
基于Hadoop的分布式并行增量爬虫技术研究
2018-10-18 10:11,,
计算机测量与控制 2018年10期
,,
(河南科技大学 信息工程学院,河南 洛阳 471023)
0 引言
爬虫[1]一般用于搜索引擎,实现快速、高效的从庞大的互联网信息中找到用户感兴趣的信息。爬虫还用于研究人员所需要的研究数据的采集[2]。但是随着大数据和Web2.0时代的到来,多媒体社交网络上的各类信息都“爆炸式”增长,单机爬虫的效率和更新速度已经无法满足用户的需要,将并行技术用于爬虫可有效改善爬虫的效率[3],大数据环境下,并行爬虫都是在分布式架构[4-5]上实现的,因为分布式爬虫比单机多核并行爬虫更适用于大数据环境。
为了获取互联网上的最新信息,全部重爬技术存在刷新代价大和数据冗余等问题,增量爬虫技术可以有效解决该问题[6]。增量爬虫技术就是利用特定的页面刷新策略保证页面副本的时新性。其中,针对页面变化的研究是制定页面刷新策略的重点。通过采样根据样本的变化规律估计整个网站的变化规律的方法可以保证页面副本的时新性,但是还是存在数据冗余的问题。故通过历史记录监控网页的变化,提出基于时间感知的增量更新算法,最后和基于Map/Reduce的并行算法相结合,在提出的分布式集群架构上验证算法的性能和效率。
主要贡献:1)在Hadoop分布式集群的基础上提出基于Map/Reduce框架的并行算法;2)提出基于时间感知的增量更新算法,监控网页的更新模式,计算出不同时间产生的页面的相似性得分,通过页面的相似性得分序列计算出时间感知相似性协方差矩阵,通过调整爬虫频次和最大相似性阈值等参数,使用混合整数二次规划方法优化目标函数,得出最优的刷新策略,能以更低的刷新代价获得更好的信息精确度和信息新鲜度;3)将增量爬虫和分布式并行爬虫相结合,应用于真实的数据集上,证明算法有较好的性能和效率。
余下部分的组织如下:第1部分是研究的相关工作进展,第2部分介绍分布式并行爬虫框架、并行爬虫和增量爬虫及相关算法,第3部分是实验结果分析及应用,最后是给出结论。
1 相关研究工作
文献[7]为了快速获取微博数据,在单进程爬虫的基础上进行了并行框架的扩展,实现了基于MPI的并行数据抓取功能,该并行爬虫拥有较好的加速比,可以快速地获取数据,并且这些数据具有实时性和准确性。文献[8]提出一种基于Kademlia的全分布式爬虫集群方法,该方法能构建高效、均衡、可靠、可大规模拓展的全分布式爬虫集群。文献[9]研究的是基于Hadoop的分布式爬虫技术,并在该分布式爬虫的基础上实现爬虫的并行化处理,从节点不仅在各节点之间并行处理主节点分配的各个分任务,而且从节点内部也多线程的并行处理内部任务。
关于增量爬虫的页面的刷新策略,Tan[10]等人利用采样样本的方式来确定刷新时刻。文献[11]提出了基于泊松(Poisson)分布的页面刷新策略,作为增量爬虫的页面刷新方法。大量研究证明网页的变化一般遵循泊松过程,根据这个规律可以为网页的变化建立刷新模型,以此来预测网页的下次更新时间。C Olston[12]等人将基于网页特征的采样和符合Poisson分布的这种周期性的变化结合起来,提出了一种基于信息周期的刷新策略,根据上下效用值边界来动态地调整网页的刷新周期。文献[13]在C Olston等人的基础上改进Super-shingle 算法,使其适用于视频资源的爬虫。由于C Olston等人引入的估计效用值的方法没有实际意义,故文献[14]给出了一种实用有效的估计效用阈值的方法,与以前的基于边界的方法相比,该基于效用值的方法更好的平衡了新鲜度和刷新成本,以更低的成本获得更好的新鲜度。K Gupta[15]等人提出一种精度感知的云爬虫技术,使得在资源/预算受限环境中对本地数据重新抓取以便高精度的检索最大信息量。
综上所述,现有的爬虫技术还没有在效率、刷新代价和新鲜度上有较好的平衡,故提出了分布式并行爬虫来提高爬虫的效率,提出基于时间感知的增量更新算法以更低的刷新代价获得更好的新鲜度,并将两者结合起来更好的平衡效率、刷新代价和新鲜度。
2 分布式并行增量爬虫
2.1 基于Hadoop的分布式并行爬虫框架
论文使用的分布式爬虫系统采用主从结构,即一个主控节点控制所有从节点执行抓取任务,主控节点负责分配任务,保证集群中所有从节点的负载均衡。使用的分配算法是计算每一个URL对应主机的哈希值,然后将相同主机的URL分到一个分区里。这样做的目的是使相同主机的URL 在一台机器上被爬取。分布式爬虫可以看作是多个集中式爬虫系统组合而成,每一个从节点都相当于一个集中式爬虫系统,这些集中式爬虫系统在分布式爬虫系统中由一个主控节点来控制和管理使其能够协同工作。
