
基于卷积神经网络的车牌识别技术
2018-10-18 11:47刘建国
物流技术 2018年10期
刘建国,代 芳,詹 涛
(1.武汉理工大学 现代汽车零部件技术湖北省重点实验室,湖北 武汉 430070;2.武汉理工大学 汽车零部件技术湖北省协同创新中心,湖北 武汉 430070)
1 引言
车牌自动识别是智能交通管理系统中的关键组成部分之一,在很多领域得到广泛应用,如交通监控,停车场管理等[1-2],国内外许多学者进行了广泛的研究。文献[3]采用基于机器学习的方法进行车牌字符识别,该方法针对车牌字符清晰的车牌具有一定的鲁棒性,但对于车牌字符倾斜、模糊则效果不佳。文献[4]采用基于颜色的车牌定位方法,该方法充分利用车牌颜色信息,但车身颜色与车牌颜色一致时,定位错误率增加,且易受光照信息影响。文献[5]采用了深度学习的方法对车牌进行识别,准确率较高,但进行了字符分割步骤,对于字符粘连的车牌无法进行识别,且效率较低。文献[6]采用了基于颜色的车牌定位和基于LeNet-5的车牌字符识别方法进行车牌识别,但仅用单一的颜色定位在雾霾、夜晚等天气进行车牌定位效果不佳。为了兼顾车牌检测的定位速度和定位准确率,本文提出了一种由粗到精、基于SVM的车牌检测方法。首先结合车牌的颜色信息、边缘信息和文字信息快速检测出车牌的候选区域,再利用梯度方向直方图和支持向量机对候选区域进行筛选,从而实现车牌区域的快速精确定位。对于精确定位到的车牌进行样本扩充,得到80 602张图片,输入到改进的AlexNet卷积神经网络中进行训练,得到车牌字符识别模型,并使用该模型进行车牌识别。
本文提出算法的主要流程图如图1所示。首先对输入图像进行预处理,实现车牌的精确定位。将定位好的车牌输入到SVM[7]模型中判断是否为车牌,将判断为车牌的图块输入到端到端的深度学习模型License Plate Recognize(以下简称LPR)中进行车牌识别。
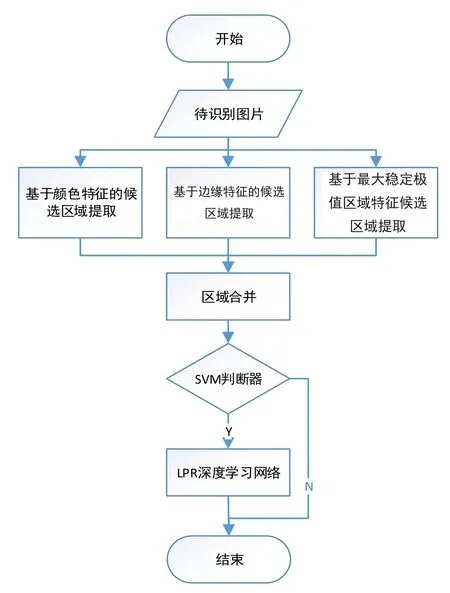
