
使用Bootstrap方法计算认知诊断评估中的信度*
2018-11-08 02:37:16张金明
心理学探新 2018年5期
郭 磊,张金明
(1.西南大学心理学部,重庆 400715;2.西南大学统计学博士后科研流动站,重庆 400715; 3.中国基础教育质量监测协同创新中心西南大学分中心,重庆 400715;4.重庆市脑科学协同创新中心,重庆 400715; 5.伊利诺伊大学香槟分校教育心理学系,香槟,伊利诺伊州 61820 美国)
1 引言
认知诊断评估(cognitive diagnostic assessment,CDA)已成为国内外测量学研究的关注热点。CDA优势为不仅能获得被试能力水平,还能诊断其在知识点上的掌握情况。通过对知识状态的估计,可知晓强项与弱项,指导教师开展针对性的教学补救,实现个性化教学。由此,认知诊断被视为新一代心理测量理论的核心(涂冬波,蔡艳,丁树良,2012)。
CDA依赖测验进行评估,因此,测验质量决定了评估质量。测验信度是衡量测验质量的一个重要指标(温忠麟,叶宝娟,2011)。一个良好的测验,首先应该保证在评价同一批被试时,在不同时间或场合得到的测量结果是一致的。在心理与教育测验中,常用信度来衡量测验的稳定性,信度越高,稳定性越强。信度向来都是心理测量学的重要研究领域,国内外有关信度的研究数不胜数,但大多都属于经典测验理论或项目反应理论框架内的研究。而在CDA中,却很少看见信度方面的研究。因此,对于同样依赖测验的CDA,对其信度的研究也就非常有必要和有价值。
目前,CDA中的信度研究刚刚处于发展阶段,国内外相关研究主要有:(1)Templin等(2013)提出了属性信度的计算方法,但未关注到模式信度的指标。本文将Templin的方法称作“四分相关法”。(2)Cui,Gierl和Chang(2012)基于后验概率分布信息,构建了分类一致性指标以衡量CDA中的模式信度,但未提出属性信度。(3)Wang,Song,Chen,Meng和Ding(2015)基于前人研究,提出了属性信度和模式信度指标,完善了之前的研究。和Cui等的方法进行比较后发现新指标具有同样表现。本文将Wang的方法称作“一致性法”。这些研究有一个相同的基本假设:被试在两次相同测验上估计的后验概率分布和边际分布分别相同。该假设的目的是为了构建重测信度(test-retest reliability)指标,但该假设与现实有些许不符。但凡测量总会存在误差,即使同一批人第二次作答同一批试题,由于随机误差的存在,也很难保证前后两次测验的结果完全一致。在经典测验理论中表现为观察分数不一致,而在CDA中则表现为后验概率分布、边际分布不一致。因此,在CDA中开发出符合测验实际情况,能够将随机误差考虑在内的信度指标至关重要。本研究基于一次施测结果,采用Bootstrap方法对后验概率及边际分布抽样,提出了两类新的属性和模式信度指标。