
基于分布式Redis集群的WEB共享管理研究
2018-10-23 02:02黄裕
计算机与数字工程 2018年10期
黄 裕
(广东生态工程职业学院 广州 510520)
1 引言
随着大数据时代的来临,基于WEB共享的信息系统需要面对的数据具有海量、实时、高并发等特点,这就要求WEB共享能够快速响应大量的磁盘写入、读出操作,高频率地更新数据检索目录,高效率地处理大规模的内存数据处理队列。目前常用的WEB共享系统的数据存储平台都是分布式的物理磁盘的文件系统。基于分布式磁盘文件系统系统具有较好的存储分布性和结构可拓展性,可用较低的性价比提供巨大的存储空间,还拥有较强的数据存储可靠性和较高的数据存取吞吐量。但是由于基于物理磁盘的文件系统在处理高并发的海量数据的实时存取时需要大量磁盘I/O操作,而且需要消耗大量的内存资源,因此会导致数据处理性能急剧下降、数据检索效率低下、服务器内存泄漏甚至数据丢失、系统崩溃。
针对这种高并发的海量数据实时存取引发的性能瓶颈,基于分布式内存数据库Redis的集群体现了突出的优势。Redis是一种能够提供高速访问、丰富数据类型支持、高并发读写能力的内存数据库。基于分布式的Redis集群则是利用冗余的Redis数据库构建的具有数据冗余、故障容错的分布式数据库系统,具有Redis数据库所有优异性能之外还能够降低单点损失,对外提供可靠数据管理服务。
本文通过对分布式Redis集群的关键技术进行深入研究,并利用Redis内存数据库集群的性能优势,构建分布式存储架构,将分布式Redis集群应用于基于WEB的海量数据实时共享系统,提高WEB共享系统的数据实时处理的能力,为高并发的海量数据的实时存取提供一种高效的解决方案。
2 分布式Redis集群的关键技术
2.1 分布式Redis集群的容错机制
Redis节点集群是由主节点和从节点组成全连接拓扑结构。主节点保存从节点的数据备份。集群节点两两之间建立点到点的连接,并通过心跳信息传递节点是否可达的信息。Redis集群的拓扑结构如图1所示。
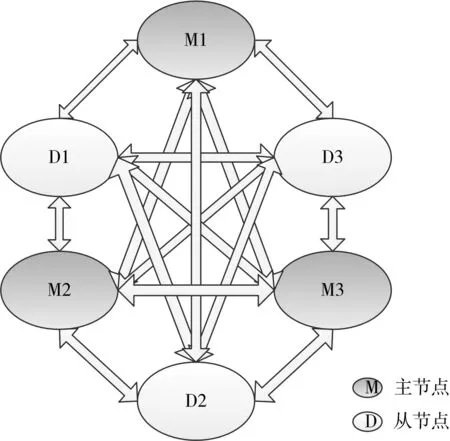
