
基于Hadoop平台的GPU集群加速Apriori算法
2018-11-20 06:08:36瞿诗齐刘少江倪伟传余庆茂
计算机工程 2018年11期
瞿诗齐,刘少江,倪伟传,余庆茂
(中山大学 新华学院,广州 510520)
0 概述
伴随着存储技术的迅猛发展,人类社会进入了一个大数据时代,各行各业都有着庞大的数据库,然而在这些海量的数据中挖掘出有价值的信息成为一个难题[1]。分布式计算[2]因对大数据具有良好的处理能力而逐渐兴起,它通过多个节点部署成一个集群,每个节点并行处理计算后通过汇总来处理任务。然而,针对Apriori算法,集群中单个节点的计算能力极大地限制了算法的效率[3]。因此,为通过GPU较强的运算能力解决该问题,本文提出一种CPU和GPU协同工作的方式,将GPU加入到现有的Hadoop平台中,增强集群中节点的计算能力,并且进行对比实验来检测算法的运行效率。
1 Apriori算法的并行化
并行化计算[4]是现代计算要求越来越高的产物,更是目前高性能计算中非常实用的一种计算手段,它主要是把一个很复杂或者计算量很大的任务,分割成很多互相不具关联性的小任务,然后把这些许许多多的小任务利用多个处理器并行来完成,最后把得到的结果汇总合并。通过这种方式有效地利用计算资源,减少运算所需的时间,提高算法效率。
1.1 Apriori算法
Apriori算法一种从海量的数据中找出数据间相关性的算法,它通过逐层迭代的手段来挖掘频繁项,是关联规则算法中最经典的一种[5],也是最先验证其原理并且借鉴了源于support的剪枝技术的成果,有效地剔除了候选的真子集项的指数级增长姿态,使得它成为了关联挖掘算法中应用最为广泛的算法之一[6]。
