
异构信号处理平台中层次性流水线调度算法
2018-11-20 06:08:46杨平平岳春生胡泽明
计算机工程 2018年11期
杨平平,岳春生,胡泽明
(信息工程大学 信息系统工程学院,郑州 450001)
0 概述
随着无线通信技术的快速发展,任务计算和数据信号的处理量出现爆炸式增长,对通信装备平台的快速研发、实时处理能力提出更高要求,使得软件无线电[1]平台成为了研究热点。目前,通用软件无线电平台有加泰罗尼亚大学的ALOE[2]、爱尔兰圣三一学院的IRIS[3]和中国微软研究院的SORA[4]等,这些平台在信号处理方面应用较少,而且弗吉尼亚理工学院研究的OSSIE[5]和被誉为“黑客无线电”的GNU Radio[6]只能用来完成通信系统的建模和仿真学习[7]。异构信号处理平台通过软件和硬件的解耦,解决了不同平台间的可移植性和可扩展性等问题,充分利用了异构可重构特性。但是当前大多数实时任务调度算法是针对同构系统提出的,对于异构系统的实时调度算法研究还不成熟,需要进一步深入研究[8]。
异构平台相比于同构平台,由于其处理节点的异构性,提高了平台处理复杂任务的灵活性和效率。异构和同构平台算法的不同之处主要在于任务划分阶段,即建立任务模型有无考虑处理节点的异构性带来的影响。异构平台的实时调度本质上就是资源映射和任务调度,在满足任务约束关系的前提下,对任务进行合理的划分,实现资源的负载均衡,减少任务的调度长度,同时构造低延迟的流水线调度,提高任务调度的实时性。
层次性流水线调度包括多层次任务划分和同步流水线调度。文献[9-10]提出一种应用于ALOE框架的资源映射算法,利用框架的同步机制和流水线调度[11],能够保证应用的服务质量,但该算法缺少对任务粒度划分的研究。文献[12-13]研究一种面向多核处理器实时数据流的低通信软件流水调度方法,利用整数线性规划理论对通信和计算资源进行统一建模,但该方法没有考虑分布式环境对调度的影响,缺少对网络拓扑和层次性任务并行优化的研究。文献[14]提出一种面向多核集群的数据流层次流水线并行优化方法,利用任务中的并行性构造低延迟流水线调度,但该方法针对同构集群采用的是均衡划分策略,在任务划分时没有考虑节点计算能力和节点间的通信速率。文献[15]针对异构计算中的非均衡划分问题,提出一种基于图的多级划分算法,利用处理器计算性能的不同将图与节点计算能力成比例划分,然而,该算法没有考虑任务间的依赖关系。
