
基于字符的递归神经网络在中文语言模型中的研究与实现
2018-10-21 10:52伍逸凡朱龙娇石俊萍
现代信息科技 2018年8期
关键词:自然语言处理
伍逸凡 朱龙娇 石俊萍
摘 要:本文通过对基于字符的长短记忆递归神经网络的研究与实现,探究了其在自然语言模型中的应用,并选用了小说《挪威的森林》对递归神经网络进行了训练与文本生成,总结了不足之处,探讨了未来应该解决的问题与研究方向。研究结果表明递归神经网络仅能学会字与字或词与词之间在表面的连接或变化关系,而自然语言不仅仅是文字表面的异同,更多的是字里行间中情感或思维上的变化,这些是一组序列数据所不能表达的。因此,未来自然语言模型应更加注重对于文字间情感和思维的学习,构建更接近自然语言的模型。
关键词:长短记忆单元;递归神经网络;自然语言处理;字词嵌入
中图分类号:TP391.1;TP183 文献标识码:A 文章编号:2096-4706(2018)08-0012-03
Abstract:Through the research and implementation of character-based recursive neural networks of long and short memory,this essay explored its application in natural language models,and selected the novel Forest in Norway to train recurrent neural networks and generate the corresponding text. Summed up the shortcomings,discussed the problems and research directions that should be solved in the future. The research results show that the recurrent neural network can only learn the connection or change relations between word and words or words on the surface,and the natural language is not only the similarities and differences between the surface of the words,but also more changes in emotions or thoughts between lines. These are a group of sequence data far from being able to express,so in the future natural language models should pay more attention to the study of sentiment and thinking between words to build a model that is closer to natural language.
Keywords:long short term memory unit;recursive neural network;natural language processing;word embedding
0 引 言
自然語言是人类智慧的结晶,而自然语言处理(Nature Language Processing)是尝试通过计算机技术结合概率论与数理统计等数学方法,让计算机理解或生成自然语言的技术。近年来,自然语言处理技术随着时代的进步逐渐兴起,并迅速发展,让计算机正确有效地理解和处理人类自然语言,并进一步实现与人类的对话,已成为当今具有巨大挑战性的难题。
