
元组级不确定数据库的Top-K概率频繁项集挖掘
2018-11-14 12:58陈凤娟
赤峰学院学报·自然科学版 2018年10期
陈凤娟,马 恺
(辽宁对外经贸学院,辽宁 大连 116052)
1 引言
在越来越多的实际应用中,如无线传感器网络和RFID等环境下,数据采集设备获得的数据是不确定数据,因此,数据库存储的数据也就具有了不确定性.不确定性数据有的是由于数据采集设备的精度不够造成的,如无线传感器网络和RFID等,有的则是对某些原始数据进行综合分析得到的,如对超市的购买记录数据库的顾客购买行为进行统计或对患者就医记录进行分析获得疾病信息等[1].这些不确定数据一般采用不确定数据库进行存储和处理,采用数据挖掘方法来分析这些数据中隐含的有用的信息.
关联规则是数据挖掘的一个重要研究内容,也是分析事务数据库中数据之间隐含的规则的重要工具,它对分析数据和预测未来趋势都有很重要的意义[2].频繁项集挖掘,也称为频繁模式挖掘是关联规则挖掘的第一步,也是最关键的步骤,它能找出数据库中出现次数大于用户给定的最小阈值的所有模式,称为频繁项集或频繁模式.在不确定数据库中挖掘概率频繁项集能发现不确定数据库中出现次数大于某个阈值的所有模式,但是,由于数据不确定性的存在,使得挖掘工作比确定数据库中的频繁模式挖掘更为复杂.由于挖掘概率频繁模式时,需要用户提供最小频繁概率的阈值,增加了挖掘难度,因为,阈值的设置没有统一的标准.当阈值设置过高时,挖掘到的结果基本都是已知的,参考价值不大,但是,若将阈值设置过低,则会导致挖掘结果太多,且挖掘时间太长.
为了解决这些问题,本文主要研究无需设置阈值的Top-K概率频繁项集挖掘问题.为了分析问题和节省运算时间,本文主要研究在记录级不确定数据库中,挖掘频繁概率值最高的K个概率频繁项集,即Top-K概率频繁项集挖掘问题.文中分析不确定数据库的性质并给出了Top-K概率频繁项集挖掘算法,在不确定数据库上对算法进行仿真实验,验证了算法的性能.
2 不确定数据库与概率频繁项集
不确定数据库一般是指包括概率信息(不确定信息)的数据库,根据不确定信息(概率值)在数据库中出现的位置的不同,可以将不确定数据库划分为记录级的不确定数据库和属性级的不确定数据库[3].如果在不确定数据库中,概率信息是出现在每条记录的最后,表示该条记录在数据库中出现的概率,那么,这个数据库就是记录级不确定数据库.如果在不确定数据库中,每条记录中每个属性的属性值是不确定的,即概率信息出现在记录中每个属性值的后面,那么,这个数据库就是属性级不确定数据库[4].如表1和表2所示,记录级不确定数据库的结构比属性级不确定数据库简单,算法在计算频繁模式时,需要计算的信息较少.本文主要探讨记录级不确定数据库中的频繁模式挖掘问题,但下面的定义也适应于属性级不确定数据库.
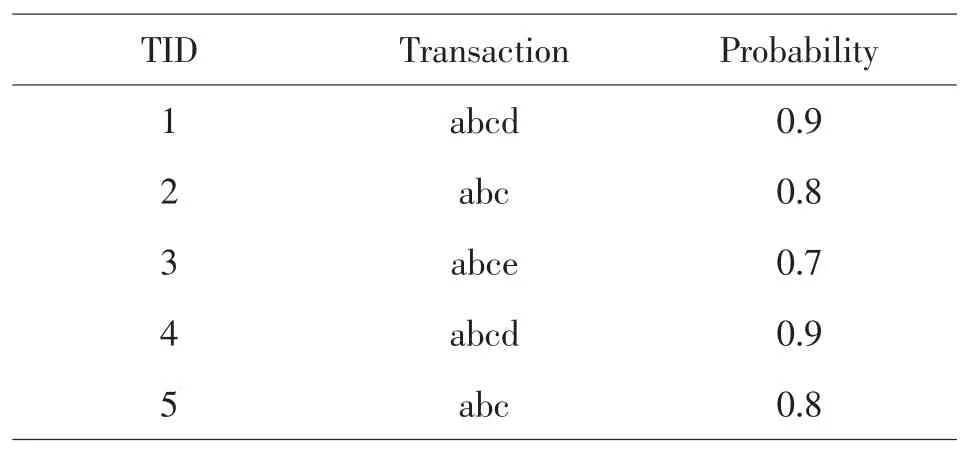
