
基于蜜蜂繁殖机理的蜂群聚类算法
2018-10-30 11:15:48曹永春纪金水蔡正琦
西北民族大学学报(自然科学版) 2018年3期
曹永春,纪金水,邓 涛,蔡正琦
(西北民族大学 数学与计算机科学学院,甘肃 兰州 730030)
0 引言
蜂群算法是受自然界蜜蜂群体行为启发而产生的一种元启发式优化算法. 蜂群算法作为一种新兴的群体智能优化算法,近年来受到了相关学者的广泛关注.根据受启发的生物机理不同,蜂群算法可分为基于繁殖机理和基于采蜜机理两类蜂群算法,并且各成体系.基于蜜蜂繁殖机理的蜂群算法(marriage in honey-bees optimization, MBO)最早由Abbass于2001年提出[1],MBO算法将蜂后作为待求解优化问题的最优解,基于蜂群实际婚配行为建立算法模型,通过蜂后的婚飞过程,模拟蜂后与雄蜂的交配行为产生幼蜂,并通过工蜂(启发式方法)优化蜂后和幼蜂(潜在蜂后)的质量,最终获得问题的最优解.目前蜂群算法已被成功应用于解决可满足行问题、动态规划问题、多目标配电网重构问题、车辆路径问题等[2].
聚类就是按照一组数据对象的特征属性将其划分为若干类(簇),使得同类中的数据对象尽可能相似,不同类中的数据对象差别较大.聚类分析是一种广泛应用于机器学习、模式识别、数据挖掘及图像处理等领域中的重要的无监督的学习技术,是进一步分析和处理数据的数据预处理方法.按照不同标准,传统的聚类分析方法大体可分为以下几类:划分聚类方法、层次聚类方法、基于密度的聚类方法、基于网格的聚类方法、基于模型的聚类方法及模糊聚类法等[3].
随着智能优化算法的快速发展及广泛应用,多种智能优化算法被用于解决聚类问题并获得较好的聚类效果.文献[4]将多目标粒子群优化算法和K-means算法相结合生成随机分布的初始化种群,最终采用maximin策略确定帕累托最优解,算法表现出较好的聚类效果和稳定性,但存在粒子编码复杂,算法效率有待提高的问题.文献[5]通过引入差分进化中的变异和交叉思想对基于人工蜂群的模糊C均值聚类算法进行了改进,改进后的算法在收敛速度及聚类稳定性方面有明显改善.文献[6] 在现有K-means蚁群聚类算法的迭代过程随机选择一个或多个簇,并从中选择含有信息素最小的节点进行变异操作,改进了原有算法易陷入局部最优的问题,但算法耗时较长.文献[7] 结合了K调和均值聚类算法(KHM)和遗传算法的优点,采用KHM计算每一代种群的聚类中心,并构造适应度函数,通过遗传算法优化操作获得最优聚类结果.算法在聚类精度和稳定性方面表现较好,但该算法时间复杂度较高.
本文将MBO算法应用于聚类问题,提出了一种基于MBO的蜂群聚类算法(MBOCA).该算法采用基于聚类中心的蜂后染色体编码方式,通过模拟退火算法进一步优化初始蜂后来提高初始解的质量,从而加快算法的收敛速度;采用适合于聚类中心编码方式的算术交叉操作产生幼蜂;充分利用蜂后良好基因信息的启发式方法来模拟工蜂对幼蜂展开邻域搜索,从而有效改进幼蜂质量.
1 聚类评价标准
在解决聚类问题时首先要确定评价数据对象相似性的度量标准.广泛被使用的一个度量标准是数据对象之间的“距离”.本文采用Euclidean距离,以Kaufman等人提出的轮廓系数(silhouette coefficient)[8]作为衡量数据对象相似性的内部评价指标.轮廓系数的数学模型及含义说明如下:
对含有n个数据对象的聚类问题,若聚类结果将n个数据对象聚类为k个类,则该聚类方案K的轮廓系数定义为:
(1)
其中,Sj为第j个类Cj的轮廓系数,具体定义如式(2):
(2)
sj表示第j个数据对象xj的轮廓系数,其形式如式(3):
(3)
式(3)中aj表示数据对象xj与同一类Cj中其他所有数据对象的平均距离,bj表示数据对象xj与其他类Ci(i∈[1,k]且i≠j)中数据对象平均距离的最小值,即若di为xj与类Ci中所有数据对象的平均距离,则bj=min(di).