图1 Redis集群的网络拓扑示意图
Redis集群在运行过程中,需要高效率的实现对故障节点的掉线检测和节点修复。故障节点按其状态可分为疑似掉线、掉线和恢复三个阶段。集群中节点是通过和其他节点通过周期性的心跳信息来获取各自节点状态信息。心跳信息的发送分为两个阶段:首先在发送周期的一开始发送hello信息;其次向超过T/2时间没有通信的所有节点发送hello信息。其中T为心跳超时时间。心跳信息分为hello和echo两种格式。心跳信息包含一个in⁃fo负载字段.info字段随机包含若干条节点的状态信息。
发送节点首先随机性选取一个节点发生hello心跳信息,如果超过超时时间T仍没有收到echo回复信息,就将对应节点标记为疑似掉线状态;如果在T之内收到回复信息echo,就对回复信息的info字段进行解析并更新本地节点状态数据库。随着节点不断发送心跳信息,超过半数的节点把该节点的状态标记为疑似掉线,就确定该节点掉线。
如果主节点被确定为掉线,就需要进行节点修复操作。首先从节点在Redis集群内广播主节点选举信息,Redis集群进入节点修复状态。收到选举信息的主节点依据选举算法给从节点投票,获得超过一半主节点投票的从节点被选举为新的主节点。新的主节点当选后广播获选信息,Redis集群结束节点修复状态并恢复上线。
由上述分析可知快速收敛对故障节点的状态检测是提高容错机制效率的关键。在故障节点的检测过程中,Redis集群节点可分为两类:已知故障节点的不可达状态的节点(记作已知节点)和未知故障节点的不可达状态的节点(记作未知节点)。
集群节点总数为S。检测过程一开始,只有一个已知节点N。N每次随机对一个节点进行状态传播。则传播过程可表示为{B (m),m>0}。其中B(m)表示为经过m次传播后已知节点的次数,显然B(0)=1。
假设B(m)=y,则B(m+1)后已知节点可能增加的数量记为x,其中 x∈[0 , y]。增加x个节点的概率为
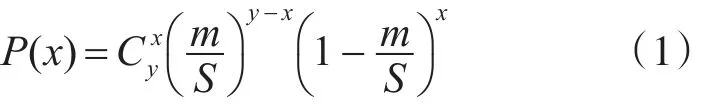
由式(1)可以得出B(m+1)为