现有流水线调度算法在任务划分时未考虑硬件体系结构,即处理器节点的计算性能和通信带宽资源带来的影响。本文根据异构信号处理平台实时任务的特点,提出层次性流水线调度方法。针对异构信号处理平台的任务划分,提出负载均衡低通信同步开销的多层次划分算法;在平台对已有的事件触发调度实时处理能力不强的情况下,采用低延迟的同步流水线调度。最后在ATCA平台下,以雷达等典型应用为测试程序,验证该层次性流水线调度算法的有效性。
1 系统描述
1.1 异构信号处理平台
异构信号处理平台是将模块化、标准化和通用化的硬件单元以总线或交换方式连接起来构成通用平台,通过在平台上加载可复用、可移植、可扩展和易升级的标准化软件模块,实现各种信号处理功能[16]。异构信号处理平台在硬件体系架构上采用通用的高性能硬件平台,如ATCA、CPCI、VPX等,平台内存在大量不同类型的处理器,包括FPGA、DSP、GPU、GPP等。在软件架构上通过构建标准化、规范化的层次式新型软件体系架构,通过系统抽象屏蔽底层之间的差异,解决组件在异构平台中跨平台操作和可移植性的难点。异构信号处理平台软件体系架构如图1所示。
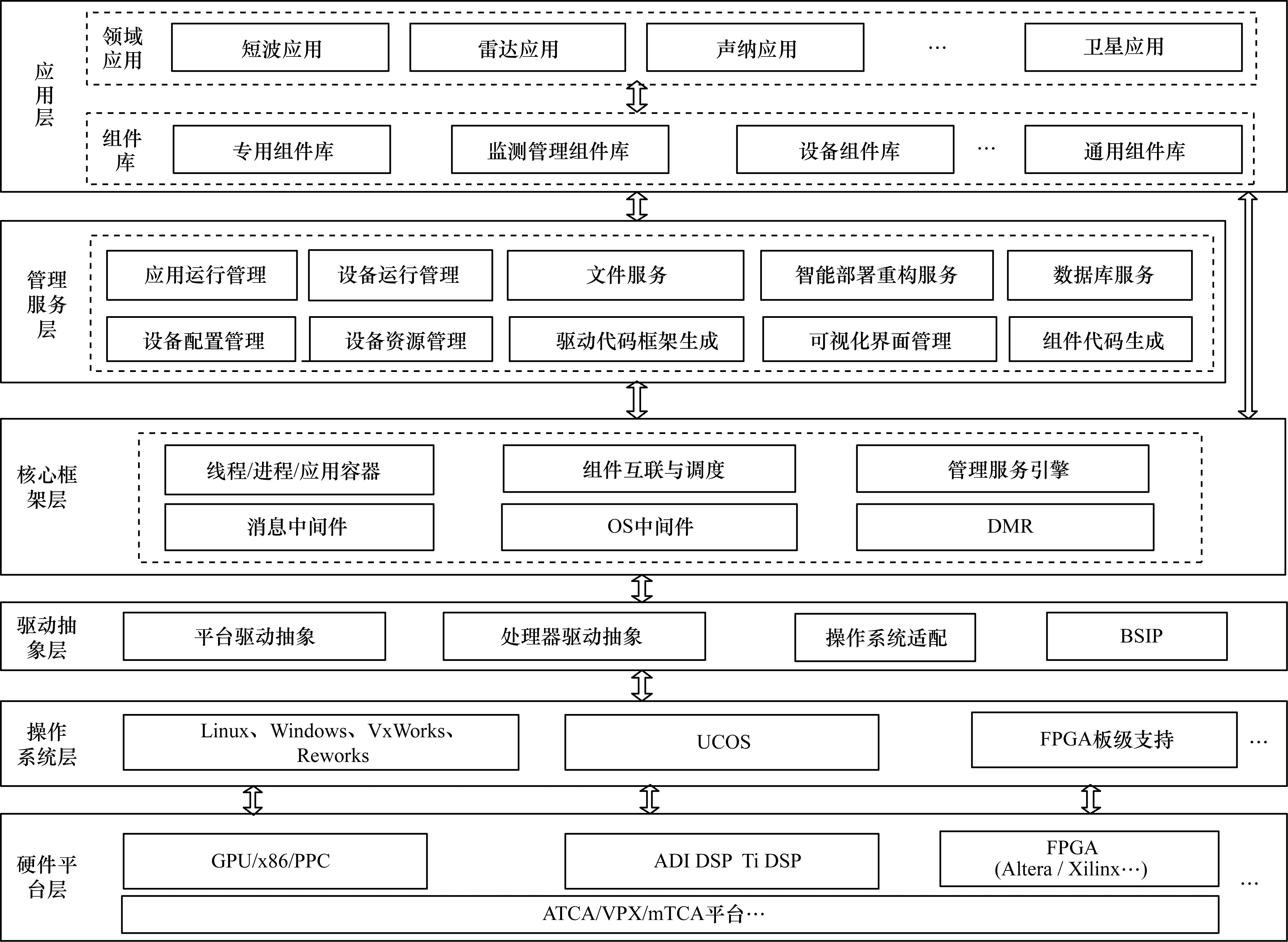
图1 层次化新型信号处理平台软件体系架构
图1所示的异构信号处理平台软件体系架构主要分为硬件平台层、操作系统层、驱动抽象层、核心框架层、管理服务层和应用层。其中,操作系统层与驱动抽象层属于运行支撑服务层,能够屏蔽底层处理单元的操作系统、通信、内存及文件操作等硬件差异性,为上层提供统一规范的接口;核心框架层基于容器技术(包括FPGA容器、进程容器、线程容器等)屏蔽处理器任务调度上的差异,实现应用组件化调度服务;管理服务层包括系统运行管理环境和可视开发管理两大部分,提高应用系统开发的可视性以及便捷性;应用层包括组件库和应用控制台,负责完成信号处理功能。目前,异构信号处理平台的开发模式已经成为一种发展趋势。
1.2 异构信号处理平台任务模型
本文利用有向无环图(Directed Acyclic Graph,DAG)描述异构信号处理平台应用的处理流程,数据流程图中节点和有向边分别代表应用的组件和通信链路。软件无线电应用可分解为一系列具有相互依赖关系、周期性执行、可部署的软件模块或组件[17]。各软件模块之间存在数据流水依赖性,其中,某个组件的输出可以是相应下一步组件的输入,因此,系统模型可用一个四元数组表示,记为G={V,E,C,L}。其中,G代表平台的一个应用,V={v1,v2,…,vn}是应用所包含组件的集合,节点vi∈V表示应用中的一个组件,E={e12,e23,…,eij}表示依赖关系的有向边的集合,E⊆V×V,eij=(vi,vj)∈E表示组件vi和组件vj有直接通信链接,组件vi是组件vj的前驱节点,C={c1,c2,…,cn}表示组件的计算量集合,C(vi)表示组件vi的计算数据量,L(vi,vj)表示组件间的通信量集合。如图2所示,每一个应用都可以用DAG来表示。