图1 系统流程图
2 车牌检测
车牌检测是车牌识别系统的第一步,由于我国的车牌具有特征明显,字符数目确定,选择采用车牌边缘检测的方法进行车牌定位;在自然场景下,车牌存在部分遮挡或其他类似轮廓区域,使得车牌定位准确度不高,而车牌颜色特征明显,因此采用基于颜色检测方法进行车牌检测;针对车身颜色与车牌颜色相近的情况,颜色检测效果不佳,此时采用文字检测进行补充[8]。
2.1 车牌边缘检测
根据车牌本色的特点,采用垂直边缘检测进行车牌定位。车牌边缘检测中,由于原始图像包含很多噪声,因此采用高斯模糊算法对自然场景下的图片进行处理,减少图像噪声,然后对图像进行灰度化处理。车牌字符主要是垂直边缘,因此选择Sobel算子实现垂直边缘检测。该方法是用3*3的模板卷积对图像进行变换,计算过程如式(1)所示。
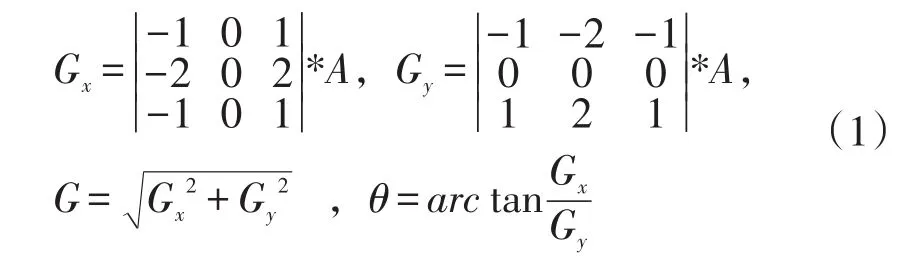
其中,A代表灰度图;Gx和Gy分别表示横向和纵向边缘检测的图像,G表示横向和纵向合并后的梯度值,θ表示梯度方向。采用openCV中Soble算子实现横向卷积,检测出图像的垂直边缘,针对蓝色车牌对检测出垂直边缘的图像进行正二值化操作,即越接近0的像素值赋值为0,否则为1。而黄色车牌字符深,背景浅,因此进行反二值化操作,即接近0的像素值赋为1,否则为0。由于车牌图像受光照影响,因此二值化的阈值采用openCV提供的自适应阈值进行处理。对得到的二值图像进行形态学闭操作,使车牌区域连通,并取连通区域的外接矩形,并将取出的矩形块输入到SVM模型中进行判断。
2.2 颜色检测
基于颜色检测的方法中,由于GRB模型中对于颜色相近的图像,G、R、B值相差较大,导致直接使用GRB模型进行车牌定位困难。因此将图像从GRB颜色空间转换到HSV颜色空间进行车牌定位,其中H表示色调(Hue),S表示饱和度(Saturation),V表示亮度(Value).转换方法如下所示:
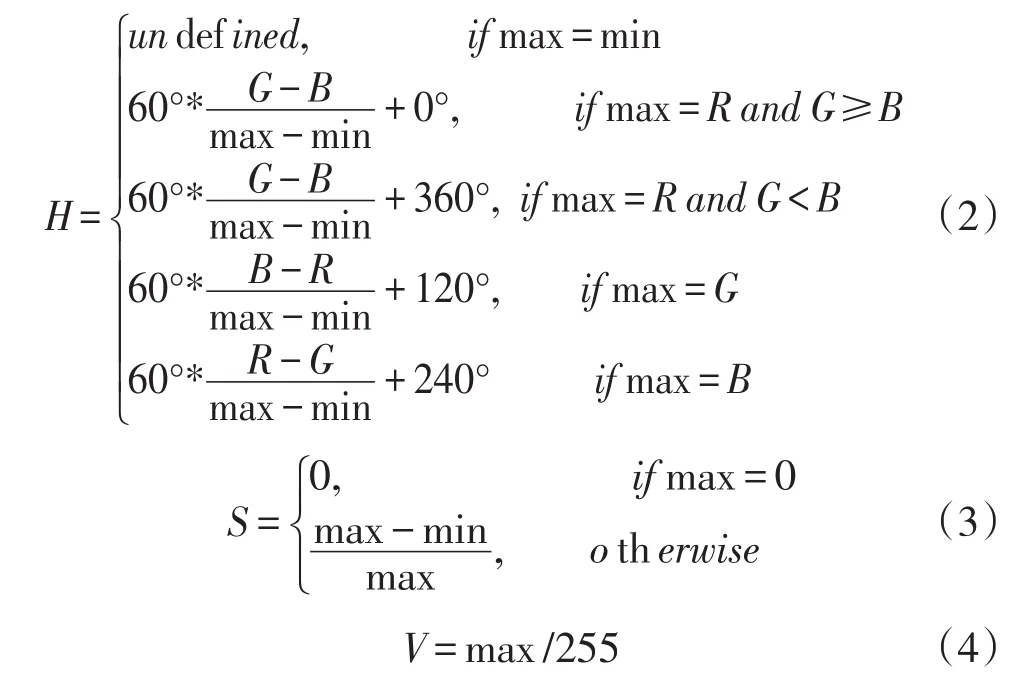
