
Method of Generating Ontologies and InstanceMatching for Material Experiment Data
2018-11-14 08:29,
复旦学报(自然科学版) 2018年5期
,
(School of Computer Engineering and Science, Shanghai University, Shanghai 200444, China)
Abstract: With the development of information technology, applications such as online data sharing have become increasingly popular. The multiform data types in material experimental data sets cause information problems, increasing the challenges of discovering relationships among sources. To solve this data sharing problem, a rule-based automatic algorithm that transforms various complex tables in the materials research field to ontology information is proposed in this paper. Furthermore, an instance-matching method based on TF-IDF algorithm and its two improving schemes are also proposed. The experimental results indicate that the existing ontology matching tools work well with the ontology results, which are generated approximately five times faster than the approach of generating databases from complex tables. But the common tools work not well in instance matching. This paper analyzes the reason and proposes an improved matching scheme based on TF-IDF algorithm to the current situation of the data source in the material field, which lacks of domain knowledges and dictionary. The method explores an implementation route for the construction of the entire material data ecological environment. The experiment result of the method is more feasible than the common tools in this situation.
Keywords: ontology; instance matching; TF-IDF algorithm; tree structure; table structure
1 Introduction
With the development of information technology and modern experimental methods, online material databases have become a research hotspot in the field of materials research. Multiple online material databases, including MatWeb[1]and MatNavi[2], have emerged in countries outside China. Related research in China started in 2011 with the Materials Scientific Data Sharing Network project[3]. Our research is based on the material experimental database project organized by the Shanghai Municipal Science and Technology Commission, which aims to create huge databases containing data generated through experiments by different research groups. In addition, similar or identical data sets exist in databases; thus, one of our goals is to match or recommend data pairs with the same or similar structure and to match content between different resources.
The material experimental data are stored in different structures and complex tables, which is incompatible with existing analysis computing tools. The sources and structure characteristics are as follows:
1) Little data come from papers on material fields. The data are shown in complex tables instead of formatted ones in databases. Most of the material experimental data are gathered from colleges or enterprises. The data types are usually plain text, Excel, Csv, or Txt, which are produced by material characterization apparatus.
2) The table structure, written in Txt or Csv, for example, cannot be directly incorporated into databases. There are merged columns or cells, more than 2 rows, hierarchical relationships in the header area, and duplicated column name data containing more than one row. These situations raise issues of atomicity.
Research groups are driven to conduct identical or similar experiments because of the lack of shared data. Beginners cannot learn from previous experiments. The different storage formats make the data understandable for affiliated staff and experts only. In short, the material experimental data sets are increasingly problematic information-isolated islands. Therefore, how to find matched case pairs from humongous similar material data is a challenging issue.
Since the structures from material experimental data sources are not available for common matching tools, we wish to transform the complex table with material experimental data into standard expressions for ontology, such as OWL and RDFS files. In our previous paper[4], TMEDSM (Tree-based Material Experimental Data Storage Model), based on a tree structure, was proposed to describe material complex tables and to contain the data sets along with a generation algorithm. The present paper aims to generate a rule-based algorithm based on our middle structure to generate ontology information.
We use general ontology matching method for our generation, including schema matching and instance matching. The scale of the schema is smaller, and the schema fits existing ontology matching tools. When matching instances with common tools, the following challenges are encountered:
1) No dictionaries exist in material domains with different languages. The material experimental data are collected among Chinese universities and written in English and Chinese. Common online dictionaries, such as WordNet, have trouble accommodating linguistic support and specialties.
2) The tools lack knowledge or a background in the material field, and the weight of terms cases problems. As with our understanding of the material filed, researchers may pay attention to different specific terms. Although two data instances are similar in general, it is not a useful pair for researchers if specific terms are different.
The above issues arise when using existing instance matching tools with our transformed ontologies.
Based on this case, a method of instance matching is introduced in this paper. A simple instance-matching method based on a TF-IDF algorithm with Chinese word segmentation and string similarity is proposed in this paper as an alternative to using WordNet.