从图1的分布式并行爬虫框架图中我们可以看到,框架中的主要部分包括负责任务生成、任务分配和调度以及控制管理整个系统(如爬虫的深度,更新时间配置、系统的启动和停止等)的主控节点;负责并行下载页面的爬虫集群;负责解析页面、优化链接和网页更新的MapReduce功能模块;负责主控节点、爬虫节点和集群之间的通信和协作(如日志管理、爬虫集群间数据交换及运行维护)的消息中间件;和负责数据存储的分布式文件系统(HDFS)。
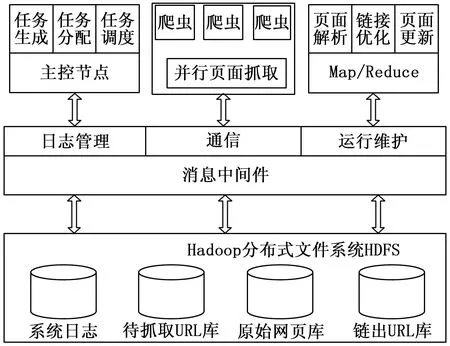

图1 基于Hadoop的分布式并行爬虫框架图
2.2 并行爬虫
为了能对存储在HDFS中的大规模数据进行并行化的计算处理,Hadoop又提供了一个称为Map/Reduce的并行化计算框架。该框架能有效管理和调度整个集群中的节点来完成并行化程序的执行和数据处理,并能让每个从节点尽可能对本地节点上的数据进行本地化计算。
整个爬虫系统的核心部分可以分为3大模块,分别为下载模块,解析模块和优化模块。每个模块都是一个独立的功能模块,每个模块对应着一个Map/Reduce过程。
1)下载模块可以实现并行下载未抓取列表。具体下载是在Reduce阶段完成的。
2)解析模块可以实现并行分析已下载网页,提取出链出链接。该模块只需要一个Map阶段即可完成目标,还通过规则限制链出链接的类型,防止抽取出的链接链接到其他网站上。
3)优化模块可以实现并行优化链出链接集合,过滤掉重复链接。
可以看出Web爬虫系统的并行化是通过这3个可并行化的模块实现的,实质上也就是通过Map/Reduce的并行化计算框架实现的。
在Map/Reduce任务开始时,输入数据会被切分成若干个分片(split),默认每64M为一个分片。每一个分片都由一个Map进程处理,一个爬虫可以同时开启多个Map进程。所有Map的输出结果合并之后,根据分区算法,将相同站点的URL分配到一个分区中,这样可以使相同站点的URL在同一台机器上被爬取,每一个分区的任务由一个Reduce进程处理,若干个分区有若干个Reduce进程并行处理,同时一个爬虫还可以开启多个Reduce进程。最后将并行执行的结果保存到HDFS上。
定义1:Crawler={c1,c2, ...,cn}:表示集群中爬虫节点的集合。ci表示第i个爬虫节点。一个爬虫节点可以开启的最大Map进程数和最大Reduce进程数由节点上的处理器个数决定。
定义2:{split0,split1, ...,splitm-1}:表示文件分片的集合。一个分片由一个Map进程处理。
定义3:{part0,part1, ...,partk-1}:表示文件分区的集合。一个分区由一个Reduce进程处理。
假设m= 2n,k=n,那么基于Map/Reduce的并行算法如Algorithm 1所示。Algorithm 1: Parallel algorithm based Map/ReduceInput: Input-File
Output: Output-File
1: Begin
2: Split Input-File into m slices => {split0, split1, ..., splitm-1};
3: send split0, split1to c1, open two Map processes to process this two slices
4: and send split2, split3to c2, open two Map processes to process this two slices
5: and ....
6: and send splitm-2, splitm-1to cn, open two Map processes to process this two slices;
7: Combiner all Map output => Inter-results;
8: partitioner(Inter-results) => {part0, part1, ..., partk-1};
9: send part0to c1, open a Reduce process to process part0=> partition_0
10: and sendpart1to c2, open a Reduce process to process part1=> partition_1
11: and ....
