
基于水文-水力学耦合的辽河中游河道洪水预报及不确定性分析
2018-10-19 09:19董湃
水利技术监督 2018年5期
董 湃
(辽宁省水利水电科学研究院有限责任公司,辽宁 沈阳 110003)
1 研究区域概况
辽河流域位于我国东北地区的南部,河道主干流长约为472km,流域面积为13820km2。流域中游区间内地势结构由南至北逐渐降低,河道交错复杂,降雨量在时空上分布极不均匀,尤其是汛期暴雨频繁,较大洪水发生频率为7~8年一次,一般洪水发生频次为2~3年,该区段是辽河流域洪水灾害预防的重要区间。流域上、下游水位及干支流状况对辽河河道的影响显著,河道内水位流量变化关系复杂,据此对洪水演算采用传统的水文学法已无法满足相关要求,而水力学法利用圣维南方程组可对任意时刻任意河道内的水位、流速和流量等因素进行计算分析[1]。为提高计算效率对模型结构进行简化,该研究结合研究区域水文站点及河网水系分布特征,对研究区域状况进行了概化。其中干流河道的控制断面分别选取辽源站、二龙山水库、福德店三处;浑河、太子河、大辽河为主要支流,分别选取铁岭站、辽阳站和营口站三处水文站为三条支流的控制水文站;对其他较小支流和沿河河道均概化为区间流域[2]。结合模型简化处理,文章在构建了水文-水力学耦合模型的基础之上,对模型参数采用SCE-UA法进行优化,然后采用HUP法对耦合模型预报结果不确定性进行定量的评估分析,从而建立了辽河中游河道洪水预报方案[3]。
2 辽河中游河道洪水预报方案
2.1 整体框架
河道上、下边界条件是进行水力学模型计算的基础,文章将模型的预报流量过程作为上边界条件,并采用水位-流量关系作为下边界条件,以此确保预报的可预见期。采用水力学模型对辽河干流与浑河、太子河和大辽河三条支流的下游进行河道洪水演算分析,而对福德店、二龙山水库上游及辽源站流域、昌图—开原—沈阳区间流域、台安—双台子区—盘山区间流域采用水文模型进行产汇流计算分析[4];利用营口站的水位-流量关系作为模型的下边界入流条件[5];采用SCE-UA法对水力学模型和水文模型的参数进行率定,辽河中游洪水预报方案结构如图1所示。
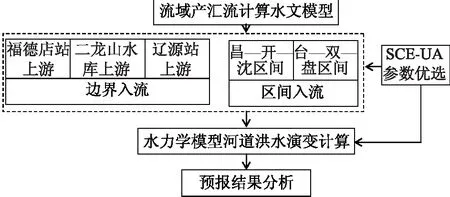
图1 辽河中游河道洪水预报方案逻辑结构图
2.2 水文模型
