
恶意软件新型检测方法
2018-11-16 09:34刘耀宗李千目
软件 2018年10期
姚 键,刘耀宗,侯 君,凌 飞,4,李千目
恶意软件新型检测方法
姚 键1,刘耀宗2,3*,侯 君3,凌 飞3,4,李千目3
(1. 国家税务总局北京市税务局第一分局,北京 100089;2. 五邑大学 智能制造学部,广东 江门 529020 3. 南京理工大学 计算机科学与工程学院,江苏 南京 210094;4. 南京联成科技发展股份有限公司 江苏省研究生工作站,江苏 南京 211800)
每年有数以千计的恶意软件出现,这已经成为一种严重的安全威胁。目前的杀毒软件系统试图通过人工启发式生成来检测这些新型的恶意程序。这种方法的困难在于,成本极高,且确定恶意程序的过程中,即分析程序和生成签名时,系统处于程序的危险中,经常会导致检测失效。本文提出一种针对未知工控恶意软件的自动挖掘框架。这个框架自动发现现有数据集的模式,使用模式去检测一组新的恶意二进制文件。该方法在检测工控未知恶意软件的效率显著高于当前传统的检测方法。本文研究不仅对交通、电网等行业能有重要意义,对税务系统中的税控机、自助办税这类设备也有显著的价值。
网络攻击;网络流量;信息安全
0 引言
恶意软件是一段执行恶意功能的程序,比如危害工控系统安全、破坏工控系统或者在未经过用户允许的情况下获取敏感信息[1,2]。在工控安全领域检测工控恶意软件不是一个新问题[3]。早期的方法使用签名去检测工控恶意软件。这些签名由许多不同的属性组成:文件名、文本串或字节码[4]。研究思路集中在保护系统使其不受工控恶意软件创造的安全漏洞所侵害。例如,专家们手工分析可疑程序,发现签名不同于其他工控恶意软件或安全程序的工控恶意软件[5]。这种分析方法尽管精确,但是代价高昂、速度缓慢。目前,检测工控恶意软件的方法是在已知工控恶意软件库中进行匹配[6]。例如,有研究者开发了一个可以自动提取工控恶意软件签名的静态方法[7]。文献[8]提出了一个过滤恶意代码的方法,这个方法是基于“迹象”来检测恶意代码的[8]。这些是通过观察恶意代码的特征来手动设计的。不幸的是,一个新的工控恶意软件可能不包含任何已知的签名,导致传统的基于签名的方法无法检测。为了解决这个问题,有研究者提出手动生成启发式分类器[9]。这种处理过程甚至比生成签名代价还要大,研究人员曾将人工神经网络应用到检测引导扇区的恶意二进制文件[10]。ANN是扩展人类认知的神经网络模型的分类器。使用ANN分类器,将所有引导扇区工控恶意软件的字节作为输入,研究人员可以成功识别80-85%未知的引导扇区可执行文件,误判率低于1%[11]。但是他们不能找到将ANN分类器应用到另外95%的计算机恶意二进制文件上的途径。
本文提出在大量数据中发现模式,使用数据挖掘算法在一组恶意和良性的可执行文件上训练多分类器,例如字节码,并使用这些模式在相似数据中去检测未来的实例(新实例),利用分类器检测新的工控恶意软件。这些二进制文件首先被静态分析并提取特征属性,然后分类器会训练这些数据的子集。分类器是由数据挖掘算法在训练数据集上得到的一个规则集或是检测模型。
1 检测思路
本文通过探索若干数据挖掘方法来分析和找寻准确的探测器用于未知二进制文件。首先在实验中,集中大量的公共来源的程序,并将这些程序分成两个类别:恶意的和良性的可执行文件。为了使数据集标准化,实验使用了MacAfee更新的病毒扫描器,将程序打上恶意或者良性可执行文件的标签。由于病毒扫描器的更新,且病毒来源于公开渠道,本文假设病毒扫描器为每一种恶意病毒生成了签名。其次,将数据集分开为两个子集:训练集和测试集。数据挖掘算法利用训练集生成规则集。本文利用测试集检验分类器在未知实例上的准确性。接下来,本文从数据集的每一个实例中自动提取它们的二进制配置文件,然后利用分类器从配置文件中提取特征。在数据挖掘框架中,特征就是从数据集中提取出的属性,比如字节序列,分类器可以利用这些属性生成检测模型。利用不同的特征,训练出一组数据挖掘分类器来辨别良性或工控恶意软件。注意,提取的特征是二进制的静态属性,不需要执行二进制文件。
