具体网络分析任务,因此算法所得的表示向量具有广泛适用性。
2 算法实现
本节首先分别介绍刻画节点文本属性信息相似性和网络结构信息相似性的基础模型,然后基于这2种基础模型给出融合训练模型及其算法的优化求解过程,最后结合算法伪代码进行算法复杂度分析。
2.1 基础模型
2.1.1 节点文本属性信息表示学习
近年来,基于CBOW[9]神经网络语言模型的词向量表示学习方法,通过窗口上下文预测中间词,较好地保留了文本语句中的词序信息。在此基础上,文献[15]提出了用于文本向量表示的Doc2Vec算法,在很多应用中取得了较好的结果。因此,将其作为本文融合算法的基础模型之一。
如图1所示,对于任意词w,给定左右窗口大小为b的上下文词集合context(w)={w-b:wb},v(w)表示一个从词w到对应节点的映射函数,矩阵W中的每一行表示一个词对应的表示向量,矩阵UW中的每一行表示一个节点对应的文本属性信息的表示向量。

图1 节点文本属性信息表示学习模型
算法基本思想是在已知上下文context(w)和v(w)的情况下,预测到词w的概率最大。其对应最大化目标函数如下:
(1)
其中,D对应于节点文本属性信息中所有词的集合。p(w|context(w),v(w))定义为如下Softmax函数:
(2)
其中,v(u)和v′(u)表示u的表示向量及其辅助向量,xw采用累加求和的形式计算如下:
(3)
通过模型训练后,UW将作为最后所有节点的文本属性信息表示向量矩阵输出。
2.1.2 节点网络结构信息表示学习
对于网络结构信息表示学习问题,主要分为采样和训练2个阶段。在采样阶段,使用文献[8]提出的随机游走策略捕捉网络结构信息。从任意节点vi出发,随机游走固定长度l得到随机游走序列S={vi,vi+1,vi+2,…,vi+l}作为训练集。在训练阶段,将随机游走序列看作特殊的“句子”,作为CBOW模型[10]的输入,学习节点向量表示。如图2所示,对于任意节点v,假设给定左右窗口大小为b的上下文节点集合为context(v)={v-b:vb},矩阵US中的每一行表示一个节点对应的网络结构信息的表示向量。
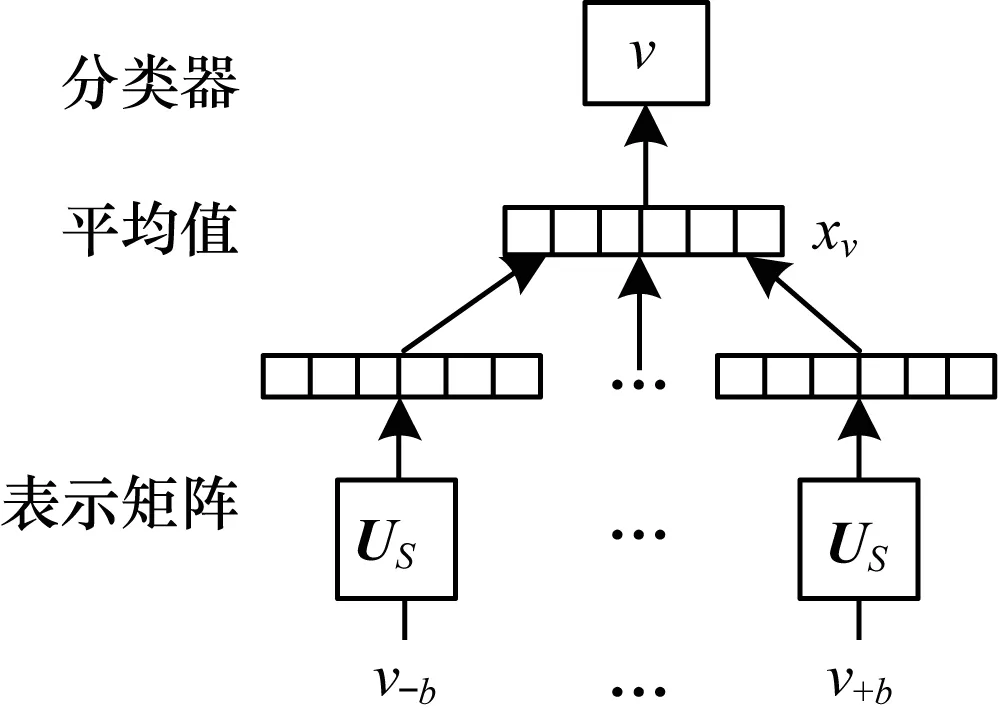
图2 网络结构信息表示学习模型
与第2.1.1节类似,在已知上下文context(v)的情况下,预测到节点v的概率最大,其对应最大化目标函数为:
(4)
其中,V是所有节点的集合。p(v|context(v))定义为如下Softmax函数:
(5)
这里xv采用累加求和的形式计算如下:
(6)
通过模型训练后,US将作为最后所有节点的网络结构信息表示向量矩阵输出。
2.2 融合表示学习模型及其算法优化
为实现节点网络结构信息和文本属性信息的融合表示,最简单的方法就是拼接。如图3(a)所示,记通过文本属性信息表示学习模型训练得到的表示矩阵为UW,通过网络结构信息表示学习模型训练得到的表示矩阵为US,直接拼接得到最终的节点表示向量矩阵U+,即U+=UW⊕US,然而这种方法由于UW和US在训练过程中相互独立,属于训练后结合,缺少了两方面信息在训练过程中的相互补充与制约。因此,提出基于参数共享的交叉训练机制实现融合表示学习,如图3(b)所示。首先,使用融合表示向量矩阵U替换基础模型中的UW和US,建立共耦神经网络模型,如图4所示。

图3 2种节点文本属性的融合方案

图4 融合节点文本属性信息的表示学习模型
左右两部分的表示学习模型交替训练,U由2个模型共享,即U在训练过程中相互传递。最后,通过反复迭代,得到融合两方面信息的节点向量表示,其对应的最大化目标函数为:
(7)
其直观解释是:一方面融合表示向量和上下文词向量一起用于预测中间词w,使得融合表示向量包含节点文本属性信息;另一方面融合表示向量又参与节点网络结构信息的表示学习训练,通过节点网络结构信息修正融合表示向量。在反复迭代过程中,实现两方面信息的相互补充与制约。
