
图像三维重建中的特征点提取
2018-10-20 09:31李宇鹏
数码设计 2018年9期
关键词:卷积神经网络
李宇鹏


摘要: 三维重建技术是将从普通相机获得的二维图像生成一个三维虚拟场景的过程。在这个过程中需要对图像进行特征点的提取和匹配,得到三维场景中的点,获稀疏的点云,为此需要对点云进行稠密化以获得更多的点,接着对获得的稠密点云进行网格化处理得到三维模型,然后把二维图像的纹理信息与三维模型进行对应贴图,最终获得逼真的三维纹理模型。既然输入图片为二维图像,所以特征点提取主要针对二维图像。对图像特征点的提取是基础,也是最重要的一部分,只有能够得到正确的特征点,才能在接下来的一系列计算中保持准确度。现在做图像处理的时候,人们普遍使用的是卷积神经网络(CNN),卷积神经网络是局部连接网络,其最大的特点就是局部连接性。即对一副图像中的某个像素p来说,一般离像素p越近的像素对其影响也就越大。因此卷积神经网络在图像领域获得巨大的成功的核心点在于可以捕捉局部相关性。而且采用CNN进行图像特征提取比起其他传统方法,具有实时快速的优点。所以在二维图像特征点提取方面,本文主要介绍使用CNN方法。
关键词: 图像三维重建;卷积神经网络;多层神经网络;池化
中图分类号: TP391.41 文献标识码: A 文章编号: 1672-9129(2018)09-0098-02
Abstract: The technology of 3D reconstruction is the process of generating a 3D virtual scene from 2D images obtained from ordinary cameras. In this process, it is necessary to extract and match the feature points of the image, get the points in the 3D scene and obtain sparse point clouds, so we need to dense the point clouds to obtain more points. Then the dense point cloud is meshed to obtain the 3D model, and then the texture information of the two-dimensional image is mapped to the 3D model, and a realistic 3D texture model is obtained. Since the input image is a two-dimensional image, feature point extraction is mainly for two-dimensional image. Extraction of Image feature points is the basis It is also the most important part that can maintain accuracy in the next series of calculations only if the correct feature points are obtained. When image processing is done now, it is widely used that convolution neural network (CNN), convolutional neural network is a local connection network, and its biggest characteristic is local connectivity. That is, for a pixel p in an image, the closer the pixel p to the pixel p, the greater the impact on the pixel p. Therefore, the key to the great success of convolution neural networks in image field lies in the ability to capture local correlation. In addition, compared with other traditional methods, CNN is used for image feature extraction. The advantage of real-time and fast. So in two-dimensional image feature point extraction, this paper mainly introduces the use of CNN method.