第一类称作积差相关法,有两个指标:ARC(Attribute-level Reliability base on Correlation)和PRC(Pattern-level Reliability base on Correlation);第二类称作修正一致性法,有两个指标:ARM(Attribute-level Reliability base on Multiplication)和PRM(Pattern-level Reliability base on Multiplication)。新指标同样是通过计算两次测验结果的一致性来反映重测信度,不同之处在于构造第二次测验结果的方式。四分相关法以及一致性法直接假设第二次测验结果恒等于第一次测验结果,而新方法将随机误差考虑在内,通过Bootstrap方法合理构造第二次测验结果。为探查新指标在模拟和实证研究中的表现,本研究将与四分相关法和一致性法进行比较。
文章按如下方式组织:第二部分分别介绍四分相关法、一致性法、基于Bootstrap抽样构建的新指标,并给出计算步骤。第三部分是模拟研究。第四部分是实证研究。最后一部分是结论与讨论。
2 属性和模式信度的计算方法
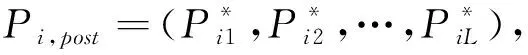
2.1 四分相关法
Templin等(2013)认为CDA中的属性信度是前后两次施测后被试在第k个属性上掌握情况的一致性程度。由于知识状态α是二分变量,故使用四分相关计算重测信度,其步骤为:
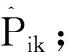
(1)
基于四格表计算四分相关,即得到属性k的重测信度。
从公式(1)中可以看出,Templin等创建了第二次施测结果(实际并未施测),并假设第二次估计结果恒等于第一次结果。经典测验理论模型为X=T + E,X为观测分数,T为真分数,E表示随机误差。该模型认为真实能力和观察分数之间呈线性关系,并相差一个随机误差部分。尽管CDA测量模型与经典测验理论不同,但基于同样道理,即使是同一批被试作答同一份测验,也很难保证两次测验的边际概率完全一致。因此,四分相关法的前提假设较强,在现实中不太容易满足,会得到误差较大的信度估计值。
2.2 一致性方法
Wang等延续了Templin等对CDA中重测信度定义的思想,提出了属性信度的计算方法:
(2)
和模式信度的计算方法:
(3)
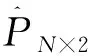
由公式(2)和(3)可以看出,这两个指标的计算仍然假设第二次测验的后验概率分布和边际概率恒等于第一次测验的结果。该假设和Templin等一样,偏于理想化。
2.3 基于Bootstrap的新方法