随着时代的变迁与技术的发展,在自然语言处理中,词汇的表征由最先的One-hot编码发展为如今的词嵌入编码,词嵌入将词汇嵌入到一个低纬而紧凑的向量空间中,大大加强了词汇间的联系;文本的处理由最先的N-Grams模型发展为如今的递归神经网络模型,递归神经网络通过神经元在时序上的连接,成功捕获了文本长短期的顺序依赖关系;而后由Jürgen Schmidhuber等人提出的长短记忆递归神经网络,即LSTM网络,通过在网络中引用一种叫做记忆单元的特殊结构,成功解决了递归神经网络中信息在传递过程中的梯度消失问题。随后研究者们将这些成果结合,并运用于各项领域,如语言翻译、语音识别、自然语言处理和时间序列分析等,均取得了良好的效果。本文将主要讨论LSTM网络在中文语言模型中的研究与实现。
1 递归神经网络
递归神经网络(RNN,Recursive Neural Network)是一种专门解决序列问题的人工神经网络。它通过将神经运算单元在时序上堆叠,同时记忆历史信息,向后传播并预测,通过反向传播算法,让神经网络逼近时序数据在前后逻辑上的映射关系。
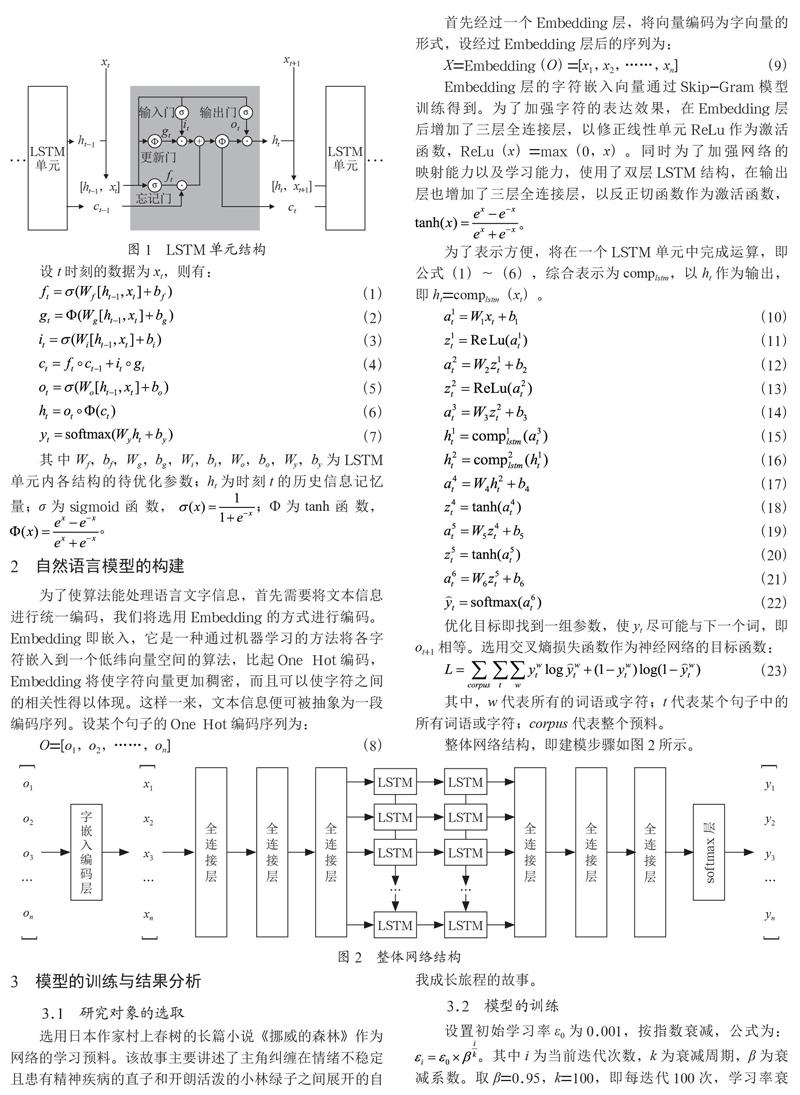
本文以LSTM单元,即长短记忆单元,作为基本递归神经运算单元。LSTM单元包括输入门、忘记门、更新门和输出门,它们将共同决定历史信息的去留,以实现历史信息的长期记忆,它的网络结构如图1所示。
设t时刻的数据为xt,则有:
2 自然语言模型的构建
为了使算法能处理语言文字信息,首先需要将文本信息进行统一编码,我们将选用Embedding的方式进行编码。Embedding即嵌入,它是一种通过机器学习的方法将各字符嵌入到一个低纬向量空间的算法,比起One Hot编码,Embedding将使字符向量更加稠密,而且可以使字符之间的相关性得以体现。这样一来,文本信息便可被抽象为一段编码序列。设某个句子的One Hot编码序列为:
首先经过一个Embedding层,将向量编码为字向量的形式,设经过Embedding层后的序列为:
Embedding层的字符嵌入向量通过Skip-Gram模型训练得到。为了加强字符的表达效果,在Embedding层后增加了三层全连接层,以修正线性单元ReLu作为激活函数,ReLu(x)=max(0,x)。同时为了加强网络的映射能力以及学习能力,使用了双层LSTM结构,在输出层也增加了三层全连接层,以反正切函数作为激活函数,。
为了表示方便,将在一个LSTM单元中完成运算,即公式(1)~(6),综合表示为complstm,以ht作为输出,即ht=complstm(xt)。
优化目标即找到一组参数,使yt尽可能与下一个词,即ot+1相等。选用交叉熵损失函数作为神经网络的目标函数:
其中,w代表所有的词语或字符;t代表某个句子中的所有词语或字符;corpus代表整个预料。
整体网络结构,即建模步骤如图2所示。
3 模型的训练与结果分析
3.1 研究对象的选取
选用日本作家村上春树的长篇小说《挪威的森林》作为网络的学习预料。该故事主要讲述了主角纠缠在情绪不稳定且患有精神疾病的直子和开朗活泼的小林绿子之间展开的自我成长旅程的故事。
3.2 模型的训练
设置初始学习率ε0为0.001,按指数衰减,公式为:。其中i为当前迭代次数,k为衰减周期,β为衰减系数。取β=0.95,k=100,即每迭代100次,学习率衰减为先前的0.95倍。总共经过10000次训练,每次迭代送入语料中256句长度为64个字符的句子进行训练,训练过程中的交叉熵损失曲线变化如图3所示。
3.3 模型结果分析
利用训练好的模型,随机生成一段约500字的文本,如下:
我此:『我說话,他也是不能见解了。我说:『你有什么都不认为怎么样?”