其中max=max(R,G,B),min=min(R,G,B)。本文主要对黄底和蓝底车牌进行检测,由统计数据得到蓝色和黄色在HSV空间中的范围,见表1。

表1 蓝色和黄色在HSV空间中的范围
为保证HSV分量落在0-255之间,对HSV分量进行处理,如公式(5)-(7)所示,

对转换成HSV空间的图像分别进行蓝色模板匹配和黄色模板匹配,避免车牌和车身颜色的干扰。在蓝色模板匹配过程中,将图像中H、S、V分量落在表1蓝色区域中的像素标记为白色像素,即255,否则标记为黑色像素,即0。在黄色模板匹配过程中,将图像中H、S、V分量落在表1黄色区域中的像素标记为白色像素,否则标记为黑色像素。从而得到两幅二值图像。对得到的二值图像进行形态学闭操作,使车牌区域连通,并取连通区域的外接矩形,并将取出的矩形块输入到SVM模型中进行判断。
2.3 文字检测
采用极大稳定值区域方法对获取的图片进行车牌字符文本检测,获取极大稳定值区域:
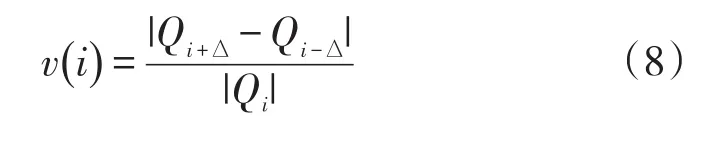
在对图像二值化过程中,有些区域面积随阈值上升变化很小,该区域称为Mser区域,其中Qi表示第i个连通区域的面积,∆表示微小的阈值变化,当Vi小于阈值时认定该区域为Mser区域。对Mser文字获选区域进行连通域分析,求最小外接矩形。若存在连续七个Mser文本区域,将七个矩形框进行合并,并判断为车牌候选区域,输入至SVM模型中进行车牌判断。
通过以上三种方法检测得到的矩形图块先通过外接矩形的宽高比和外接矩形的大小进行初步筛选,筛选后的矩形进行归一化处理,将预处理的矩形块输入到训练好的SVM模型中,判断是否为车牌,判断为车牌的图片则输入到卷积神经网络中,判断为非车牌的图块进行舍弃。图2为包含有车牌的自然场景下的图片,图3为通过三种检测方法定位的车牌图片,图4表示输入到SVM模型中的车牌矩形块。

图2 车牌原图

图3 车牌定位图片

图4 候选的车牌矩形块