采用随机梯度上升方法进行迭代训练,考虑到计算式(2)和式(5)时需要分别遍历整个词集合与节点集合,不适合在大规模网络的实际应用,文献[16]提出了基于负采样(Negative Sampling,NEG)的优化策略用于降低计算复杂度,给出式(5)的近似表示如下:
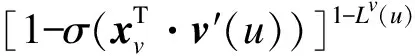
(8)
其中,Lv(u)为0-1判决函数,当u=v时,Lv(u)=1,否则Lv(u)=0,σ(x)=1/(1+e-x)。NEG(v)表示正样本(v,context(v))对应的负样本集。从式(8)不难看出,负采样的基本思想是最大化正样本出现概率的同时最小化负样本出现概率。
下面进一步推导表示向量的更新公式,将式(8)带入式(4)中可得:
(9)
为求导方便,记式(9)两次求和项如下:
(10)
首先考虑LS(v,u)关于v′(u)的梯度,推导如下:
(11)
同理,可求出LS(v,u)关于xv的梯度如下:
(12)
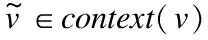
(13)
u∈{v}∪NEG(v)
(14)
对于节点文本属性信息表示学习模型的计算方法类似,在此不再赘述,直接给出最后的更新公式。
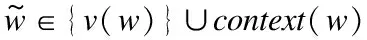
(15)
u∈{w}∪NEG(w)
(16)
2.3 融合算法流程及其复杂度分析
融合算法伪代码如下:
算法1融合节点文本属性信息的网络表示学习算法
输入信息网络G=(V,E,C),迭代次数r,表示向量维度d,采样窗口左右大小b,随机游走长度l,随机游走次数r′,负采样样本数k
输出节点融合表示向量矩阵U,每一行对应节点表示向量v(u),u∈V
训练数据集采样步骤
1.对于节点文本属性信息,给定参数(b),以采样窗口大小b采样文本信息,构成文本属性信息训练集{(w,context(w),v(w),NEG(w))}。
2.对于网络结构信息,给定参数(l,b,r′,k),首先通过随机游走产生节点序列集合,再以采样窗口大小b采样节点序列,构成网络结构信息训练集{(v,context(v),NEG(v))}。
迭代训练步骤如下:
3.for iter=1 to r
4.for w in D
5.random sample(w,context(w),v(w),NEG(w))
6.update=0
8.for u in {w}∪NEG(w)
10.update=update+delta·v′(u)
11.v′(u)=v′(u)+delta·xw//辅助向量更新
end
12.for u in {v(w)}∪context(w)
13.v(u)=v(u)+update//表示向量更新(词向量及节
//点融合表示向量)
14.end
15.end
16.forvin V
17.random sample (v,context(v),NEG(v))
18.update=0
20.for u in {v}∪NEG(v)
22.update=update+delta·v′(u)
23.v′(u)=v′(u)+delta·xv//辅助向量更新
24.end
25.for u in context(v)
26.v(u)=v(u)+update//表示向量更新(节点融合表
//示向量)
27.end
28.end
29.end
下面结合算法伪代码(算法1)分析算法流程并讨论其复杂度问题。
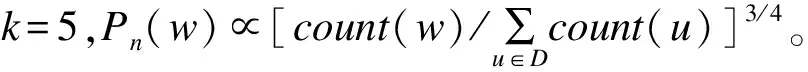
其次,对于迭代训练部分,一方面使用随机梯度上升法(对应求极大值)作为优化更新策略,式(13)~式(16)给出了向量更新公式;另一方面基于参数共享策略进行交叉迭代训练:步骤4~步骤15实现了节点文本属性信息的表示学习,步骤16~步骤29实现了网络结构信息的表示学习,由于节点融合表示向量在两部分模型中相互传递,使得在训练过程中受到两方面信息的相互补充与制约。迭代过程中,对于给定的词w,在负采样策略下,计算次数从式(3)的|D|(语料库大小)次减少到1+k次。