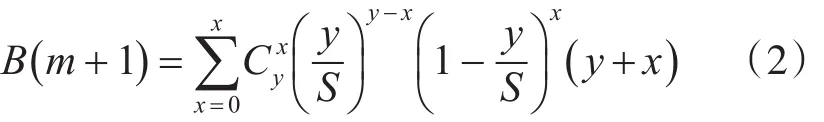
经过公式整理和递推计算可以推导出:
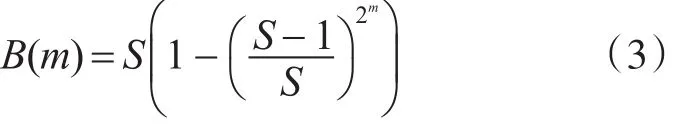
式(3)表明了经过m次的心跳发送,已知节点的数量。当B(m)=S/2时,就能够完成掉线检测。因此完成掉线检测所需的心跳发送次数为

假设心跳发送频率为f,心跳信息中info字段中包含故障节点的概率为p,掉线检测耗时t满足:
为加快故障节点信息的状态检测过程,同时不能过度增加节点的通讯负担和网络负载,需要均衡心跳信息的通讯负载,使得心跳信息的发送数量在时间上保持均衡,降低心跳信息的发送峰值,同时还要避免节点的心跳间隔过长。
假设某节点心跳频率为f,在T/2的时间内执行心跳函数的次数为Z,在T/2的时间内发送心跳信息的数量为C。记第x次心跳信息中发送量为hx。则在T/2时间内,需要根据节点状态数据库重新计算hx:

如果集群内节点数量不变,T/2内通信的数量固定为C=S-1。结合式(3)和式(5)可得出:
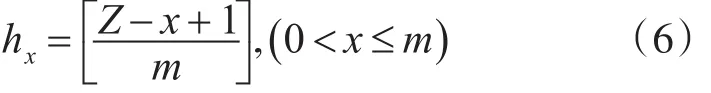
为避免节点心跳间隔过长,可使用优先级队列来选择心跳对象节点的。优先级依据与该节点心跳时间间隔来设置,时间越长优先级越高。这样可保证优先向心跳间隔最长的节点发送心跳信息。
Redis集群发送心跳信息的算法过程如下:
1)初始化队列Q1、队列Q2和计数器Counter:Q1为空;Q2包含所有节点;Counter设置为1。
2)如果Q1为空且Counter为1,则交换队列Q1和队列Q2。
4)从队列Q1中弹出hx个节点,发送心跳信息;把 hx个节点压出队列Q2;对(i+1)/K取余,并把取余结果赋值给i。
5)跳转步骤2)执行。
2.2 数据读写流程
基于分布式Redis集群的数据存储过程主要包括数据缓存、建立索引、数据整理与磁盘写入。为提高数据写入的并发能力,数据在写入之间要将数据分成小数据块分配到不同的Redis客户端。数据存储流程如图2所示。
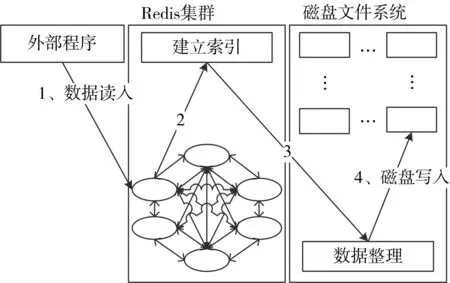
图2 数据存储流程