The main contributions of this paper are as follows: 1) With the TMEDSM from the complex table[4], an automatic ontology generate algorithm is proposed. 2) The existing ontology matching tools work well for schema matching with our generated results but work poorly for instance matching. Based on research requirements in material-related fields, we propose an instance-matching method with a TF-IDF and propose suggestions for various circumstances.
2 Related work
2.1 Analysis of complex tables
The process of interpreting tables can be divided into three parts[5]: functional analysis, structural analysis, and interpretation relationships. Considering the satiation of material experimental data sources, we focus on the table structural analysis and interpretation relationships.
A widely accepted description of table structure was proposed by Xinxin Wang as follows. A table is divided into four parts, namely, the Body, BoxHead, Stub and StubHead. The Body contains data. The BoxHead is the index of a column at the top of the table, while the Stub is the index of a row. These components are collectively called headers. The StubHead lies at the top left of a table and overlaps the headers. Wang’s structural definition for tables is shown in Fig.1.
A text-based and grammar-based tree was used by Wang to describe the table structure. The results (shown in Fig.1) are as follows:
(Year, {(1991, ∅), (1992, ∅)}),
(Term, {(Winter, ∅), (Spring, ∅), (Fall, ∅)}),
(Mark, {(Assignments, {(Ass1, ∅), (Ass2, ∅), (Ass3, ∅)})}).
Ref. [6-9] propose their own method and algorithm to understand the relationships of labels in complex table. Previous studies[6-8]analyzed tables from the BoxHead area. Ref. [8] presents 8 context-free grammar rules to obtain Wang’s tree. On study[9]focused on parsing tables from the layout features in the Stub part and on designing an end-to-end table processing system(TEXUS) to accommodate different complex structures.

Fig.1 The structural definition of Wang’s table[10]
For the current situation of the material data, we previously proposed a method to analyze the structure of experimental tables automatically by discovering the relationships among the headers and generating TMEDSM structure with data labels for describing material-related experimental data tables[4]. We also placed data parts into TMEDSM structure to build a database. The experiment results show that 77.2% blank or meaningless cells are deleted. The speed of queries in our built material is more than 3 times faster[4]. As a middle structure, TMEDSM structure should be transformed into a widely supported form, such as ontology, which provides a feasible solution to generating material experimental ontology information from our tree structure called TMEDSM to analyze complex tables from material-related experimental data resources.
2.2 Ontology
Before using ontology matching and instance matching to solve problems of information-isolated islands, it is necessary to generate ontology information from sources. Ontology describes the relationships between concepts in information science to share a well-accepted, unique and clear definition. Elsewhere, ontology was defined to consist of five modeling primitives: concepts, relations, functions, axioms and instances.
The description languages of ontology include OWL2[11]and RDFS. OWL2 ontologies provide classes, data properties, object properties, individuals and data values with three basic notions (axioms, entities, and expressions[11]) to describe the hierarchical relationships of classes and constraint semantics among properties.
Certain rule-based algorithms have been proposed to generate ontologies from databases, particularly relational databases. Ref. [12] used mapping rules based on a view-based method to extract relationships using reasoning. Ref. [13] generated ontologies by analyzing executions written in SQL that contain clues on functions, value restrictions and data types. And paper [14] proposed an approach for generating ontologies from relational database schema with a rule-based method. However, the table structures in our situation are complex and do not conform to 1NF databases, making it challenging to use with methods mentioned above. Therefore, the current study focuses on proposing an approach to extracting classes, instances, properties, relationships and restrictions from complex tables. We propose TMEDSM and transformation algorithm in an automatic way, as in Ref. [4]. As an application of the tree, we create a method to automatically generate ontology information.
2.3 Ontology and instance matching
Certain similar concepts pertain from heterogeneous ontologies. To address this situation, semantic heterogeneity contains two steps, which are the following[15]. The first step is to match entities and find an alignment, which is called ontology matching. The second step is to explain the alignment according to the application scenario.
Ontology matching can be subdivided into schema matching and instance matching, which are complementary. Instance matching focuses on “ABOX”, while schema matching, also called ontology matching, focuses on “TBOX”. Two levels exist in ontology matching[16]: the element level and the structure level. The matching at the structure level considers the hierarchical relationships between ontology entities, while the matching at the element level does not. A previous study[17]reported that ontology matching can be divided into three kinds of algorithms:
1) String similarity matching, which calculates string distances with Jaro-Winkler’s and the cosine similarity algorithm.
