
大数据的时代背景、系统实现及关键技术解析
2018-11-16 09:10魏建琳
西安文理学院学报(自然科学版) 2018年5期
魏建琳
(西安文理学院 图书馆,西安 710065)
2011年5月,国际著名咨询公司麦肯锡(McKinsey & Company)预言,人类将步入一个“大数据时代”[1].短短几年间,信息技术的飞速发展已让预言成为现实.大数据不仅受到普遍关注成为国际流行的热门话题,而且相关技术不断取得突破促使新产品新项目大量涌现,更重要的是大数据已应用于各行各业,成为政府、企业、社会组织以至于个人的重要生产组织决策资源.
“大数据时代”翩然而至,成为本世纪继云计算、物联网后又一次颠覆性的技术变革,对国家、企业、团体、个人都已经或将要产生巨大影响.面对汹涌澎湃的大数据浪潮,笔者拟从时代背景与技术实现两个维度对大数据的基础知识——概念(What)、理由(Why)以及方式方法(How)做一简单梳理与解析.
1 信息化发展演变视阈下大数据的再审视
什么是大数据?为什么要研究大数据?对此,IT行业已做出了精确的界定与合理的解释.2011年,麦肯锡(McKinsey & Company)将大数据定义为“大小超出了传统数据库软件工具的抓取、存储、管理和分析能力的数据群”[1].随后,IBM公司概括了大数据的三大特点——大量化(Volume)、多样化(Variety)和快速化(Velocity).[1]笔者拟在此基础上,联系信息化发展演变的具体语境,对这两个命题进行再审视,以做出更通俗的阐释与解析.
20世纪中叶,人类迈入了信息时代.随着计算机的发明和应用,信息的承载从“语言”到“文字”,进而发展到了“数据”.“数据”是客观事物的符号化表示,二进制的发明实现了数据在物理机器中的表达、计算和传输,数据可输入计算机,被计算机程序理解和处理,这样利用计算机强大的计算能力,人类对数据得以有效的管理与开发利用.经过近半个世纪的探索,人类以计算机为工具管理数据从依赖“特有程序”到“文件系统”管理,再到“数据库管理系统”,基本实现了数据的快速组织、存储和读取.以计算机为工具管理数据不仅提升了信息描述的精确性,更扩大了信息传递的广泛性,信息在越来越广阔的空间发挥着越来越重要的作用.
但是,信息时代在利用现代信息技术有效管理利用数据的同时,也带来了数据的爆发式增长.据国际数据中心IDC发布[2],2010年全球数据量已达1.2 ZB,2011增长到1.8 ZB,2012年达到2.8 ZB,全球数据总量年增长率维持在50%左右,预计到2020年,全球数据总量将达到40 ZB.现在,数据不仅数量庞大(Volume),增长迅速(Velocity),而且来源类型多样化(Variety).传统数据基本来源于行业或企业的内部数据,现在则大部分来源于互联网和物联网.传统数据以结构化数据为主,而现在来源于社交网站、电子商务、物联网的数据基本都是非结构化和半结构化的数据.传统数据用关系数据库的管理系统可实现有效的管理与开发,现在数据因其大量、迅速、复杂,大大超出了传统数据库软件工具的能力范围,以至于引发了数据存储与处理的危机.[1,3]

图1 大数据采集、处理、存储、分析的系统实现架构
大数据带来了危机,同时也呼唤着大数据处理技术,推动着大数据研究的飞速发展.
2 大数据采集、处理、存储、分析的系统实现
信息时代极大地彰显了“数据”的价值,但人们无法有效地利用“数据”,望“大数据”而兴叹.由此,“大数据技术”应运而生.2012年,美国政府颁布《大数据研究与发展倡议》(Big Data Research and Development Initiative),并投资两亿美元以支持大数据相关技术的研发.[4]2015年9月,国务院印发《促进大数据发展行动纲要》,围绕“大数据”着手实施一系列研发应用工程[5].另外,IBM、谷歌、亚马逊、阿里巴巴等商业公司亦纷纷推出了大数据系统解决方案.当前,大数据技术初见端倪,初显成效.下面笔者对大数据的系统实现模式做一简要梳理.
尽管当前大数据解决方案千差万别,采用技术五花八门,但都有一个基本相似的流程,即大数据的采集、处理、存储、分析,围绕流程开发工具,实现对大数据的科学管理合理利用.如图1.
大数据主要有三个来源,一是传统的行业/企业内部数据,如ERP(Enterprise Resource Planning,企业资源计划系统)、CRM(Customer Relationship Management,客户关系管理)等,这类数据以结构化数据为主;再就是泛互联网数据,如QQ、微博等社交网站和亚马逊、阿里巴巴等电子商务产生的动态数据,这类数据以非结构化数据为主;还有就是物联网数据,如RFID(radio frequency identification,射频识别)和传感器数据,这类数据以半结构化数据为主.
针对不同的数据类型,有不同的采集方法.对于结构化数据的采集利用传统关系型数据库管理系统接口实现.对于非结构化的泛互联网数据,可通过网络爬虫或网站公开API等方式获取非结构化数据,再在本地存储为结构化数据.对于半结构化数据流,需借助专用采集工具,如Chukwa、Flume等.
