
多区域大规模迭代计算框架应用研究
2018-11-16 06:34王晓斌卢福军马忠义
信息通信技术 2018年5期
王晓斌 卢福军 殷 颖 闫 萌 马忠义
1 中国联合网络通信有限公司山西省分公司 太原 030006
2 山西建筑工程(集团)总公司 太原 030012
3 东北大学软件学院 沈阳 110169
前言
在数学中,迭代函数是可重复与自身复合的函数,反复地运用同一函数计算,前一次计算得到的结果被用做下一次计算的输入,这个过程叫做迭代。在计算机科学中,迭代是程序中对一组指令(或一定步骤)的重复,它通常描述一种特定形式的具有可变状态的重复。迭代算法是用计算机解决问题的一种基本方法。它利用计算机运算速度快、适合做重复性操作的特点,让计算机对一组指令(或一定步骤)进行重复执行,在每次执行这组指令(或这些步骤)时,都从变量的原值推出它的一个新值。即使是看上去很简单的算法,在经过迭代之后也可能产生复杂的行为,衍生出困难问题的求解方法[1]。
随着数据挖掘、机器学习等相关领域的发展,越来越多的迭代计算应用到诸如社会网络分析、高性能计算、推荐系统、搜索引擎、模式识别等领域中[2]。例如:网页排名算法PageRank算法根据网页之间的链接关系进行迭代并收敛至最终结果,其迭代本质即从任意迭代初始点开始,根据迭代函数进行反复迭代更新;K-means算法反复迭代更新数据聚类中心点,根据最终收敛的不动点结果来判定数据单元的聚类所属关系;协同过滤(Collaborative Filtering)算法,通常作用在用户与购买商品关系的二维图上,通过交叉运行以用户为核心的和以商品为核心的两个迭代计算过程,最终收敛的两个向量表示购买习惯相似的用户群和功能相似的商品群,利用相似用户群中其他用户的商品喜好信息来进行个性化推荐。
“海量”是大数据的一个主要特点。大数据是数据量庞大且分布广泛的数据,当我们谈及大数据时,很难假设数据是集中存储的,也很难认为数据是静态存储的。众所周知,大数据分析算法期望作用在全集数据而非局部数据之上,而“全集”又是相对的。因此迭代分析算法既会在各局部数据上执行,得到相对局部的分析结果;又会在汇总的全集数据上运行,产生相对整体的分析结果。我们对这种迭代称为多区域大规模多级迭代计算,简称多区域迭代。多区域迭代计算原理如图1所示,这是本文的研究重点。我们从文献[2]中得到了大量的启发,类似的工作包括Pramod等人提出了Incoop[3]框架,以及文献[4]中,提出的针对PageRank算法的增量式迭代分析计算。
1 系统架构
