
一种复杂事件处理语言的自定义函数功能扩展
2018-11-01 08:34刘婧妍廖湖声高红雨
计算机与现代化 2018年10期
刘婧妍,廖湖声,高红雨
(北京工业大学信息学部计算机学院,北京 100124)
0 引 言
在当前的大数据背景下,很多领域需要对实时快速到来的数据(即流数据)进行分析。流数据往往单体价值较小,数据价值随时间后移而降低。传统对大数据的批量计算模式已很难满足对流数据的实时性查询需求。
复杂事件处理(Complex Event Processing, CEP)[1]是对流数据进行即时处理的一种技术。复杂事件处理模型使用事件模型驱动。在处理数据时,使用事件间的因果关系、模式匹配等对事件进行过滤,对事件做聚合映射,从而筛选出用户感兴趣的信息。复杂事件处理广泛应用于医疗[2-3]、物流[4-5]、传感器网络[6-8]等多个领域。
目前大多数的复杂事件处理语言都拥有基础算子[9](选择、映射、逻辑算子、序列化等),可供用户实现相应的复杂事件查询功能。CEL语言是复杂事件处理系统Cayuga[10-11]上运行的语言。CEL语言在传统数据库声明性语言的基础上扩展序列、迭代算子,以应对流数据的处理需求。CEL语言不支持窗口。EPL语言及其支持引擎Esper[12]支持对于XML类型数据的操作。它包含SQL中的所有算子,同时拥有连接、过滤、聚合算子。EPL语言支持自定义函数操作。但是其支持的函数只能处理同一类的所有数据,比如满足筛选条件的同一属性数据,而不能对其中的单个属性进行操作。以上的复杂事件处理语言都是针对流数据进行批量处理,无法针对数据进行细粒度的筛选和操作。XSeq语言及其系统[13-15]主要针对类型更加复杂的半结构化数据(XML流数据)进行查询。该语言可以处理基本的XPath查询结构,并添加了顺序约束和克林闭包。XSeq语言在基础的类数据库查询的同时,增加了部分内置函数以提供聚合的功能。例如计数、求均值、平均值等。XSeq对于XML类型数据的查询针对性较强,但其仅支持对于批量的XML元素做统一的查询,同时其描述相对复杂。CEStream是一种支持分布式流数据复杂事件处理的语言[16-17]。该语言主要针对XML数据进行检测,支持基础的SQL算子,以及常见的流数据处理算子连接、过滤、聚合等,并增加了顺序约束、克林闭包等操作。该语言提供了正规树模式匹配功能,并且支持结构连接,同时可以对多个事件源进行组合处理,事件处理能力较强。以上的复杂事件处理语言都难以满足对流数据做灵活的细粒度查询功能。
为满足复杂事件处理的细粒度处理需求,本文设计一种CEStream语言的自定义函数功能。通过定义函数形式参数的流模式匹配功能,实现对流数据标签的逐个处理。同时,在自定义函数中给用户提供对原有语句封装、参数化变量,提高语言的可用性。本文主要工作为:
1)为复杂事件处理语言CEStream扩展用户自定义函数(User-Defined Function, UDF)功能。扩展的UDF主要分为2类:支持形参模式匹配的细粒度处理UDF和参数化变量的UDF。
2)提出一种流模式匹配方法,使用户自定义函数支持对流数据的细粒度检测。
3)设计一种参数化变量的用户自定义函数。该函数给用户提供对原有查询语句的封装功能,增加语言的复用性和灵活性。
4)设计并实现CEStream语言的用户自定义函数运行系统。实验表明在完成相同功能查询时使用自定义函数,在提高语言可用性的同时,吞吐量并未下降;支持细粒度检测功能的自定义函数加强了CEStream复杂事件处理语言的检测功能。
1 动 机
原有的复杂事件处理语言CEStream主要处理语句有构造流数据、构造模式这2种语句。在用户使用该语言时,每当需要改变语句中的变量都需要对整个语句完全重写,用户体验不友好,同时容易造成程序代码冗余。为解决这种问题,可以设计用户自定义函数将原有语句放在函数内并将变量参数化,使用户在需要改动变量值时改变调用函数的传入参数即可。同时,自定义函数的设计带给该语言初步模块化的功能,使用户在求解问题时可以将问题分解为几个模块进行分析。
由于各行业对于复杂事件处理语言处理数据的能力要求越来越高,原有针对流数据中每个事件进行相同筛选、批量处理的操作已经不能满足使用者的需求。例如,股市、核电站警报等都需要复杂事件处理语言能够对数据进行一种上升趋势的筛选和处理。具体的查询案例如表1所示。