2) Structure similarity matching, which analyzes hierarchical relationships between ontologies. The common approaches are the similarity-flooding algorithm, graph theory and the anchor-flood algorithm.
3) Matching based on instances. Here, semantic information among instances is used to match with schema.
Other approaches, such as machine learning, naïve Bayesian models and SVM, are used to match in matching tools[18].
A previous review[19]indicated that research on ontology matching is focused on cooperation among the existing solutions to enforce a dynamic and custom configuration during the process. Likewise, a focus exists on obtaining more suitable data for the Semantic Web or data from custom domain environments rather than creating a new technique and algorithm. The method of ontology matching is stagnating these years[20]. Some famous schema-matching and instance-matching tools are as follows.
YAM++ in Ref. [18,21] uses machine-learning techniques at the elemental level to estimate similarity metrics. If no training data is available for learning, string similarity is used instead. Over 15 matchers exist, including a semantical matcher used to remove inconsistent mappings.
AgreementMakerLight[22-23]divides matching algorithms into primary and secondary matchers to obtain an efficient and high-performance system. It is designed to solve large-scale matching problems. In 2016, it is one of the best performing ontology-matching systems in five tracks according to the OAEI reported in Ref. [20].
RiMOM[24], proposed by Tsinghua University, uses Bayesian decisions to calculate the conditional probability of two ontologies for the minimum mapping risk. RiMOM-IM is a derivative tool for large-scale instance matching[25].
Logmap[26]is a schema and instance-matching tool for bio-medical ontologies that uses an un-satisfiability detection and repair algorithm.
The anchor-flood algorithm, proposed by MH Seddiqui et al., is an iterative algorithm[27]. A match pair is chosen manually and then used to find matches recursively among its neighbors. Therefore, the results depend on the first chosen pair.
A testing platform is necessary to evaluate the performance of various tools. The Ontology Alignment Evaluation Initiative(OAEI) is an organization that evaluates ontology matching systems with a number of standard ontology sources. This organization compares tools and systems on the same basis[28]. However, our goal is aimed at material experimental data sets specifically, which are not suitable for standard evaluations.
3 Tree model and generate ontologies
In this section, we use TMEDSM as a middle structure in the process of transforming complex tables to ontologies. First, we define the tree with some limitations for convenience while adapting it to material experimental sources.
3.1 TMEDSM
We previously proposed a TMEDSM structure with a series of transform rules[4], shown in Tab.1. From the top to bottom of the header, namely, the BoxHead part, the system parses and builds a tree structure. We use a virtual root to unite the leaves and branches.
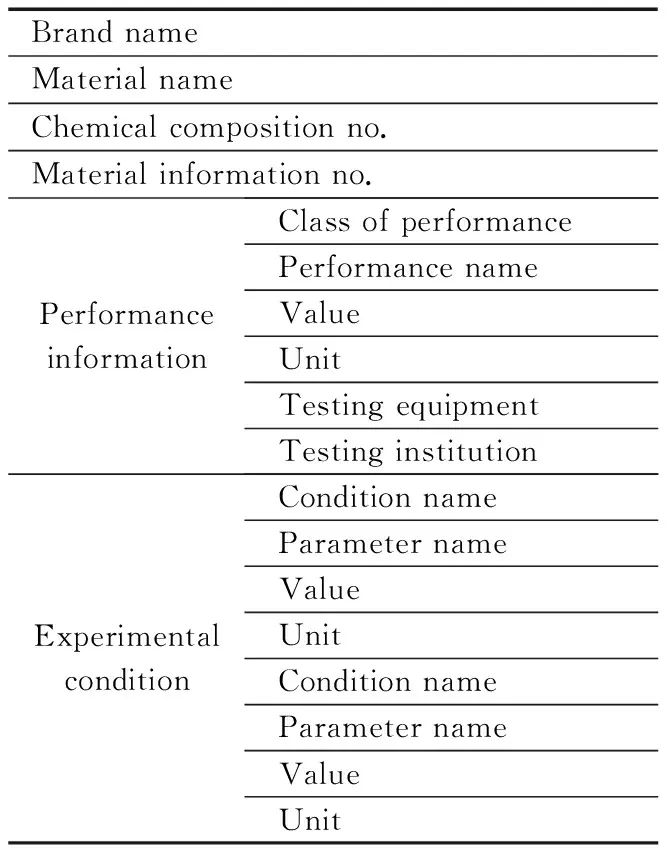
Tab.1 Example of part of headers in material data
To simplify the TMEDSM, we make the following assumptions to constrain the table. These assumptions do not influence our accuracy or completeness.
