
基于A*算法优化的片上网络源路由算法
2018-11-14 08:29荆明娥
复旦学报(自然科学版) 2018年5期
来 耀,荆明娥
(复旦大学 专用集成电路与系统国家重点实验室,上海 201203)
片上网络(Networks-on-Chip, NoC)是片上系统(System on a Chip, SoC)重要的硬件形式之一,其将片上系统的结点以网络的形式相连.片上网络路由算法是指从一个结点发送数据包到另一个或多个指定的结点而选择其网络上的传输路径的算法.好的路由算法不仅需要考虑使单个数据包的传输延时最短,还要考虑整个片上网络工作的整体延时,并且需要一定的防拥塞、防死锁和容错机制.
片上网络的路由算法从其路由结果的决策地点来分,可分为源路由和分布式路由[1].分布式路由是指路由的下一步决策是根据当前数据包所在的路由结点完成,因此整个路由决策是由数据包所经过的所有结点共同决定的.而源路由是指路由的决策在数据的发送结点(即源结点)已经全部完成,该路由决策将附加在数据包的头部,中间的传输结点根据数据包的路由信息决定下一步的发送结点.对于分布式路由,一般途经的结点只做出下一步的路由决策,因此只需考察其周围结点的状况,因此分布式路由一般更易于硬件实现,但缺少决策的宏观性.对源路由而言,源结点一般需要得到整个网络的信息再产生路由决策,可以做出较为宏观的决策.
在源路由算法中,最著名的是链路状态算法(NoC-LS)算法[1],其思想是每个片上网络的结点都存储一份整个网络上的状态信息(链路延时、故障等).当需要进行路由决策时,在源结点处根据存储的整个网络结点的延时和故障信息使用图论中最短路径算法找出最佳路径.该路由算法具有在任何网络上运行的通用性,但没有充分利用片上网络拓扑结构的特性,因此其效率不够高.本文将A*寻路算法应用于片上网络中,可以更好地利用片上网络的拓扑结构.
1 片上网络路由的问题描述
2D-Mesh的片上网络可视为N×N的网格,每个片上网络的结点对应于网格中的一个格点.则片上网络的源路由问题可看成网格中源结点(s)到目的结点(t)的寻路问题.由于片上网络处于实时动态状态中,其中将出现拥塞结点和不可用结点.对于拥塞自适应的路由策略需要尽可能少的通过拥塞结点,对于容错的路由策略需避开不可用结点[2].
一个片上网络结点路由问题的例子如图1(见第606页)所示,其黑色结点表示不可用结点,路由算法则需从s到t找出一条最优的路径.当源路由算法得到路由策略后,将该路径信息附加在将要发送数据包的头部,沿途结点根据该信息将数据包转发至下一个结点.
2 BFS寻路算法

图1 片上网络路由问题示意图Fig.1 Diagram of NoC routing problem
BFS算法即广度优先搜索(Breadth First Search, BFS)算法,其基本思想是设置两个线性表: open表和close表.open表使用队列维护.首先将源结点放入open表中.每次从open表头中取出结点,往周围4个方向扩展结点,若扩展的结点不在close表中,则将结点放入open表尾.扩展完成后将该结点放入close表中,即设为已访问过.然后不断地从open表头中取出结点进行下一步扩展,直至找到目标结点为止.
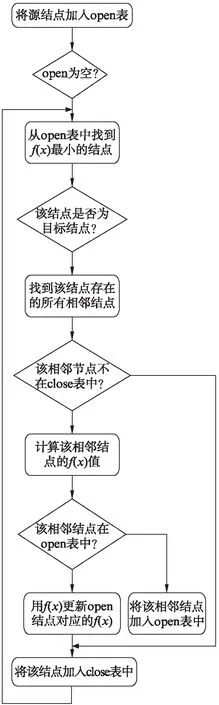
图2 A*算法流程图Fig.2 Flow chart of A* algorithm
该算法的优点是只要源结点与目的结点之间存在路径,就一定能找到通向目的结点的最短路径,但其缺点是具有盲目性,往往扩展出许多远离目的结点的路径,因而其代价较高,影响了整个片上网络工作的效率.对于N×N的2D-Mesh结构,该算法的最坏情况是扩展出网格中的所有结点,因此时间复杂度是O(N2)的[3].