3 车牌字符识别
本文提出的基于卷积神经网络的识别主要分为两部分,第一部分将预处理过的训练集输入到神经网络中进行训练,得到网络模型;第二部分将测试集输入到训练好的模型中进行字符识别。
3.1 车牌字符预处理
本文的样本量来源于easypr训练集[9]和网络。在上一步骤中得到的样本量不足,因此在网络上找到20张背景图片对样本量进行扩充。扩充的样本为模拟自然场景中的图片,添加了高斯噪声,样本倾斜等处理。为方便卷积神经网络的处理,将图片进行归一化。基于车牌本身的特征,将图片归一化至72*272大小。
3.2 识别车牌的端到端CNN模型
本文采用的CNN[10]模型结构如图5所示。2012年AlexNet[11]在ILSVRC2012竞赛上摘冠以来,深度学习网络在图像处理领域应用越来越广泛,本文采用端到端的车牌识别,车牌字符图像包括34个汉字,21个字母和10个数字的65类图像,但在终端输出需要同时输出7个车牌字符,本文改进了AlexNet网络,为获取更多的车牌字符特征,添加了一层卷积层,并添加切片层,使其得到7个分类输出。
具体网络结构各层介绍如下:
LPR网络底层是车牌图像,其大小为72*272;C1层为卷积层,该层采用32个3*3的卷积核对图像进行卷积,卷积步长为1,经过卷积后得到32张大小为70*270的特征图;C2层为卷积层,该层采用3*3的卷积核对C1层中32个70*270特征图进行卷积并累加,卷积步长为1,使用32个卷积核进行该操作,从而得到32张大小为68*268的特征图;P2层为池化层,本文采用的是2*2的池化窗口进行最大值池化,步长为2,减少待处理神经元的数目,得到32张34*134的特征图;C3层为卷积层,该层使用3*3的卷积核对P2层中32张特征图进行卷积并累加,卷积步长为1,从而得到32*132大小的特征图,使用64个卷积核进行卷积,输出为64*32*132个神经元;C4层为卷积层,该层运用3*3的卷积核对C3层中64张特征图进行卷积并累加,卷积步长为1