本文使用系统资源信息、字符串和从数据集的工控恶意软件中提取出的字节序列作为不同类型的特征,本文使用了三种学习算法:
•基于规则的布尔规则
•给定一组特征的某一类概率的概率方法
•结合多个分类器输出的多分类器系统
本文设计了一个自动的签名生成器,将数据挖掘方法和传统的基于签名方法比较。由于商业的扫描器包含数据集中所有工控恶意软件的签名,因此无法使用现成的病毒扫描器模仿新工控恶意软件的检测。像数据挖掘算法,基于签名的算法仅仅被允许在训练集上生成签名。这允许本文的数据挖掘框架在新数据上能与传统扫描器公平对比。为了量化表示本文方法的表现,本文展示了正确肯定、正确否定、错误肯定、错误否定计数的表格。正确肯定是恶意例子被正确标注为恶意,正确否定是良性实例被正确分类。错误肯定是良性实例被算法错误归为工控恶意软件,错误否定是工控恶意软件被错误归为良性程序。为了评价这些表现,本文计算了错误肯定率(假阳性率)和检测率。
根据上述思路,本文的数据集由4266个程序组成,其中有3265个工控恶意软件,1001个无害程序。数据集中没有程序副本,每个程序都由商业病毒扫描器标记为恶意或良性。工控恶意软件是从不同的FTP网站上下载的,被商业病毒扫描器贴上正确的类别标签(恶意的或是良性的)。数据集由5%的特洛伊木马和95%的工控病毒。本文也检查数据的PE(可移植的可执行文件)格式的子集。由PE格式的可执行文件组成的数据集包含206个良性程序和38个工控恶意软件。
2 LibBFD数据处理与特征分析
首先,使用LibBFD,仅检测PE文件的子集。然后,使用更多的普通方法提取所有类型的二进制文件的特征。为了从Windows二进制文件中提取源信息,本文使用GNU二进制目录检索文件。GNU二进制目录检索文件套件工具能够在Windows上分析PE二进制文件,在PE或者通用目标文件格式(COFF)中,程序标题由一个COFF标题、一个选配标题、磁盘操作系统(MS-DOS)和一个文件签名组成。PE标题本文使用libBFD(包含二进制目录检索文件的库)来提取目标格式的信息。PE二进制文件的目标格式给出了文件大小、动态链接库(DLLs)名称和DLLS及重定位表的函数调用的名称。从目标格式中本文提取特征集,用于组成每个二进制文件的特征向量。
为了理解资源如何影响二进制文件的行为,本文利用三种特征来完成本文的试验:二进制文件使用的DLLs(动态链接库)的清单;二进制文件的DLLs的函数调用清单;每个DLL的函数被调用的次数。
第一步,剖析二进制文件使用的DLLs。加载二进制文件作为特征,如式(1)所示。特征向量包含30个布尔值,表示此文件是否使用了DLLs。并不是每个DLL都被所有二进制文件使用,大部分文件调用相同的资源。例如,几乎所有的二进制文件调用了GDI32.DLL,这是Windows的图形设备接口,是Windows操作系统的核心组件。
┑advapi32∧avicap32∧……∧
winmm∧┑wsock32 (1)
以式(1)为例,式(1)中给出的向量至少由两项未使用的资源组成:ADVAPI32.DLL(高级的Windows API)和WSOCK32.DLL(Windows套接字API)。同样,向量至少包含两项使用的资源:AVICAP32.DLL(AVI捕捉API)和WINNM.DLL(Windows多媒体API)。