在大数据环境背景下,基于Hadoop MapReduce[5]的HaLoop框架[6]是现阶段相对成熟的分布式迭代计算框架,它采用MapReduce的编程模型使得其可以充分利用廉价的分布式服务器集群得到强大的迭代分析能力,并对Hadoop框架进行适应迭代分析算法的改进,从而支持大数据下大部分迭代分析算法的运行。近些年,由于计算机硬件的快速发展,UC Berkeley AMP Lab提出了Spark框架[7]。Spark框架与HaLoop框架不同,它完全作用于内存计算,而无需从HDFS上读写迭代数据,迭代的分析速度更快、更便捷,因此Spark框架能更好地适用于机器学习和数据挖掘等计算机科学领域中的迭代分析算法。综上所述,多区域大规模迭代计算将选择Spark计算框架作为计算平台,通过对Spark框架的扩展实现大数据环境下的多区域迭代计算。
将迭代计算模型运用于山西联通大数据业务分析领域,其系统架构如图2所示。例如山西联通组织机构可以根据地理位置划分为太原分公司、大同分公司、吕梁分公司、临汾分公司等11个地市分公司,每个行政地市都有对应的通信业务分析机构,对区内自身的通信数据进行分析操作,获得区域内可靠的通信结果;而对于山西联通省公司而言,也对应存在一个省级分析机构,用于全省数据的分析,即将各个地市的移动通信进行汇总,并在汇总后的全集数据上进行数据分析得到某市整体的分析结果。
在图2中,蓝色虚框标记的是区域(地市)分析机构的集群架构,包括各个地市自身的Spark&Yarn分析计算集群和存储数据的分布式文件系统,红色虚框标记的是省级分析机构的集群架构,主要由计算集群Spark&Yarn框架组成。各个地市基于内部的Spark&Yarn分析计算集群,在区内自身的数据上进行分析得到对应的区内分析结果,服务于区内个性化的政策和未来科学合理地决策,而当省级机构需要对全市数据进行分析时,各个地市的机构可以将自身区内的数据以及区内分析结果反馈给省级机构,省级机构可以基于省级的Spark&Yarn分析计算集群,直接在区内分析结果的基础上进行迭代计算,快速地得到全省的分析结果。其中,各个区内(地市)的分析计算集群Spark&Yarn的架构如图3所示。
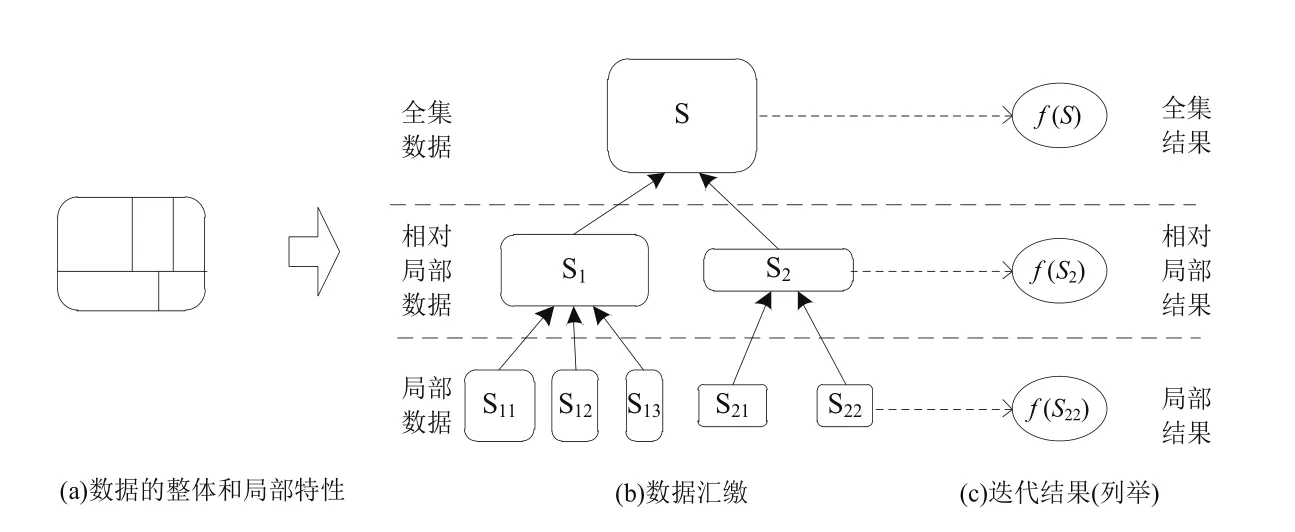
图1 多区域迭代计算原理

图2 多区域大规模迭代计算系统架构图
多区域大规模迭代计算框架的运行主要步骤为:Client提交迭代计算的应用,主节点构建迭代的运行环境并启动Driver,Driver向主节点或者资源管理器申请迭代计算所需的资源,并通过SparkContext将迭代计算应用转化为RDD Graph,再通过DAGScheduler将RDD Graph分解为Stage的有向无环图,将TaskSet发送给TaskScheduler,最终由TaskScheduler发送Task给对应的Executor执行迭代任务。在迭代计算任务执行的过程中,Yarn中的Resource Manager负责迭代计算资源的分配和调度,其中Container是迭代计算资源分配和调度的基本单位,封装了内存、CPU、网络、磁盘等计算节点中重要的机器资源。