表1 记录级不确定数据库
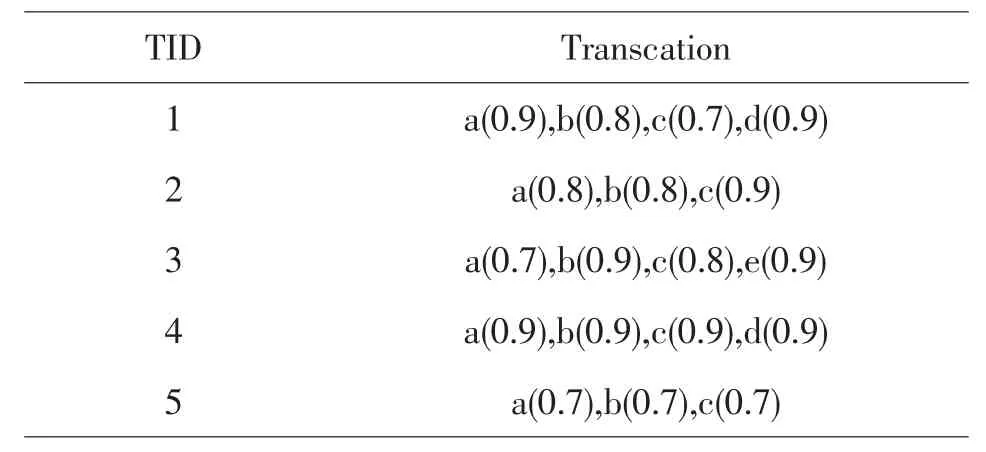
表2 属性级不确定数据库
下面,采用可能世界语义来分析不确定数据库.可能世界用所有记录的不确定信息(等于每条记录在数据库中出现的概率乘以不出现的概率)来表示记录的所有的出现与否的可能性大小[5].可能世界可以描述不确定数据库的所有的可能情况,它的个数是按照指数增长的,因此,直接在可能世界上做挖掘,会产生巨大的计算量,算法的扩展性差.可能世界出现的概率大小,用其概率值表示,每个可能世界出现的概率等于出现的每条记录的概率与不出现的每条记录的概率的乘积,这样,所有可能世界的概率之和等于1.根据可能世界的分析,对不确定数据库中的频繁模式挖掘,进行如下定义[6].
定义1假设D是一个记录级的不确定数据库,D的一个可能世界W是D的所有可能世界的一个子集.其中,每个可能世界的概率称为PD(W),则PD(W)的定义用公式可以表示为PD(W)=∏(t,v)∈WD(t,v)(∏(t,v)∈T×VW(1-D(t,v))).
假设构成不确定数据库的所有项的集合为I,那么I的任意一个非空子集称为项集,项集中包含的项的个数称为项集的长度.在确定数据库中,一个项集的支持度是判断项集是否是频繁的主要标志,而绝对支持度就是该项集在数据库中出现的总次数,相对支持度是该项集在数据库中的出现次数与数据库总记录数的比值.假设X是不确定数据库中的一个项集,那么项集X在不确定数据库中的支持度用X在可能世界中的支持度来计算[7].项集X在一个可能世界中的支持度就是该可能世界中包含该项集的所有记录的个数.任意一个项集在不确定数据库中的支持度可以定义为该项集在所有可能世界中的支持度之和,而该项集是否是频繁项集,也可以用这个不确定数据库中的支持度来定义.由此,可以给出不确定数据库中的期望支持度概念.
定义2在不确定数据库D中,I是所有项的全集,X是I的一个任意非空子集,项集X的期望支持度是该项集在不确定数据库的所有的可能世界中出现的概率之和,记为ESup(X),即ESup(X)=∑t∈TP(X⊆t)=∑t∈T∏x∈XP(x⊆t).
在期望支持度定义下,可以给定一个不确定数据库的最小期望支持度,用于挖掘不确定数据库中的频繁项集.为了更精确的计算不确定数据库中的支持度,还可以用项集在所有可能世界中的离散概率分布来定义不确定数据库中的支持度.任意一个项集在不确定数据库中的概率支持度表示其在可能世界中的离散概率分布.
定义3给定一个不确定数据库D和该数据库的所有可能世界的集合W,所有的项的集合为I,任意一个项集X的支持度为i的概率称为支持度概率Pi(X),它等于项集X的所有支持度为i的可能世界的概率之和,即 Pi(X)=∑S(X,wj)=twj,其中,wj表示一个可能世界,S(X,wj)表示可能世界中,项集X的支持度,P(wj)表示可能世界wj的概率.