第二步,二进制文件性能分析使用DLLs和函数调用作为特征。这一步与第一步类似,但增加了函数调用的信息。特征向量由2229个布尔值组成,一些DLL有着相同的函数名,记录了这些函数是哪个DLL的。式(2)是DLL及每个DLL内部的函数调用,式(2)中给出的样本向量至少包含四个资源。ADVAPI32.DLL的两个函数调用:AdjustTokenPrivileges()和GetFileSecurityA(),还有WSOCK32. DLL的两个函数调用:recv()和send()。
advapi32.AdjustTokenPrivileges()∧advapi32. GetFileSecurityA()∧……∧wsock32.recv()
∧wsock32.send() (2)
第三步,统计每个DLL内部不同函数调用的次数。特征向量包括30个整型值。这个概要文件粗略测量DLL使用特定二进制文件,统计每个资源调用数目,而不是列举引用函数。比如,如果一个程序仅仅调用WSOCK32.DLL的recv()和send()函数,计数为2。注意:不统计函数可能被调用的次数。
3 GNU strings数据处理与特征分析
由于非PE可执行文件同样有着字符串编码,可以使用这些信息来给所有的4266个项目数据集分类,而不是小的LibBFD数据集。为了从第一个有4266个程序的数据集中提取特征,本文使用GNU字符串程序。这个字符串程序可以从任何文件中提取连续可打印字符。通过干净程序中的相似字符串,能够从中区分工控恶意软件,通过工控恶意软件中的相似字符串,可以从中区分干净程序(通过相似字符串来区分工控恶意软件和干净程序)。二进制文件中每个字符串都作为一个特征。在数据挖掘步骤,本文讨论频度分析如何在数据集的整个字节序列上工作。
一个二进制文件中的字符串可能由重复代码片段、作者签名、文件名、系统资源信息等组成。这个检测工控恶意软件的方法已经被反工控病毒社区用来生成工控恶意软件的签名。从可执行文件中提取字符串并不如特征提取那样强健,因为它们很容易被改变,因此本文分析另一个特征,字节序列。
字节序列特征集中最后一个特征,本文利用整个4266个的数据集。本文利用hexdump来将二进制文件转成十六进制文件。字节序列特征最具信息性,它表示可执行文件的机器代码,而不是像LibBFD特征这样的资源信息。第二,分析整个二进制文件可以给出非PE可执行文件的更多信息,strings方法则不行。生成hexdump之后,可以得到如图1中展示的特征,其中,每一行代表机器代码指令的一个短序列。
假设工控恶意软件中有一些相似指令,可以通过它们来区分出干净程序,干净程序中也有相似指令来区分工控恶意软件。类似于strings特征,二进制文件中每个字节序列都被当做一个特征。

图1 Hexdump例子
4 算法设计和分析
本文使用2个不同的数据挖掘算法来生成有不同特征的分类器:Naïve Bayes、Multi-Classifier系统。
基于签名检测方法是工业中最常用的算法。这些签名被选择来区分工控恶意软件与干净文件。签名通过某个领域的专家生成或者通过自动方法生成。典型地,签名被用来说明特定工控恶意软件的独特属性。我们用这个方法实施一个基于签名的扫描器。
首先,我们计算只在工控恶意软件类中发现的字节序列。这些字节序列串接在一起成为每个工控恶意软件样本唯一的签名。因此,每个工控恶意软件签名包含只在工控恶意软件类中发现的字节序列。为了使签名唯一,每个样本中发现的字节序列串接在一起构成一个签名。由于训练时一个字节序列仅会在某类中发现,也可能在另一类中出现,这就导致了测试的假阳性(误报)。