,得到30*130大小的特征图,使用64个卷积核进行卷积,该层输出为64张30*130的特征图;P4层为池化层,该层运用2*2的池化窗口进行最大值池化,步长为2,从而得到64张15*65的特征图;C5层为卷积层,该层利用3*3的卷积核对P4层得到的64张15*65的特征图进行卷积并叠加,卷积步长为1,使用128个卷积核进行卷积,得到128张大小为13*63的特征图;C6层为卷积层,该层采用的卷积核大小为3*3,卷积步长为1,使用128个卷积核进行卷积,得到128张大小为11*61的特征图;P6层为池化层,采用2*2的池化窗口进行最大值池化,池化后神经元数目减少至128*5*30;F6层为展平层,将128张5*30的特征图转换为(128*5*30)*1*1的简单向量,向量包含有128*5*30即19 200个神经元。在该层中,防止出现过拟合,添加D6层进行数据泛化,令部分隐含层节点不工作。F7层为全连接层,本文采用的车牌数据包含小车的黄牌和蓝牌,该类型车牌字符包含有34个汉字,21个字母和10个数字,因此本层采用65个过滤器。同时,在数据层中,根据字符个数添加切片层,使其能识别7位数字,因此出现F7_1至F7_7全连接层,同时输出1-7个数字。该层不同于AlexNet网络。
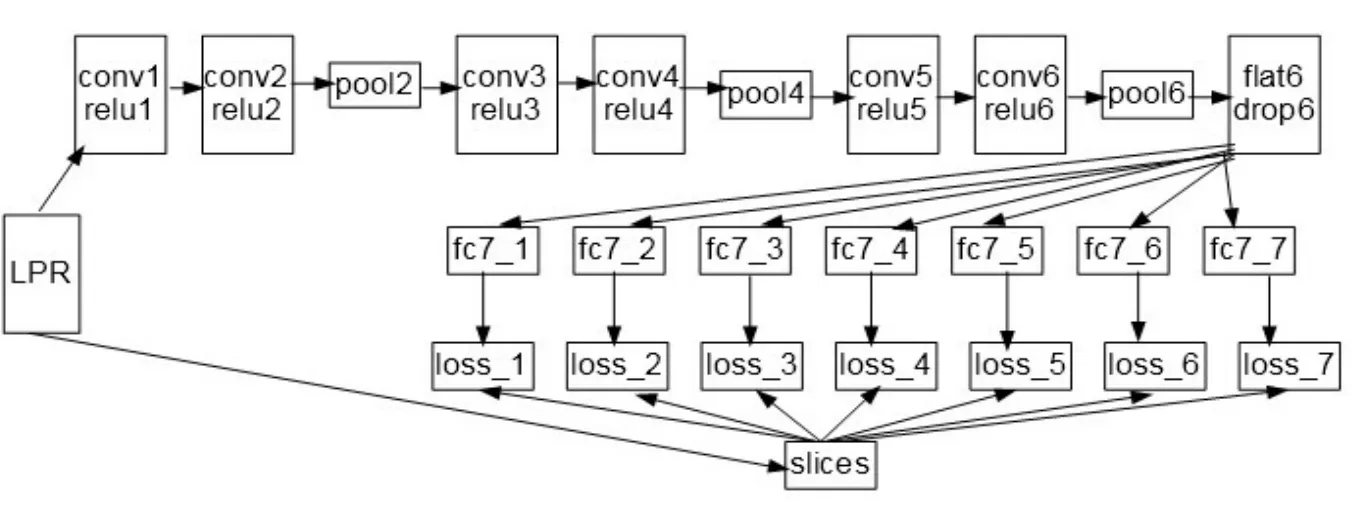
图5 端到端网络结构
由于本文采用的车牌图片由生成器生成,避免网络过快的收敛,以上的每一层卷积层都使用RELU函数进行激活。通过本文深度学习端到端的模型识别结果如图6所示。图7表示ANN模型车牌识别的结果,其中图片表示文件名,(g)表示标定图片,(d)表示识别结果。图8表示AlexNet模型车牌识别结果。
4 实验结果与性能分析
本文采用EasyPR的数据集和网络图片进行实验,在车牌定位阶段,本文使用EasyPR数据集进行验证,在256张包含有车牌的图片中,标定297张车牌图像,采用基于边缘检测和颜色检测的方法结合检测车牌,和使用文件检测方法检测车牌,以及本文采用的改进EasyPR车牌检测方法进行检测,结果表明,本文使用的方法中车牌检测准确率到达96.3%,但时间较长(见表2)。本文采用的实验硬件配置见表3。