Apriori算法的计算流程如图1所示。首先遍历事务数据集,统计出每条事务中每项出现的次数,即每项的支持度。删减掉小于最小支持度的项,剩余的每个项即1阶频繁项集[7]。然后Apriori算法进入一个循环过程,根据k(k>0)阶频繁项来生成k+1阶候选项集[8],如果候选项的个数小于0,则算法结束;否则,统计每个k+1阶候选项集的支持度,删除达不到最小支持度的候选项,就得到了k+1阶频繁项集合。最后继续进入循环进行计算,直到算法结束。
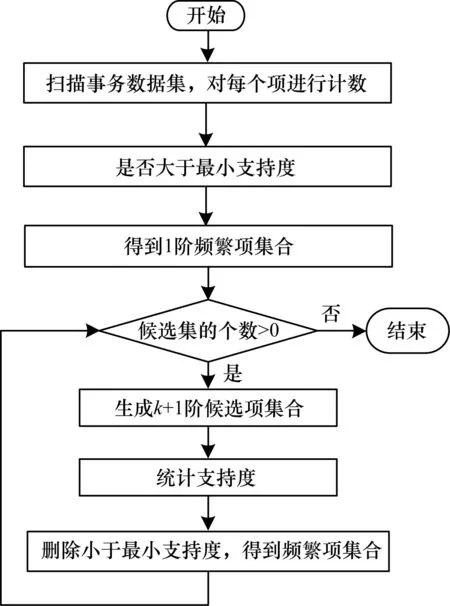
图1 Apriori算法流程
Apriori算法的计算流程实际上是一个寻找数据集中频繁项的过程,但是因为在迭代过程中出现了大量的候选频繁项集,在计算过程中为了得到候选项集的支持度而多次扫描数据集,在原始数据样本较少时能有较好的计算效率。一旦数据增长到一定规模后,候选项集将呈指数增长,算法的执行速度和效率都会受到较大的影响。
1.2 Hadoop平台下的Apriori算法
自从云计算出现以来,有关大数据的相关研究也相继出现,其中使用最多的分布式结构即Hadoop[9],它是用来解决大规模的数据批处理的平台,它的MapReduce计算框架[10]为Apriori算法的计算过程提供了一个很好的并行化思路。MapReduce计算框架也就是一个Map-Reduce的过程。首先进行一个Map的过程,即将大规模数据集分割成许多小的子数据集。然后将子数据集分配给Hadoop下的多个Mapper计算节点,使各个节点之间同时并行计算。最后进行Reduce的过程,即将每个Mapper节点计算出的结果通过Reduce节点进行汇总合并,来实现计算的并行。
在Hadoop平台下,Apriori算法MapReduce的并行化流程如图2所示。首先主节点把原始的数据集分成N个小的数据块,均匀地散布到Hadoop集群中的各个工作节点上。工作节点应用MapReduce框架的原理,把收到的数据块进行Map处理后计算k项候选集。