定义4对于一个不确定数据库D和D中的任意一个项集X,给定一个最小支持度minSup(minSup∈{0,…,|T|}),X在所有可能世界中的支持度至少是minSup的概率称为频繁概率,记为P≥minsup(X),则有
这样,任意一个项集X的频繁概率P≥minsup(X)就是该项集出现的频繁程度的可能性大小,因此,可以用该项集的频繁度判断该项集是否是可能的频繁项集,即候选项集.当用户给定一个具体的阈值,最小频繁概率,作为算法的参数时,就可以用下面的定义挖掘出概率频繁项集.
定义5给定一个不确定数据库D,所有的项的集合为I,由用户定义的两个阈值,最小支持度值minsup和最小频繁概率阈值minfp.若任意一个项集X频繁概率P≥minsup(X)大于等于用户给定的最小频繁概率阈值minfp,则项集X是概率频繁项集,即P≥minsup(X)≥minsp.
由此,可以定义不确定数据库中的概率频繁项集挖掘问题.
定义6给定一个不确定数据库D,所有的项的集合为I,由用户定义的两个阈值,最小支持度值minsup和最小频繁概率阈值minfp.在D中发现所有频繁概率大于最小频繁概率的项集的挖掘就是不确定数据库中的频繁项集挖掘问题.
3 Top-K概率频繁项集挖掘
根据记录级不确定数据库中,出现的项集的频繁概率和用户给定的最小频繁概率的阈值,可以得到记录级不确定数据库中的所有概率频繁项集.但是,不确定数据库的概率频繁项集的数量非常大,尤其是在阈值设置较低时,概率频繁项集的数量更大.这样,无论是直接分析概率频繁项集还是用概率频繁项集实现关联规则分析,都会带来不便.为了减少输出的概率频繁模式,可以采用仅挖掘频繁概率最大的K个概率频繁项集,为分析者提供最有参考价值的关系.
Top-K概率频繁项集的挖掘比概率频繁项集的挖掘过程更为复杂,不确定数据库的UApriori和UFP-Growth等算法是对确定数据库上的经典频繁模式挖掘算法Apriori和FP-Growth在不确定数据库中的扩展,而不确定数据库的Top-K概率频繁模式挖掘,也可以从确定数据库的频繁项集的挖掘算法上进行扩展.Top-K概率频繁项集挖掘不同与概率频繁项集挖掘之处在于当最小频繁概率给定时,概率频繁项集是固定的,而Top-K概率频繁项集是随着每次得到的最新的概率频繁项集的频繁概率影响的.当挖掘到新的概率频繁项集时,原有的概率频繁项集不变,但是,所有的概率频繁项集的排名却会发生变化.因此,相对于概率频繁项集的挖掘,Top-K概率频繁项集的挖掘重点在动态调整概率频繁项集的排名,并仅保留对后续挖掘有用的概率频繁模式,从而减少挖掘时间,提高挖掘效率.
记录级不确定数据库的Top-K概率频繁项集的挖掘算法基于UApriori算法的框架,基本思想是在每次扫描数据库时,挖掘出当前候选集,根据最小频繁概率(初始设置为0),得到概率频繁项集,然后对本次挖掘到的概率频繁项集进行排序,并根据当前的排序结果,比较第K个概率频繁项集的频繁概率与最小频繁概率,用二者中大的作为最新的阈值,再进入下一次对数据集的扫描和概率频繁模式的挖掘,直到不再产生候选集为止.
在记录级不确定数据库中,频繁项集的向下封闭的特性仍然成立,用定理1来描述这种性质.
定理1对于给定的记录级不确定数据库D,所有项的集合是I.假设A是任意给一个项集,即A是I的非空子集.项集B是A的一个非空子集.如果项集B的频繁概率小于用户定义的最小阈值,则项集A的频繁概率也一定小于最小阈值.
证明由频繁概率的概率可得,任意一个项集的频繁概率等于包含该项集的记录的概率之和.因此,若包含两个项集的记录的集合是包含关系,即包含二者之一的项集的所有记录是包含另一个项集的所有记录的子集,则对应记录集合大的项集的频繁概率高,另一个频繁概率低.对于两个具有包含关系的项集,A和B,包含二者的记录集合只有两种可能,一个是完全相等,一是包含关系,且包含父项集A的记录集合是包含子项集B的记录集合的子集.这样,就有项集A的频繁概率小于等于项集B的频繁概率.因此,当项集B的频繁概率小于用户给定的最小阈值是,项集A的频繁概率也一定小于最小阈值.