Bootstrap是以样本来代表总体,在该样本中进行放回抽样,直至抽取n个数据组成一个样本。这样的程序反复进行多次,即可产生多个样本,基于每个样本数据就可以进行统计计算(江程铭,李纾,2015)。
2.3.1 属性信度的计算
使用Bootstrap方法计算CDA的属性信度步骤如下:



分别计算属性信度ARC和ARM指标:
(4)
(5)

2.3.2 模式信度的计算
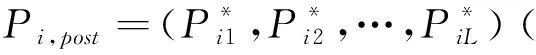
(6)
(7)
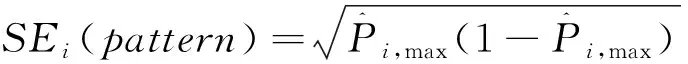
下面将分别通过模拟研究和实证研究比较四种方法在不同实验条件下的表现。
3 模拟研究
3.1 研究设计
本研究以DINA模型(Culpepper,2015;de la Torre,2009;Junker & Sijtsma,2001)为例,但不局限于该模型。s和g参数均从U(0.15,0.25)中抽取。考察3个变量对信度估计的影响:(1)属性个数K:3个和5个。(2)题目数量J:5题、10题、20题。Q矩阵如附录表1和表2所示,行代表属性数,列代表题目;1表示题目考察到该属性,0表示未考察。K=3时,将Q10重复即可得20题的Q矩阵。(3)协方差矩阵Σ的非对角线元素ρ:0.2(低相关)、0.5(中相关)、0.8(高相关)。
1000名被试知识状态的生成方式如下:依据多元正态分布MVNK(0,Σ)生成K维连续变量矩阵,设定各连续变量满足标准正态分布,用0为切点对各连续变量进行两段切割,并且可以通过设定Σ矩阵的非对角线元素ρ来调控各属性之间的四分相关(詹沛达,陈平,边玉芳,2016)。
Bootstrap取样次数M设置为30000次。本研究为2×3×3的完全交叉设计,每个实验条件重复30次,以减小随机误差。
3.2 信度真值的产生
固定被试的知识状态、以及题目参数,使用DINA模型重复生成H次被试的作答数据,将这H次作答数据看作多次重测(test-retest)的结果。计算所有作答数据两两配对[H*(H-1)/2对]的估计一致性值,然后将这些一致性值的均值作为信度的真值rT,当重复数量足够大时,均值可以逼近信度的真值,本研究中H取200次,该做法可参见Wang等(2015)的研究。其中,一致性值的计算方法采用Wang等(2015)文中的指标:
(8)
(9)
PTRCR1,2表示模式重测一致性指标,下角标1和2表示第一次和第二次施测。ATRCRk,1,2表示属性k的重测一致性指标。
3.3 评价指标
①平均偏差
(10)
其中,rT为信度的真值,ri为每次实验的信度估计值。该值越接近于0越好。
②误差均方根:
(11)
3.4 研究结果
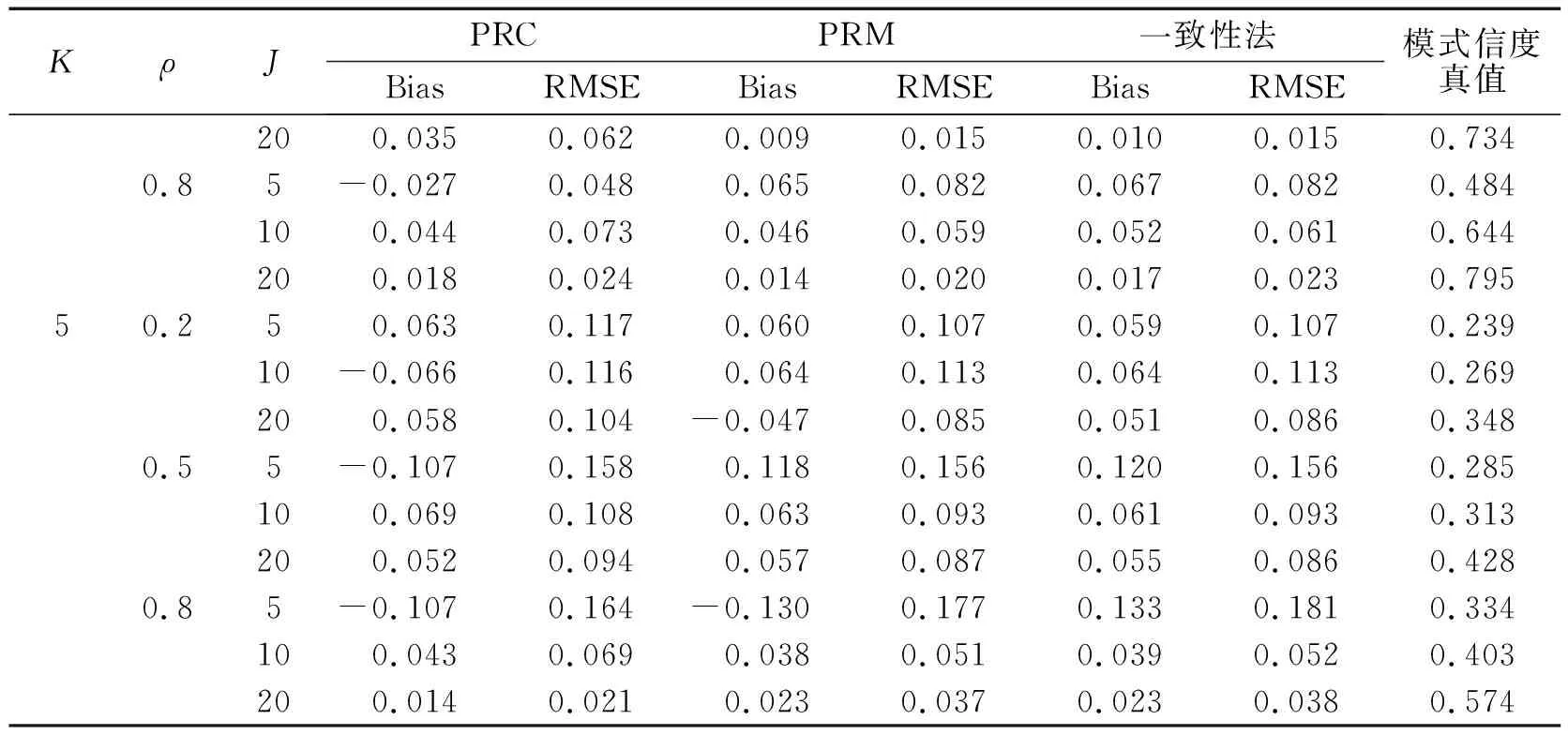