1) We discuss two-dimensional tables only. A row and column pair can locate one cell in the table.
2) The neighbor cells can be merged only when the merged cell has a rectangle shape. The top-left cell in the merged cell represents its location.
3) At this time, the information format is not discussed.
The definition of the TMEDSM with table structure is as follows:
1) The top node is a virtual root. All nodes are children of this top node.
2) A cell that is not blank or repeated in the level of the father node is added as a child node of the superior label node.
3) Duplicate cells can only repeat at the level of the father label node. If necessary, we generate new father node and child relationships to satisfy the definition. For instance, in Fig.2(see page 570), the child nodes of “Experimental condition” are organized as a repeat loop.
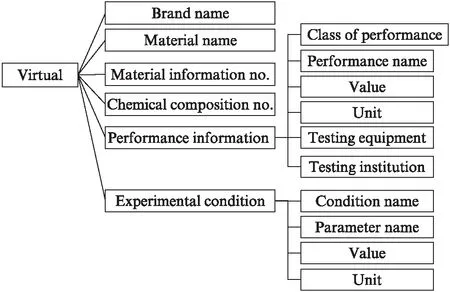
Fig.2 Structure of the TMEDSM from Tab.1
4) The consistent relationships between nodes are necessary to retain the tree structure. A forest or graph does not meet the conditions.
The algorithm that generates TMEDSM is described in our previous paper[4]and is not discussed here. According to the experimental material data sets that we have discovered, a sample structure is shown in Tab.1, and the tree result is shown in Fig.2 using the algorithm we proposed previously[4]. The tree can be easily transformed to JSON or XML files.
We previously combined material experimental data into TMEDSM with material structure to generate a TMEDSM with data. The data tree of TMEDSM is defined as follows:
1) The data tree is based on the structure tree. Each data set has a data tree.
2) The data node is added as a child of a structure node. Only leaf nodes of structure nodes have data children.
3) For duplicate columns, a number should be recorded to mark the order.
Based on the data structure tree, our goal is to match ontologies with material experimental data. The first step is to transform the data in complex tables to ontology information. Therefore, in next sub-section, an algorithm to move from the tree to OWL files is introduced.
3.2 Algorithm from TMEDSM to ontology
Our main algorithm concept is as follows. The non-leaves in the TMEDSM structure correspond to classes in ontology. The relationships among non-leaves are transformed to restricted object properties called “has-subdata” and “subclass”. The relationships between non-leaf and leaf correspond to data properties.
The algorithm is divided into two parts, namely, schema and instance. The first generates definitions of schema within the TMEDSM structure, while the second generates instances by analyzing TMEDSM structures with data. The algorithm is implemented using OWLAPI; it is a lightweight ontology editing tool written in Java[29], through which the results in OWL and RDFS formats are widely supported by ontology tools, such as Protégé.
The following rules are proposed for generating the schema:
1) Make a class called “root” as the parent class of all other classes.
2) For the non-leaf node, a class is created, and leaf nodes are transformed into data properties. These properties are all identified in IRI format.
3) If a leaf node is called “leaf”, then the corresponding data property should be named “has-leaf”. The domain restraint of the data property is the IRI of the parent node. Check the other restraints, such as range and types, according to the complex table.
4) For the non-leaf node, check their relationships to generate subclass restraints.
To generate instances, this paper proposes certain rules as follows.
1) The processing is based on TMEDSM structure with data sets and schema information.
2) For every set of data, at least one individual is created. For a non-leaf node, create an individual of its class.