12: and sendpartk-1to cn, open a Reduce process to processpartk-1=> partition_n-1 ;
13: Output-File = {partition_0,partition_1,...,partition_n-1};
14: End
2.3 增量爬虫
增量爬虫的主要作用就是对数据集合的日常维护与即时更新。该技术只会在需要的时候下载新产生的网页或发生更新的网页,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬取的网页,减小资源的耗费,保持本地数据和集成的Web数据的一致性。
下面是基于精度感知的页面刷新策略[15]的改进。首先根据爬取网页目标的不同设置不同的爬行计划,然后在精度感知的基础上增加新鲜度感知来确定最优的爬行计划,最后对基于页面相似性得分的时间感知相似性协方差矩阵进行降维处理来优化混合整数二次规划方法,提高算法的效率。
定义4:T={t1,t2, ...,tn}:表示初始爬行计划中的爬行时间戳列表。
定义5:页面P的爬行计划(表示为TP)是执行爬行的时间戳的顺序集。爬行计划TP中的时间戳数|TP|称为爬行频次f。其中,f= |TP| < |T|。
定义6:P={P1,P2, ...,Pn}:表示页面在不同时间戳产生的快照的集合,Pi是页面P在时间戳ti的快照。
为了简化研究,只考虑从给定页面Pi提取相关科技链接,而不是完整的页面内容。因为新的科技以新的链出链接的形式发布重要内容,其中每个科技链出链接都链接到视频页面。总之,每个Pi现在可以被看作是相关科技链接的集合。
定义7:Accuracy:爬行计划的信息精确度,表示为相对于基线爬行计划T捕获的信息NT,通过爬行计划TP捕获的信息的百分比。令NTP是使用爬行计划TP获得的一组内容(链出链接)。那么,AccuracyTP定义如下:
(1)
定义8:Freshness:爬行计划的信息新鲜度,从侧面反应着所抓取的元素中当前为新元素的比例。即相对于基线爬行计划T捕获的信息NT,通过爬行计划TP捕获的最新信息的百分比。令FTP是使用爬行计划TP获得的一组最新内容。那么,FreshnessTP定义如下:
(2)
定义9:S(Pi,Pj):表示不同时间戳上爬行的两个页面之间科技视频链接的相似性得分。
(3)
定义10:PTS:表示页面相似性得分时间序列。给定n个爬行页P={P1,P2, ...,Pn}的顺序集,页面相似性得分的时间序列是计算P中连续的两个页面相似性得分的n-1个值的序列。
PTS={S(P1,P2),S(P2,P3),...,S(Pn-1,Pn)}
(4)
例如,保持爬行固定时间段大小为1个月,因为科技类视频网站更新频率低。初始爬行计划是T= {1号,2号,...,30号}。如果每月爬行次数为5次,在随机选择技术中,从T随机选择不同的时间戳。在统一分配方案中,以均匀的间隔从T选择爬行时间戳。则每6天即可进行统一的爬行策略,TP= {1号,7号,13号,19号,25号},这两种方法是无监控的,没有利用网页更新模式的特征,无法获得更好的精度和时新性。故需要使用监控技术获取网页的更新模式,分析计算出最优的爬行计划使得网页更新的精度和新鲜度都是最优的。