其次,我们使用的算法是一个归纳规则(诱导性规则)学习者。这种算法生成一个由资源规则组成的检测模型,被用于检测未知的工控恶意软件样本。此算法使用libBFD信息作为特征。算法是基于规则的学习者,建立规则集来确定分类,是错误总数降到最小。错误被定义为训练样本被规则误分类的数目。
正例被定义为工控恶意软件,反例被定义为良性程序。初始假设Find-S由<⊥,⊥,⊥,⊥>开始。假设最具体的,因为在尽可能少的样本上为真,none。检查Table 2中第一个正例
经过两个正例的结果假设是
接下来,引入Naïve Bayes分类器。Naïve Bayes分类器计算给出特征的一个程序是工控恶意软件的似然估计。本文使用strings和字节序列数据来计算一个二进制文件是恶意的概率。本文计算一个包含特征集F的程序的类,定义C为分类集上的一个随机变量:良性和恶意的可执行文件。本文想要计算P(C|F),即程序在某类中的概率,程序包含特征集F。为了训练分类器,我们记录了每个类中有多少程序包含唯一特征。我们使用Naïve Bayes算法,为字节序列和strings计算最可能的类。
每个数据挖掘算法生成自己的规则集来评估新样本。每个算法的规则集能合并为一个扫描器来检测工控恶意软件。规则的生成仅需要定期来做。
一个工控恶意软件符合四个假设之一:
1. 不调用user32.EndDialog(),调用kernel32. EnumCalendarInfoA()
2. 不调用user32.LoadIconA(),kernel32.GetTempPathA()和advapi32.dll中的其它任何函数
3. 调用shell32.ExtractAssociatedIconA()
4. 调用msvbbm.dll和the Microsoft Visual Basic Library中的任何函数
如果一个二进制文件不符合Figure 5中所有恶意二进制文件的假设,那么它会被标记为良性。
由Multi-Naïve Bayes算法生成的规则集是每个朴素贝叶斯分类器组件生成的规则的集合。对每个分类器,都有一个规则集。不同分类器的概率规则可能不同,每个分类器训练的基本数据是不一样的。为了评估本文方法,定义:
•正确肯定(TP),工控恶意软件样本被归类为恶意的数目
•正确否定(TN),良性程序被归类为良性的数目
•错误肯定(FP),良性程序被归类为恶意的数目
•错误否定(FN),工控恶意软件被归类为良性的数目
检测率是所有工控恶意软件中被标记为恶意的百分比。假阳性率是良性程序中被标记为恶意的百分比,别称误警。检测率定义为TP/(TP+FN),假阳性率定义为FP/(TN+FP),总准确度是(TP+TN)/ (TP+ TN+FP+FN)。实验的结果如表1所示。
表1 实验结果
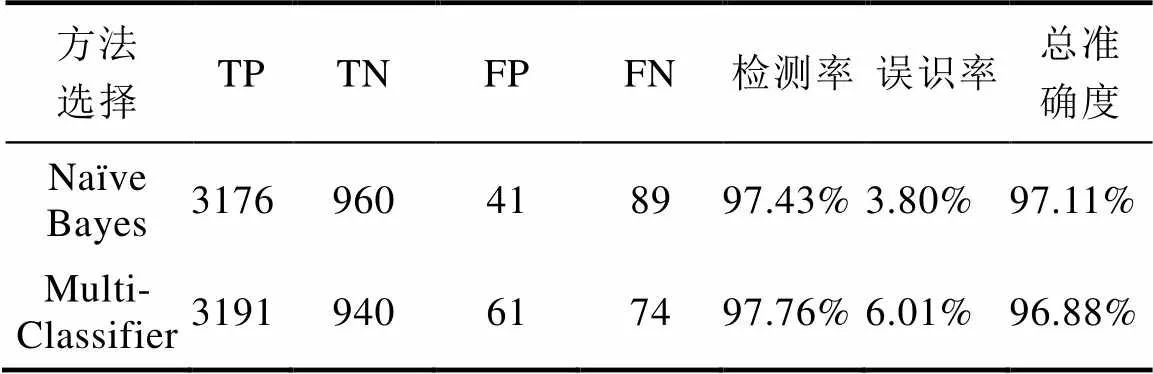
Tab.1 Experimental Result
5 结论
本文提出一种针对未知工控恶意软件的自动挖掘框架。这个框架自动发现现有数据集的模式,使用模式去检测一组新的恶意二进制文件。通过与传统的基于签名(基于特征)方法比较,该方法在检测工控未知恶意软件的效率显著高于当前传统的检测方法。本文研究对税控机、自助办税设备也很有意义。
[1] LIU Lixia, LING Ren, BEI Xiaomeng, GUO Rongwei, et al. coexistence of synchronization and anti-synchronization of a novel hyperchaotic finance system[C]. IEEE Proceeding of the 34th Chinese Control conference, Hangzhou, 2015: 8585- 8589.