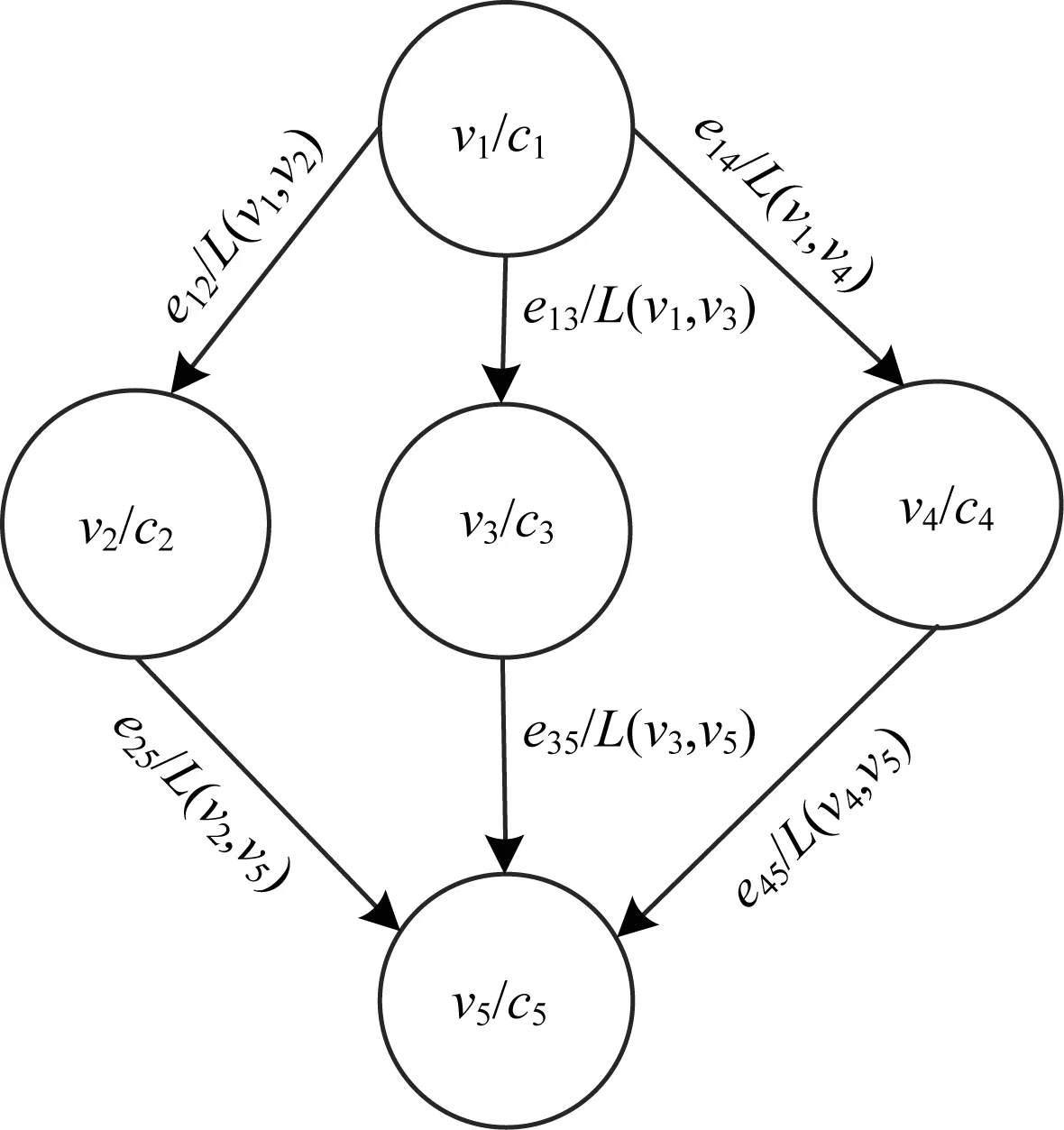
图2 应用的DAG示意图
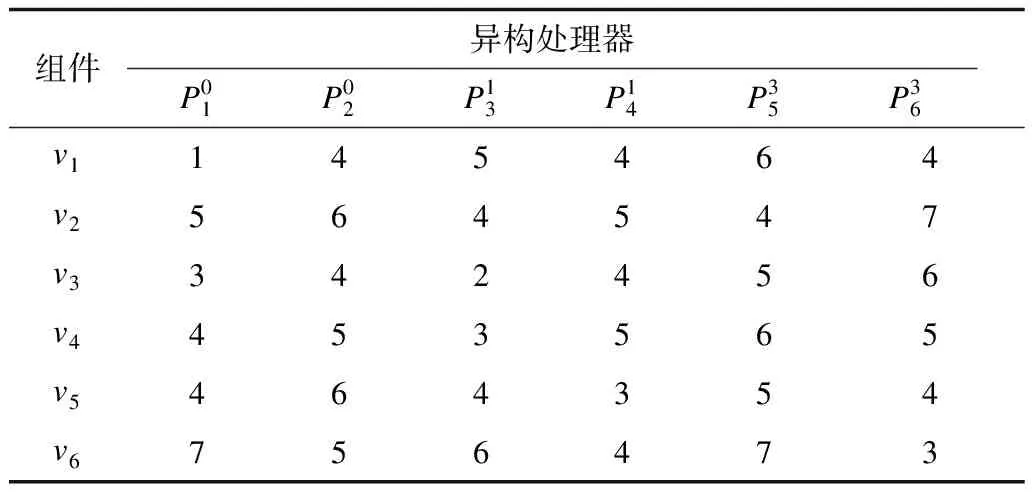
表1 异构信号处理平台任务执行时间
2 异构信号处理平台实时任务调度策略
2.1 基于DAG的多层次任务划分方法
任务划分是实时调度的首要步骤,快速有效的划分方法是调度成功的关键。本文提出的基于DAG多层次划分算法借鉴了多层图划分的思想,主要由3个阶段组成:对DAG进行分层拓扑排序,顺序融合分组进行初始划分以及局部非均衡聚簇。任务划分的目的是为了保证节点间的负载均衡性,减少节点间的同步开销,构造低延迟高吞吐率的流水线调度。
2.1.1 DAG的分层拓扑排序
分层拓扑排序是对DAG进行预处理。由图论可知,有向无环图节点存在入度值,入度值指的是邻接到某顶点弧的数目。预处理是根据节点的入度值,将有向无环图分成多层,每层的组件没有数据依赖关系的节点,可以进行并行处理。
DAG分层算法描述如下:
算法1任务分层算法
输入原始DAGG(V,E)
输出经过分层后的DAGG:(V,E)
Void TopologicalSort (int Num); {//节点数目
Int gInDegree[MAX_NODE];
FindInDegree();//对各顶点求入度值
IniStack(S);//建立入度值顶点栈
for( int i = 0; i < Num; i++ )
if (! gInDegree[i] )
push (S,i);
//入度为0者进栈,k层
While(! StackEmpty(S)){
pop(S,i);
gVisited [i] = true;//输出i节点
for( int e = gHead[i]; e!= -1; e = gEdges[e].next){
int v = gEdges[e].to;
gInDegree[v]--;
//对i顶点的每个邻节点的入度值减1
if ( ! gInDegree[v] ){
push (S,v);
//如果入度值减为0,则入栈,k+1层
}// END IF
}//END FOR
}//END WHILE
for (int i =0; i < Num; i++)
if(!gVisited [i]) return ERROR; //存在回路
}//输出分层结果