数据写入操作的具体描述如下:
1)读取外部程序的数据,分块读取的数据,批量存入分布式Redis节点。
2)建立数据索引,并在Redis集群内部共享索引。
3)根据索引合并数据块。
4)把处理后的数据提交给HDFS客户端,进行物理磁盘写入操作。
基于分布式Redis集群的数据读取过程主要包括缓存检索、索引映射、磁盘数据读入和数据缓存。为提高数据读取的响应能力,Redis集群缓存了磁盘数据的索引和一部分使用频率较高的数据。数据读取流程如图3所示。
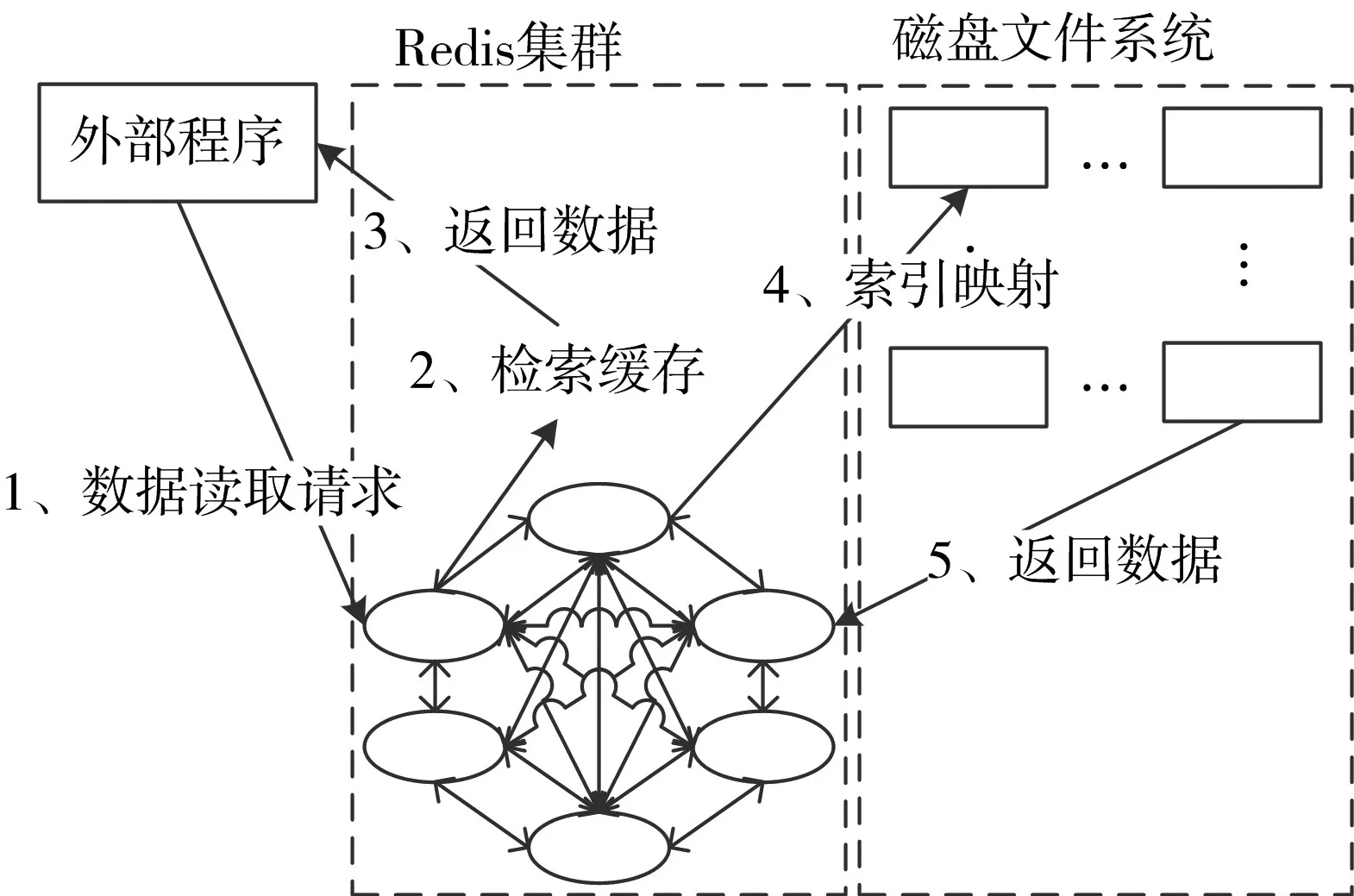
图3 数据访问流程
数据读取操作的具体描述如下:
1)接受外部程序的数据读取请求。
2)检索Redis集群中是否存储了要访问的数据,如有,立即返回数据;如没有转步骤3)。
3)在Redis集群中检索数据索引,并把检索到的索引映射给磁盘文件系统的管理客户端。
4)磁盘文件系统的管理客户端根据接收的索引记录读取、合并数据,把整理好的数据缓存到Re⁃dis集群中,并由Redis节点把数据返回给外部程序。
5)数据预存储机制激活,把从磁盘文件系统中读取的数据设置为使用频率高的文件,缓存到Re⁃dis集群中,把使用频率最低的文件替换掉。
2.3 数据索引的建立
快速读取数据的一个关键是实时建立数据索引。由于WEB数据存储在时间上的随机性和数量上的海量性,给Redis集群上数据索引的更新、维护带来困难。Redis是基于键值对的数据库,这让Re⁃dis数据库拥有高效率的基于主键检索的优势,但是在面对基于非主键的检索时,Redis需要全表关键字扫描,效率难以得到保证,而且其响应速度会随着索引结构的增大而快速降低。为此需要对Re⁃disd的索引结构进行轻量化处理,以适应快速检索的需求。
用二维平面代表磁盘文件系统的逻辑地址,其中每一个网格表示数据的一个逻辑地址,如图4所示。在逻辑地址平面中为每一个常用的检索关键字分配一个可以由Z曲线完整编码的矩阵,如图中矩形框z1、z2、z3。在同一矩阵内的数据具有相同的关键字,在矩阵相交区域则具有所属矩阵关键字的组合,如z1和z2相交区域具有z1·z2的关键字组合。