由上述模型可见,轮廓系数S(K)作为衡量聚类结果的相似度,兼顾了类内聚合度和类间分离度,即S(K)越小说明类间距离越大,类内距离越小,类内数据对象的相似度越高,聚类效果越好.本文将聚类结果的内部评价指标轮廓系数作为目标函数,用于计算蜜蜂染色体的适应度值从而指导蜂后的优化过程.
对聚类结果的另一个度量标准是外部评价指标,即用已知的正确聚类结果评判聚类算法的聚类效果.本文采用Rand index作为外部评价指标衡量本文算法的聚类效果,其定义如下:
(4)
式(4)中,TP和FP分别表示算法的聚类结果,与已知正确聚类结果相比,被划分到同一类中的正确和不正确的样本对数;TN和FN分别表示被划分到不同类中的正确和不正确样本对数.由上述Rand index定义可知,R(K) ∈[0,1],R(K) 的值越趋近于 1 ,则算法聚类结果越接近正确结果,说明算法聚类结果越好.
2 基于繁殖机理的蜂群算法模型
MBO算法属于一类群体智能算法,它是基于蜂群实际婚配行为而建立的算法模型.算法中每个蜂群是由蜂后、雄蜂、工蜂和幼蜂组成[9].蜂后的主要任务是通过产卵繁衍后代.在一个蜂群的生命周期中可能有一只或多只蜂后,只有一只蜂后的蜂群为单雌群,有多只蜂后的蜂群为多雌群.雄蜂的惟一任务是通过婚飞与蜂后交配,交配后雄蜂随即死亡.工蜂的任务主要是照顾幼蜂,有时候也产卵.幼蜂来自受精卵或未受精卵.由受精卵产生的幼蜂表示潜在的蜂后或工蜂,而来自未受精卵的幼蜂会生长为雄蜂.
蜂后的婚飞在蜂群繁殖过程中起着关键作用.一次婚飞开始于蜂后的一段舞蹈,接着蜂后开始飞离蜂巢,大量雄蜂追随其后试图与之交配.在一次典型的婚飞过程中,每只蜂后会选择7~20只雄蜂进行交配[1],每次交配就是将雄蜂的精子收集在蜂后的受精囊中形成蜂群的遗传池(genetic pool).当蜂后的受精囊装满精子后,蜂后飞回蜂巢开始产卵(包括受精卵和未受精卵).蜂后通过从受精囊中随机取出精子产生受精卵.新的蜂后和工蜂就是来自于受精卵,而雄蜂则来自于未受精卵.
婚飞可看作是在问题解空间中一系列状态之间的转移[2].在蜂后进行婚飞的开始阶段,蜂后被初始化为一定的能量和速度,并以一定的概率与相遇的雄蜂进行交配.把这个过程可以看作算法在较大范围的解空间中进行全局最优解的探索.随着婚飞的继续进行,蜂后的能量和速度逐渐降低,蜂后开始低速飞行寻找待交配的雄蜂,即进行局部最优解的开采.在蜂后的能量消耗至设定的阈值(如0)或受精囊装满精子后,蜂后停止飞行返回蜂巢.在算法处理过程中,工蜂的主要作用是照顾幼蜂,每个工蜂代表一种改进幼蜂质量的启发式方法.
MBO算法中雄蜂D被蜂后Q选择交配的概率按式(5)计算
prob(Q,D)=exp[-Δ(f)/S(t) ]
(5)
其中,
prob(Q,D)表示雄蜂D被蜂后Q选择交配的概率;
Δ(f)表示雄蜂D和蜂后Q之间适应度的绝对差值;
S(t)表示蜂后Q在t时刻的飞行速度.