3 A*寻路算法
3.1 启发式函数的定义
A*寻路是应用最为广泛的地图寻路算法,其核心思想是启发式函数的设计[4].
对于网格中的每一个结点x,都存在一个启发式函数的值f(x).其中:f(x)=g(x)+h(x);g(x)是从源结点s到当前结点x已经走过的最短距离(路由步数),是一个已知量;h(x)为当前结点x到目的结点的预测距离,一般设为到目的结点的曼哈顿距离.
3.2 算法的执行过程
算法运行的过程中需要使用open表和close表分别存储待扩展的结点和已扩展的结点.算法的初始化将源结点s放入open表中.每次从open表中找到f(x)最小的结点x,依次取出该结点的相邻结点y,若y在close表中,则忽略;若y在open表中,则将用当前计算出的f(y)更新open表中对应结点的f(y)值;若既不在open表中也不在close表中,则将扩展出的结点加入open表.直到扩展出目的结点t为止.可以看出当h(x)=0时,A*算法就是BFS算法.
算法流程图如图2所示.
3.3 片上网络路由算法的特殊性
由于A*寻路算法产生的路由策略会在片上网络中形成环路.因此若直接运用到片上网络的路由算法中,将产生死锁,即数据包循环占用缓存导致其无法继续传输.
因此将A*寻路算法应用于片上网络路由算法中,需要增加虚通道来防止死锁的出现.虚通道方法是一种应用于输入/输出通道的算法,即在每个结点的输入输出缓冲区,划分出具有不同编号的逻辑通道.对于设置虚通道解决死锁的方法也有很多,本文中采用在x方向设置两条虚通道x0及x1,而在y方向的通道不设置虚拟通道的方式[5],将整个网络分成上升子网和下降子网.上升子网包含x0和y+(y轴正向传输通道),下降子网包含x1和y-(y轴负向传输通道).当目的结点在发送结点的上方时,使用上升子网路由;当目的结点在发送结点的下方时,使用下降子网路由.因此任意数据包的传输过程将只使用其中的一个子网,因而消除了环形依赖[6].
对于A*算法的具体修改方案为: 在寻径时需要记录最近一次在y方向的路径是正向还是负向.当数据包将要转向x方向寻径时,若上一次在y方向的寻径是正向,则使用虚拟通道x0,否则使用虚拟通道x1.
4 路由算法的优化
4.1 open表的优化
A*算法中open表需要进行插入结点、删除结点、找出代价最小的结点和找出对应结点更新的操作.因此对open表采用何种数据结构对算法效率影响明显.目前对open表采用的数据结构主要有未排序的数组或链表、排序数组、排序列表、索引数组、散列表、二叉堆、伸展树、顶部堆(Heap on Top, HOT)队列等[4].不同的数据结构各种操作的时间复杂度各不相同,均有各自的常数时间消耗以及空间复杂度.因此并不能简单的认为某一种数据结构一定优于另一种数据结构.
对于小规模的片上网络,由于高级数据结构操作复杂,汇编成的指令数也较多,导致常数时间过大,因此更适合用数组或链表来实现open表.对于大规模的片上网络,随着数组和链表查找和插入的时间复杂度逐渐上升,此时使用二叉堆、伸展树等数据结构的算法能大大降低open表操作的时间复杂度.