Keywords: image 3D reconstruction;convolution neural network;multilayer neural network;pooling.
隨着计算机技术的不断进步,人们对计算机技术能力的要求也在不断地增加,人们希望计算机技术不仅仅能做一些简单的工作,更希望计算机技术能够替代人去完成他们想做的一些危险的、复杂的事情。本文中所研究的技术正是要实现人们所想要计算机能达到的效果之一。计算机技术中的计算机视觉是一种类似于人眼睛功能的一项技术,它的目的就是实现把二维图像转换为虚拟的三维场景的过程。虽然当前计算机视觉技术还不能做到像人的眼睛一样的效果,但是在这几十年的发展中也形成了很多的成熟的技术来完成一些简单的类似眼睛的功能。
与以往的方法相比,利用扫描设备例如深度扫描仪和三维相机虽然能够获得准确的三维模型,但是不能广泛的应用在一个非局限的空间中,它只能应用在一些局部范围内,比如可以扫描一个小的物件像小型的古物、杯子等。同时使用扫描仪的成本也是非常高的。而使用基于图像的三维重建技术可以很好处理这些问题。在与传统的基于几何构造三维重建(实体造型、细分曲面、隐式曲面等)相比,三维重建技术不仅使用方式简单,而且减少人力、物力、财力。尤其对于大型的复杂的室外场景,使用基于图像的三维重建技术相比其他方法有很大的优势。
正如我们所知,三维重建技术在我们的生活中的需求在不断地增加,例如在机器人导航,医疗影像,虚拟展示,人脸识别等领域,三维重建技术不仅在日常生活中有着重要的应用,在工业仿真和军事模拟中也是起着重要的作用。
三维重建技术最早在国外出现,在上世纪六十年代,麻省理工学院首次进行了从二维图像到三维立体的研究,这标志着三维重建的开始。在1992年卡内基梅隆大学内完成了第一个基于图像的三维重建系统。近年来关于三维重建的发展和研究也不断的进步,Ramalingam和Antunes等人在2015年提出的一种特征点获取的方法,使用交比这一数学方法来得到特征点。在2016年由Silvano Galliani和Konrad Schindler提出了使用卷积神经网络CNN来形成三维表面点的法向量,这是一种使用卷积神经网络和传统方法相结合的新技术。
在国内虽然在这方面起步比较晚,清华大学、中科院、哈尔滨工业大学、浙江大学等都有杰出的代表。清华大学的王磊提出了基于平面投影和遗传的算法,该算法可以在非定标的情况下进行,得到很好的特征点的提取。
1 神经网络
1.1神经元。科学家们希望能模拟人类大脑的思考方式,制造与人类大脑作用相同的机器。所以科学家就在大脑思考方式的启发下,模拟神经元,组成神经网络,进而模拟人类思考。1904年生物学家就已经知晓了人体大脑中神经元的组成结构。一个神经元通常具有多个树突,主要用来接受传入信息;而轴突只有一条,轴突尾端有许多轴突末梢可以给其他多个神经元传递信息。轴突末梢跟其他神经元的树突产生连接,从而传递信号。这个连接的位置在生物学上叫做“突触”。1943年,心理学家McCulloch和数学家Pitts参考了生物神经元的结构,发表了抽象的神经元模型今天仍然在使用。
图1所示的神经元模型是一个包含输入,输出与计算功能的模型。输入(x1,x2,x3)可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算则可以类比为细胞核。在设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定。神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别。
结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。
1.2单层感知器。关于单层的感知器,输入层里的“输入单元”只负责传输数据,不做计算;输出层里的“输出单元”则需要对前面一层的输入进行计算。一个神经元的输出可以向多个神经元传递,所以输出可以不止一个。
图2的公式是一个矩阵乘法,其中a为输入向量(a1,a2,a3)转置的列向量,w是一个两行三列的权重值组成的矩阵,用wx,y来表达一个权值。下标中的x代表后一层神经元的序号,而y代表前一层神经元的序号。所以简写为z=g(a*w),这个公式是神经网络中从前一层计算后一层的矩阵运算。感知器只能做简单的线性分类任务。
