
基于稀疏表示和深度学习的图像识别算法研究
2018-10-20 02:16吕焦盛
新乡学院学报 2018年9期
吕焦盛
(郑州工业应用技术学院 信息工程学院,河南 郑州451100)
随着高清设备的普及,人们采集到的图像信息越来越多地呈现出多样性、高维性和复杂性的特点,但原始数据也可能遭受光照、污损、旋转等干扰[1],传统的图像识别算法已经很难满足实际需要。深度学习,即通过学习人脑的组织机构机理,对组合底层特征进行更抽象、更有效的高层表示,可解决底层像素特征不稳定易受环境影响的问题[2]。融合稀疏表示和字典学习,利用提取到的高层特征进行多尺度字典训练,即可实现图像的精确识别。具体流程如图1所示。

图1 图像分类流程
1 稀疏表示
传统的图像表示方法[如主成分分析法(PCA)、小波变换法(WT)、傅里叶变换法、支持向量机法(SVM)等[3]]往往只提取部分有用特征而忽略了大多数特征,破坏了数据的关联性。
稀疏表示是为了提高特征的提取率,将样本数据通过过完备字典进行线性组合,进而得到原始数据的稀疏表示形式[4]。稀疏表示的数学表示为:假设图像数据可以用数据y∈RN表示,其中N为数据长度,即RN中标准正交基个数,线性组合得到的图像数据为

其中:A∈RN×N为图像数据构成的基矩阵,x=[x1,x2,x3,…,xn]为线性组合向量。如果在x中有k个非零项,且非零项的个数k远小于数据长度N,那么我们称在基A上的数据y是稀疏的,且非零项的个数k越小,数据的稀疏程度越大,信号称为k_稀疏信号。这里,向量中非零项的个数用范数

来计算。
1.1 基于稀疏表示的分类算法
传统的特征提取方法需要对图像特征进行一系列变换,如统计、平移和滤波等,来得到合适的图像数据,而这往往依赖设计者的经验,具有很大的不确定性[5]。这些方法,如线性判别分析(LDA)、核主成分分析(KPCA)和主成分分析(PCA)等都是从图像的视觉特性出发[6],利用图像的几何特征、灰度统计特征、变换域特征和局部不变特征等方面进行特征提取。
基于稀疏表示的图像分类的过程是:在训练集中抽取图像数据y作为测试样本,计算由测试样本y在基矩阵A上构成的稀疏字典基与稀疏系数x0的映射,再通过对x0中的系数进行分析,得到测试样本y的最终图像分类。基于稀疏表示的特征提取方法如图2所示。
稀疏表示分类算法流程如下:
2)对A的列元素进行归一化处理。
3)由于A为欠定矩阵,故将求解l1范数的最小化问题转化为凸优化问题,从而得到欠定矩阵的稀疏解。如果数据中存在噪声,则稀疏解x1=arg min||x||1满足Ax=y并同时服从||Ax-y||2≤ε 。
4)计算测试样本数据与样本间的残差ri(y)=||y-Aδi(x1)||2(i=1,2,…,n),δi为特征函数。
5)输出测试样本类别定义为 arg min ri(y)。
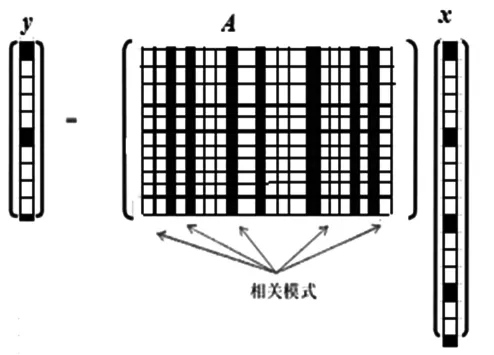
图2 稀疏表示特征提取示意图
1.2 多尺度稀疏表示图像识别
稀疏表示可以在不丢失图像重要信息的同时得到更为简洁的表示方式[7]。但是图像信息往往会受到噪声影响,因此需要对图像进行预处理,得到去噪后的图像[8]。另外,稀疏表示需要大量的训练样本,如图像数据偏少就会导致稀疏表示的丰富性和多样性受损[9]。
多尺度稀疏表示是指在特征层对数据进行单次稀疏表示,以降低噪声对稀疏求解过程的影响,使后期图像识别更加准确。同时,训练样本的种类对稀疏表示非常重要,训练集中样本的多样性构成了字典的多样性[10]。因此,笔者在字典学习阶段引入多尺度概念,对样本进行多尺度变换来丰富样本的多样性。算法具体步骤如下:
1)从训练样本集中提取图像的多尺度特征,此时提取的特征数据中会存在大量的冗余数据。
2)对特征数据进行随机抽样,得到特征数据的多尺度训练子集。
3)将得到的多尺度训练子集作为输入,构建全局多尺度字典。
4)在训练集中对原始特征数据进行多尺度稀疏表示,作为分类器的训练样本。在测试集中,通过构建的全局多尺度字典对稀疏表示进行求解,作为分类器的输入数据。
2 深度学习
深度学习就是通过模拟人脑的多层抽象学习过程,在减少人工干预的前提下实现对数据的抽象表达。机器学习经历了由浅层到深层的过程,浅层学习需要外力驱动,是一种机械式的研究方法,被动接收而不对相关信息进行关联记忆。浅层学习形式主要有最大熵(LR)、支撑向量机(SVM)等浅层监督或半监督学习模型[11]。由于浅层学习具有局限性,面对多个变量和海量数据时,很多问题无法通过单层感知器解决[12],故产生了深度学习。深度学习的模型结构相比于浅层结构对数据有更强的表达能力。深度学习通过多层非线性单元构建深度学习网络,利用低一层网络的输出数据作为高一层网络的输入数据,从大量数据中逐层筛选出有效的高阶特征数据,利用含有大量信息的高阶特征数据进行图像的识别、分类和检索[13]。
2.1 基于深度学习的稀疏编码
稀疏编码在图像的稀疏特征表示中主要是重构一个含有大量信息的输入向量,输入向量的数据来源于通过样本函数构建的字典向量。对一系列原始数据基向量进行线性叠加后得到的单个图像块表示为