表1 查询案例
对于表1案例中这种上升趋势的判定,实际是前2个事件中的数据进行比较,根据不同的比较结果,进入不同的分支。这是对于复杂事件所进行的细粒度处理,用CEStream原有语句对每一个事件都进行相同筛选的操作是无法完成的。其他复杂事件处理语言中,只有Esper语言[12]支持这种细粒度的数据操作。但Esper语言对于这类操作的语言写法相对复杂,对于递增的n个连续事件,必须有n条语句与之对应。因此有必要设计一种令CEStream语言支持对元素的逐个处理,可以扩展一种支持形式参数模式匹配的自定义函数。该函数的形式参数中可以写一种只匹配一个到几个XML元素标签,同时可以嵌套匹配深层XML元素标签的模式匹配表达式。通过对XML数据流的头部进行匹配,达到对流数据进行细粒度处理的效果。同时,可以通过递归调用函数的形式,实现对流数据的整个处理过程。
2 用户自定义函数
在复杂事件处理语言CEStream中扩展用户自定义函数功能,给出一种通过UDF实现细粒度处理流数据的方法并增加该语言的灵活性。UDF提供流的参数模式匹配功能,使CEStream语言能够支持对于一个到几个XML标签流的匹配及操作,并通过对于XML标签内容的筛选进入不同的分支,提供细粒度检测数据的方法;同时实现对CEStream原有创建模式、创建流语句的封装,使原有变量参数化。
2.1 UDF语言设计及案例
2.1.1 支持形式参数模式匹配的细粒度处理UDF
CEStream语言的用户自定义函数为满足对XML数据段的细粒度查找操作,使用函数重载的机制对每一个XML标签组做出筛选,并能够根据其实际匹配的形式参数类型,实现对不同标签组,进行不同处理的操作。
表2给出一个监控核电站核心温度的自定义函数案例。该案例所对应的查询需求如表1所示。为监控核电站温度是否过高,可通过定义函数tempUp、 tempUp1进行处理。如表2中给出的函数定义以及形式参数注释所示,其中tempUp为入口函数,判断第一个eve事件的温度是否大于阈值$v,同时前2个eve事件是否后一个大于前一个。tempUp1函数为一组重载函数,针对后续的逻辑进行判断。

表2 监控核心温度函数案例
函数tempUp有2个形式参数,分别为流模式匹配表达式eve(t($a)$b) eve(t($c)$d) $e与阈值 $v。调用该函数时,传入的第一个流数据参数必须与流模式匹配表达式匹配。
重载函数tempUp1有2个同名函数,第一个函数判断结尾处是否符合最后一个事件的温度大于第一个事件温度的1.15倍;第二个函数判断中间状态是否一直符合递增关系。这2个函数的形式参数列表有部分不同,下面逐个说明第一个函数定义的形式参数含义:常量匹配表达式0,阈值$v,首个事件温度$t1st,已得到的流数据头部$h,流模式匹配表达式eve(t($a)$b)$e。当调用函数tempUp1时,根据传入参数成功匹配的形参,进行调用。
2.1.2 参数化模式的UDF
用户可以通过自定义函数将一个或多个功能封装起来,对外提供调用接口。在为复杂事件处理语言CEStream增加用户自定义函数功能时,可以考虑将一些固定的模式匹配语句、创建流语句放在函数内。也可将其中一些调用函数时经常更改的设定值作为函数的参数传入,设计一种参数化模式的函数。
例如复杂事件流处理中的典型应用火情检测,这种参数化模式的函数,可使得处理操作更便捷,对火情检测的细微调整等更加方便。表3给出了通常情况下的检测案例:30 s内出现连续3次温度检测值大于80 ℃,则发出一条报警消息。但由于环境不同,检测设定的温度阈值可能改变。使用表3所示的函数调用改变调用时传入的参数,即可改变温度阈值。

表3 火情检测案例
参数化模式的用户自定义函数,使CEStream语言更进一步模块化。它在实现对正规树模式匹配、事件流模式封装的同时,使用参数化模式的方式,使得在调用该函数时对函数内部的模式匹配标签以及创建流的时间窗口大小等变量可以进行调整。使用CEStream语言的用户可以实现自定义函数,并在调用函数时传入不同参数,以达到不同的筛选效果。
2.2 UDF语法
以下是复杂事件处理语言CEStream扩展的UDF的核心语法以及相关内置函数设置的描述。
1)CEStream语句语法。
正规树模式定义语法与事件流定义语法如表4与表5所示。