3) If a class has subclass, its instances should contain an object property that points to the instances belonging to subclass in the same set of data.
4) According the schema information, the instances have data properties associated with the classes. Check their restraints and report the incorrect relationships.

Fig.3 Simple architecture of schema and instance matching in material experimental data
Fig.3 shows that ontology generating algorithms are an important part of the matching architecture. Only the standard ontology information files can be analyzed by common ontology matching tools.
In the experiment section, we show the speed of our algorithm, which is faster than the algorithm with databases. The matching tools work well on schema matching but not on instance matching because of the lack of knowledge and multilingual content. In the next section, we analyze the problem and propose an instance matching method based on TF-IDF with text similarity and specific terms.
4 Ontologies instance matching with TF-IDF
According to the rule-based algorithm proposed in the previous section, we attempt to use common ontology matching tools for instance matching. However, the results are not satisfied, and the similarities lie at almost the same level whether they are similar or not. The reasons are as follows.
1) The schema matching is aimed at the header area in complex tables, which is hierarchical and has a limited count. This approach fits the schema-matching tools. However, large data sets from material experimental sources create a multiple instances, which require substantial time to process.
2) The source contains English and Chinese. The tools are not suitable for mixed-language environments. The schemas can be translated manually due to their limited size, but the large number of instances precludes this operation while also ensuring semantic accuracy.
3) Certain matching tools rely on semantic dictionaries, such as WordNet. However, in material fields, particularly in material experimental data, few dictionaries are available, and none are written in Chinese. Thus, we cannot use dictionaries in the current study.
4) Not use specific terms. The tools use unimportant terms as the evaluative foundations. For example, Logmap matches most instances to the first one based on insignificant terms, which is certainly inaccurate.
Considering the situation and reasons above, a sample instance matching method based on the TF-IDF algorithm with string similarity and specific term setting is proposed in this section to satisfy our needs. Since researchers may pay attention to various terms, which can create differing results, the goal of this paper is to give appropriate recommendations depending on various needs. They prefer all accurate and obscure results which similarities are greater than a threshold. Qualitative conclusions are made in the experiment section.
Two pretreatments are introduced in next two sections. Due to the Chinese content, a Chinese word segmentation algorithm is necessary for to improve the Chinese-language analysis. To avoid the influence of different term expressions, the Jaro-Winkler algorithm, a string similarity algorithm, is incorporated into the TF-IDF algorithm instead of dictionaries.
4.1 Word segmentation
To use TF-IDF, splitting sentences are necessary to obtain terms. The sources contain Chinese, which is not suitable for widely used blank segmentation. We tried using Lucene to segment the Chinese text, but the base segment algorithms only split text based on Chinese characters. Therefore, we chose the IK-Analyzer for segmentation. This tool is a light, open-sourced and fast third party tool based on Lucene; it uses basic Chinese word dictionaries and an iterative algorithm to segment strings[30-31]. The result of the IK-Analyzer is a set of Chinese phrases, which are suitable as terms in the TF-IDF algorithm after processing by a stopword filter.
4.2 Jaro-Winkler distance
For matching different expressions of terms, TF-IDF, an algorithm with term frequency, cannot distinguish their relationships, which influences the results. A previous study[32]proposed a TF-IDF-based tool with synonym recognition. However, without a material-related field dictionary, the use of synonyms seems unreachable for the time being. Therefore, an alternative method is proposed to find similarities between terms.
The Jaro-Winkler distance[33], proposed in 1999, is used in this study as a string similarity algorithm. Relative to the Jaro algorithm, when considering the beginning of a string, the Jaro-Winkler approach performs much better because it is better suited for shorter strings and is used for term similarity instead of instance similarity. In addition, we also accept the synonym dictionary in the material field instead of the string similarity algorithm.
4.3 TF-IDF algorithm and specific terms
The definition of TF-IDF in this paper is as follows. The term frequency of termiin instancej, designatedTFij, is shown in Equation (1),
(1)
whereTjis the set of all terms appearance in instancej.