图3所示为DAG分层拓扑排序处理的示例,其中,图3(a)为一个异构信号处理平台应用的DAG映射到处理器的示例,Vi表示组件,权值为组件在处理器上的执行时间,图3(b)描述了经过任务分层后的DAG。首先计算图3(a)中各个顶点的入度值,将所有入度值为0的节点放在第k层,然后将上一层顶点的所有边消除,再计算新图入度值为0的顶点,放入第k+1层,直到DAG中不存在入度值为0的节点。分层拓扑排序可以检测DAG中是否出现环路,防止执行时出现死锁。
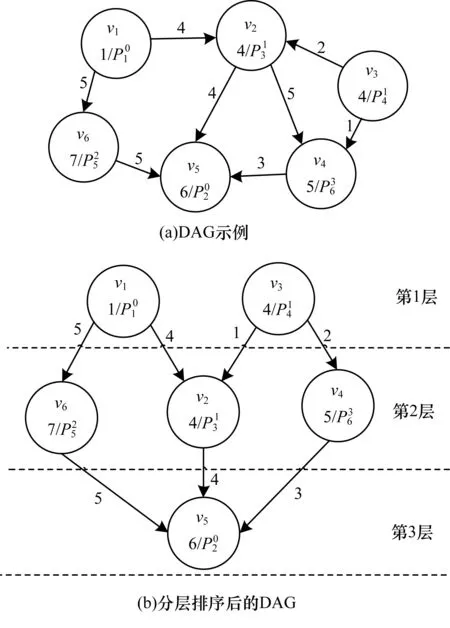
图3 DAG分层拓扑排序示例
2.1.2 顺序融合聚簇算法
顺序融合聚簇是对分层处理后的DAG进行初始划分,将相邻的节点进行融合。任务划分粒度越小,子任务数越多,并行程度越高,但通信开销就越大;相反,任务划分粒度越大,通信开销越少,但并行度就越小。顺序融合聚簇方法是消除通信延迟划分算法中的一种,其将相邻节点融合可以降低通信开销的收益,但有可能会丧失后驱节点的并行性。因此,顺序融合聚簇时要尽量使任务之间的通信开销减小,又同时保持任务自身并行性以及预防出现环路情况。本文采用文献[14]的DAG粗粒度融合方法,将相邻节点融合产生的收益定义为:
(1)
其中,任务模型中的元素L(vi,vj)、C(vi)、C(vj)分别表示组件间的通信量、组件vi的计算量(即负载)和组件vj的计算量。
顺序融合算法描述如下:
算法2顺序融合算法
输入经过分层后的DAGG:(V,E)
输出经过顺序融合后的DAGG:(V,E)
Graph G =ConstructGraph(DAG);
VertexNum = Count(G);//当前节点数
averageWorkload = Weight(DAG)/ClusterNum;
// 理论上平均最佳负载
priorityQueue = ConstructpriorityQueue(G);
//收益为权值的优先队列
While(VertexNum > ClusterNum){
MaxGain = GetMaxGain(priorityQueue);
//优先队列中选择收益最大的融合
If(maxGain<=0)break;
Pair
GetMaxGainCluster(priorityQueue,G);
ClusterWeight =Weight(cluster);
//计算当前cluster的负载
If(ClusterWeight < averageWoekload && ErrorDAG) //当前相邻节点融合负载小于划分后理论平均负载值且新//DAG没有环路
PriorityQueue.delete(maxGainCluster);