1.3多层神经网络。
图3为由多个神经元组成的多层网络。第一层感知器接收外部输入,做出判断后发出信号,信号作为上层感知器的输入,直至得到最后的结果。将这张图中第一层inputs叫输入层,最后一层output叫输出层,中间为隐藏层。而这种结构,显然还是符合矩阵乘法。单层(只有输入层和输出层)的感知器其实只能进行线性的分类,而加入隐藏层后,可以进行一些空间变换从而达到可以无限逼近任意连续函数的效果。
需要说明的是,在多层神经网络中,使用S型函数sigmoid作为函数g,把函数g也称作阈值函数。而事实上,所谓的神经网络的本质就是通过参数与激活函数(激活函数就是我们的输入)来拟合特征与目标之间的真实函数关系。这张图里,上层感知器的输出总是下层感知器的输入。现实中,还有可能发生循环传递,本文重点在卷积,所以不详细叙述。
1.4训练(学习)。一个神经网络的搭建,需要满足三个条件:
(1)输入和输出
(2)权重(w)和偏置(b)
(3)多层神经网络的结构
也就是说,需要事先画出类似于图3的图形,其中如何确定有几个隐藏层是很重要的。每层神经元的个数需要设计者自己设定,目前在这方面还未出现一个明确的算法。然后就是确定每个权重(w)和偏置(b),进行训练。可以拿一些已知结果的数据输入神经网络,求得输出,这是正想传播,然后再根据已知的输出结果反向,求得每层的w和b,并进行修改,这是反向传播。上述操作即为深度学习的过程。
正因为神经网络需要不断尝试,所以对于运算速度的要求很高,这也是为什么神经網络在近几年才发展的原因之一。
2 卷积神经网络
2.1概况。卷据神经网络简单的来说一般包含这几个层次:1、输入层:用于数据的输入(图像处理中就是图像的输入);2、卷积层:使用卷积核来进行特征提取和特征映射;3、池化层:对特征图进行稀疏处理,减少数据运算量;3、全连接层:减少特征点的损失;4、输出层:用于结果的输出。
2.2卷积。19世纪60年代,科学家通过对猫的视觉皮层细胞研究发现,每一个视觉神经元只会处理一小块区域的视觉图像,即感受野(Receptive Field)。用卷积和池化操作可以相当程度的减小运算量,这个在下面会讲到。我们还是举一个例子来了解一下这里的卷积的具体含义。
输入一个RGB(red,green,blue三种颜色来表示此图),所以这个图片是一个7*7*3的图片(就是图中最左侧的Input Volume)(其实原图是一个5*5*3的,但加入了一个由0组成的边框)。现在有两个3*3*3过滤器(Filter)(也叫卷积核),以及对应的偏置(Bias)。然后将过滤器放在图片的左上角,把过滤器上的每个点与在图中对应位置上的每一个点的值相乘并求和,得到卷积后的结果作为输出(Output Volume)中的下角标。而这个式子就可以写成output[0,0,0]=∑(x[i,j,k]*w0[i0,j0,k0]+b0)(0≤i,j,k≤2)。其中i0==i,j0==j,k0==k,但随着卷积核移动,将出现不相等的情况。得到这个结果后,过滤器按照步长依次从左往右,从上往下滑动,每滑动一次,就会生成一个输出值。当一个过滤器扫描结束后,换下一个过滤器继续扫描,所以最终会有两个3*3*3的output volume,这个output也叫特征图(feature map)。如上,有几个filters就会有几个feature map。Feature map的尺寸=[(输入图片的尺寸-过滤器的尺寸+2*padding尺寸)/步长]+1=[(6-3+2*1)/2]+1=3。
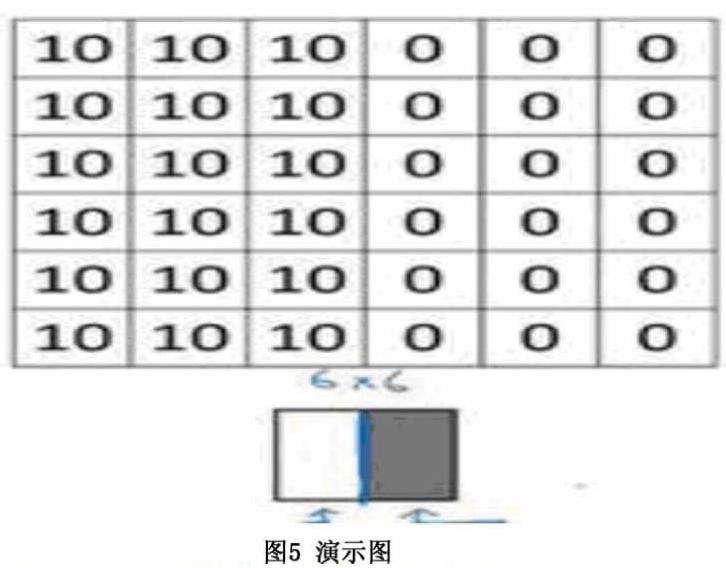
为了理解清楚,举一个简单的小例子,这是一个简单的6×6图像,左边的一半是10,右边一般是0。如果你把它当成一个图片,左边那部分看起来是白色的,像素值10是比较亮的像素值,右边像素值比较暗,我使用灰色来表示0,尽管它也可以被画成黑的。图片里,有一个特别明显的垂直边缘在图像中间,这条垂直线是从黑到白的过渡线,或者从白色到深色。
当用一个3×3过滤器进行卷积运算的时候,这个3×3的过滤器可视化为下面这个样子,在左边有明亮的像素,然后有一个过渡,0在中间,然后右边是深色的。卷积运算后,就得到的是右边的矩阵。
如果把最右边的矩阵当成图像,它是这个样子。在中间有段亮一点的区域,对应检查到这个6×6图像中间的垂直边缘。这里的维数似乎有点不正确,检测到的边缘太粗了。因为在这个例子中,图片太小了。如果用一个1000×1000的图像,而不是6×6的图片,会发现其会很好地检测出图像中的垂直边缘。