最后,分析算法的整体复杂度问题。在单次迭代过程中,对于给定词w,在负采样策略下,计算次数从式(3)的|D|(语料库大小)次减少到1+k次。遍历词集合,计算次数为|D|·(1+k)次。同理,对于给定节点v,遍历节点集,计算次数为|V|·(1+k)次。因此,迭代r次后,整体计算复杂度为ο(r·(|D|+|V|)·(1+k))。在实际应用场景中,由于r,k<<|D|,|V|,因此算法计算时间复杂度和网络规模成线性比例关系,算法可扩展到大规模场景的实际应用。
3 实验验证与分析
为验证本文提出算法的有效性,在2个公开数据集上与具有代表性的表示学习算法进行对比。
3.1 实验数据集
DBLP数据集来源于AMiner网站公开数据集。本文抽取其中4个知名国际会议论文数据(CIKM,KDD,IJCAI,CVPR),将论文作为网络节点,标题信息作为节点文本属性信息,利用引用关系构建引文网络,包含节点18 223个,连边15 867条,4类节点标签对应不同的会议论文集。
CiteSeer-M10数据集来源于CiteSeerX网站中抽取的数据集。本文将文献[17]从该网站中抽取的包含10个方向论文引用关系的数据集作为实验数据集。将论文作为网络节点,标题信息作为节点文本属性信息,利用引用关系构建引文网络,包含节点10 310个,连边77 218条,10类节点标签对应不同方向的论文集。
3.2 对比算法
将对比算法分为3类:1)仅利用节点文本属性信息;2)仅利用网络结构信息;3)同时利用两方面信息的融合算法。
下面简要介绍对比算法:
1)Doc2Vec算法:仅利用节点文本属性信息进行表示学习。
2)DeepWalk算法:仅利用网络结构信息进行表示学习。
3)DW+D2V算法:将Doc2Vec算法和DeepWalk算法学习的表示向量进行拼接,使得到的节点表示向量既包含文本属性信息又包含网络结构信息。
4)TADW算法:通过矩阵分解的形式,直接利用节点文本属性信息和网络结构信息得到节点表示向量。
本文算法的主要参数设定为表示向量维度d=200,迭代次数r=10,其余参数设定为对应子结构的原始文献给出的建议值:文献[15]中的Doc2Vec算法设定文本属性信息表示学习窗口大小为10;文献[8]根据DeepWalk算法对随机游走的讨论,设定游走长度l=40,窗口大小为10,游走次数r′=80。为保持一致,各对比算法维度都设置为d=200。
3.3 评测任务及其指标
评测方法与文献[11,13]类似,首先进行无监督的表示学习,然后将其用在多标签分类任务中,比较不同算法的性能。基本思想是具有较好标签预测能力的表示学习算法能够更加准确地从原始网络数据中提取节点特征向量表示。由于评测数据集是多分类问题,因此在评价指标选择问题上,先在各混淆矩阵上分别计算准确率和召回率,记为(P1,R1),(P2,R2),…,(Pn,Rn),再计算平均值,得到宏准确率(Macro_P)、宏召回率(Macro_R)及相应的宏F值(Macro_F):
(17)
(18)
(19)
为方便进行算法比较,与文献[11,13]一致,统一采用SVM线性分类器进行节点分类任务,排除不同分类器对节点分类性能造成影响的情况。为考察算法在不同监督信息量情况下的标签预测性能,随机取训练集大小从10%~90%,剩余部分作为测试集,重复10次取结果平均值。实验流程如图5所示。

图5 实验流程
3.4 实验结果分析
图6和图7分别记录了在DBLP和CiteSeer-M10数据集上的不同训练率下(10%~90%,间隔20%进行测试)的3种节点分类性能指标结果,即宏准确率、宏召回率和宏F值。实验结果显示,本文所提算法的节点分类性能高于比较算法。
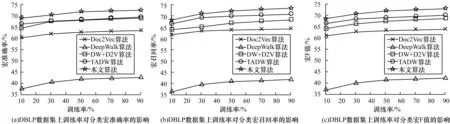
图6 DBLP数据集上的分类结果

图7 CiteSeer-M10数据集上的分类结果