表4 正规树模式定义语法

表5 事件流定义语法
在扩展CEStream语言时,将原有的pd(正规树模式匹配)、sd(事件流模式)以及新增的赋值语句统称为语句(statement)作为用户可以书写的语句,并扩展变量(ID)、常量(PRIMITIVE_TYPE_CONST)、函数调用(func_call)、四则运算表达式、条件判断表达式这5种表达式。其中四则运算表达式、条件判断表达式不再给出详细的文法规定。下面是CEStream语句语法。
statement_list→statement_list ‘,’ statement | empty
statement→pd | sd | ID=expression ‘;’
expression→ID | CONST | func_call
| arithmetic_expr | if_expr
|expression‘,’expression
func_call→ID ‘(’ expression [‘,’ expression] ‘)’
2)UDF定义语法。
fd→define function ID ‘(’ paramlist‘)’ ‘{’ func_body ‘}’
paramlist→paramlist ‘,’ param | param
param→CONST | arithmetic_expr
| pattern_match
pattern_match→ID | NULL | TAG(pattern_match) pattern_match
func_body→[ statement ] return expression
用户自定义函数定义(fd)中包含函数名、形式参数以及函数体这3部分。其中形式参数(param)为基础类型常量(CONST)或流模式匹配表达式(pattern_match)或四则运算表达式。函数体(func_body)包括零个或多个CEStream语句(statement)以及一个返回值表达式。
当调用自定义函数时,通过传入的实际参数与函数定义中形式参数相应位置的流模式匹配表达式是否匹配决定是否调用该函数。对于函数重载形式的同名函数,根据顺序依次对函数调用语句的实参和函数定义的形参进行匹配,实参和形参全部匹配成功则确定调用语句调用的是该函数。
3)UDF细粒度查询内置函数描述。
对于流数据的处理,可以使用内置函数。内置函数操作流数据共分为4种:head、 tail、 isnull、 cons。这4种内置函数操作,分别针对流数据取头、取尾、判断变量是否为空、连接2个数据段。
可以作为内置函数参数的语法结构为:符合内置函数输入参数类型约定的用户自定义函数调用语句,内置函数,流模式匹配表达式,变量。
3 系统详细设计
系统设计部分主要对于自定义函数的处理进行说明,本系统分为编译模块、查询预处理模块、数据初步处理模块、集群这4部分。其中编译模块增加对语句、自定义函数定义、调用的编译功能;查询预处理模块区分细粒度处理UDF和参数化模式的UDF;数据预处理模块分别对2种函数调用做不同处理,实现新增的细粒度数据处理功能;集群对数据进行后续筛选工作,并输出最后的查询结果。
图1为该系统的活动图,说明了各个模块的工作流程和模块之间的关系。