其中,B表示m×n的基向量矩阵,c表示m维的稀疏向量, ε 为对样本集进行采样时得到的n维噪声向量。当基向量的m<n时,字典是欠定的;反之则是超完备的。对图像块进行稀疏编码有:

2.2 基于深度自编码网络的图像识别
深度学习通过训练大量的模拟样本来防止数据模型出现“过拟合”,而在大多数情况下,训练样本数量较少,所得到图像的识别效果欠佳[14]。为此,本算法在传统的局部特征提取的基础上,利用含有大量数据信息的高位特征进行深度自编码学习,以提升后期的图像识别效果。算法具体步骤如下:
1)在训练图像集中提取图像的尺度不变特征(SIFT),得到训练图像的特征数据库 R={r1,r2,…,rN},其中N为总的特征点,r为SIFT特征。
2)对得到的训练图像的特征数据库进行无监督受限玻尔兹曼机(RBM)编码,并不断迭代,生成过完备字典集。
3)对生成的过完备字典集进行误差反向验证,并对受限玻尔兹曼机(RBM)编码进行有监督的误差调整,再对优化后的特征库进行编码,得到稀疏表示系数和新的字典W。
4)要得到每个图像块的稀疏特征,就通过梯度优化算法对字典W进行优化;要得到图像块的深度学习编码向量表示,就对稀疏特征进行最大值融合。
5)通过训练图像集的深度自编码向量表示训练分类器,得到图像的识别效果。分类器选取传统的支持向量机分类器(SVM)。
基于深度自编码图像识别的流程如图3所示。

图3 深度自编码图像识别流程图
3 实验与仿真
首先,构建深层自编码网络。实验中取网络层数为5并归一化目标图像,使其大小为128×128。然后,提取图像SIFT特征,提取到的图像特征维数为128。接着,对深层网络进行无监督迭代训练,迭代次数越多效果越好,但计算量也越大。(本文中取迭代次数200次。)最后对目标函数进行均方差优化。网络层中第一层到第五层的神经元节点数分别为 128、500、500、500和100,误差调整采用迭代次数为50的随机梯度算法。
深层网络进行无监督迭代训练后,得到含有表示属性类别和信息的高层特征,通过对分类器的线性训练,得到图像的最终识别效果,并以识别的准确率作为判断算法有效性的重要指标。文中分别以LFW(labeled face in the wild)和耶鲁人脸数据库(the Yale face datebase)为对象,验证不同算法的图像识别效果。具体识别效果如表1所示。
从表1可以看出,在不考虑噪声对图像影响的情况下,PCA对LFW和Yale Face的平均识别率为96.74%,传统SVM算法的平均识别率为96.76%,而本文算法的平均识别率为97.02%,具有更高的识别率和鲁棒性。同时,基于深度自编码网络的特征提取方法易于实现,训练方法简单,计算复杂度低,具有良好的发展前景。
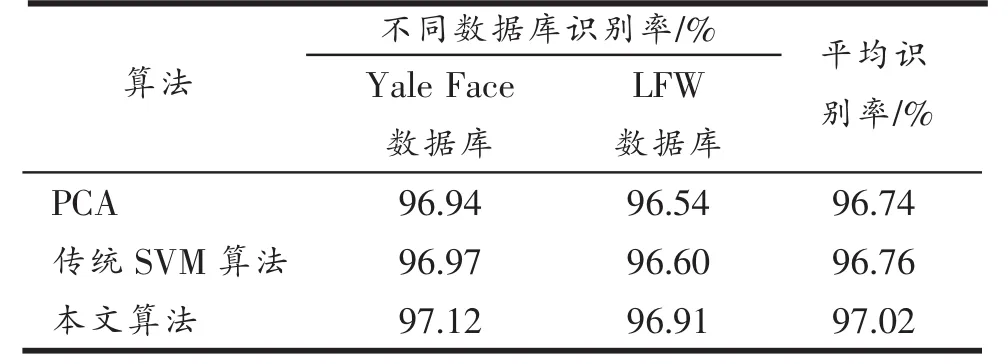
表1 不同算法图像识别率
4 总结与展望
我们首先简要介绍了传统的特征提取算法,如主成分分析法(PCA)和稀疏表示法等;其次,为了丰富样本的多样性,提出了在稀疏表示基础上对样本进行多尺度融合;最后利用深度学习的高阶特征数据得到图像的最终识别效果。新算法在字典集的训练时间、过度拟合和图像分类几个方面进行了优化,并取得了良好的效果。但深度学习网络尚没有形成完善的系统理论框架,同浅层学习相比算法的理论水平有待进一步提高。
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
电子制作(2019年16期)2019-09-27
中国交通信息化(2019年4期)2019-07-13
小学阅读指南·低年级版(2019年11期)2019-07-01
疯狂英语·新读写(2018年3期)2018-11-29
电子制作(2018年19期)2018-11-14
电子制作(2018年14期)2018-08-21
小天使·一年级语数英综合(2017年11期)2017-12-05
