
基于异质SVM神经网络的土壤盐渍化灾害预测模型
2018-10-15 02:06贾科利张晓东张俊华
水文地质工程地质 2018年5期
武 丹,贾科利,张晓东,张俊华
(1.宁夏大学资源环境学院,宁夏 银川 750021;2.宁夏回族自治区遥感测绘勘查院(宁夏回族自治区遥感中心),宁夏 银川 750021;3.中国地质大学(北京)信息工程学院,北京 100083;4.宁夏回族自治区地质调查院,宁夏 银川 750021;5.宁夏大学环境工程研究院,宁夏 银川 750021)
土壤盐渍化是气候、水文地质、环境地质及人类活动共同作用下形成的一类灾害性的土壤变化,忽视土壤盐渍化治理,会导致土壤肥力下降,不利于土壤的可持续利用。由于技术方法与数据精度等因素的限制,早期土壤盐渍化程度的评价工作主要使用信息叠加的分析方法,通过地理信息系统(GIS)的叠加分析功能将多个指标进行叠加来评估土壤盐渍化风险等级。研究表明,评价指标之间不仅仅是叠加关系[1],而是呈非线性关系,通过综合作用影响土壤盐渍化的程度。因此,通过数学方法建立预测模型逐渐成为土壤盐渍化研究的主要方法。丁建丽等[1]选择BP-Adaboost预测器对4个预测指标进行处理,得到土壤盐渍化预测结果;姚荣江等[2]将生态风险评价数学模型与灰色系统理论结合,对苏北海涂围垦区进行土壤盐渍化风险评估与分级;沈掌泉等[3]对比集成BP神经网络与传统统计学的克里格插值法,研究土壤养分的空间变异和插值精度。以上研究均表明基于数学建模的盐渍化研究方法能更准确地评价土壤盐渍化程度且预测精度更高。