图1 自定义函数处理系统活动图
1)编译模块是系统最初接收用户输入的CEP语言的模块,该模块做下列操作:
①对CEP语言进行语法分析及语义分析,生成查询计划。
②将查询计划发送给查询预处理模块。
2)查询预处理模块从编译模块接收查询计划,进行下列操作:
①接收查询计划,对其进行预处理。区分2种不同的自定义函数。对包含原有语句的参数化模式函数做预处理,对每一个数据源生成一个单源查询计划。对支持形参模式匹配的细粒度处理函数,将相互之间有调用关系的函数关联,合并生成细粒度函数查询计划。
②根据函数调用,分析变量间的绑定关系,并将其与查询计划发送到集群中做初始化操作。
③根据调用函数需要的数据源信息,将数据源和对应的数据处理模块连接,并发送查询计划给其对应的数据处理模块。
3)数据初步处理模块接收查询预处理模块生成的查询计划,做以下操作:
①对单源查询计划生成模式树,对实时到来的XML数据流进行正规树模式匹配并不断轮询。
②对细粒度函数查询计划,根据函数调用形参中的流模式匹配表达式,以及函数内的语句对XML流数据进行筛选。该部分采用惰性求值的方法,对需要值的部分求值并输出,后续的流数据以闭包形式保存,以解决对与流数据递归调用的问题。
4)集群使用接收到的查询计划做初始化操作,并在得到数据流后对其进行匹配、筛选等操作,输出最终的查询结果。
4 实 验
本章通过实验分析用户自定义函数的性能以及功能扩展。实验主要从自定义函数中使用原有语句时对查询性能的影响,以及其增加的细粒度数据处理功能这2个方面进行。主要分析:1)在完成相同功能的查询时,由自定义函数封装的语言和未封装的语言之间的性能差异;2)用户自定义函数对原有复杂事件处理查询语言的功能扩展。本实验的数据源为网站服务器中各种XML格式的记录日志。本章所有实验的软件环境为JDK1.8,硬件环境为Intel Xeon E5-1607 3.0 GHz、 6 GB内存的PC机。
表6是本实验的测试案例。案例Q1.1、 Q1.2是使用原有查询语句进行查询的案例,作为对照组。案例Q2.1~Q2.4使用用户自定义函数进行查询,其中Q2.1的查询效果和案例Q1.1相同,Q2.2~Q2.4的查询效果和案例Q1.2相同。实验通过使用用户自定义函数前后的性能对比,判断调用自定义函数对查询性能的影响。
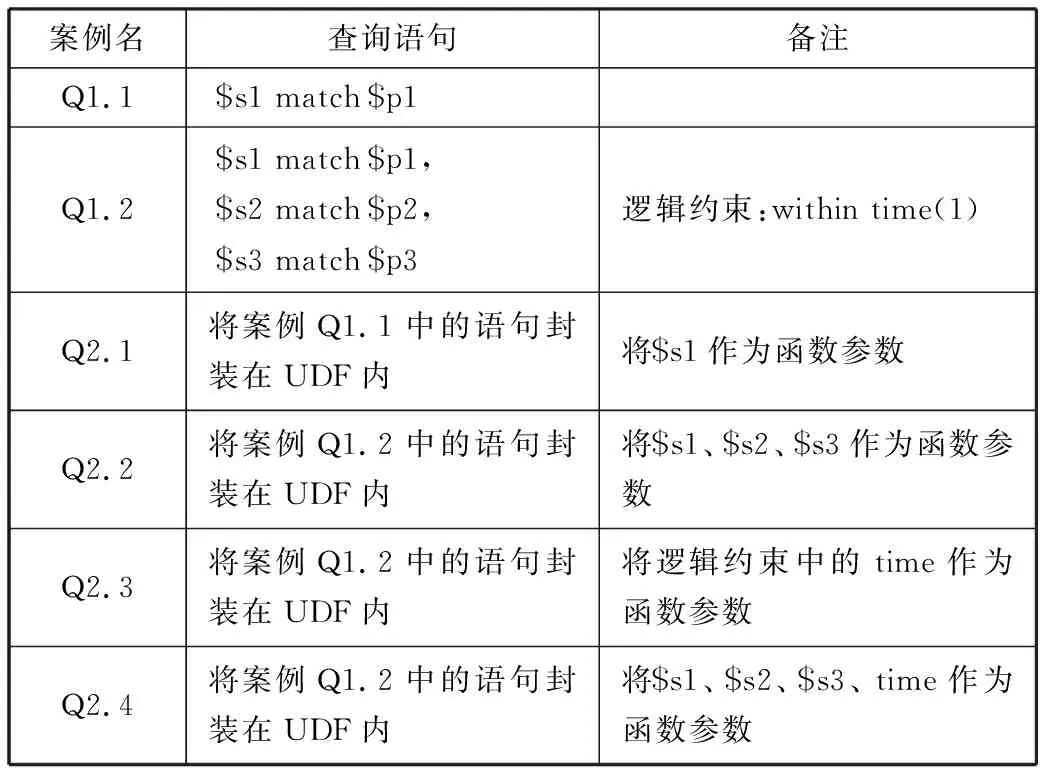
表6 测试案例
如图2与图3所示,单个数据源输入案例Q2.1和原有语句的对照组Q1.1在进行检测时,吞吐量均为24000(事件数/s)左右;多个数据源输入的案例中,使用UDF的Q2.2~Q2.4和其对照组Q1.2进行检测,吞吐量为19500(事件数/s)左右。实验表明,对于相同的查询需求,使用自定义函数来实现,在增加程序的可扩展性的同时,对查询效率的影响很小。

图2 单源案例吞吐量对比

图3 多源案例吞吐量对比
另外,为了测试用户自定义函数为CEStream复杂事件处理语言增加的细粒度查询能力,在各个需要复杂事件处理的行业中,筛选出100个需要对数据进行细粒度处理的场景进行功能性测试。这些场景包括股票分析、环境温度检测、故障检测等各个行业。实验证明用户自定义函数可以很好地支持这些细粒度查询要求。
5 结束语
本文提出了一种为复杂事件处理语言增加用户自定义函数功能的方案,并给出了自定义函数部分的语法设计及其运行系统。用户自定义函数使复杂事件处理语言增加了细粒度处理流数据的能力,并使用户能够通过函数对查询功能进行封装。
猜你喜欢
红外技术(2022年11期)2022-11-25
初中生世界(2020年47期)2021-01-07
安阳工学院学报(2020年2期)2020-06-05
安顺学院学报(2020年1期)2020-04-05
电子制作(2019年13期)2020-01-14
现代计算机(2019年6期)2019-04-08
移动信息(2018年1期)2018-12-28
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