每次婚飞后,蜂后的速度和能量按式(6)和式(7)衰减,
S(t+1)=α(t)×S(t)
(6)
E(t+1)=E(t)-γ
(7)
式(6)中α是取值为[0,1]区间的表示每次婚飞后蜂后飞行速度的衰减因子,式(7)中γ为蜂后每次婚飞能量的递减量.
由式(5)可见,在婚飞的开始阶段,蜂后的速度较高,则雄蜂被选中交配的概率较大.在这一阶段蜂后将与较多的雄蜂交配.种群的多样性得到了很好的保留,算法在较大空间中进行了全局最优解的探索.随着婚飞的进行,在婚飞后期蜂后的飞行速度衰减到较低时,则雄蜂被选中交配的概率主要受蜂后和雄蜂适应度绝对差值的影响.适应度越接近蜂后,适应度值的雄蜂被选中的概率就越大.在这一阶段能更好地保留蜂群的良好基因.算法在局部较优范围内进行更为精细的开采.
根据上述思想,MBO算法可分为如下4个主要阶段:
1)构建蜂后:根据问题解的编码方式随机产生指定数目的蜂后,并应用启发式方法优化每个蜂后,得到较高质量的蜂后.
2) 交配过程:在婚飞开始前,将每个蜂后的能量和速度初始化为[0.5, 1]区间的随机值,在婚飞期间每个雄蜂依据式(5)计算的交配概率与相遇的蜂后进行交配,并以式(6)和式(7)更新蜂后的能量和速度,直到蜂后的能量小于设定的阈值或受精囊被装满.
3)产生幼蜂:通过单倍体交叉蜂后的染色体和受精囊中收集的雄蜂精子生成幼蜂,并通过工蜂照顾幼蜂(即使用启发式方法执行局部搜索优化幼蜂).
4) 替换蜂后:若优化后的最好(适应度值最高)幼蜂优于蜂后,则用该幼蜂替换蜂后,并杀死其他幼蜂.
3 基于繁殖机理的蜂群聚类算法
3.1 蜂后的染色体表示及选优
结合聚类分析的问题特征及MBO算法的处理过程,本文蜂群聚类算法中蜂后的染色体以聚类中心表示,即蜂后的染色体可表示为向量:
Q=[X11,X12, …,X1d,X21,X22, …,X2d, …,Xk1,Xk2, …,Xkd]
即每个蜂后的染色体为k×d个实数组成的基因序列,k表示特定聚类问题的聚类数,d表示待聚类样本的维数.根据文献[1]的实验结果,本文算法采用1个蜂后.
初始蜂后是通过随机生成蜂后染色体的每一位基因Xij获得,每一位基因Xij须满足Xij∈[jmin,jmax].jmin和jmax分别表示在数据集的所有样本中第j维数据的最小值和第j维数据的最大值.
初始生成蜂后的基因质量在一定程度上将会影响MBO算法的求解效率,应该通过工蜂对其优化.本文采用的方法是首先按照上述蜂后染色体表示的方法随机产生一组初始解表示候选蜂后,按照每个蜂后的适应度值排序,选出适应度最高的候选蜂后作为蜂群的蜂后.然后采用模拟退火启发式算法对初始蜂后进行邻域搜索,进一步优化蜂后质量,加快算法的收敛速度.在邻域搜索过程中发现候选蜂后Q′的适应度值高于当前蜂后Q的适应度值,则以Q′取代当前蜂后Q;否则以概率p(T,Q′,Q)决定Q′是否取代当前蜂后Q,p(T,Q′,Q)的计算如下所示:
(8)
式中T表示当前时刻的温度,F(Q′)和F(Q)则分别表示候选蜂后Q′和当前蜂后Q的适应度值.