4.2 启发式函数的选择
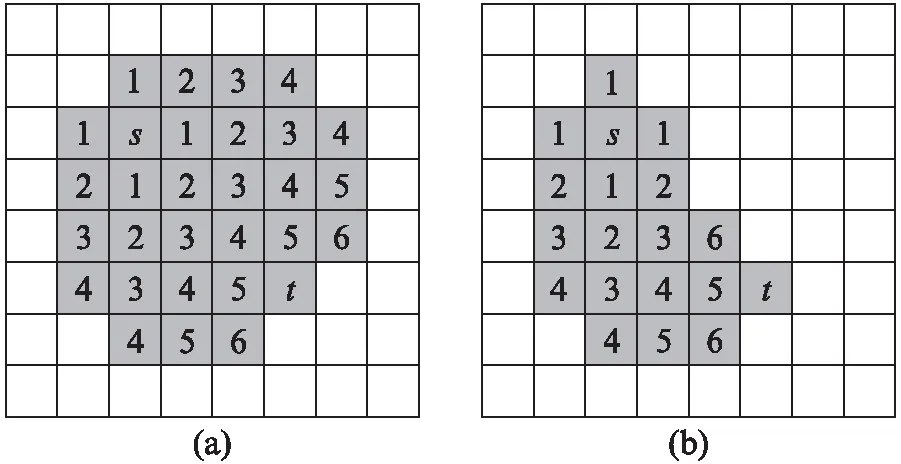
图3 启发式函数权值的选择对扩展结点数目的影响Fig.3 Influence of selection of Heuristic function weights on the number of extended nodes
对于启发式函数f(x)的选择往往决定寻径的效率和寻径的结果.为了使A*算法可以找到源结点到目的结点的最短路径,需使h(x)不小于x结点到目的结点的实际最短距离.因此上文中提到的h(x)为当前结点x到目的结点的曼哈顿距离是保证找到最短路径的下界.此时若增大h(x),算法将优先扩展目的结点附近的结点.在故障结点数少的情况下,将提高路径搜索的效率,但却不能保证找到最短路径.因此,当片上故障率较低时,可以适当提高h(x)相对g(x)比例,牺牲路径长度而加快寻径速度即:
f(x)=g(x)+w(x)h(x)w(x)>1,
(1)
其中:w(x)既可以为大于1的常数,也可以根据x的具体情况来定义w(x).
图3(a)是w(x)=1时的扩展结点情况,图3(b)是w(x)=2是的扩展结点情况,可以看出增大预测函数的权重可以有效减少算法运行时扩展的结点数.
4.3 双向搜索
A*算法也可以借鉴双向BFS算法的双向搜索思想,同时从源结点和目的结点开始扩展结点.选择启发式函数:
f(x,y)=g(s→x)+h(x→y)+g(t→y).
(2)
每次找出使得f(x,y)最小的结点x与结点y进行扩展,减少总体扩展结点的个数,并且可以应用并行计算,提高寻径效率.
4.4 维片上网络的扩展
目前的3维片上网络几乎都采用网格结构,即3D上的Mesh结构.其又可分为两类:
(1)z方向的通道采用相邻结点相连结构(3D-Mesh结构);
(2)z方向的通道采用总线结构(叠层Mesh结构)[7].
对于情况(1),只需要在2D-Mesh上的A*寻路算法稍加修改即可得到3D-Mesh下的A*寻路算法.首先将每次扩展的结点变为6个,增加Up和Down 2个扩展方向.将启发式函数h(x)扩展为3维上的两点间曼哈顿距离即可:
h(x)=|xx-xt|+|yx-yt|+|zx-zt|.
(3)
对于情况(2),为了避免数据包占用总线的时间,一般只允许数据包通过总线1次.因此当扩展的结点一旦改变z坐标,则必须直接进入与目的结点同层的结点,并且在今后的扩展中都不能改变z(即此时退化为2维A*寻路).
5 路由算法的测试
测试程序分别使用了单向BFS寻路算法和A*寻路算法,在CPU Intel Core i5-6200U 2.30GHz,内存8G的PC环境中进行测试.采用黑盒测试法,对于不同规模的片上网络,对于30%的不可用结点率,分别随机生成5000组网络状态,主要测试其时间效率和空间占用的情况.
分别测试BFS算法、A*算法以及加速A*算法等3种算法.A*算法与加速A*算法均采用二叉堆结构的open表,其中加速A*算法的启发式函数为f(x)=g(x)+2h(x).