大数据来源多样,类型复杂,数据大多不完整或不一致,需要ETL(Extract-Transform-Load)进行预处理,将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目标数据库或相应文件存储系统.
大数据场景下,数据量呈爆炸式增长,存储方案一般是分布式存储架构,以保障海量数据的读取.当前较出名的存储技术有谷歌的GFS(Google File System)和Hadoop的HDFS(Hadoop Distributed File System).另外,采用NoSQL(Not Only SQL)数据模型自定义数据存储格式,对数据和系统架构进行扩展,也是较流行的存储技术.
完成了数据的采集、处理和存储,下一步就是数据的分析和挖掘.当前大数据分析主要采用数据仓库、联机分析和数据挖掘解决方案.数据仓库(Data Warehouse)是核心,它是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合.联机分析(On-Line Analysis Processing,简写为OLAP)和数据挖掘(Data mining)是数据仓库系统的主要应用形式.OLAP属于验证型的分析,辅助实现多元数据一致存取和多维分析,从而获得对数据的更深入了解.数据挖掘是通过算法从大量的数据中搜索隐藏于其中信息的过程,它主动去发现有用信息,发掘潜在规律,与OLAP一同用于支持管理决策.[1,3]
3 大数据的关键技术解析
互联网和物联网的广泛应用,产生了大小超出了传统数据库软件工具处理能力的数据群,使得人们无法有效地利用“数据”,望“大数据”而兴叹.由此,“大数据技术”应运而生.人们通常所说的“大数据”,其实更多地是指“大数据技术”,实质是一个“新技术群”.大数据技术丰富多彩,难以面面俱到,笔者仅撷取其最基本的关键技术做一简要解析.
大数据技术与传统数据处理在流程上并无太大差异,主要的区别在于处理方式.大数据处理方式是基于MapReduce技术对海量结构化、半结构化和非结构化数据的混合并行处理,MapReduce技术应用于各个环节.
MapReduce最早是由Google公司研究提出的一种面向大规模数据处理的并行计算模型和方法.Google公司设计MapReduce的初衷主要是为了解决其搜索引擎中大规模网页数据的并行化处理,但由于MapReduce对数据一致性要求不高,具有可扩展性和可用性,可以普遍应用于很多大规模数据的计算问题,特别适用于海量的结构化、半结构化及非结构化数据的混合处理,因此MapReduce迅速普及成为通用的面向大数据并行处理的计算模型、软件框架和系统平台.MapReduce的运行原理如图2所示.
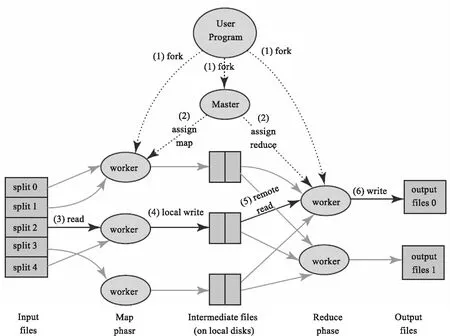
图2 MapReduce运作原理[6]
因为对于大数据的处理,不是一台计算机同时处理许多任务,而是许多计算机同时做一件任务的逻辑关系,所以必须进行有效的分工与协同.MapReduce将计算机分为两类,一类是Master负责调度,另一类是Worker负责执行.同时,MapReduce将大数据处理任务分为Map(映射)和Reduce(化简)两个阶段,首先Master对来自User Program的大数据进行Map(映射),即把海量数据分割成若干部分split,分给多台处理器Woker并行处理;然后对处理结果Reduce(化简),即把各台处理器Worker处理后的结果进行汇总操作、集成输出Output file以得到最终结果.
MapReduce将传统的查询、分解及数据分析进行分布式处理,并基于网络环境共享大量的廉价PC资源,耦合度低,有容错机制,所以特别适合大数据环境下的处理需求.MapReduce已经成为事实上的大数据处理工业标准,尽管还有很多局限性,但人们普遍公认MapReduce是截止目前最为成功的大数据并行处理技术,也是截至目前大数据处理的关键技术.[1,3,6-7]
4 结语
大数据和其他划时代的信息技术一样,几乎对所有行业及其从业人员都有革命性的影响.大数据时代,数据就是最重要的“财富”,能汇集挖掘大数据价值为己所用的行业及其从业人员将是未来的“赢家”.千里之行始于足下,大数据时代已经翩然而至,融入大数据时代,成为大数据时代的佼佼者,就从了解“大数据的入门知识”开始.
猜你喜欢
学习与科普(2022年17期)2022-04-23
心理学报(2022年4期)2022-04-12
能源工程(2021年6期)2022-01-06
水泵技术(2021年3期)2021-08-14
建材发展导向(2021年12期)2021-07-22
河北理科教学研究(2021年4期)2021-04-19
军民两用技术与产品(2021年2期)2021-04-13
云南教育·小学教师(2021年12期)2021-03-23
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