//优先队列删除最大收益值
newVertexr = Fused(Vi,Vj);
//融合后的新节点
G.update(Vi,Vj,newVertex);//更新DAG
PriorityQueue.update(maxGainCluster,
newVertexr);//更新收益优先队列
-- VertexNum;
}//END WHILE
ClusterNum是对节点数量设置的下限阈值,防止过度融合。顺序融合算法首先计算理论上的平均最佳负载,采用贪心算法计算相邻节点融合的收益,并构造以收益为权值的优先队列。然后,从队列中选择收益最大的相邻节点进行融合,计算融合后节点的负载,如果当前融合后的负载小于划分后理论平均负载且新DAG没有环路,那么就将参与融合的相邻节点删除,插入融合后的新节点并更新DAG,最后更新收益优先队列。算法经过多次迭代,当收益为负或者DAG中的节点数小于下限阈值时,DAG中节点停止融合。图4所示为DAG多层次划分处理的示例,其中,图4(a)中的节点vi表示组件,权值为组件的负载,图4(b)描述了经过融合后的DAG。
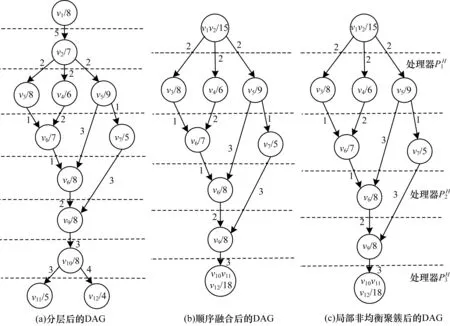
图4 DAG多层次划分示例
2.1.3 局部非均衡划分算法
局部非均衡划分算法考虑到异构信号处理平台中处理器的计算能力不同,为保证任务实时调度适应更广泛意义上的异构负载均衡,任务粒度划分要随计算能力成正比例改变。局部非均衡算法要尽量保证任务间通信开销减小,注意预防执行死锁。
由表1可知,异构处理器的计算能力影响任务的执行时间,本文采用文献[15]的计算方法来表示处理器的计算能力。在异构信号处理平台中,单个处理器的计算能力(Computing Power,CP)是一个综合量,主要包括I/O、内存读写、处理器、网络通信开销。因此,单个处理器的计算能力可以定义为:
(2)
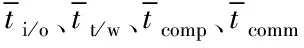
局部非均衡聚簇算法描述如下:
算法3局部非均衡聚簇算法
输入经过顺序融合后的DAGG:(V,E),initPartition Map(G)
输出经过非均衡聚簇后的DAGG:(V,E)
ProcessNum = Count(P);//实际处理器个数
PriorityQueue_CP = ConstructpriorityQueue(CP);
//构造以处理器计算能力为权值的优先队列
PriorityQueue_Workload=ConstructpriorityQueue(G);
//构造以任务负载为权值的优先队列