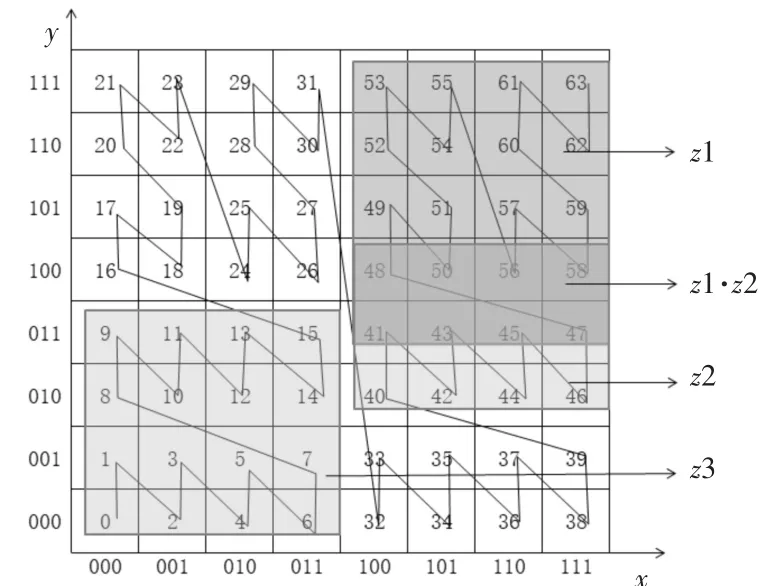
图4 逻辑地址的二维平面
Redis用键值对的形式保存所有关键字矩阵之间的包含关系形成关键字矩阵索引表,如表1所示。Redis用键值对的形式记录关键字所属矩阵及其交叉矩阵的索引信息,如表2所示。其中关键所属矩阵的索引信息包含其实网格的二维平面坐标和网格数量。

表1 关键字矩阵索引表
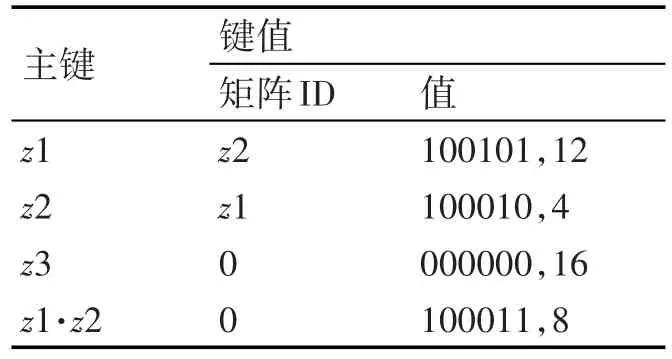
表2 关键字所属矩阵索引表
通过对关键字建立矩阵索引,可以快速检索到不同关键字组合所分布的逻辑区域,进一步提高了含有相同关键字的数据之间的关联度,大大提升了基于关键字的数据检索效率。
3 基于分布式Redis集群的WEB共享架构
共享数据普遍具有海量性、数据的无特定相关性、数据的并发访问量大以及数据访问响应的实时性等。根据共享数据的上述特点,利用分布式Re⁃dis集群的高速读写性能和分布式原理作为系统数据存储的缓存,提高数据访问的速度和系统的并行性,从而解决大的访问量,而将不经常访问的数据存储在磁盘上的Hadoop文件系统中,形成两级的数据存储架构,如图5所示。
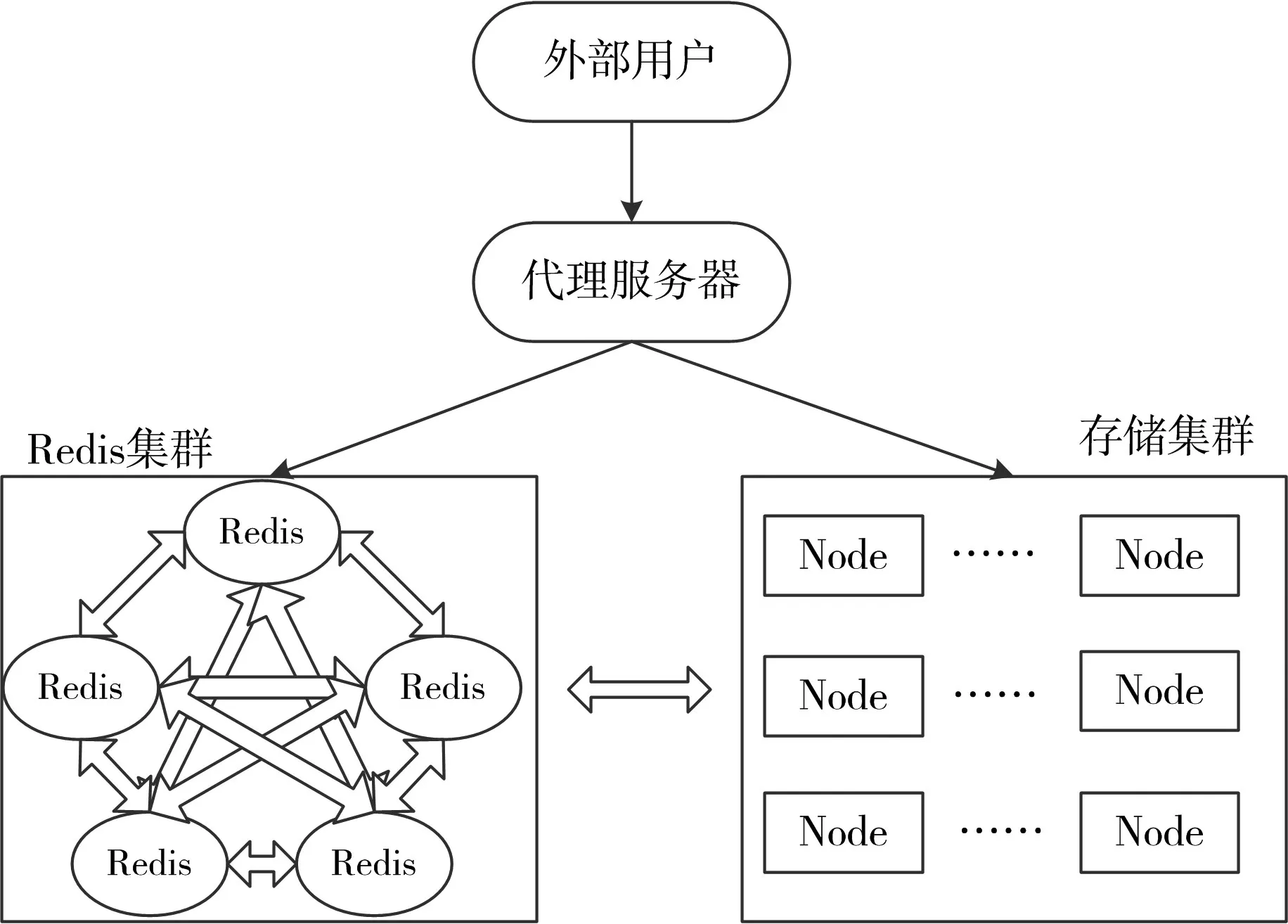
图5 基于分布式Redis集群的WEB共享架构示意图
图5 所示的架构主要由分布式Redis集群、存储集群、代理服务器组成。Redis集群具有较强的数据读写性能,作为存储集群的分布式数据缓存系统。在大数据系统中存储集群通常是基于Hadoop的HDFS存储集群。存储系统为数据永久存储提供磁盘空间。代理服务器的主要作用是接受外部用户提交的数据访问请求,并把请求数据访问连接分发给Reids节点,具体的操作由Redis完成。
HDFS存储集群使用分布式Redis集群作为数据存储的缓存,HDFS集群中各节点都能直接访问Redis集群,因此,采用这种基于Redis分布式缓存的架构具有结构清晰、数据存取效率高的优势。HDFS系统的数据存取操作分为两步。