定义11:M:表示基于页面相似性得分的时间感知相似性协方差矩阵。令n为T的基数。M是n×n矩阵,其中单元格(i,j)中的条目表示在时间戳ti和tj上爬行的页面之间的相似性得分的平均值。假设我们已经监视了d个月的页面更新,则单元格(i,j)中的条目表示为:
(5)
其中:S(Pi,Pj)表示在第k个月爬行的页面Pi和Pj之间的页面相似性得分。如果页面Pi和Pj不是连续的页面,中间隔着一个页面Pk,那么,
S(Pi,Pj)=S(Pi,Pk)×S(Pk,Pj)
(6)
理想情况下,应该选择合适的时间戳,使它们在M矩阵中具有较小值。间接地,应该寻找一个子集T’,使得以下功能被较小化。
(7)
用枚举的方法可以获得使公式(7)较小化的子集T’,但是这种方法的时间复杂度是指数级的,为了优化这个方法需要从另一个角度考虑问题。这个问题的本质实际上就是给定一组变量,必须选择一些变量才能实现目标。这里,一组变量对应于爬行的时间戳,目标是使公式(7)中给出的函数较小化。 正式的问题定义如下:
假设t1,t2,...,tn是爬行时间戳。每个ti与布尔参数bi相关联,使得:
(8)
给定子集T’的基数f和时间感知相似性协方差矩阵M,重构问题如下所示:
(9)
这是一个二进制二次规划问题,可以使用混合整数二次规划求解。混合整数二次规划的目标函数是形式如下。
(10)
其中:H=2 M。为了使用混合整数二次规划(MIQP)求解二进制二次规划问题,将α设为零向量,将x设为大小为n的布尔向量。使用混合整数二次规划工具箱miqp解决MIQP问题。该算法的时间复杂度是多项式级别的,即O(|T|2)。
可以通过自定义爬行频次f调用MIQP算法得到页面更新的最佳爬行时间序列T’,但是如果在最佳爬行时间序列中某个时间戳上的页面几乎没有太明显的更新,或者实现这些更新会花费更多的代价,那么对于这些计划内的页面更新是没有必要的,所以,需要先把页面相似性得分时间序列PTS中相似性得分平均值偏高的时间戳过滤掉,然后再计算最佳的爬行时间序列,通过这种降维的方式可以降低计算公式(10)的时间复杂度。如果降维后的维数小于爬行频次f,那么把该网页标记为“无变化”,在增量抓取过程中不将该网页放入待抓取队列中。基于时间感知的增量更新算法如Algorithm 2 所示。
2.4 增量式更新分布式并行爬虫
增量更新分布式并行爬虫基本流程说明如下:
1)收集种子集合。先为每一个爬虫目标收集一个URL种子作为下载数据的入口链接。同时,设置已抓取层数为0。
2)判断待抓取列表是否为空。若是,跳转到7);否则,执行3)。
3)并行下载待抓取列表中的页面。
4)并行解析已抓取的网页。
5)并行优化解析出来的链出链接。将优化结果放入待抓取列表中,等待下一轮抓取。