Match(PriorityQueue_CP,PriorityQueue_Workload);
//将处理器的计算能力与任务的负载进行匹配
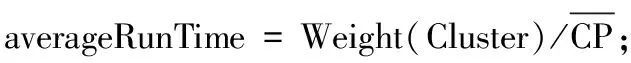
//计算理论上平均最佳执行时间(即最佳同步周期)
TopologicalSort[]=ConstructClusterTopoLogicSort(G);
//构造聚簇拓扑排序,进行划分
Int curPartitionNo = 0;//当前的划分编号
While(SearchClusterTopoLogicSort(G)){
//依次遍历DAG中分簇节点
CurPartitionWorkload=Weight(Vertex)+
Weight(curPatitionNo);
If(Weight(curPartitionWorkload)< averageRunTime×matched(CP)){
//根据任务负载量匹配相应的处理器
initPartitionMap.insert(curPartitionNo,Vertex);
//当前负载不足,添加节点
}//END IF
else
++curPartitionNo;
G.update(newVertex);//更新DAG
}//END WHLIE
局部非均衡划分算法首先计算所有节点的负载以及系统中各个处理器的计算能力,构造相对应的优先队列。然后,将队列中任务的负载与处理器计算能力进行匹配,计算理论上平均最佳执行时间(即最佳同步周期),对DAG进行拓扑排序,依次遍历DAG中的节点,确定各个簇的划分编号。最后,根据子任务负载情况匹配相应的处理器,对后驱节点依次进行融合,如果融合后形成新节点的负载小于最佳时间乘以处理器计算能力的值,那么添加节点,反复迭代上述过程直到确定划分的编号。经过非均衡划分后的DAG见图4(c)。
2.2 同步流水线调度
异构信号处理平台采用同步流水线调度作为调度模型。同步流水线调度根据应用组件的依赖关系,将一个应用分割成若干个流水线阶段,同一阶段内的组件是相互独立的,同时采用全局同步时钟保证流水线各个执行阶段具有相同的时间片。在任一时间片内,组件最多只能执行一次处理任务,同时将数据传输到后驱组件,后驱组件要等待下一个时间片,才能处理前驱组件的输出数据。因此,同步流水线调度利用时间片消除了组件间前后依赖关系,实现了组件的并行执行。