接下来把每个节点上Map进程得到的局部k项候选集通过Reduce进程进行汇总得到全局的k项候选集的支持度。然后根据最小支持度的筛选得到全局k项频繁项集合。最后根据全局k项频繁项得到k+1项候选集,重新进入第2次数据处理直到k+1项候选集为空,结束算法。
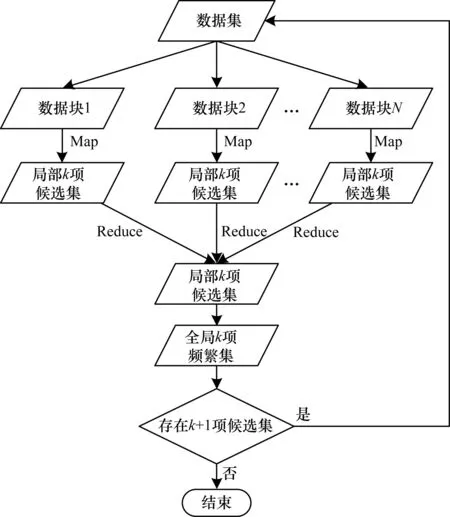
图2 Apriori算法MapReduce计算框架的并行化流程
2 GPU集群加速Apriori算法
2.1 GPU并行计算
CPU最初设计是为了次快速地一次完成多条串行指令,目前它的发展已经遇到了瓶颈,而GPU被设计用来执行并行指令[11],拥有大量的流处理器并行执行,运算能力不是CPU能够比拟的。同时,GPU的计算成本也比CPU要小得多,因此,GPU非常适合用来进行密集型的计算。
从上文对Apriori算法的介绍可知,在运算过程中,主要是找出数据集中的频繁项集合。实际上,频繁项集主要是通过统计候选项的支持度来确定的,而候选项集就是一个排列组合的过程。其中,候选项集生成的规模大小主要是由项集的长度来决定的,大多数甚至呈指数增长,在数据集中对候选项进行计数的计算量十分巨大。因此,频繁项项集的计算实际上也是一个计算密集型的计算。
2.2 改进的Apriori算法
CPU/GPU是一种CPU搭配GPU的新型计算模式[12],由于GPU在计算方面的超强性能远远超过了多核系统,将任务中的计算密集型工作交由GPU来完成,而CPU主要负责对任务进行分配、汇总等。这种方式不仅只是计算能力的提升,而且在达到同样高性能计算能力的同时,还拥有更廉价的计算成本。
2.2.1 Hadoop平台中GPU的引入