下面从两方面分析实验结果:
1)融合算法优势明显。Doc2Vec算法和DeepWalk算法分别挖掘了节点文本属性信息和结构信息,但效果都较为普通。基于简单拼接的DW+D2V算法性能进一步提升,但是相比于融合模型仍然有提升空间。在30%的训练率情况下,在DBLP网络中,本文算法的分类宏F值比DW+D2V算法提高了4.3%,比融合算法TADW提高了2.2%;在CiteSeer-M10网络中,本文算法的分类宏F值比DW+D2V算法提高了11%,比融合算法TADW提高了3.8%。
2)神经网络特征挖掘优势明显。和通过矩阵分解方式进行融合表示的TADW算法相比,基于共耦神经网络的本文算法平均节点分类准确率在DBLP和CiteSeer-M10网络中分别达到68%和71%,比TADW算法分别提高了3%和3.6%。作为本文算法子结构的Doc2Vec文本表示学习算法仅依赖节点文本属性信息的情况下就达到较好的节点分类效果。如图6(a)和图7(a)所示,在30%训练率下,在DBLP和CiteSeer-M10网络上的节点分类准确率分别达到61.9%和47.9%。这一方面说明结合文本属性信息的重要性,另一方面也说明了神经语言模型在挖掘文本语义信息方面的巨大优势,这也是结合神经语言模型改进网络表示学习算法的初衷。
3.5 算法参数敏感性分析
本文算法包含了表示向量维度d和融合算法迭代次数r这2个主要超参数,本节将通过实验分析超参数的选择对算法用于多标签节点分类问题性能好坏的影响。通过改变参数取值,得到不同的节点表示向量。按照图5的实验流程,在30%训练率的情况下,测试不同的节点表示向量对多标签节点分类问题性能指标宏F值的影响,实验结果如图8所示。图8(a)表示了改变表示向量维度d对算法分类预测性能的影响,d取值从50~300,每间隔50进行一次实验。随着表示向量维度的增加,分类预测宏F值逐渐增加,说明了较高维度能够捕获更多的网络信息,形成更具区分性的网络表示。然而同时也注意到,表示维度增加到200维以后,分类预测宏F值有所下降。这说明采用过多的表示向量维度衡量网络节点相似性,减少了具有重要区分度特征的权重影响,反而导致性能损失。因此,200维的表示向量维度较为合适。图8(b)是改变算法迭代次数r对算法分类预测性能的影响,将迭代次数变化范围设置为2~12,间隔2次进行一次实验。随着迭代次数的增加,分类预测宏F值明显提升,体现了交叉训练过程中两方面信息的相互补充。迭代次数超过10次以后,分类预测性能趋于稳定,说明融合模型能够挖掘的网络信息趋于稳定。因此,迭代次数超过10次后停止迭代更新。

图8 超参数对算法分类性能指标宏F值的影响结果
4 结束语
本文基于神经语言模型提出了一个结合节点文本属性信息的网络表示学习算法,实现了节点文本属性信息和网络结构信息的融合表示学习。针对文本属性信息和网络结构信息等异质信息难以有效融合表示的问题,给出基于参数共享的共耦神经网络模型用于融合训练。在2个真实世界网络数据集上的实验结果表明,该算法有效实现了融合表示学习,在面向节点分类的评测任务中,算法性能有一定提升。算法复杂度与网络规模大小成线性比例关系,能够适用于大数据时代背景下的大规模复杂信息网络的表示学习问题。然而,该算法仅考虑了节点文本属性信息,下一步将针对实际网络中存在的图像信息、语音信息等其他异质信息对算法进行优化。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
新高考·高一数学(2022年3期)2022-04-28 07:02:46
国际眼科杂志(2021年9期)2021-09-15 03:24:42
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
装备制造技术(2020年2期)2020-12-14 03:09:16
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