在我国半湿润和湿润地区新安江模型是进行洪水预报较为广泛的模型,该模型具有较高的精度和可靠性[6]。采取三层次方式对研究区域内三处主要水源进行新安江模型的蒸散发计算;结合河道蓄满理论和机理对河道产流进行计算,将总径流按照水库蓄水构造划分为地表、地下和壤中径流三种类型;将水库视为线性分布条件进行河道的汇流计算,并将汇流按照连续性演变规律进行马斯京根计算;耦合模型中其他参数所代表的含义较为具体,且易于理解和计算[7]。辽河流域多年平均降雨量为900mm,以长白山脉的千山山脉为界其南部为湿润区,北部为半湿润区,据此,文章采用三水源新安江模型作为辽河中游洪水预报的水文模型。
2.3 水力学模型
利用圣维南方程组进行河道洪水演算描述,方程组如下所示:
∂A/∂t+∂Q/∂x=q
(1)
(2)
式中,A、Q—分别为断面面积和流量;q—单位河长上的支流流量;x、t—分别为距离和时间;Z、C、R—分别为水位、泄洪系数和水力半径;α—动量校正系数。
圣维南方程组解析较为困难,通常采用数值法进行求解,而有限体积法和有限差分法是进行求解的主要方法。MIKE11模型是由丹麦DHI公司研发的一种利用有限差分法对圣维南方程组进行离散求解的一维水力学计算软件,该方法是采用追赶法对河道上、下游边界条件进行递推求解计算。Courant计算数的稳定性可利用离散格式的无稳定性基本特点进行保证,据此可采用较长时间的步长并提高计算效率。文章对河道洪水演算采用MIKE11模型进行模拟分析,河道干支流实测断面共32个,并结合研究需求采用线性插值法对部分变化较大的断面进行加密计算,最终得到非等距计算断面56个。根据河道上、下游边界条件对水位和流量初始值取固定值,设定计算步长为60s。
为提高模型预测精度,该研究将辽河干流与浑河、太子河和大辽河等支流同等对待[8]。通过计算网格结点对流域主干流之间和河道内部断面之间的节点进行连接,该节点也被成为流量节点和水位节点。利用平衡原理,可构建水量平衡方程,如下所示:
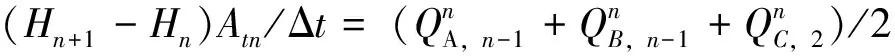
(3)
式中,H,Q—分别为节点水位和节点流量;At—节点水面面积;A,B,C—均为河道编号。
界定河网水系中共有N个结点,则可得到N个与上述方程相同的节点方程组。在河道边界水位和流量已知的条件下,采用高斯消元法可对各个节点的多元方程进行求解,最终得到河网体系中各节点的流量和水位计算结果。
2.4 SCE-UA参数优化法
SCE-UA是综合基因遗传算法中相关的优点,利用多边形法则进化寻优的计算方法,对于求解高维参数的全局寻优问题表现出较高的适用性和可靠性,可用于水文模型参数的优化计算问题。结合相关文献,该优化算法的若干参数应满足:m=2ns+1,q=ns+1,s=pm,β=2ns+1,α=1。m,ns分别为每个复合形顶点个数和模型优化参数的总个数;s,q分别为种群大小和每个子复合形个数。α,β分别为参数寻优子代个数和代数。SCE-UA优化法对洪水预报模型的目标函数如下所示:
(4)
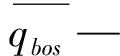
3 预报结果与分析
3.1 水文模型预报结果
在水文模型中的时间计算步长设定为2.5h,并选取2000—2015年期间资料较为完整的12场次的洪水数据资料,对水文模型的率定随机选取10场洪水资料,并以其他场次的洪水进行模型的验证[9]。对新安江模型采用SCE-UA法进行参数率定,则待优化的参数共16个,参数取值区间即为寻优计算的空间,参数取值可根据其所代表的物理含义或推荐范围进行确定。利用率定期洪水场次进行模型的率定,各洪水场次的模拟精度计算结果详见表1。
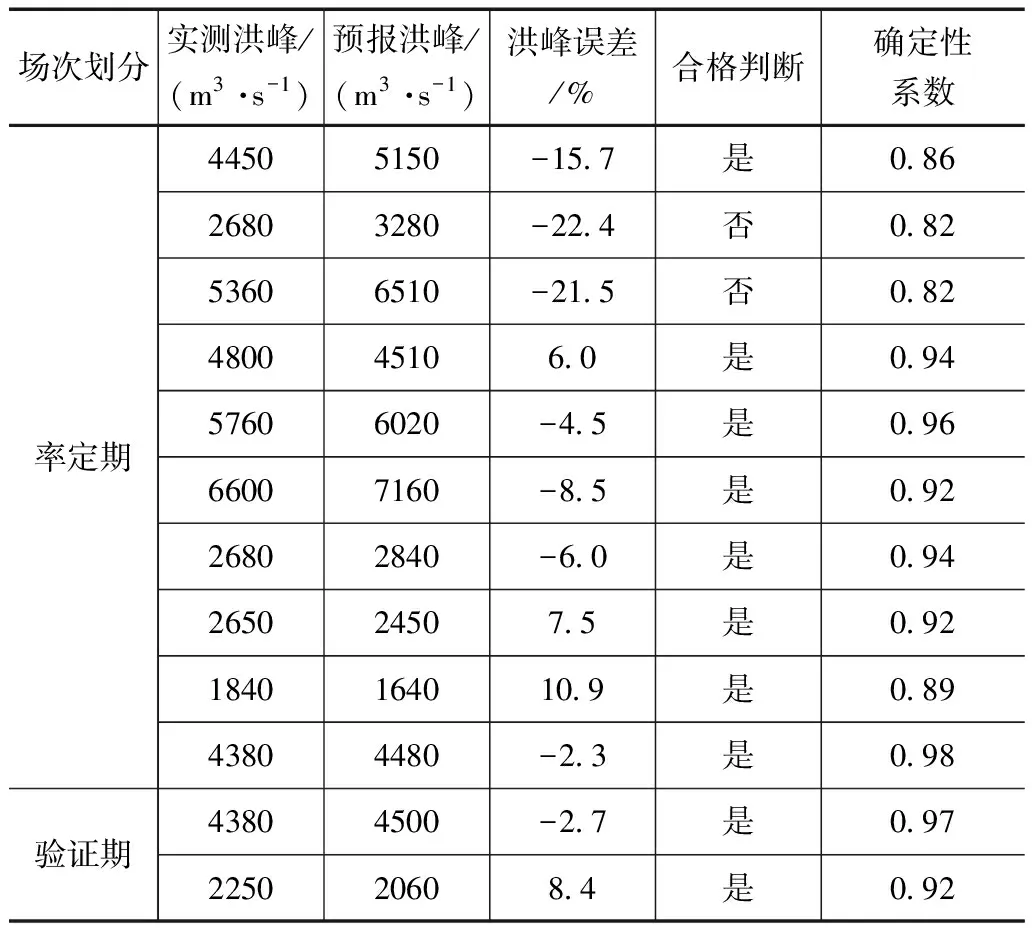
表1 新安江模型洪水场次在率定期的验证计算结果
由表1计算结果可知,在12场次的洪峰流量模拟中,仅有2场次相对误差大于20%,其余各场次误差结果均满足误差精度要求,模型对洪峰流量模拟的合格率达85%,并且各洪水场次的确定性系数均保持在80%以上;而用于模型验证的2个场次洪水模拟结果表明,误差值保持在10%以内。综上,所构建的新安江流域水文模型表现出较高的精确度和准确性,水力学模型的上边界入流条件可以采用该模型的预报结果为依据。
3.2 水力学模型预报结果
为了降低水力学模型优选参数糙率系数受水文模型预测结果误差的影响[10],该研究分别选取12场次中模拟精度较高的5个场次洪水进行MIKE11模型的参数率定。其中3场次用于模型的率定,其他2场次对模型进行验证。因研究区段内河道为复式河道,在汛期暴雨时洪水可越过槽漫滩,其过流量所占断面比重较大,据此对糙率系数的率定问题采用三区法进行处理,对糙率系数利用SCE-UA法进行优选,计算结果详见表2。
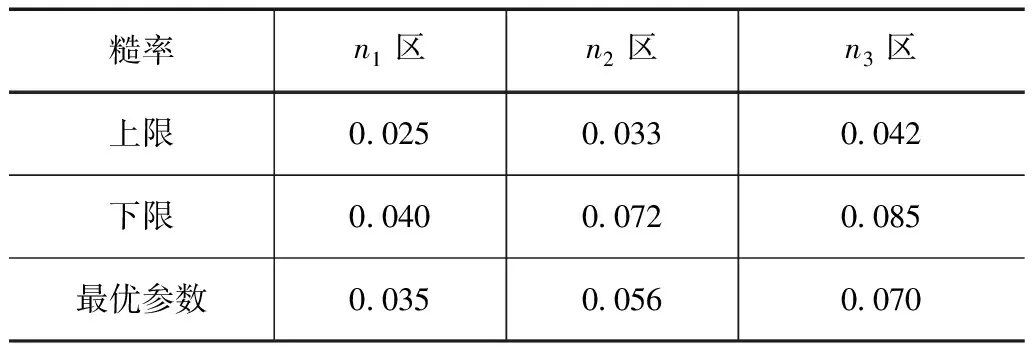
表2 河道糙率系数率定结果表
利用水力学模型对5场次铁岭水文站洪水集水断面的径流进行分析计算,计算结果详见表3。
由表3计算结果可知,5个场次洪水的相对误差值均在10%以内,且各场次的确定性系数均大于0.9,由此表明所构建的水力学模型具有较高的精度和可靠性。通过对控制断面实测值与预测值进行拟合,可知耦合模型预报结果与实测过程保持高度的一致性,二者的变化趋势吻合程度较高。
3.3 定量对预报结果的不确定性分析