高性能计算主要分为分布式计算和GPU并行计算2种不同的计算方式[13]。当然,不管是利用集群来进行分布式计算还是GPU对数据的并行计算,对Apriori算法进行改进,分离出更多的并行化操作,使硬件资源并行来处理算法,减少运行时间。但是面对海量数据利用Apriori算法计算时,Hadoop平台中集群的单个节点的计算量依旧是提高算法速度的一个瓶颈,而单个GPU的存储能力不足,难以处理海量的数据输入。因此,本文提出将GPU引入Hadoop平台来充当主要的计算单元,不仅保留了Hadoop平台高效的分布式管理,而且还能发挥GPU强大的并行计算能力。
虽然GPU拥有着更为强大的计算和并行能力,但是这并不意味着所有的计算任务都应该交由GPU来处理。GPU适合那些计算量大而控制流简单的任务,即该任务大部分的处理时间都运用在计算上才能充分发挥GPU的高计算性能。通过前面的分析可知,Apriori算法的瓶颈主要是对候选项集支持度的计数。因此,把对候选项集的计数过程主要交给GPU来处理,Hadoop平台下主节点Master主要负责子数据的分发、候选项集的下发与剪枝得到频繁项集;从节点Slave主要存储子数据,收到候选项集后创建kernel函数,调用GPU计算来对候选项集进行计数。本文在原来Hadoop的框架下,设计一种多节点并发、节点内多线程并行的多层次多粒度GPU-Hadoop框架,主体框架如图3所示。首先搭建一个Hadoop集群,主要由一个主节点Master和N个从节点Slave构成,主节点Master控制多个从节点Slave并行进行任务,每个从节点Slave调用GPU进行计算密集型计算,最后将汇总给主节点Master。
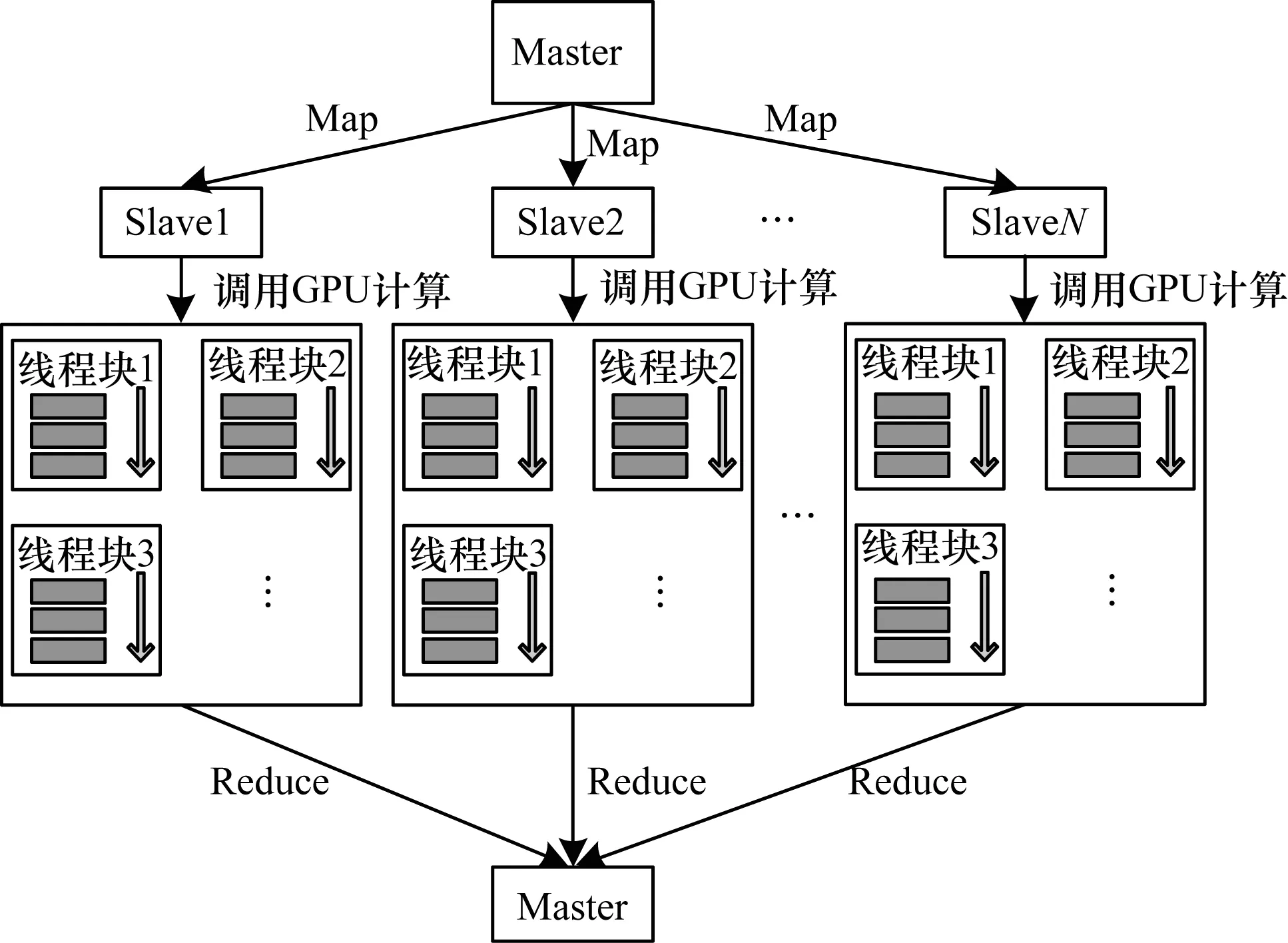
图3 GPU-Hadoop主体框架