表2 车牌定位
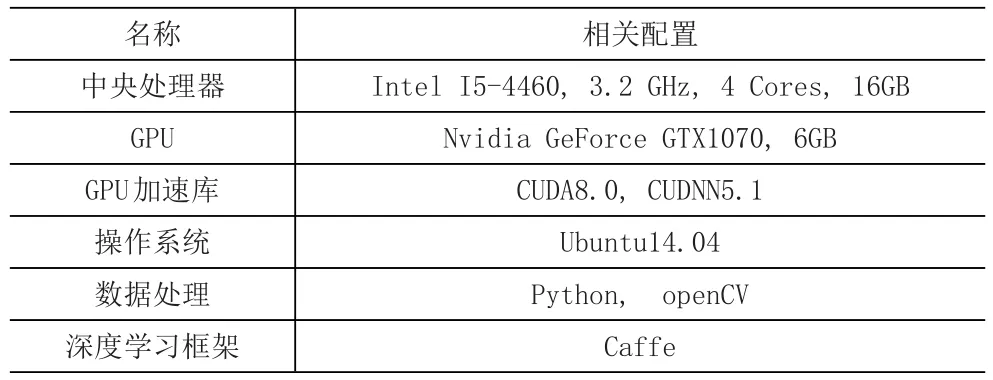
表3 软硬件配置
除却EasyPR数据集,本文还采用网络上的部分车牌图片以及自己收集的车牌图片进行车牌图片定位,得到车牌图片3 956张,并从网络上下载20张背景图片进行样本图片扩充,将扩充后的图片输入到端到端的车牌网络中进行车牌识别,得到的车牌识别准确率达到96.7%(见表4),且具有实时性。

表4 车牌字符识别
5 结论
本文采用了基于端到端的车牌识别方法进行自然场景下的车牌识别,改进了端到端的深度学习网络,提高了车牌识别的准确度,并省却了车牌字符分割的步骤,避免车牌倾斜或部分粘连造成车牌字符识别不准确的情况,对车牌字符粘连、倾斜情况下的车牌识别准确率大大提高。通过EasyPR字符集的验证结果得知,车牌定位的准确率达到96.3%,车牌字符识别准确率达到96.7%,但在样本中存在许多扩充样本,影响了模型训练结果,同时系统整体车牌识别实时性不够,这是本文算法需要改进的地方,也是今后研究的重点。
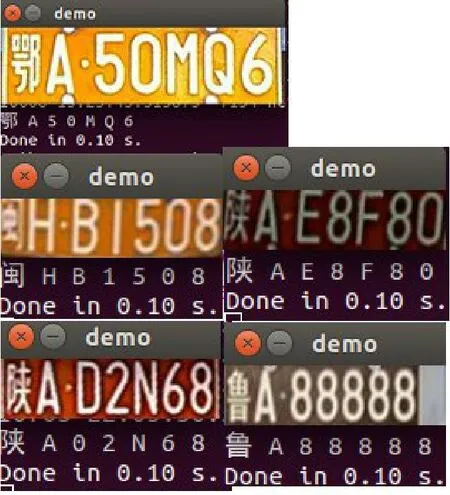
图6 本文算法车牌识别结果
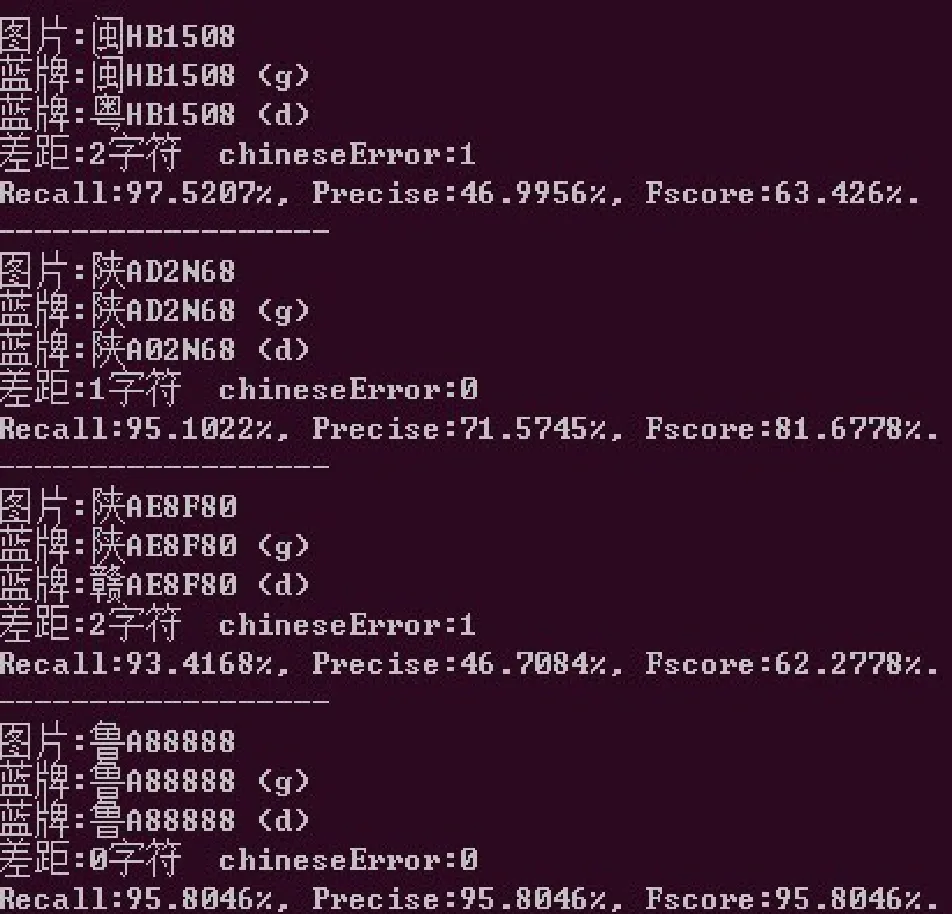
图7 ANN模型车牌识别结果

图8 AlexNet识别结果
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年12期)2019-07-16
电子制作(2019年11期)2019-07-04
数字通信世界(2019年3期)2019-04-19
北京航空航天大学学报(2018年1期)2018-04-20
小猕猴智力画刊(2017年5期)2017-05-25