For the Jaro-Winkler algorithm and the terms calledaandb, if the threshold isδ, thensabas follows is used for calculatingtij:
(2)
If termsaandbbelong to number type in ontology, then they are considered the same due to the similarity threshold.
The IDF is as follows, in whichNis the number of instances andniis the number of instances that contain termi:
(3)
The formula of TF-IDF vector is written as
(TF-IDF)ij=TFij×IDFj.
(4)
The similarity of two instances is calculated by the cosine of their TF-IDF vector. The equation (5) shows a shorthand of TF-IDF:
Ai=(TF-IDF)iA.
(5)
Then, the cosine similarity of instancesAandBis as follows:
(6)
During the experiments, we found the expectations of material research to vary; thus, it is necessary to monitor one or more specific terms. Then, the TF-IDF should change due to these concerns, and specific terms are used to manually set the weights of interested terms. If a termiis in the specific term set and the value is set toδ, then set ∀A∈Instance,Ai=δ. In the experiment section, an evaluation is made to determine the recommended range ofδ, which is referenced for users.
A diagram of instance matching is shown in Fig.4. The system is divided into two stages: the pretreatment stage and query stage. The primary task of the pretreatment stage is to generate OWL files and calculate the term frequencies. If a special term request is advanced by users, then the term weight modification is made during the pretreatment stage. The system waits for instance queries in the query stage to calculate the cosine of a matching score.

Fig.4 The diagram of instance matching
5 Experimental results
We implemented the methods in Java and conducted an experiment using a laptop computer with 16 GB of RAM.
In the first sub-section, we discuss generating ontology files. Discussions on instance matching appear in the second sub-section.
5.1 Word Segmentation

Tab.2 Calculation time comparison
Our goal is to generate OWL files from complex tables with material data, using TMEDSM as a middle model. Tab.2 shows the efficiency on generating ontology with 1000 instances. We previously proposed an algorithm for transforming source data in material experiment tables to databases[4]. At the size of 1000 data sets, we compare ontology algorithms with database executions, as shown in Tab.2. This approach is approximately 5 times more efficient than database executions, implying efficiency to generate ontologies from tables and trees directly instead of from databases for secondary conversion.

Fig.5 The classes, data properties and object properties from Fig.2
Two methods are introduced in Ref. [13-14] to transform RDB to ontologies. But our resources are complex tables which are not suitable for those methods. Therefore, these methods are only available for the database generation method proposed in our paper[4]which also using a tree as a middle structure. Because there is few differences on information between OWL files and databases, it is no doubt that the method in Ref. [13-14] spend more time on getting relational databases and get the almost same result as the result in this paper.
Fig.5 shows a sample example of classes, data properties and object properties declarations generated from tree structure in Fig.2. We store most of relationships shown in resource documents into the ontologies. Because of lacking of space, the instances in Fig.2 are not provSSided.
Common schema matching tools are executed with the results generated in this paper. Although 1000 instances exist, there are only approximately 30 data properties and few object properties and classes. The small scale of the schema makes it well matched for schema matching. With YAM++[18]for schema matching, the precision is 0.96, the recall is 0.75, and the F-measure is 0.84. We conclude that the common schema-matching tools work properly in the generated ontology.
5.2 Experiment on instance matching
The existing instance matching tools do not work well with the output of this study. Agreement Maker Light is incompatible with Chinese content, while Logmap[26]returns almost the same similarity value, which cannot reflect the relationships among instances. RiMOM-IM[25]gives the results with only one matching pair for each instance, which does not meet the requirements. It can be concluded that the multi-language and background knowledge significantly influence the results.

Fig.6 Time consumed in the pretreatment
Qualitative conclusions are made in this paper based on the sample instance-matching method using selected samples characterized by researchers in materials-related fields. The effect of two parameters, namely, the special terms setting and the Jaro-Winkler threshold, are discussed in this paper.
Fig.6 shows the time consumed during the pretreatment stage. The process requires 4.3 more time with string similarities than without it.
Selected examples are shown from this experiment. There are particular instances, termed Instance #0, #1, #2, #3, #4, #6, #18 and #20. Instances #0, #1, #2, #3, #4 and #6 are similar in terms of a key term, while others are different in other terms and structure. Instances #18 and #20 are independent in terms of the key term. The instance pair #0-#20 and #18-#20 is similar in structure because these instances came from the same research lab.