[2] 孙哲, 巫中正, 李千目. 基于网络流量的安全可达性推理方法[J]. 软件, 2018, 39(04): 36-43.
[3] 孙哲, 巫中正, 李千目. 流量攻击图的建模与生成方法[J]. 软件, 2018, 39(04): 48-52.
[4] Li QM, Zhang H. Information Security Risk Assessment Technology of Cyberspace: a Review. INFORMATION. 2012, 15(11): 677-683.
[5] 鲍克, 严丹, 李富勇, 等. 车联网信息安全防护体系研究[J]. 软件, 2018, 39(6): 29-31.
[6] Li QM, Li J . Rough Outlier Detection Based Security Risk Analysis Methodology. CHINA COMMUNICATIONS. 2012, 9(7): 14-21.
[7] 孟晨宇, 史渊, 王佳伟, 等. Windows 内核级防护系统[J]. 软件, 2016, 37(3): 16-20.
[8] Li, QM; Hou, J; Qi, Y; Zhang, H. The Rule Engineer Model on the high-speed processing of Disaster Warning Information. DISASTER ADVANCES. 2012, 5(4): 1196-1201.
[9] 李磊. 数据通信网络安全维护策略探讨[J]. 软件, 2018, 39(7): 191-193.
[10] 苏奎, 张彦超, 董默. 一种计算机安全评价系统设计[J]. 软件, 2015, 36(4): 119-122.
[11] 赵健, 桑笑楠, 马迪扬等. 智能电网安全策略切换判决算法设计[J]. 软件, 2015, 36(9): 70-77.
New Industrial Control Malware Detection Method
YAO Jian1, LIU Yao-zong2,3*, HOU Jun3, LING Fei3,4, LI Qian-mu3
(1. The first branch of the Beijing Municipal Taxation Bureau of the State Administration of Taxation, Beijing, 100089; 2. Intelligent Manufacturing Department, Wuyi University, Jiangmen, 529020; 3. School of Computer science and Engineering, Nanjing University of Science and Technology, Nanjing 210094; 4. Jiangsu Postgraduate Workstation, Nanjing Liancheng Technology Development Co., Ltd, Nanjing 211800)
Thousands of industrial malware appear every year, which has become a serious security threat. The current industrial anti-virus software system attempts to detect these new malicious programs through artificial heuristic generation. The difficulty with this approach is that it is extremely costly, and in the process of identifying malicious programs, that is, when analyzing programs and generating signatures, the system is at risk of the program, often causing detection failure. This paper proposes an automatic mining framework for unknown industrial control malware. This framework automatically discovers the patterns of existing datasets and uses patterns to detect a new set of malicious binary files. Compared with the traditional signature-based (feature-based) method, the method is significantly more efficient in detecting industrially unknown malware than current traditional detection methods. This research not only has important support for transportation, power grid and other industries, but also has significant value for tax control machines and self-service taxation in the tax system.
Network attack; Network traffic; Information security
TP391
A
10.3969/j.issn.1003-6970.2018.10.001
江苏省重大研发计划(BE2017100、BE2017739);赛尔下一代互联网创新项目(NGII20160122)
姚键(1971-),高级工程师,博士,研究方向为智慧税务、大数据、网络安全;侯君(1982-),助理研究员,研究方向为数据分析、高等教育;凌飞(1984-),高级工程师,研究方向为信息安全。
刘耀宗(1974-),讲师,研究方向为信息安全。
姚健,刘耀宗,侯君,等. 基于数据挖掘的新型恶意软件检测方法[J]. 软件,2018,39(10):01-05
猜你喜欢
中等数学(2021年8期)2021-11-22
销售与市场(营销版)(2021年10期)2021-11-21
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
销售与市场(营销版)(2019年6期)2019-06-21
网络安全技术与应用(2017年9期)2017-09-20
中国设备工程(2017年8期)2017-05-10
中国设备工程(2017年7期)2017-04-10
信息安全与通信保密(2016年3期)2016-08-23
自动化学报(2016年5期)2016-04-16