2 迭代算子
基于上节对多区域大规模迭代计算系统架构的介绍,我们可将框架主要分为以下几个模块:RDD(Resilient Distributed Datasets)算子模块、迭代调度模块、迭代计算模块。其中最重要的为RDD算子模块,是实现区域迭代的核心。

图3 多区域大规模迭代计算框架Yarn模式的架构图
RDD弹性分布式数据集,是迭代计算系统中的数据抽象,提供了一种高度受限的共享内存模型,即RDD是只读的,分区记录的集合。每个RDD数据集合都有以下属性。①RDD之间的依赖关系:RDD在进行变换过程中,会由一个旧RDD变换为一个新RDD,两个新旧RDD数据集之间存在类似流水线一样的前后依赖关系,通过RDD之间前后的依赖关系,我们可以在某些分区数据丢失时进行恢复性计算,得到正确的迭代结果;②分片Partition:分片是RDD数据集的基本组成单元,针对每个RDD数据集而言,每个分片都会被指定一个迭代计算任务进行处理,并决定了迭代计算的并行粒度。于此同时,RDD还具有一个分片函数,用于对RDD数据集进行分片,包括基于哈希的分片函数HashPartitioner和基于范围的分片函数RangePartitioner;③列表:用于存储RDD数据集中每个分片的有限位置,在HDFS文件系统中,该列表存储的是RDD数据集中每个分片所在块的位置。通过该表对RDD数据集中各个分片位置的存储,我们可以实现“移动数据不如移动计算”的思想,在迭代计算任务调度过程中,尽可能地将计算任务分配给将进行迭代计算所需资源所在的位置。
同时,RDD只能基于稳定物理存储,并通过在其中的数据集合对其它已有的RDD执行确定性变换操作来创建。当RDD数据集创建完毕后,可以在RDD数据集上进行两种数据操作,分别是①转换Transformation:在现有RDD数据集的基础上创建一个新的RDD数据集;②动作Action:在RDD数据集执行完迭代计算后,将迭代结果返回给Driver组件。
表1和表2分别列举了迭代计算系统RDD算子模块中重要的转换操作和动作操作,其中partition(Dataset)、merge(otherDataset)、loss(lossDataset)为多区域大规模迭代计算系统新增的3个RDD算子转换操作,分别用于多区域迭代计算过程中的数据分区、合并区内迭代计算结果、区内迭代计算结果的误差。其中,多区域迭代计算的编程模型如下所示。


表1 RDD数据集的转换操作表