第一步,HDFS把共享数据加载到分布式Redis集群中。这一步主要是由一个Map阶段的作业来完成。各Map任务节点并行地获取集群外部的数据,并保存到Redis集群中。
第二步,当Redis集群的缓存数据存储完成后,MapReduce节点开始建立起到Redis集群的连接,以便在执行数据操作时可以随时访问Redis集群读写共享数据。
4 测试分析
测试环境为90个节点构成的Redis集群,其中包括30个主节点。测试用的Redis版本为最新的稳定版3.2.9。测试用到的物理主机有两台,配置为48核、内存256G、cpu为Inter至强E5-2690 V3 2.69GHz。为了验证文中阐述的分布式Redis集群的性能,分别进行如下三项测试:主节点故障恢复测试、数据缓存性能测试和不同数据量下检索性能测试。
4.1 主节点故障恢复测试
Redis集群主节点故障恢复测试主要是记录集群恢复故障节点的时间。主节点恢复过程分为三个阶段:故障检测阶段、故障确定阶段和故障恢复阶段,各阶段耗时依次记为t1、t2、t3。首先在测试集群中人为宕机1~14个主节点,然后分别对各阶段耗费时间进行记录分析。其中故障检测阶段是单个节点发送心跳信息,这主要与节点的配置性能有关,因此这个阶段耗用的时间本次测试不予记录。
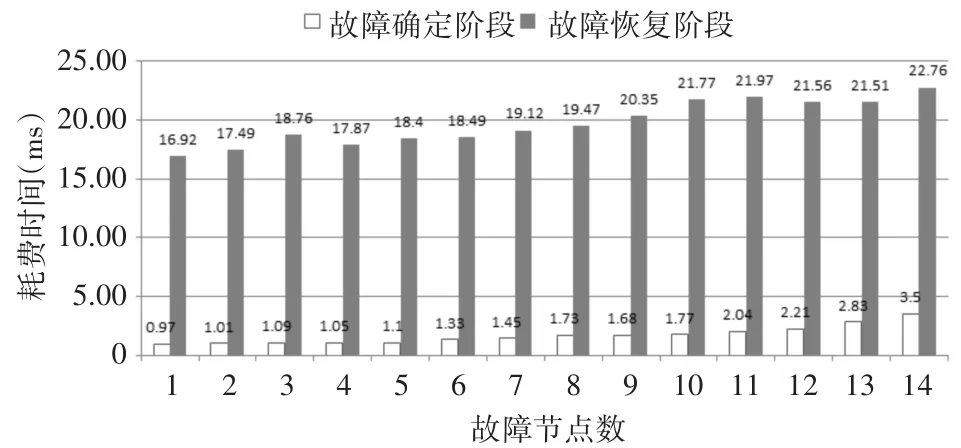
图6 主节点故障恢复时间测试结果
由图6可以看出,Redis集群在故障确定阶段耗费时间极短,这是由于本文所述的Redis集群采用效率较高的故障容错机制。故障恢复阶段耗费时间较长是因为此阶段需要在所有节点运行选举算法。总体而言,Redis的故障恢复时间能够控制在20s以内。
4.2 数据读写性能测试
实验数据使用网页链接数据,共包含52773315个网页节点,大小约41GB。测试步骤是先把数据写入磁盘,随后再把数据读出。测试中为了验证Redis集群的性能,使用30、60、90个节点分别进行测试。测试结果如表3所示。
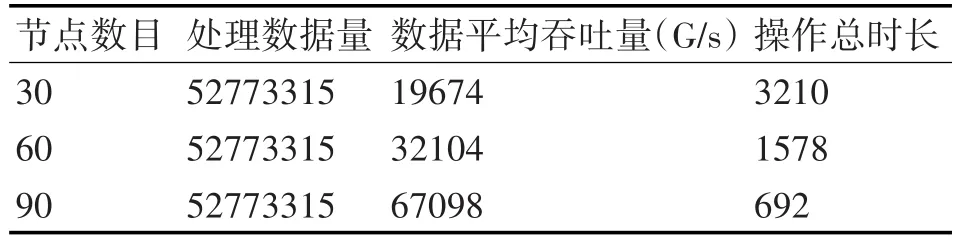
表3 分布式Redis集群数据读写测试结果