定理1给出了不确定数据库中,父项集和子项集的频繁概率的关系.同时,定理1也是生成候选集时的剪枝依据.当(n-1)项集的频繁概率小于最小频繁概率时,其父项集n项集的频繁概率一定小于最小阈值.也就是说,一个(n-1)项集是非概率频繁项集,则包含它的n项集也一定是非概率频繁项集.因此,在生成候选集的时候可以不用考虑.
在本文的Top-K算法中,当挖掘出1项概率频繁项集后,对其按照频繁概率的降序进行排序,若生成的概率频繁项集的个数不少于K个,则第K个概率频繁项集的频繁概率必定不小于最小频繁概率.这样,调整最小频繁概率的值,用第K个概率频繁项集的频繁概率作为新的最小频繁概率的阈值,进行2项候选集的生成.不断重复该过程,就可以快速的得到Top-K概率频繁项集.算法的具体描述如下.
Input:一个记录级不确定数据库D,用户指定的K值
Output:Top-K概率频繁项集
Begin
C0=ø //概率频繁项集的候选集合,初始为空
PK=ø //Top-K概率频繁项集的集合,初始为空
min_psup=0 //最小频繁概率的初始值
扫描不确定数据库,统计1项集的频繁概率
对所有概率频繁1项集按频繁概率降序排列
PK={前K个概率频繁项集}
min_psup=第K个概率频繁项集的频繁概率
Do while Cn-1≠ø
用PK生成Cn候选集
for i=1 to|Cn|
扫描数据库,计算候选集中项集X的频繁概率
If候选集中的项集X的频繁概率>=min_psup then
Pk=PK∪{X}
End If
End For
对所有对概率频繁n项集按频繁概率降序排列
PK={前K个概率频繁项集}
min_psup=第K个概率频繁项集的频繁概率
End Do
End
Top-K概率频繁项集挖掘算法能挖掘频繁概率最大的K个概率频繁项集,但是由于向下封闭特性的存在,会导致这K个项集有一些是另一些的子集.例如,如果项集ABC是K个概率频繁项集之一,那么,它的所有子集A,B,C,AB,AC,BC一定都包含在Top-K概率频繁项集内.
4 实验与性能分析
为了测试Top-K概率频繁项集挖掘算法的性能,在记录级不确定数据库上使用该算法进行挖掘,并与UApriori算法进行比较,分析算法的性能.采用人工合成的方法生成实验需要的记录级不确定数据库,合成方法分为两个步骤.第一步,获得确定数据库,可以从FIMI’04数据集中获得,如mushroom和connect等数据库.第二步,为确定数据库的每条记录,增加一个概率,用于表示该记录在数据库中出现的可能性,为了保留数据库中的频繁项集,添加的概率服从正态分布.本文的实验采用的确定数据库是Mushroom和connect,为每条记录增加的概率值为服从正态分布的均值为0.8,标准差为0.1的概率值.算法采用JAVA实现,在JDK环境下编译运行,运行环境的硬件配置为Intel core i7 CPU,16G内存,操作系统为Win7.
图1描述了算法的运行时间,图中比较了在选取不同的K值时所花费的时间.很明显,在K值越小时,算法运行时间越短.这是因为K值越小,每次调整的最小频繁概率就越大,被剪枝的项集就越多,需要计算频繁概率的候选项集就越少,因此运行时间短.
图2对比了算法与UApriori算法的运行时间.由于UApriori算法的最小频繁概率是固定的,因此,它的时间与最小频繁概率阈值的设置有很大关系,当阈值设置很高时,用向下封闭的特性可以剪枝掉很多非频繁的项集,因此算法的运行时间短,当阈值设置很低时,算法的运行时间很长,而Top-K的运行时间是受K值影响.为了对比二者的性能,将UApriori算法中的最小频繁概率和Top-K算法的K值共同抽象为模拟参数,用1~5来表示该参数值的增加

图1 Top-K算法的运行时间

图2 Top-K与UApriori的比较
5 结束语
在记录级不确定数据库中挖掘Top-K概率频繁项集能大大减少输出的概率频繁项集的个数,为很多应用提供有参考价值的信息,同时,算法的运行时间也较短.但是,Top-k挖掘到的K个项集,会出现多个子集与其父集均在挖掘结果中的情况,减少了用户发现更多有意义的项集的机会,在未来的工作中,将会研究Top-K概率频繁闭项集的挖掘.
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
天津科技大学学报(2018年4期)2018-08-22
河北遥感(2017年2期)2017-08-07
衡阳师范学院学报(2016年3期)2016-07-10
网络安全与数据管理(2010年1期)2010-05-18