6)判断已抓取层数是否小于depth。若是,“已抓层数”自加1,返回2);否则进入7)。
7)合并去重。将每层抓取的网页合并,去掉重复抓取的网页。
8)更新本地数据库。将合并去重后的原始网页保存到本地数据库。检索整个本地数据库,根据Algorithm 2得出的网页的爬行计划将拥有此刻爬行任务的页面添加到待爬取列表中。
9)对网页内容做进一步解析。并行分析网页内容,从合并去重后的网页中解析出需要的属性信息,本系统需要的属性信息有标题,发布时间,来源,视频源等。
10)根据解析出的属性信息做进一步筛选。如果属性信息满足用户规则,如发布时间在最近7天内。就将满足条件的属性信息包括网页的URL上传到服务器数据库中。否则,舍去。
Algorithm 2: Time - aware incremental updating algorithmInput: PTS set, Crawling frequency: f, Initial crawling plan:T={t1,t2, ...,tn}, the Maximum similarity:δ
Output: Crawl_Queue
1: Begin
2: new_T={t1}, new_PTS={}
3: form←1 to N// N indicates the number of Local page
4:if PTSmisExist
5: fork←1to n-1
6: ifPTSmk< δ
7:new_PTS.add(PTSmk)
8:new_T.add(tk+1)
9: endif
10:endfor
11: if| new_T| >= f
12: new_PTS => M
13: MIQP( f, M, new_T ) => T’;
14: Crawl_Queue.add(Pm) by schedule T’;
15:endif
16:endif
17: generate a new PTS for Pm
18: endfor
19: End
3 实验及结果分析
为了快捷有效的汇聚海内外最新最前沿的科技视频,开发了基于Map/Reduce的并行增量爬虫,该爬虫在分布式框架Hadoop集群上实现。搭建的Hadoop集群由三台服务器组成,一台作为Master节点,两台作为Slave节点,节点之间局域网连接,可以相互通信。由三台服务器搭建的Hadoop集群的配置如表1所示。
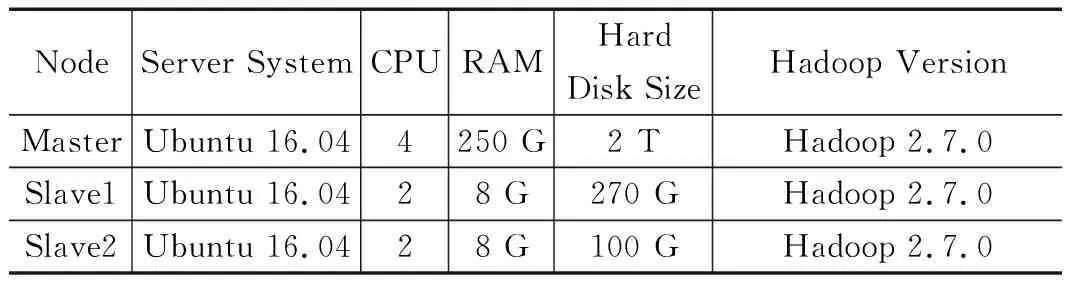
表1 Hadoop集群配置
3.1 实验数据收集与数据分析
先使用经验数据来说明MIQP方案的表现。首先,收集数据并分析。接下来,专注于找到针对给定爬行频次的最佳爬行时间表的问题。与基准策略相比,将基于优化技术来说明解决方案的性能。
3.1.1 实验数据收集
爬虫从2017年11月1日开始,到2018年1月30日结束,以1天为间隔监控3种不同的科技来源。表2列出了数据集中存在的3个主要科技来源。