表1和表2是各个指标在不同实验条件下属性和模式信度估计结果的bias和RMSE值。图1和图2为对应的bias(A)和RMSE(B)折线图。由于信度真值是H次作答估计一致性的均值,因此,bias和RMSE的本质是“离均差的和”与“离均差平方和的算术平方根”,两者反映的是估计值与均值的波动大小。从整体上看,属性信度的估计比模式信度稳定,偏差值更小。
就属性信度来说,新方法对属性信度的估计精确度更高。表现最好的是ARC方法,bias的绝对值离0最近,RMSE在大部分实验条件下是最小的,从图1中也可看出,其bias的趋势线在0周围波动最小,RMSE的趋势线位于最下方。ARM的结果与一致性法表现基本相当,bias和RMSE与一致性法非常接近,ARM与一致性法的趋势线基本重合。四分相关法表现最差,bias在0周围波动最大,RMSE最大、趋势线最高。属性间相关性ρ对属性信度的影响并未呈现一致性趋势;随属性个数增加,估计偏差在整体上呈现不断增大趋势,bias波动变大,但ARC的表现仍最好;随题目数量增多,估计偏差在整体上呈不断减小趋势。就模式信度来说,PRC、PRM的估计精度与一致性法相当,三种方法的bias和RMSE值非常接近。而在有些实验条件下,PRC的精确性要比ARM和一致性法要高(表2的第2至第4行结果)。由图2可知,PRC、PRM与一致性法的bias趋势线波动幅度较一致,RMSE趋势线也基本重合。除此之外,属性间的相关性、属性个数以及题目数量对模式信度的影响与属性信度的结果基本一致。
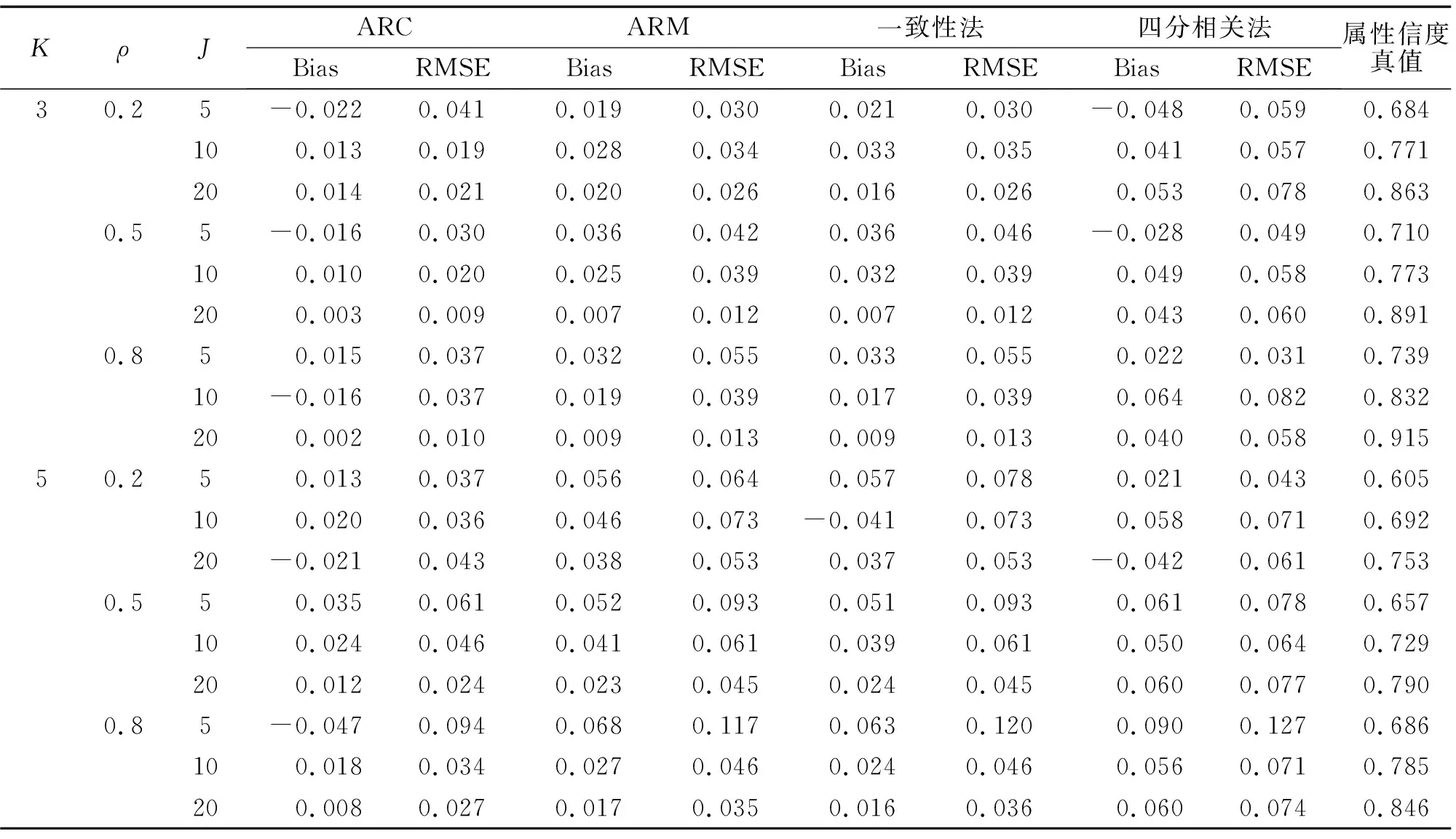
表1 不同方法的属性信度估计精度结果

表2 不同方法的模式信度估计精度结果
续表2
KρJPRCPRM一致性法BiasRMSEBiasRMSEBiasRMSE模式信度真值200.0350.0620.0090.0150.0100.0150.7340.85-0.0270.0480.0650.0820.0670.0820.484100.0440.0730.0460.0590.0520.0610.644200.0180.0240.0140.0200.0170.0230.79550.250.0630.1170.0600.1070.0590.1070.23910-0.0660.1160.0640.1130.0640.1130.269200.0580.104-0.0470.0850.0510.0860.3480.55-0.1070.1580.1180.1560.1200.1560.285100.0690.1080.0630.0930.0610.0930.313200.0520.0940.0570.0870.0550.0860.4280.85-0.1070.164-0.1300.1770.1330.1810.334100.0430.0690.0380.0510.0390.0520.403200.0140.0210.0230.0370.0230.0380.574