GPU嵌入Hadoop的具体流程如图4所示。将原始数据存储在HDFS中,主节点Master将原始的数据分割成多块子数据,然后将数据均匀地分散到各个Slave处。主节点Master生成对应的k项候选项集下发到Slave中。Slave收到后创建kernel函数来调用GPU对项集进行计数,每个Slave节点得到部分k项候选集的计算,然后汇总得到全局k项候选集合的计数,Master节点通过最小支持度剪枝来得到全局k项频繁项集。之后,主节点Master判断是否存在k+1项候选项集,如果生成k+1项候选项集,就将它发给Slave进行下一轮计算;反之如果不存在,计算结束。
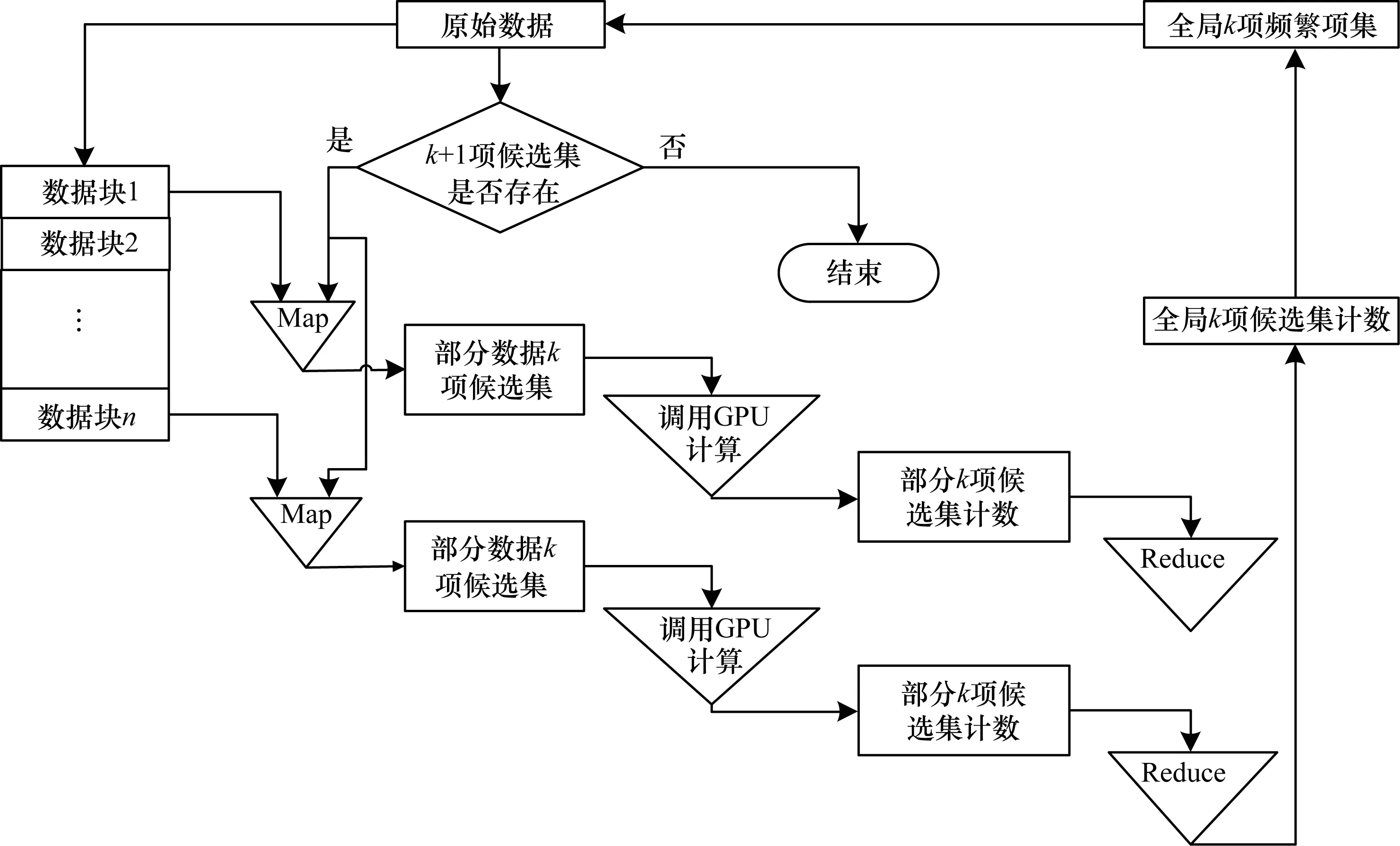
图4 GPU-Hadoop计算的具体流程
由于本文是利用Hadoop平台中的分布式文件系统HDFS来存储数据集,因此相对而言存储的数据量更大,扩展性也更好。另外,因为框架的主体控制是以Hadoop平台为主,所以还能很好地处理节点失效和负载不均衡等问题[14],较好地完成计算工作。
2.2.2 候选项集的生成
上节提到Master节点通过最小支持度剪枝来得到全局k项频繁项集,当得到全局项频繁项集后,主节点Master要判断是否存在k+1项候选项集。由于频繁项是从候选项集中通过计数挑选得到的,因此如果能很好地控制候选集的数目,防止不能成为频繁项集的候选项集产生,就能极大地减少后面的计算,提高算法效率。
Apriori算法依赖于向下封闭原则[15],假设一个候选项集是频繁项集,那么这个项集的子项也一定是频繁项集。相应地,一个不是频繁项集扩展出来的父项集一定也不是频繁项集[16]。针对Apriori频繁项集的这个特点,本文利用联合和删减的方法生成频繁项集,可以生成包括全部频繁项集较小的候选频繁项,较前面的方式有了很大的提高。
联合过程:在一个长度为k的频繁项集集合Fk中,任意取2个不同的频繁项集f1和f2。如果f1和f2中有k-1项是相同的,那么就可以得到其中一个由f1和f2组成的并集组成的k+1项项集f,可以把这个项集f放入临时的k+1候选项集集合Ck+1′。然后重复这一合并的步骤,直到将Fk全部的项集元素都两两组合完毕为止。