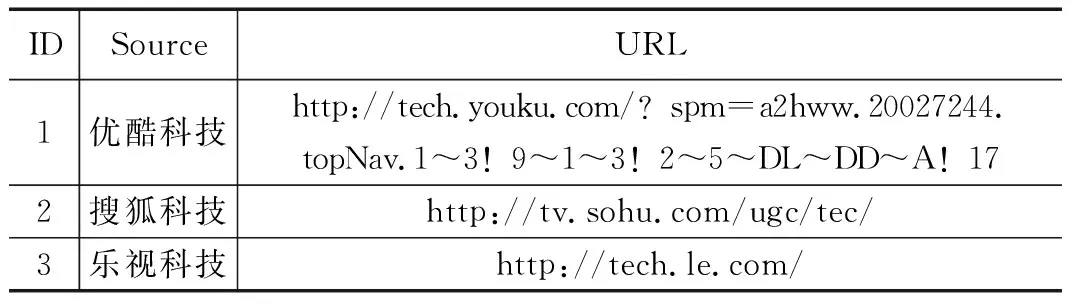
表2 主要科技来源
收集的数据为每次爬虫的日志数据,部分数据如表3所示,Out_links字段存储当前页面上的所有链出链接ID的集合,对照表4(本地数据),可找出具体的链出链接集合。
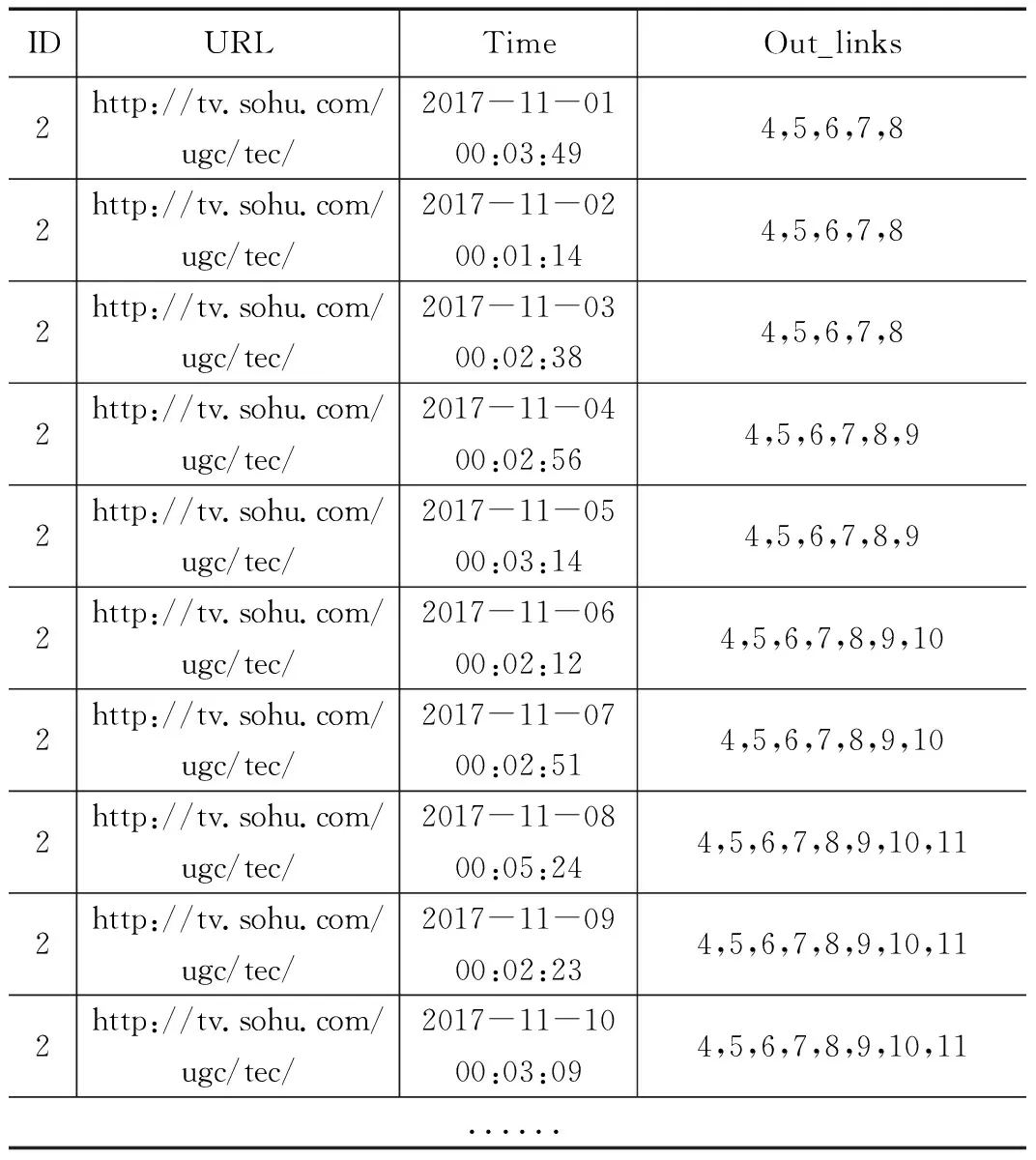
表3 爬虫记录表
3.1.2 实验数据分析
将MIQP策略和穷举策略,随机策略,均匀策略的进行对比来说明MIQP策略的综合性能最优。
首先介绍第2.3节讨论的穷举策略和MIQP策略的爬虫结果。如前所述,已经爬取了3个属于科技类别的新资源3个月。使用前2个月的数据作为训练数据,以制定最佳爬行计划,剩余的一个月数据作为测试数据。使用训练数据发现给定爬行次数的爬行计划,然后构建跟踪测试数据中每月发现的计划的爬虫程序。该分析的评估指标是信息精确度(见定义7)和信息新鲜度(见定义8)。初始计划以1天的时间间隔从月初1号开始爬行科技视频,到月末30号结束。表5显示了针对不同爬行频次值的搜狐科技的穷举策略和混合整数二次规划策略的最佳爬行计划。
在表5中,我们可以看到,穷举策略和混合整数二次规划(MIQP)策略生成的时间表(以天为单位,1#代表1号)并不完全相同。但是,这两个策略的性能方面仍然与图2所示的相似。我们可以看出,穷举策略执行最好,然后是混合整数二次规划策略。这两个计划之间的精确度差异很小,而随机策略和均匀策略的表现是不可预测的。除了考虑信息的精确度之外,还要考虑信息的新鲜度,如图3所示,与穷举策略相比,MIQP策略的信息新鲜度除了个别的差异较大之外,都和穷举策略的相似。然而,如图4所示,与穷举策略相比,MIQP策略的时间复杂度非常低。
综合考虑图2、图3和图4的信息精确度数据、信息新鲜度数据和时间复杂度数据,当爬行频次为11时,爬虫可以以较小的代价获得最优的性能。
在爬行频次一定的情况下,还可以继续优化MIQP策略的效率,如表6和图5所示,随着最大相似性阈值的降低,信息精确度和新鲜度几乎没有多大变化,而MIQP策略的效率在明显提高,当最大相似性阈值继续降低时,信息精确度和新鲜度也明显降低。其中,表6中δ代表最大相似性阈值,|M|代表矩阵的维数。

表5 最优爬行计划表
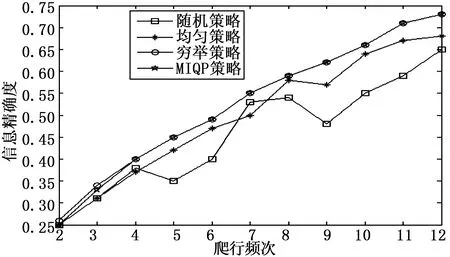
图2 不同爬行频次下不同策略的信息精确度比较
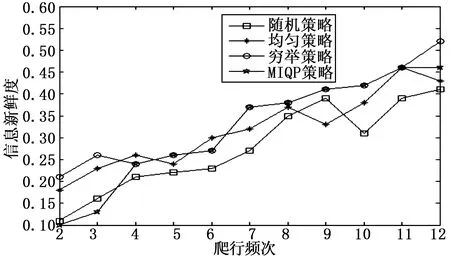
图3 不同爬行频次下不同策略的信息新鲜度比较

图4 MIQP策略与穷举策略的时间复杂度比较
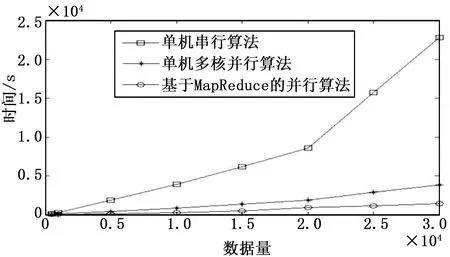
图5 不同最大相似性阈值下MIQP策略的时间复杂度
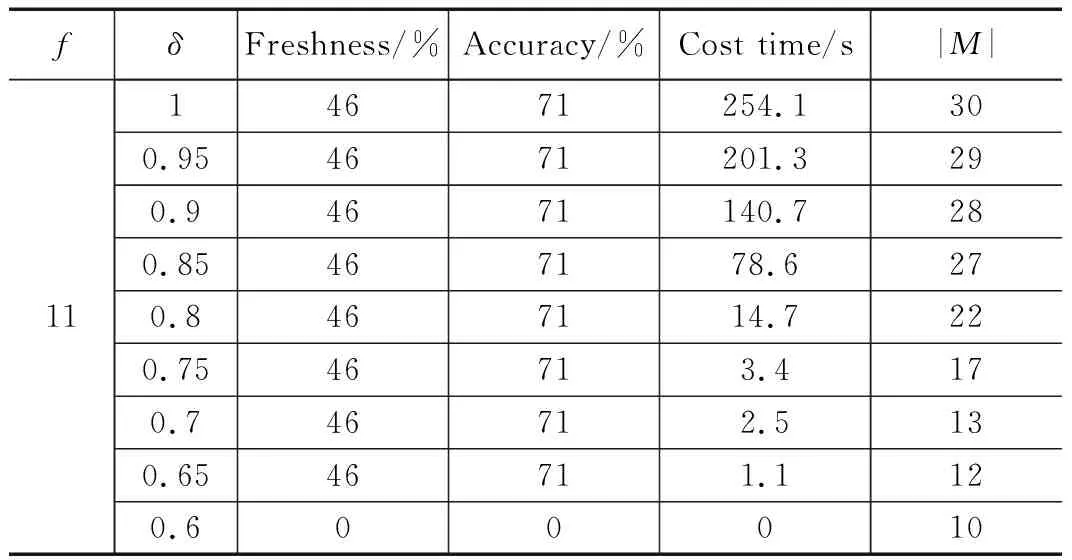
表6 最大相似性阈值选取
通过分析可以知道当爬行频次为11,最大相似性阈值为0.65时,可以获得46%的信息新鲜度,71%的信息精确度,MIQP策略的效率提升了约230倍。