表2 RDD数据集的动作操作表
3 实验验证
为了保证实验结果的正确性和真实性,我们使用真实的物理计算机作为分布式集群进行实验,其中包括1台Master控制节点和12台Slave计算节点。K-Means算法的测试数据集我们采用山西联通真实的数据集。设多区域迭代计算模型中的迭代数据量为D,其中包含全集数据量以及区内数据量,同时区内数据量随着全集数据量的增长而增长;区内迭代数据的分区记为P。K-means测试数据的相关信息如表3所示。

表3 K-Means测试数据集
全部实验结果如表4所示,其中分别测量了多区域迭代与Spark迭代的迭代时长,并通过计算优化比例得出了多区域迭代的优化效果,优化比例的计算公式如下。

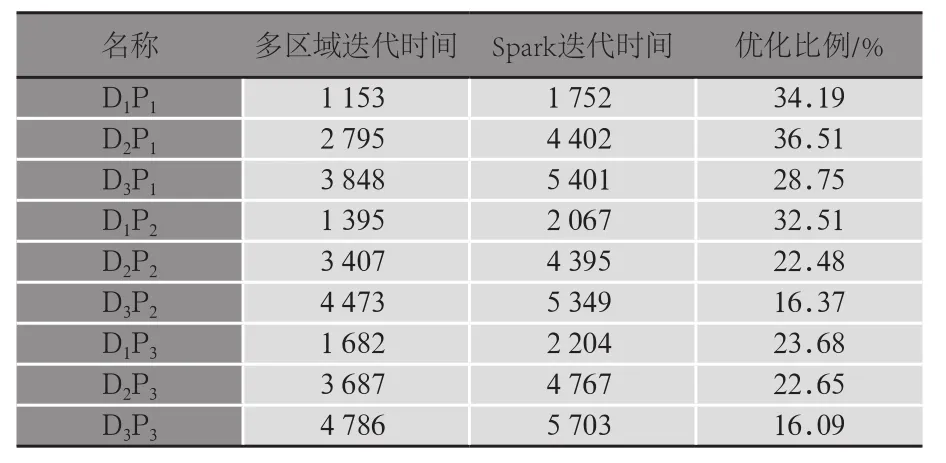
表4 实验结果
图4分别从不同数据量和不同分区数的角度展示了部分实验结果。由于K-Means算法的迭代计算轮数对初始点的选择非常敏感,为保证实验结果的正确性,我们对每一组测试用例都运行了5次K-Means算法从而求取平均值进行分析比较。由图4可知以下结论:①在各种条件下,多区域迭代计算框架的性能较传统的Spark都有明显的优化。优化比例最低也在15%至20%之间。②对于多区域迭代框架和Spark,数据量对于性能的影响大于分区数目的影响,其中数据量越大,或者分区数目越多,迭代性能越差。③我们设计的多区域迭代计算框架在给定用例下较Spark有性能优势。
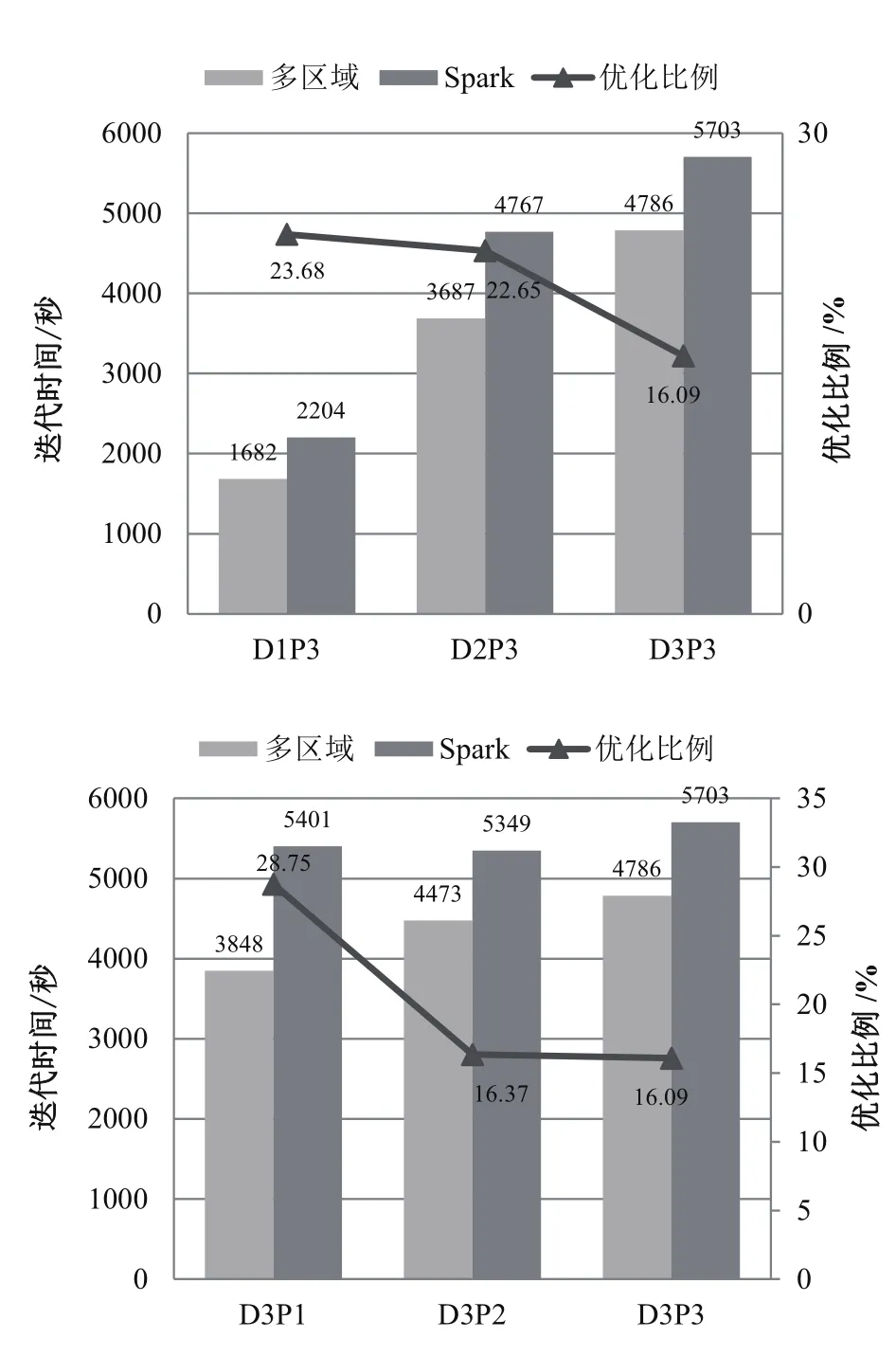
图4 多区域迭代计算框架与Spark的性能对比
4 结论与展望
多区域大规模多级迭代计算的研究来源于中国联通山西省分公司的具体数据汇集方式和分析需求,该研究成功提高了多地市数据分析和省级数据分析的效率,减少了省级数据分析的时间,减少了数据传输时延,有着确切的实际应用效果。然而,本研究仍处于初级阶段,还有许多问题需要解决。首先,多区域迭代计算模型并非适用于所有的迭代算法,而且模型角度也不具有足够的抽象性。其次,多区域迭代较全集迭代是有精度损失的,从实验和实际证明该损失对于部分适用的迭代算法可以忽略不计,同时对损失的量化评估,还需要进一步研究。
猜你喜欢
词学(2022年1期)2022-10-27
计算机工程与应用(2022年2期)2022-01-25
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
军事运筹与系统工程(2019年4期)2019-09-11
火控雷达技术(2018年4期)2019-01-15
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