不难看出,这与和前面所述的神经网络中的运算过程很相似,只是卷积核在扫描中一直没有变,每次操作对应的w和b的数量相当小,所以相较于神经网络中全连接的处理方式可以大大降低操作的时间。而这样做的原理就是图片有很强的空间相关性,但其实这毫无疑问是个牺牲正确率换取效率的方法,但能用1%的正确率换取1000倍的效率。
在之前的小例子中看到,如果用一个3×3的过滤器卷积一个6×6的图像,最后会得到一个4×4的输出,也就是4×4矩阵。那是因为3×3过滤器在6×6矩阵中,只可能有4×4种可能的位置。这背后的数学解释是,如果我们有一个n×n的图像,用f×f的过滤器做卷积,那么输出的维度就是(n-f+1)×(n-f+1)。在这个例子里是6-3+1=4,因此得到了一个4×4的输出。这样的话会有两个缺点,第一个缺点是每次做卷积操作,你的图像就会缩小,从6×6缩小到4×4,你可能做了几次之后,图像就会变得很小了,可能会缩小到只有1×1的大小。人们可不想让图像在每次识别边缘或其他特征时都缩小,这就是第一个缺点。第二个缺点是,如果注意角落边缘的像素,这些像素点只被一个输出所触碰或者使用,因为它位于这个3×3的区域的一角。但如果是在中间的像素点,就会有许多3×3的区域与之重叠。所以那些在角落或者边缘区域的像素点在输出中采用较少,意味着丢掉了图像边缘位置的许多信息。
为了解决这些问题,可以在卷积操作之前填充这幅图像,就是所谓的Padding。在这个案例中,可以沿着图像边缘再填充一层像素。如果这样操作了,那么6×6的图像就被填充成了一个 8×8的图像。如果用3×3的图像对这个8×8的图像卷积,得到的输出就不是4×4的,而是6×6的图像,就得到了一个尺寸和原始图像6×6的图像。习惯上,用0去填充。
2.3池化。
池化(pooling)操作有以下几种:
1.Max Pooling:在feature map中取每一个kernel 所对应区域的最大值
2.Mean Pooling:在feature map中取每一个kernel 所对应区域的平均值
3.Stachastic-pooling:先生成与feature map一样尺寸的概率矩阵,再根据概率矩阵随机在feature map中取每一个kernel所对应区域的随机值
需要说明的是,当Kernel width=stride是传统的不重叠池,而当Stride 2.4对比。为了显示卷积的好处,下面来进行一下全连接与卷积的对比: 在全连接层中,前一层的所有神经元都和后一层的所有神经元相互连接,如果前一层有32*32*3个神经元,后一层有5*15*15个神经元,则一共需要32*32*3*5*15*15=3456000个参数来刻画它们之间的关系。 而在卷积层中,前一层中filter区域内的神经元和后一层对应位置的神经元才会连接。例如,输入图片是32*32*3,使用5个3*3*3的filter,步长为2,生成5个15*15的feature map。这个过程一共需要的参数有:5*3*3*3=135个。 现在来做一个除法3456000/135=25600。两者相差25600倍,而这只是图片很小的情况,所以即使卷积会使我们损失一定的正确率,也是可以接受的,更何况这些正确率可以通过我们对策略进行调整来弥补。在卷积神经网络中也存在全连接层,只是会应用到卷积与池化而已。 3 结语 处理图像三维重建中的特征点提取工作时,卷积神经网络的应用需要结合具体的算法,但特征点提取基本大部分都是由输入层、卷积层、池化层完成的。卷积神经网絡广泛应用于图像处理的各种方面,不只限于在三维重建。人脸识别系统,汽车自动驾驶技术等都涉及到了卷积神经网络,卷积神经网络的应用还有广大的发展空间。 参考文献: [1]陈树,王磊.一种改进的基于RANSAC方法的SIFT特征匹配[J].信息技术,2016(12):39-43. [2]张学贺. 基于双目视觉的六足机器人环境地图构建及运动规划研究[D].哈尔滨工业大学,2016. [3]戴嘉境. 基于多幅图像的三维重建理论及算法研究[D].上海交通大学,2012. [4](英)Mark S. Nixon, Alberto S. Aguado著,杨高坡,李实英译.计算机视觉特征提取与图像处理(第三版)[M].电子工业出版社,2014.
猜你喜欢
电子技术与软件工程(2017年3期)2017-03-22
电脑知识与技术(2016年33期)2017-03-21
科技创新与应用(2017年5期)2017-03-16
电脑知识与技术(2016年30期)2017-03-06
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
软件(2016年5期)2016-08-30
电脑知识与技术(2016年10期)2016-06-16