3.1.3 算法评价指标及实验数据验证
提出的时间感知增量更新算法的评价指标有三个,分别为信息精确度,信息新鲜度和时间复杂度。信息精确度的定义如2.3节中的定义7所示。信息新鲜度的定义如2.3节中的定义8所示。信息精确度和信息新鲜度之间的区别就在于通过爬行计划TP捕获的信息是否是最新的。例如,在初始爬行计划T = {1号,2号,...,30号}下每天爬取的最新信息的量形成的序列为Newnum= {64, 11, 12, 10, 8, 12, 0, 0, 8, 11, 9, 11, 9, 0, 0, 10, 9, 16, 11, 11, 0, 0, 14, 14, 12, 7, 11, 0, 0, 15},也即第一天爬取64个最新视频,第二天爬取11个最新视频(相比于第一天),第三天爬取12个最新视频(相比第二天),以此类推,假如,最佳爬行频次为3,最佳爬行时间序列为T’={1号,13号,30号},则信息精确度和信息新鲜度的分母即基线爬行计划T捕获的信息量是一定的,等于基线爬行计划中每天爬取的最新信息之和,而信息精确度的分子(这些信息中某些信息已经失去了时效性)等于第1天的最新信息量加上第13天相对于第1天捕获的最新信息量再加上第30天相对于第13天捕获的最新信息量,由于页面上的信息都存在一定的信息周期,所以第13天相对于第1天捕获的最新信息量并不等于Newnum序列中第2个元素到第13个元素之间所有元素的和,而是小于该和。而信息新鲜度的分子(这些信息都具有时效性)等于Newnum序列中第1个,第13个和第30个元素之和。时间复杂度的概念我们并不陌生,它描述了算法的运行时间,算法的时间复杂度越高,说明该算法的效率越低。
通过上述的数据分析可知,当爬行频次为11,可以获得最优的爬行计划Topt= {1#, 3#, 6#, 9#, 13#, 15#, 19#, 21#, 25#, 28#, 30#},在该爬行计划下对最后一个月收集的实验数据进行验证,通过计算可知,通过该最优爬行计划可以获得79%的信息精确度和42%的信息新鲜度。定义的信息新鲜度的新鲜性不超过一天,也即信息的获取时间与信息的发布时间的差值小于一天。由于科技类视频的生存周期比较长,那么我们也可以把信息新鲜度的新鲜性规定在两天之内,这样的话我们通过最优爬行计划就可以获得73%的信息新鲜度。
3.2 实验结果
3.2.1 基于MapReduce的并行爬虫与单机爬虫对比
以搜狐科技频道为例,对单机单核串行爬虫、单机多核并行爬虫以及基于MapReduce的并行爬虫作对比,比较它们在处理相同规模的数据时,所花费的时间,以此作为评价爬虫效率的标准。在实验中一共进行了5次对比数据,数据量从500条增加到3万条,实验结果如图6所示。
图6 串行算法和并行算法的对比
从图中可以看出,基于MapReduce的并行算法的效率最高,其次是单机多核并行算法,而单机串行算法的效率最低。当数据量达到2万时,随着数据量的增加,单机爬虫所花费的时间急剧增加,而基于MapReduce的并行爬虫所花费的时间在缓慢增加。