同步流水线调度的性能取决于执行时间最长的组件,因此,任务划分的负载均衡至关重要。图5所示为软件无线电应用分配到2个处理器的同步流水线调度,其中,应用包含4个组件V={V1,V2,V3,V4},V1和V2分配到处理器P1,V3和V4分配到处理器P2。图5的调度流程存在透明的组件,表示组件尚未激活,其中,组件V2和V3是组件V1的后驱节点,是组件V4的前驱节点,因此整个应用被分割成3个不同的流水阶段。当应用经过3个时间片时,流水线进入满状态,此时同步流水线能够产生高吞吐量。
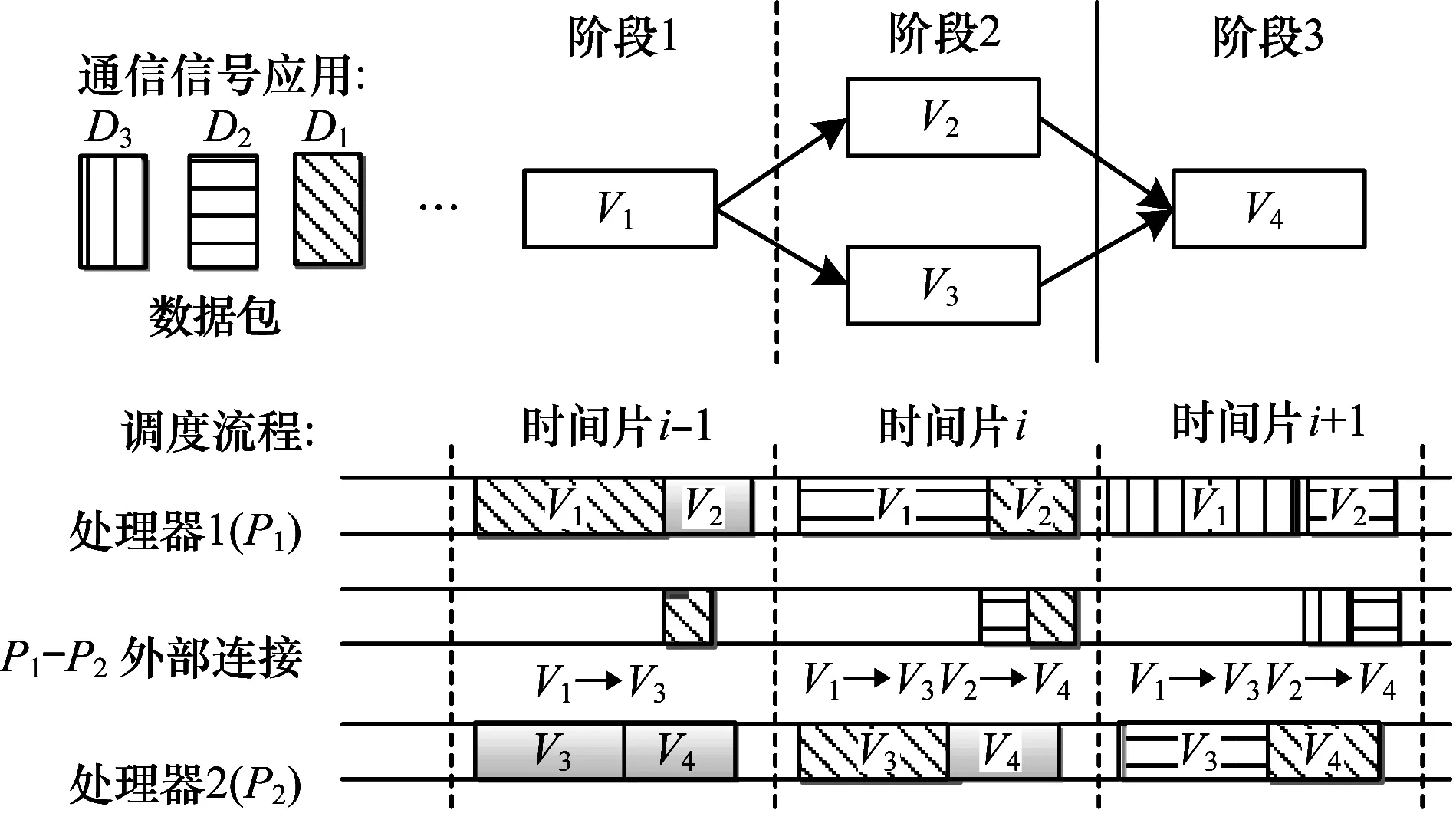
图5 应用分配到2个处理器时的流水线调度
2.3 调度策略分析
异构信号处理平台的实时任务调度策略主要包括多层次任务划分和同步流水线调度。本文提出的基于DAG的多层次任务划分算法借鉴多层图划分的思想并对其进行改进,同时考虑任务之间的数据依赖关系、节点的异构性以及处理器间的通信速率。预处理阶段的目的是对DAG进行分层排序,使同层上的任务可以进行并行处理。初始划分阶段的顺序融合聚簇算法,采用贪心算法计算融合收益,减小通信开销。非均衡划分阶段考虑到节点的计算能力不同,采用广度优先搜索算法进行任务匹配,保证粒度划分与节点计算能力成正比例改变,确定划分后的簇与处理器之间的映射,实现了任务的负载均衡和低通信同步开销。最后采用同步流水线调度方法,实现节点的并行执行,达到了数据低延迟实时处理的目的。
3 实验与性能分析
本文采用异构信号处理平台来测试多层次划分算法以及同步流水线调度的性能。异构信号平台由通用PC平台和高性能ATCA平台组成,2个平台通过网线互连形成局域网,其中,PC是域管理器客户端,用于组件的开发和应用的搭建;ATCA是运行平台,主要实现应用的软件功能,对应用进行实际处理。在恒为公司ATCA平台内,插有计算刀片、承载板以及AMC-FPGA 3种板卡,计算刀片内存在GPP处理器,运行Windows Server 2008操作系统,AMC-FPGA板卡内存在DSP处理器,移植μC/OS II操作系统,以及一块Kintex-7 FPGA处理器。平台内计算刀片板卡和承载板内通信协议为万兆网,板卡间通信协议也为万兆网,AMC-FPGA板卡内处理器FPGA与DSP之间通过RAPID I/O总线相连,其性能参数配置如表2所示。
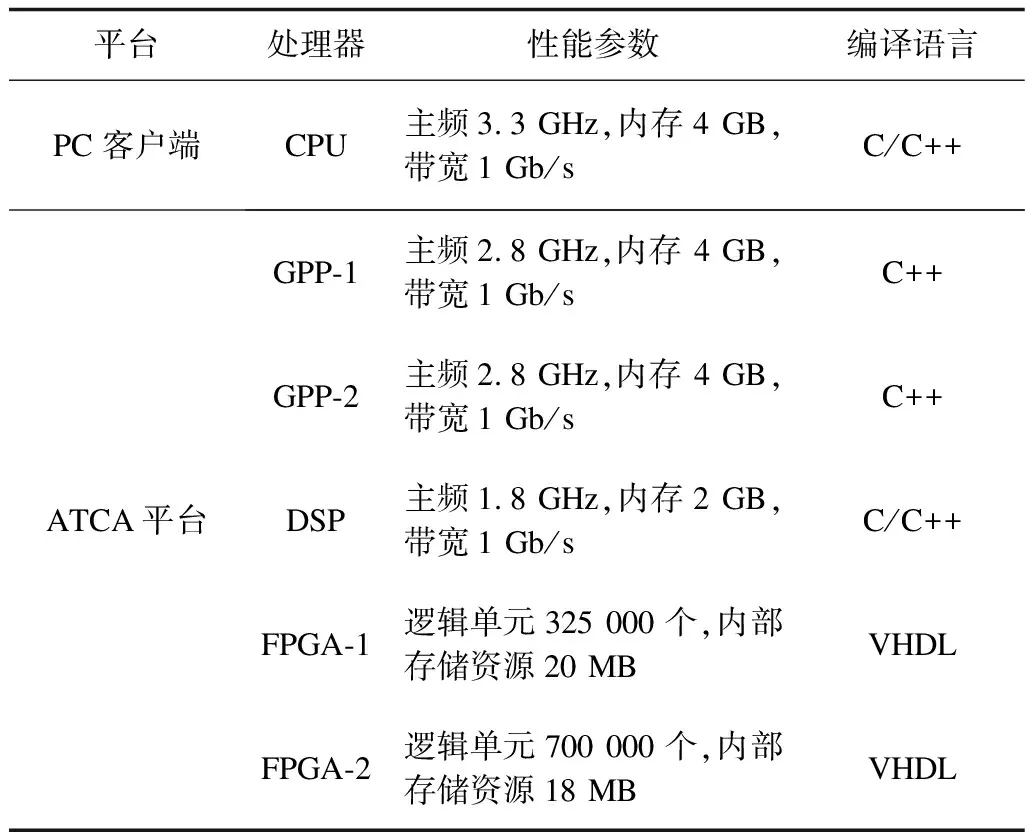
表2 异构信号平台处理器参数配置
本文选取FFT、短波FSK、QPSK和MIMO雷达信号处理4个典型应用作为测试程序,4个测试程序的DAG的节点数和拓扑结构复杂度依次增加。其中,FFT应用的DAG包含3个节点,FSK包含5个节点,QPSK包含8个节点,MIMO包含10个节点。针对平台目前采用的事件触发数据流调度算法与多层同步流水线调度算法进行对比实验,其中,事件触发调度算法按照应用原始DAG进行调度,不再进行任务划分。多层次流水线调度与事件触发调度算法的性能对比如图6所示。