测试结果表明,分布式Redis集群具有较好的数据吞吐量,这主要是由于Redis是基于内存的数据库,数据直接从内存读取,效率能够得到很好的保证。而且随着节点数目的增加,Redis集群的数据读写能力直线上升,说明Redis集群具有很好的可拓展性,能够比较简便地通过增加节点的数量来提升集群的数据读写性能。
4.3 数据索引性能测试
测试首先对不同数据量下的索引文件的大小进行记录。然后对不同数据量下的基于关键字的检索速度进行测试。测试结果如图7所示。
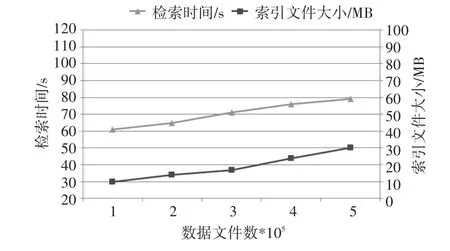
图7 数据索引性能测试结果
文中所述的Redis索引是基于关键字矩阵的键值对,所有数据的逻辑地址的索引信息都概括为矩阵的起始坐标和矩阵的大小两个信息,因此索引文件在海量数据的基础上仍能够保持较小的体积。基于关键字矩阵的Redis索引把关键字重合的区域定义为不同的关键字区域,这样使得基于关键字检索时能够快速定位目标区域,减少了无效的索引扫描,加快了索引检索的速度。
5 结语
为了解决WEB共享的高并发的海量数据实时存取引发的性能瓶颈问题,本文提出了在传统存储系统的基础上增加Redis分布式集群作为缓存的解决思路。测试结果表明,Redis分布式集群具有运行稳定性好,大数据并发读写时具有优异的性能,数据检索速度快等优点,同时Redis分布式集群可拓展性优异,能够很好地与不同数据需求的系统相结合,有效地提升了WEB共享中高并发的海量数据的实时读写效率。
猜你喜欢
华人时刊(2022年1期)2022-04-26
纺织科学研究(2021年6期)2021-07-15
电子制作(2019年22期)2020-01-14
动漫界·幼教365(大班)(2019年10期)2019-10-28
军事运筹与系统工程(2019年4期)2019-09-11
信息化建设(2019年2期)2019-03-27
制导与引信(2017年3期)2017-11-02
知识就是力量(2017年2期)2017-01-21
燕山大学学报(2015年4期)2015-12-25
汽车电器(2014年5期)2014-02-28