删减过程:在之前联合过程中,有些不满足向下封闭原则,为了将不满足向下封闭原则的项集删减,在这里加入一个Merge函数对项集进行压缩。Merge函数是遍历集合Ck+1′中的项集元素f′,f′所有k长度的子集都能在Fk中找到,f′有必要带入后面计算的候选频繁项集,放入到真正的候选项集集合Ck+1中。
2.2.3 候选项集的优化
在串行计算中,候选集的计数方式一般都是定义一个计数变量count,遍历数据集中的每条事务,不断地对变量count进行加一操作,最后count的值就是该候选项在数据集中出现的次数。由于现在将计数的工作交给了GPU来进行处理,GPU启动多个数据块计算,数据块内多线程并行,count变量在同一时间容易被多个线程同时访问和修改,可能会使得计数出错。但是如果采用线程锁的方式,频繁地加锁减锁又会严重影响算法的运行速度。
为解决这个问题,在每个单独的线程内申请了一个寄存器变量count,用来统计该线程对候选频繁项的支持数。然后,在全局寄存器中申请一个二维数组count_thread[block_num][thread_num],其中,block_num代表线程块的个数,thread_num代表线程块内线程数。每个线程块内线程对候选频繁项的计数完成后,线程之间采用并行的规约思想,统计出整个线程块的候选频繁项的计数。最后,把节点所有线程块block的结果求和,节点内的统计计数即完成。线程内的统计计数过程如图5所示。
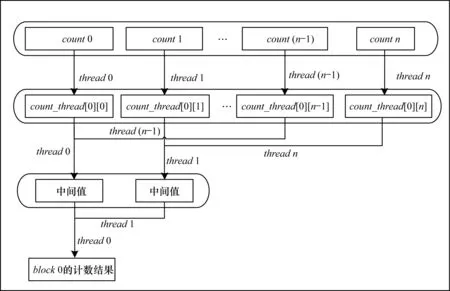
图5 线程块内并行规约计数过程
3 实验结果与分析
为了验证本文Hadoop平台利用GPU进行加速Apriori算法在面对大规模数据集时的性能,将实验分为了2个部分:1)实验对比未采用CUDA加速的Hadoop算法和采用CUDA加速后的Hadoop算法之间的效率;2)实验对比Hadoop平台下节点个数对算法的影响。