3.2 通过交叉产生幼蜂
本文算法随机产生雄蜂,雄蜂的染色体与蜂后一样以聚类中心表示.由于雄蜂是单倍体,其精子只有染色体的一半,即只有部分基因位的值.在算法交叉操作中本文通过以50%的概率选择雄蜂染色体的基因位与蜂后染色体对应基因位交叉.结合算法中蜂后染色体的表示方式,本文采用适合于蜂后编码方式的算术交叉,具体交叉方法按下式进行.
Qki=αXki+(1-α)XPi
(9)
其中,α为(0,1)区间的随机数,Xki表示蜂后Xk的第i位基因值,Xpi表示被蜂后选中进行交配的雄蜂Xp精子的第i位基因值,Qki表示交叉操作后蜂后第i位新基因值.
3.3 幼蜂优化方法
工蜂照顾幼蜂,即使用启发式方法优化幼蜂的过程.本文充分利用蜂后良好的基因信息对幼蜂展开邻域搜索来改进幼蜂质量,具体操作方法按式(10)进行.
Vij=Xij+Rij(Xij-Xkj)
(10)
其中,Xi表示当前幼蜂所代表的染色体,Xk表示蜂后所代表的染色体,j为在幼蜂(或蜂后)染色体所含基因数范围内的随机数,而Rij则是用来控制幼蜂邻域搜索范围的随机数,其取值范围为[-1,1].本文利用蜂后良好的基因Xkj调整当前幼蜂对应基因Xij,从而将当前幼蜂基因Xij改善为Vij.
3.4 蜂群聚类算法流程描述
综上所述,蜂群聚类算法流程描述如下:
首先设置初始参数,MBO算法需要设置的参数包括总婚飞次数N,每个蜂后受精囊的大小M,雄蜂数量p,幼蜂数量y.设置初始参数后算法按下述步骤进行.
Step1:按3.1所述蜂后的染色体表示方法随机生成m个候选蜂后,计算它们的适应度值,选出最优(适应度值最高)的一个作为蜂后并用模拟退火算法进一步改进蜂后的质量.
Step2:当蜂后当前婚飞次数t没有达到指定的总婚飞次数N时.
初始化t时刻蜂后的能量E(t)和速度S(t),并按式γ=(0.5×E(0))/M计算蜂后在t时刻能量递减量.式中M表示蜂后受精囊的大小.
以蜂后生成的方法随机生成p个雄蜂并计算它们的适应度值,并按式(5)计算每个雄蜂被当前蜂后选择交配的概率prob(Q,D).
Step3:当蜂后的能量E(t)>Emin,并且蜂后的受精囊未装满时,选择一个交配概率prob(Q,D)最高的雄蜂,并将其精子装入蜂后受精囊中,受精囊中精子数目增1.
根据式(6)和式(7)更新蜂后的速度和能量.
Step4:当前产生的幼蜂数量未达到指定数量y时,蜂后染色体与从蜂后受精囊中随机取出的一个精子按式(9)通过交叉操作产生一个幼蜂,并使用工蜂照顾幼蜂,即用式(10)进一步改进幼蜂质量.
Step5:计算所有幼蜂的适应度值,找出所有幼蜂中适应度最高的幼蜂,如果该幼蜂的适应度值高于当前蜂后的适应度值,则用该幼蜂替代蜂后Q作为新的蜂后.
杀死当前所有幼蜂,转Step2.
Step6:当蜂后婚飞次数达到指定的总婚飞次数N后,则蜂后Q的染色体表示待求解问题的最优解,输出最优解.
4 仿真实验及结果分析
为验证本文提出的基于MBO蜂群聚类算法的聚类效果和有效性,对1组自构造数据集和3组取自UCI(http://archive.ics.uci.edu/ml)的真实数据集进行了对比实验,比较了k-means聚类算法、遗传聚类算法(GGA)[12]、基于采蜜机理的人工蜂群算法(ABC)及本文基于繁殖机理的蜂群聚类算法(MBOCA)的聚类效果.