模型参数、模型结构以及数据的输出在洪水预报过程中存在不确定性,进而引起模型对洪水预报结果的不确定性,据此对洪水预报结果的不确定性可利用水文不确定性处理器HUP进行定量评估分析。设定模型预报前的实测流量为H0,实测流量、确定性模型预报流量分别采用Hn,Sn(n=1,2,…,N)进行表征,其中N为模型的预见期长度。Hn,Sn的取值分别采用hn,sn进行表示,则模型预报起始时刻H0=h0。后概率密度函数φn利用贝叶斯公式,结合似然函数和先验密度函数进行估计,计算公式如下所示:
(5)
确定性预报结果sn是MIKE11和新安江模型结果的耦合,利用公式(5)可得到在hn、sn条件下的预报量hn的概率分布φn(hn|sn,h0),利用等方式置信区间可定量地对预报结果的不确定性进行评估。并且,通过取φn(hn|sn,h0)概率分布区间内的某特定的分位数对预报结果提供相似的确定性分析[11]。以铁岭水文站5场次洪水为例,利用文中所述计算公式和方法可分别获取90%预报区间及离散度,确定性系数、百分比等数据,计算结果详见表4。
由表4结算结果可知,预报区间为90%的离散度均小于0.3,而百分比在95%以上,研究表明,耦合模型预测结果的不确定性较低;相对于确定性预报结果,Q50%预报结果的洪峰流量预测结果序列其精确性和可靠性更高。
4 结论
文章在详细分析了MIKE11水力学模型和新安江水文模型的适用范围和优点的基础上,通过将二者进行耦合构建了水文-水力学耦合模型,然后对模型的参数利用SCE-UA法进行优化,并对预测结果的不确定性采用HUP法进行定量评估。得出如下结论。
(1)所构建的新安江流域水文模型表现出较高的精确度和准确性,水力学模型的上边界入流条件可以采用该模型的预报结果为依据。
(2)对模型预测结果的不确定性定量评估表明耦合模型对辽河中游的洪水预报结果的不确定性较低,可提供在一定置信度下某分位数预报值和预报区间,相关成果可为相似流域的洪水预报及防洪减灾措施的制定提供决策依据和理论支持。
猜你喜欢
土壤学报(2022年1期)2022-03-08
河北地质(2021年3期)2021-11-05
河南水利年鉴(2020年0期)2020-06-09
河南水利年鉴(2020年0期)2020-06-09
中国特种设备安全(2019年5期)2019-07-16
现代计算机(2019年16期)2019-07-15
河南水利年鉴(2017年0期)2017-05-19
科技视界(2016年27期)2017-03-14
科教导刊·电子版(2016年27期)2016-11-18
电影故事(2015年33期)2015-09-06