实验的数据选自UCI机器学期数据库中某大型超市交易记录信息,数据分为2份:10万条数据集和50万条数据集。为方便实验,对这些文件又进行了多次备份,最多将数据自拷贝10次达到500万条数据集来达到大数据的情况,并对选取的数据集进行预处理,将处理过的数据上传到HDFS。
实验环境为:5台配置GPU的PC构成Hadoop集群的Slave节点,1台没有配置GPU的PC作为Hadoop集群的Master节点;NVIDIA CUDE6.0以及Hadoop-1.2.1,集群配置信息如表1所示。
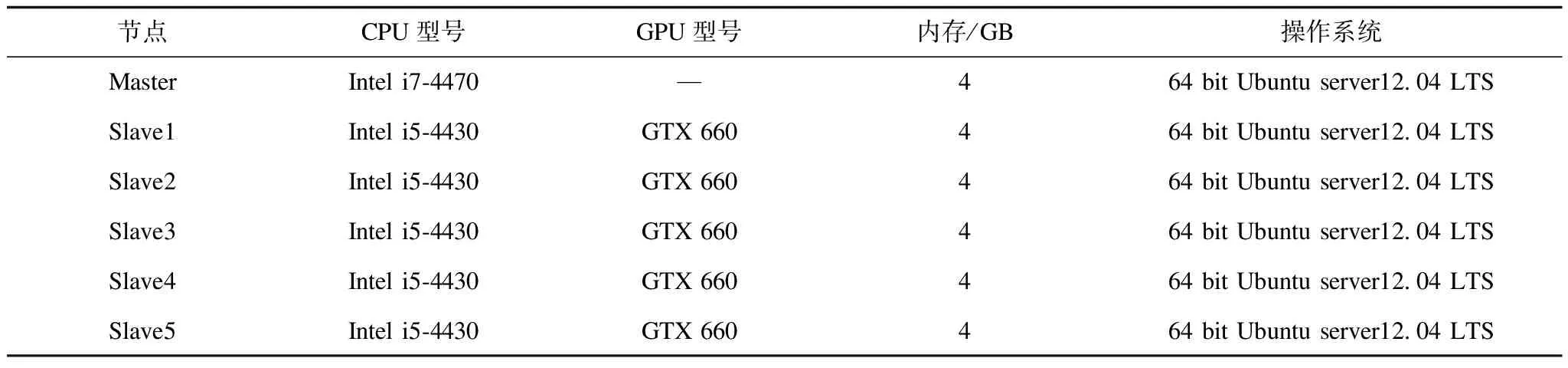
表1 Hadoop集群的节点配置
3.1 CUDA加速对比实验结果
实验采用上述的硬件环境,将未采用CUDA加速的Hadoop算法和采用CUDA加速后的Hadoop算法分别进行对10、50、100、200、500万条事务数据进行处理,查看算法所用的时间,实验结果如图6所示。
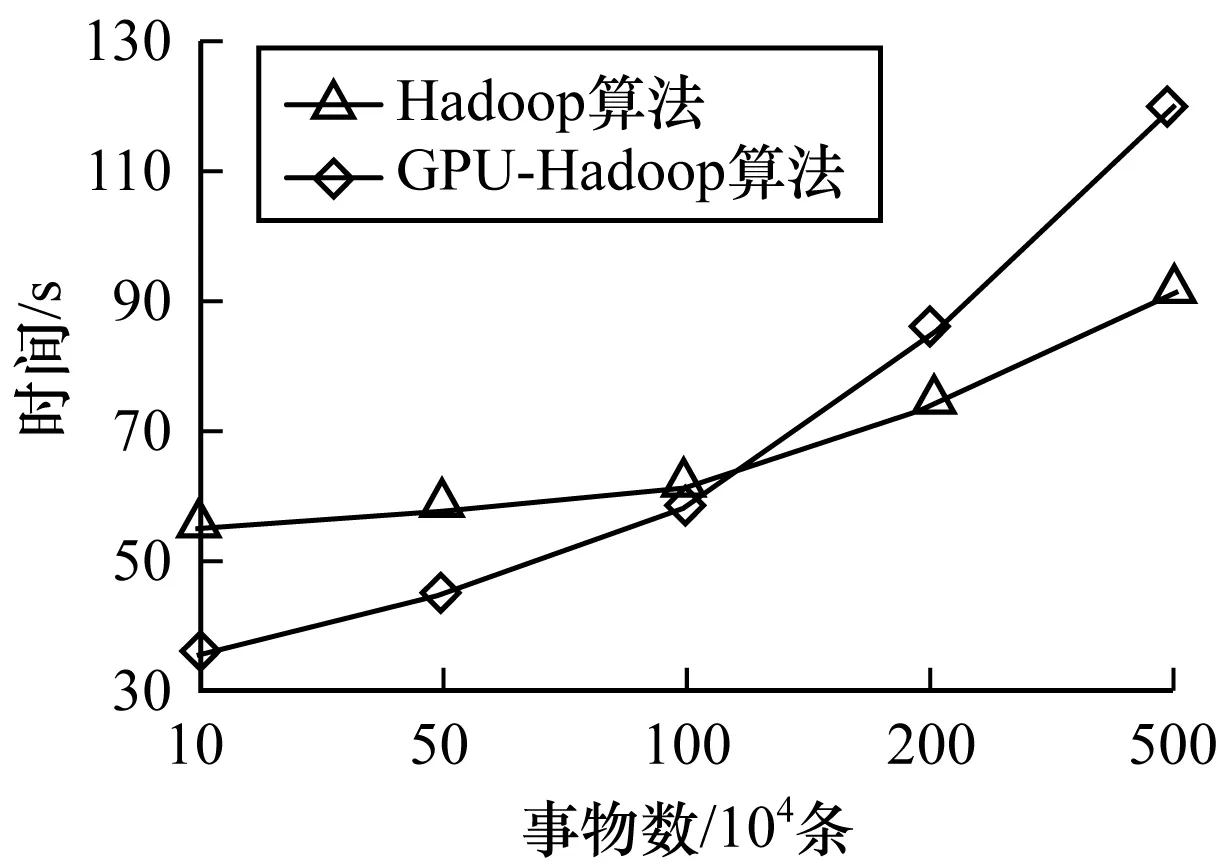
图6 运行时间与数据量的对比实验结果
当需要计算的数据量比较小时,单纯的Hadoop平台运行效率更好,这是因为在数据量较小时,相对而言计算量并没有特别大,所以将计算传递给GPU反而耗费了计算时间。当数据量逐渐增大时,算法的计算规模也越来越大,当计算时间占主要部分时,GPU-Hadoop优异的计算能力因而得以凸显出来,并且可以看出,随着数据量的增大,相对于单纯地利用Hadoop平台来计算,改进算法提升效果越来越明显。
3.2 不同节点对比实验结果