3.2.2 分布式并行增量爬虫与非分布式爬虫效率对比
以搜狐科技为例,以一个月为周期使用分布式并行增量爬虫更新本地搜狐科技数据,单机模式下增量式更新本地数据,单机模式下每天定期重爬。对这三种爬虫的效率,产生的冗余和花费的代价(爬虫更新频次)进行比较。如表7所示。
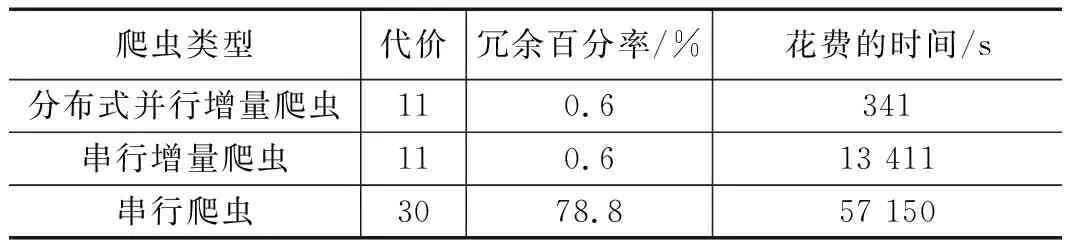
表7 不同爬虫类型性能对比
由表7我们可以分析得出,与单机模式下定期全部重爬的爬虫相比,分布式并行增量爬虫以原刷新代价的36.7%,消除了99.4%的冗余,爬虫效率提高了167倍。与串行增量爬虫相比,分布式并行增量爬虫的效率提高了39倍。由此可知,提出的分布式并行增量爬虫可以以较低的刷新代价和较高的爬虫效率获得较优的爬虫性能。
3.2.3 爬虫结果在多媒体社交网络平台(CyVOD.net)的应用
使用开发的分布式并行增量爬虫系统同时对搜狐视频网站、乐视视频网站和优酷视频网站上的科技类最新最热视频进行并行自动化抓取。图7展示了搜狐视频网站上抓取的部分数据。其中主要抓取的视频数据信息有视频名称,视频网址,视频发布时间和视频源。图7中的crawltime字段表示数据的抓取时间,videosource字段表示视频源文件的存放地址,而视频的原文件存放在云服务器上。自动化程序抓取的数据存放在CyVOD平台的数据库中,可以直接在CyVOD平台首页展示出来。如图8所示是系统运行结果的部分科技视频展示。
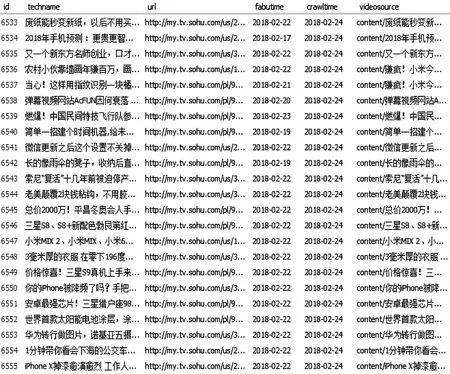
图7 搜狐科技视频部分数据
4 结束语
由于用户对用爬虫来搜索或采集信息的效率,性能和新鲜度的要求越来越高,为了适应互联网激增的数据和网页的动态变化,设计并实现了基于分布式集群的并行爬虫算法。然后通过监控分布式并行爬虫的本地数据库网页更新
图8 系统运行结果在CyVOD首页上的部分展示
模式分析网页变化的特征,用表征科技类信息的链出链接的变化作为网页变化的依据,结合时间感知相似性协方差矩阵和最大相似度阈值最大精度的优化页面的爬行计划。以网页最佳爬行时间戳序列作为网页刷新策略来增量式地更新分布式并行爬虫。实验证明,相比定期频繁的刷新策略,该方法能以较小的刷新代价获得较好的爬虫性能和更新质量。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
粮食储藏(2021年4期)2021-12-15
现代信息科技(2021年21期)2021-05-07
河北画报(2020年8期)2020-10-27
数码设计(2019年5期)2019-12-20
电子制作(2018年2期)2018-04-18
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
现代妇女(2014年9期)2014-09-09
食品工业科技(2014年13期)2014-03-11