Tab.3 Similarity estimated by TF-IDF algorithm and Logmap
Tab.3 shows the results between original TF-IDF algorithm and Logmap as a common instance matching tool. We find that result from Logmap are unavailable to use and similarities from TF-IDF have better discrimination. But some of the instance pairs are equivocal, such as “#0, #1”. So we try to use two improved method to get a better similarities for these pairs.
The effect of specific term weights on the cosine similarity without the Jaro-Winkler algorithm is shown in Fig.7(a). When not modifying the weight, the cosine similarities among similar instances are varied. However, irrelevant instance pairs, such as #0 and #20, show a clear, differing similarity. When determining the weight of specific terms, the more weight the term has, the closer the similarity will approach 1, while not influencing irrelevant instance pairs. A distinguishability problem arises if the term weight is excessively high. Therefore, we conclude that setting the weight manually is helpful for users in material fields to find a specific attribute in different structures and superfluous properties, while the ideal modified weight is from 0.2 to 0.5 due to importance of the term.
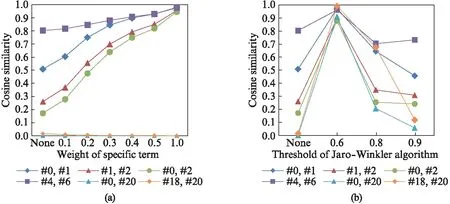
Fig.7 (a) Specific term weight effect on cosine similarity; (b) The threshold of the Jaro-Winkler effect on cosine similarity
The influence of thresholds of Jaro-Winkler on the cosine similarity is shown in Fig. 7(b). When the threshold is 0.6, then all results are high, which is not helpful for researchers. Therefore, it is not recommended to use a low threshold on string similarity. In contrast, a threshold close to 1.0 is also not recommended because it behaves similarly to the one without the Jaro-Winkler algorithm. When the threshold is 0.8 or 0.9, the string similarity has an effect. Instances #18 and #20 are similar when the threshold is 0.8 because they come from the same source and have a similar structure. Although similar in terms of specific terms, the instance pairs #0, #2 and #1, #2 differ in structure and data, which make them dissimilar under the Jaro-Winkler algorithm. We find that the Jaro-Winkler algorithm focuses on the similarity on an overall view, such as structure and broad data. The suggested threshold is approximately 0.8.
According to the experiment results above, qualitative conclusions are made as follows. Different parameters should be used in various situations. One should determine weights of specific terms that fit based on a specific attribute. In addition, the Jaro-Winkler algorithm works better on instance matching in a broad sense.
6 Conclusion and future work
A prototype system is proposed to generate ontology and match instances from complex-structured material experimental sources. An acceptable schema matching result is obtained by common matching tools with ontologies generated by the algorithm proposed in this paper. Then, an instance-matching method based on the TF-IDF algorithm is proposed that can be implemented satisfactorily without background knowledge. Different parameters are recommended for the users to meet various conditions.
Moreover, compared with other instance matching methods which are not available for the material data extracted from various complex material tables, our method achieves better accuracy, and effectively find matched cases.
However, certain shortcomings exist at present:
1) The external parts of complex tables, such as comments and the format of cells, are ignored in the algorithm.
2) A lack of understanding exists in terms of material fields, and no dictionaries are used, which reduces the accuracy of judgment terms.
3) Lacking samples provided by researchers in material fields, only qualitative conclusions are made in this paper.
4) Experts from different search subfields in material domain give different recommendations on the instance similarity. The parameters in TF-IDF algorithm need to be customized for different fields. So there is no universal solution for parameters.
Therefore, future research goals are as follows:
1) Optimize the TMEDSM structure to support all table types. Perform advance analysis to reveal the hidden relationships between tables.
2) Support more rich text and analyze the formats and useful information, such as unit and footnote, to identify more ontologies.
3) Cooperate with experts in materials. With labeled training data, background knowledge and dictionaries, an instance-matching tool employing a better algorithm (e.g., supervised learning) is feasible.