对于并行算法而言,最关注的是它的运算时间。但与此同时,还要考虑并行算法下资源本身的运行效率,即并行效率。纯粹用硬件资源来提高算法的效率,对算法的效率评价并不全面。因此,对改进算法用不同从节点个数对500万条事务数据进行了对比实验,结果如表2所示。
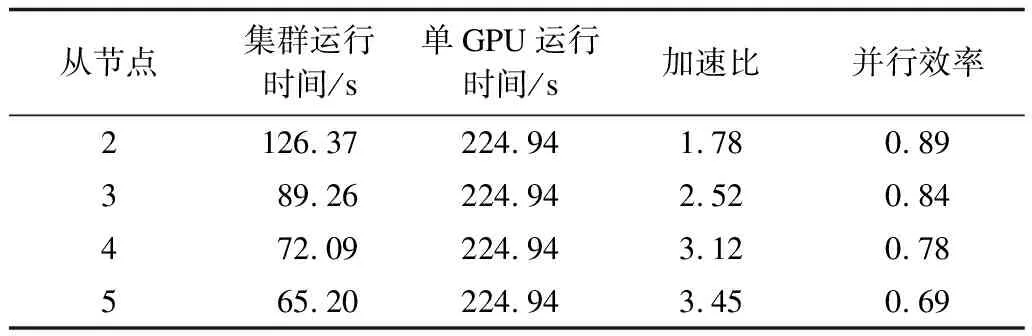
表2 不同节点的实验结果对比
从表2不难发现,随着从节点数目的增加,虽然加速比在不断变大,但是并行的效率却在下降。这是因为在处理的数据量不变时,Hadoop集群中的节点数越多,集群的计算能力越强,因此加速比明显提高。但是,节点之间的通信开销却在随之增大,导致并行效率也随之下降。因此,在进行计算时,不能仅仅单纯地追求整体效率的提升,而完全忽视硬件之间的并行效率,应该在节点数和处理的数据量之间找到一个平衡点,从而最有效地利用平台设备。
4 结束语
本文通过研究Apriori数据关联算法,提出一种基于Hadoop平台的GPU加速计算算法。由于GPU在计算方面的超强性能,超过了多核系统,因此将任务中的计算密集型工作交由GPU来完成,而CPU主要负责对任务进行分配、汇总等,不仅节约硬件成本,而且具有良好的扩展性。实验结果表明,改进后的算法能够有效地利用计算资源,减少运算所需的时间,提高算法效率。
猜你喜欢
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
环球市场(2017年36期)2017-03-09 15:48:21
知识就是力量(2017年2期)2017-01-21 18:29:36
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
网络安全与数据管理(2010年1期)2010-05-18 07:28:54
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11 11:04:49