5.1 算法测试结果
对于算法的时间效率,对不同的算法测试其在同一个PC环境下5000组数据寻径的总耗时.而对于算法的空间占用,我们采用测试5000组数据中(不包括源结点与目的结点不互通的情况)open表与close表最大存储的结点数来量化算法的空间占用情况.算法测试结果如表1所示.

表1 算法时间效率与空间占用测试结果
算法在运行过程中找出的平均路径长度与平均扩展结点数如表2所示.

表2 算法平均路径长度与平均扩展结点数测试结果
5.2 算法测试分析
从测试结果可以看出,对于越大规模的片上网络,使用A*算法的时间效率优势越大.这是由于在小规模的片上网络中,A*算法与BFS算法扩展出的结点数相差不多.而由于A*算法由于每次需要在open表中插入、删除、查找结点,对于使用二叉堆的open表来说,其时间复杂度为O(log2N),其中N为open表的大小.而BFS算法由于其每次加入的结点代价都是严格递增的,只需要使用队列实现open表,因此插入、删除的时间复杂度均为O(1).因而在小规模的片上网络中,BFS算法甚至会优于A*算法.
在片上网络规模逐渐增大时,由于BFS算法的盲目性,其在找到目标结点之前,将在片上网络所有方向扩展目标结点.由于大规模网络导致BFS算法长时间无法扩展到边界,此时使用BFS算法扩展的结点数将远远多于A*算法的结点数.因此A*算法的优势将逐渐显现出来.对比用时数据可以看出,在16×16及以上规模的片上网络中,A*算法的用时几乎均小于BFS算法用时的50%,而加速A*算法的用时均小于BFS算法的30%,时间效率大大提升.
从算法的空间占用上来看,一般情况下close表的空间占用远大于open表,因此close表的大小可以近似认为扩展的总结点数,而A*算法扩展的结点远少于BFS算法,因此A*算法的close表的空间占用也优于BFS算法.从测试结果可以看出,不可用结点数越少,A*算法的空间占用的提升更明显,这是由于路径越简单,A*算法的预测函数越准确,其扩展的结点数也就越少.即使在30%不可用结点数的情况下,A*算法的空间占用约为BFS算法空间占用的70%,加速A*算法的空间占用小于BFS算法空间占用的50%,可以有效减少需要的存储空间.
根据算法最后得到的平均路径长度来看,BFS算法与A*算法路径长度相同,其均可以找到源结点到目的结点的最短路径.对于加速A*算法而言,其在有不可用结点的情况下,由于其优先扩展预测距离小的结点,将有一定概率找不到最短路径.在64×64规模的片上网络上,在2394组合法数据中,只有68组数据(2.8%)的加速A*算法可以找到最短路径.因此传送一个数据包占用的结点数也相应的增多,更容易引起片上网络结点的拥塞.
6 结 论
片上网络技术的发展使得原本只能出现在计算机网络的源路由算法可以应用到片上网络中,而我们应用迷宫寻径的各种理论来优化源路由算法.此时每一个片上网络的结点都可以看作是一个独立的CPU单元,从而可以运行A*算法等源路由算法,然后根据整个片上网络的结点状态计算出最佳的路由路径.
对于A*算法还可以加入对片上网络各结点的拥塞情况,从而实现拥塞自适应的路由[8].此时需要对各片上结点赋予拥塞度的权值,通过权值的确定以及启发式函数的调整使得网络路由可以有效地避免片上网络的拥塞结点,进一步降低数据包的传输时间.源结点的路由算法开销大于分布式的路由算法,但其采用的路由策略更具有全局性,因此适用于结点为独立处理器的片上网络.因此,当半导体技术飞快发展的今天,片上结点的源路由算法将会逐渐运用到片上网络中.
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
电脑与电信(2021年9期)2021-12-21
电子制作(2021年14期)2021-08-21
铁道通信信号(2020年9期)2020-02-06
网络安全和信息化(2018年4期)2018-11-09
网络安全和信息化(2018年3期)2018-11-07
电信科学(2016年11期)2016-11-23
电测与仪表(2014年16期)2014-04-22
电子设计工程(2014年12期)2014-02-27