图1 属性信度的bias(A)和RMSE(B)折线图

图2 模式信度的bias(A)和RMSE(B)折线图
4 实证研究
4.1 ECPE数据
该数据来自于R软件CDM程序包中英语能力认证考试,包含2922人在28道题目上的作答数据,考察了3个属性:构词规则(Morphosyntactic rules)、衔接规则(Cohesive rules)、词汇规则(Lexical rules)。作答矩阵和Q矩阵可分别由data.ecpe$data[,-1]和data.ecpe$q.matrix进行调用。
使用四种方法估计该数据的属性和模式信度,结果见表3。

表3 ECPE信度估计结果
对于属性信度,模拟研究结果表明,当属性个数增大时,ARC的估计精确度最高,之后是ARM和一致性法,四分相关法表现较差。结合表3结果可知,使用四分相关法会高估ECPE的属性信度(均值为0.888),ARM和一致性法的属性信度均值基本接近(0.86左右),ARC估计的属性信度均值为0.825。对于模式信度,模拟研究结果表明,PRC的表现较好,计算得到ECPE模式信度为0.616,而PRM和一致性法基本相当为0.685左右。有趣的发现是,不论使用何种指标,属性A2的信度是最低的,通过表5的Q矩阵分析,A1考察了13次,A3考察了18次,而A2只考察了6次,说明考察次数会影响属性信度。其原因可能有:①当属性考察次数较少时,该属性估计的准确性自然会降低,导致其稳定性降低;②影响信度的因素之一为测验长度,在认知诊断中表现为属性考察次数,当次数较少时,信度理应不会太高。
4.2 分数减法数据
分数减法数据同样来自CDM程序包,包含536人在15道题上的作答数据,考察了5个属性。作答矩阵和Q矩阵可分别由data.fraction1$data和data.fraction1$q.matrix进行调用。使用四种方法估计该批数据的属性和模式信度,结果见表4。
模拟研究表明ARC表现最好,表现最差为四分相关法。结合表4结果可知,四分相关法仍高估属性信度(均值为0.876),ARM和一致性法估计的属性信度均值接近(均值为0.86左右),ARC估计的属性信度均值为0.818。对于模式信度,模拟研究结果表明当属性个数增加后,PRC、PRM和一致性法基本相当,模式信度约为0.6左右。同样,属性A5的信度最低,其次是A2和A4。这是因为A5只考察了3次,A2和A4分别考察了8次和9次,A1和A3分别考察了14次和12次。
5 结论与讨论
信度是衡量测验质量的一个重要指标,CDA同样需要重视信度问题。本文基于Bootstrap抽样思想,提出了两类计算属性和模式信度指标。新指标更加符合现实,突破了“假设被试两次测验的后验概率和边际概率完全相同”的局限。通过模拟和实证研究,与四分相关法和一致性法进行比较,验证了新指标的优越性,得到了以下主要的结论:
(1)整体上,属性信度的估计比模式信度稳定,且偏差更小;
(2)对属性信度而言,ARC表现最优,其次是ARM和一致性法,四分相关法表现最差。属性个数增加会增大估计偏差,题目数量增加则会减小其估计偏差;
(3)对模式信度而言,PRC、PRM估计精度与一致性法相当。属性间相关性、属性个数、题目数量对模式信度的影响与属性信度基本一致;
(4)实证研究可知,每种方法均能报告属性和模式信度。结合模拟研究结果,积差相关包括的两个指标(ARC和PRC)表现较好。想要提高属性信度,可适当增加该属性考察次数。
综上所述,计算属性信度时,综合排名为:ARC>ARM≈一致性法>四分相关法,推荐使用ARC。计算模式信度时,综合排名为:PRC>PRM≈一致性法,推荐使用PRC。
本文结合模拟和实证研究结果,拟探讨以下几个问题:
5.1 ARC与PRC相关说明

5.2 不同参数估计方法对信度的影响
Huebner和Wang(2011)比较了三种参数估计方法:后验众数法MAP、后验期望法EAP、极大似然估计MLE。不同的估计方法影响后验概率分布和属性边际概率,进而影响标准误,导致Bootstrap抽样范围发生变化。本文基于MAP得到的结果计算的信度,未来需探讨不同参数估计方法对信度的影响。
5.3 不同认知诊断信度指标的开发
在经典测验理论中,除重测信度,还有复本信度、内部一致性信度等。不同信度指标,其关注点不同,应用场景也不同。在报告信度时,需指出是何种信度。目前关于CDA中信度的研究,均从重测角度出发,这是因为该方法易于理解、指标容易构建。未来应考虑如何将其余信度指标拓展至CDA中,丰富CDA的信度指标体系。
除上述问题之外,不同的属性层级结构可能会对信度的估计带来影响,未来研究可以尝试在不同的属性层级结构下,以及不同认知诊断模型下探讨本文所提出新指标的表现。
猜你喜欢
世界科学技术-中医药现代化(2021年7期)2021-11-04 08:12:00
工程数学学报(2020年3期)2020-07-06 07:38:40
长治学院学报(2019年2期)2019-07-24 07:14:04
趣味(语文)(2018年7期)2018-06-26 08:13:48
雷达学报(2017年6期)2017-03-26 07:53:04
考试周刊(2016年88期)2016-11-24 13:30:50
管理现代化(2016年6期)2016-01-23 02:10:58
上海体育学院学报(2015年6期)2015-12-25 02:04:38
中国康复理论与实践(2015年7期)2015-05-09 08:31:45
少年科学(2014年10期)2014-11-14 07:38:17