自构造数据集由以等概率生成的160个球形分布的二维数据点组成,并以高斯分布分配到8个类中.本文以SCDS表示自构造数据集.2组真实数据集是来自UCI的Iris数据集、Wine数据集.Iris数据集中每个数据对象有4个属性值,将150个这样的数据对象分为3个类,每类50个数据对象.Wine数据集中每个数据对象有13个属性值, 178个这样的数据对象分布在3个类中.
根据文献[1]的实验结果,本文算法采用1个蜂后,设置幼蜂数目为100,蜂后的受精囊大小为21,随机产生的雄蜂数目为150,婚飞最大次数为200.工蜂以两种启发式方法实现,一种是3.1所述的模拟退火方法,用来优化初始蜂后的染色体;另一种是3.3所述的提高幼蜂质量的启发式方法.
4种聚类方法的聚类结果通过Rand index表示,在实验中通过每种聚类算法分别在不同的数据集上运行30次,统计出Rand index的最大、最小及均值,并分别用max、min、mean表示,聚类结果如表1所示.
表1几种算法聚类结果的比较
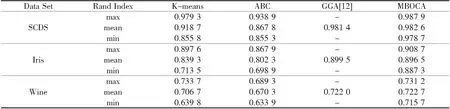
表1中数据说明,K-means算法虽然简单高效,在各数据集上的Rand index最大值较高,均值也可接受,但由于算法易受初始聚类中心的影响,多次聚类结果的差异较大,表现出聚类结果的稳定性较差.原始人工蜂群算法(ABC)在算法的各步骤未进行改进和优化的情况下,聚类精度和算法的稳定性都最低.文献[12]的遗传聚类算法和本文提出的基于MBO的蜂群算法,因结合聚类问题的具体特征及染色体的编码方式,在算法的各步骤进行了有针对性的启发式方法的处理,聚类精度均较高.由表中数据可以看出,本文算法在各数据集上的Rand index最大值和最小值的差值最小,说明本文算法在聚类效果的稳定性方面有较大的优势,并且相对遗传算法而言,MBO算法的复杂度较低.
基于以上分析,本文通过对初始蜂后的选优和优化,以及在幼蜂的优化过程充分利用蜂后优秀的基因信息进行启发式搜索,有效提高了初始蜂后和幼蜂的质量,这样既加快了算法的收敛速度,相比其他几种算法,也表现出较高的稳定性.说明本文算法是一种可行的、有效的聚类方法.
5 结束语
本文将改进的MBO算法应用于聚类分析,提出了一种基于MBO的蜂群聚类算法.算法中蜂后的染色体采用聚类中心表示.初始蜂后的产生首先在多个随机生成的蜂后中选优,再通过模拟退火启发式方法进一步优化,有效提高了蜂后的质量,加快了算法的收敛速度,加强了算法的稳定性.生成幼蜂的交叉操作采用适合蜂后染色体编码方式的算术交叉,结合MBO算法中雄蜂精子单倍体这一特征,在算法交叉操作中对每个基因以50%的概率与蜂后对应基因进行交叉操作产生幼蜂.对幼蜂的优化算法充分利用蜂后良好的基因信息,对幼蜂展开邻域搜索来改进幼蜂质量.另外,本文采用兼顾类内聚合度和类间分离度的轮廓系数计算蜜蜂的适应度值,使算法的聚类结果更可靠.通过比较几种聚类算法在3个数据集上的对比实验,结果表明本文算法具有较高的聚类精度和较好的稳定性.
猜你喜欢
第二课堂(课外活动版)(2022年1期)2022-04-23 12:35:57
中国蜂业(2021年1期)2021-03-28 15:39:18
四川蚕业(2021年1期)2021-02-12 02:03:12
昆虫学报(2020年6期)2020-08-06 06:42:52
中国蜂业(2019年9期)2019-01-07 12:11:44
中学生物学(2016年8期)2016-01-18 09:08:26
中国马铃薯(2015年3期)2015-12-19 08:03:56
小学教学研究·新小读者(2014年3期)2014-02-19 22:56:36
中国蜂业(2013年12期)2013-01-24 16:06:59
中国蜂业(2012年8期)2012-08-15 00:45:30