“是呀!你知道。”阿绿说。“你的脑上就不喜欢莫本的人。真的!”直子说。“着不是我不喜欢的。”
“是呀!我不知道!”我说。
“不过!我不能说:”
我们走着停进,像着一种东西袋喝酒。
“你是吧?渡边,我的脑袋就有这种地方呀!”直子问道。“因为你们都是个年间了。我现在做,你会常常在你的人,你也很想一起子的。”我说。
“我也不会这么做?”我说。
阿绿从床袋中探下听里,又重起阿绿似。“我不知道的。”我笑看同声音。
“我会常打开始的事。”阿绿说。
“你不会见你家看了。你们不能去跟他吗?”玲子说。
“是呀!你不知道吗?渡边,你们也不会再做,还是有自己一样。”阿绿说。
“是呀!你知道自己的意思。我们也不能这么去呀!我们的话一次不能?”
“你可以说的。虽然我这些爱了,不知道,这里到东西就会去吃饭了。”阿绿说。“不过你,她们就能去你。”
“可能,她们就能不会见,我是我不喜欢地做,还是你一样的话不行?我不要常去。”我说。“不过,你会常把这种事,而且真是我一直子做的。”
“我们去的?”初而看着我。然后我们就像想了起来了。我一直在他一个人把新宿啡的收费吃了一次。我们穿着我旁边。在我自己不知道的,我也觉得自己的话。如果顺利也许这么单。一切一个人,我只要告决硬子的事的。我想我的。”他说。“不是?”
从中可以看到,在语法上已经学会了要用引号将说的话引起来,然后或前或后会有个说话人;同时在某些语气词后学会了使用标点,比如“呀”后面接感叹号,“吗”后面接问号等,但在语义上还存在很多问题,句子表述以及上下文联系有些含糊不清。
4 结 论
递归神经网络在序列数据的学习上确实有很大的优势,能从序列数据中找到序列之间的变化规律与趋势。对于自然语言来说,它不仅仅是简单的序列数据变化,而是夹杂了机器所不能理解的情感和思维等。
将文本数据序列化,从本质上是一个降维的过程,是将一段夹杂着复杂情感和思维逻辑的内容降维成一段低维的序列数据,然后送入神经网络学习,而数据的降维必定是一个信息丢失的过程,只是丢失的程度不同,甚至有些数据在降维后必定会丢失大量信息,自然语言就是其中的一种,这是因为它太过复杂。换句话说,神经网络能学到的也就只是这段被大大压缩过的文本信息,即它永远无法理解语言本身的内涵。
综上所述,自然语言处理不能仅仅从字符之间或是词语之间来考虑它们表面的关系,更应从词语或是字符的内在出发,尝试量化这些字符或是词语在情感上的变化,以及一些思维逻辑上的因果关系,构建深层次、多结构的神经网络进行训练,从而得到更好的自然语言模型。
参考文献:
[1] 彭程.基于递归神经网络的中文自然语言处理技术研究 [D].南京:东南大学,2014.
[2] 李长亮.基于神经网络的自然语言处理研究 [D].北京:中国科学院大学,2015.
[3] 梁天新,杨小平,王良,等.记忆神经网络的研究与发展 [J].软件学报,2017,28(11):2905-2924.
[4] 张晓.基于LSTM神经网络的中文语义解析技术研究 [D].南京:东南大学,2017.
[5] 吴禀雅,魏苗.从深度学习回顾自然语言处理词嵌入方法 [J].电脑知识与技术,2016,12(36):184-185.
[6] Liu P,Qiu X,Huang X. Learning context-sensitive word embeddings with neural tensor skip-gram model [C]//International Conference on Artificial Intelligence. AAAI Press,2015:1284-1290.
[7] 张钹,张铃.人工神经网络的设计方法 [J].清华大学学报(自然科学版),1998(S1):4-7.
作者简介:伍逸凡(1996.11-),男,汉族,湖南人,本科。研究方向:深度学习;石俊萍(1974.10-),女,苗族,湖南花垣人,副教授,硕士研究生。研究方向:大数据分析与处理。
猜你喜欢
计算技术与自动化(2017年3期)2017-10-26
魅力中国(2017年24期)2017-09-15
中国市场(2016年39期)2017-05-26
电子技术与软件工程(2016年24期)2017-02-23
计算机应用(2016年12期)2017-01-13
电脑知识与技术(2016年10期)2016-06-16
求知导刊(2016年10期)2016-05-01
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年5期)2016-02-22