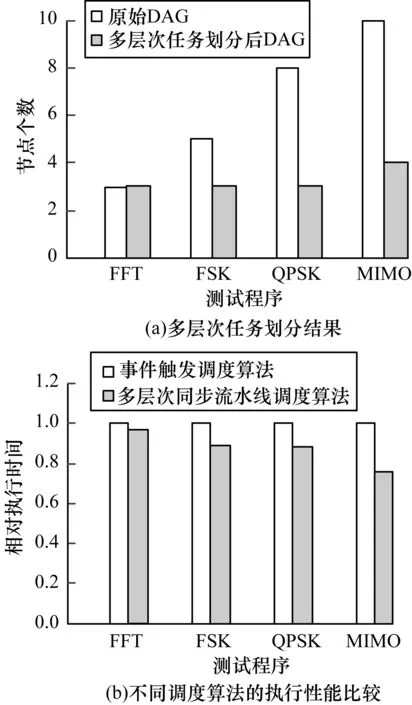
图6 多层次流水线调度与事件触发调度算法对比
图6(a)为测试程序的DAG经过多层次划分结果的示意图,可以看出,测试程序FSK、QPSK和MIMO经过多层次划分DAG节点数明显减少,但对于FFT应用,划分结果并不理想,原因是FFT应用的组件较少,DAG拓扑结构过于简单。实验测试选择的性能指标为应用完成执行的时间,图6(b)为测试程序在2种调度算法下执行性能的比较,可以看出,测试程序随着DAG节点数以及拓扑结构复杂度的增加,多层次流水线调度算法执行时间呈递减趋势,执行时间越小,说明改进效果越好。但FFT应用在2种算法下执行时间基本相同,多层次同步流水线调度并没有取得很好的性能收益,原因是FFT应用的节点数太少且拓扑结构过于简单,但随着任务DAG节点数的增多,拓扑结构复杂度增加,多层次流水线调度的优势也越明显。因为事件触发调度算法在依赖节点数过多且约束关系复杂的情况下,其节点在运行时会频繁唤醒,所以带来的开销过大。MIMO雷达信号处理应用节点数最多、拓扑结构最复杂,相对于事件触发调度算法,多层次同步流水线调度算法的运行时间能够缩短25%左右。
4 结束语
本文基于异构信号处理平台提出利用DAG的任务模型,设计实现多层次任务划分算法,保证任务节点间的异构负载均衡,减少同步开销。同时,在多层次任务划分的基础上设计同步流水线调度策略,实现节点的并行执行。实验结果表明,该算法适合异构信号处理平台中实时任务的调度。但是本文多层次任务划分算法还存在不足,在保证任务划分均衡的情况下降低节点通信开销,是下一步研究的方向。
猜你喜欢
汉语世界(The World of Chinese)(2023年2期)2023-06-22 14:50:17
小学教学研究(2022年5期)2022-04-28 21:29:36
小学科学(学生版)(2020年2期)2020-03-03 13:40:16
信号处理(2018年5期)2018-08-20 06:16:02
信号处理(2018年5期)2018-08-20 06:16:00
信号处理(2018年8期)2018-07-25 12:25:42
信号处理(2018年8期)2018-07-25 12:24:56
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
中国资源综合利用(2016年9期)2016-01-22 08:35:22