随着定量研究的不断深入,在土壤盐渍化评价中使用神经网络模型的研究逐渐增多[4],预测精度也进一步得到提升。支持向量机(Support Vector Machine,SVM)神经网络是以大脑生理变化过程为基础,借助计算机定量计算大量数据[5],计算过程中不需要反复调试权重值,克服了以往为提高模型预测精度需多次调整指标所占权重来获得参数的缺点,适合用于解决分类问题,已应用于短时交通量预测[6]、地下水位预测[7]、需水量预测等诸多领域并取得了很好的效果。本文以银川平原为研究区,应用异质SVM神经网络建立土壤盐渍化预测模型,对银川平原的土壤盐渍化进行评价研究,以期为银川平原的土壤盐渍化预测提供借鉴。
1 研究区概况及数据源
1.1 研究区概况
银川平原位于宁夏北部(图1),面积约7 790 km2,海拔高度1 100~1 500 m,属于中温带干旱区,气候干燥蒸发作用强烈,年均降水量185 mm,年均蒸发量1 825 mm,蒸降比为10∶1。银川平原位于黄河上游中段是典型的引黄灌溉区,自西向东、由南向北缓倾,黄河水溶解性总固体为4.5~4.85 g/L,局部地区地下水溶解性总固体高、埋藏浅。银川平原南部地区灌排条件较好,北部地区坡降小、地下水位高、排水不畅,导致土壤积盐情况较严重[8~9]。
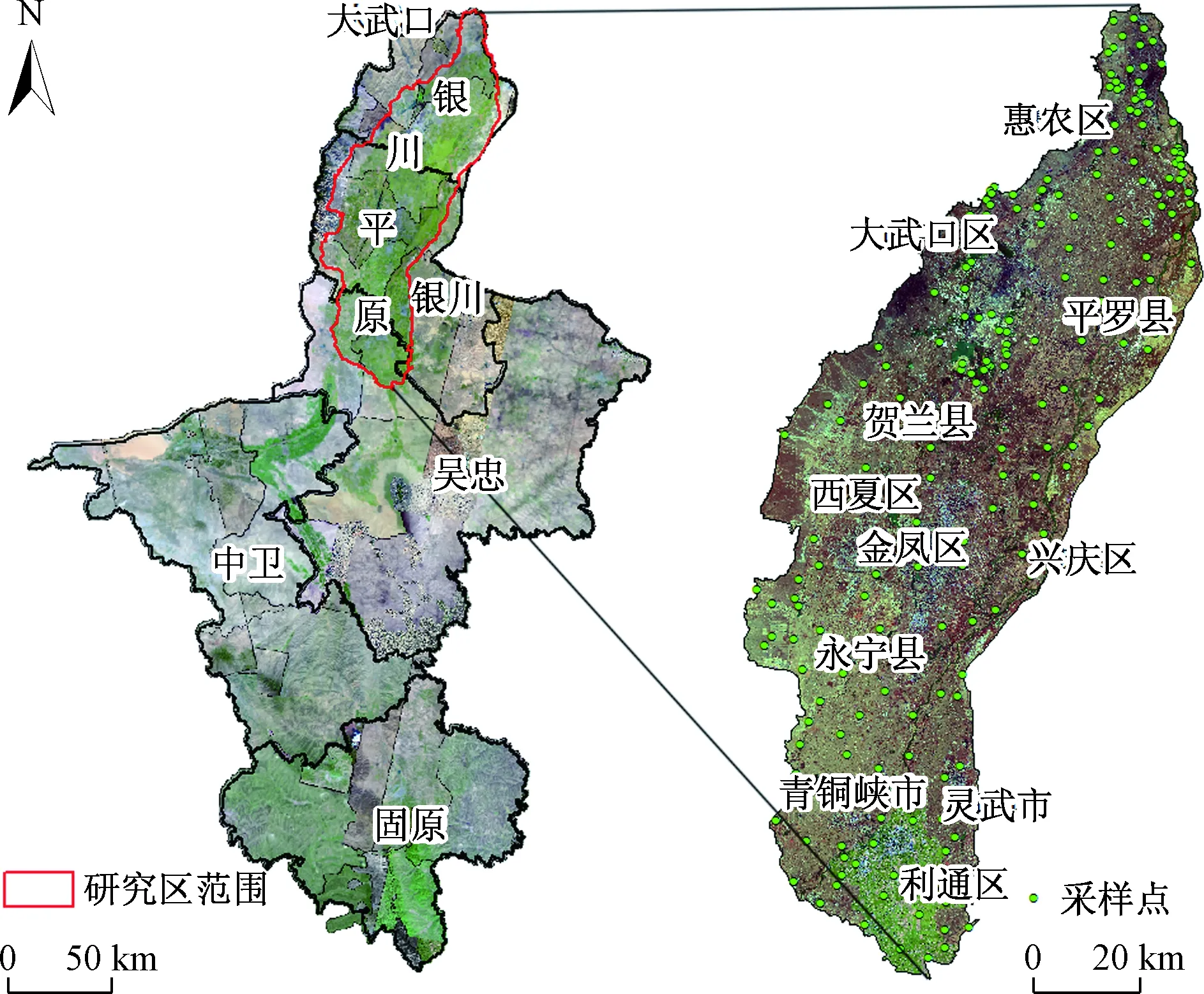
图1 研究区地理位置与采样点分布Fig.1 Location of the study area and sampling points
1.2 数据源
研究使用的遥感影像为Landsat8 OLI数据,分辨率为30 m,具有9个波段,覆盖银川平原共2景数据,影像获取时间为2017年4月30日。对影像进行辐射定标、FLAASH大气校正以及正射校正等预处理,统一对影像做投影变换、镶嵌等处理。植被指数、盐分指数、土壤干旱指数的计算均以Landsat8 OLI遥感影像为数据源,具体计算方法参考文[10~11];参考全国第二次土地调查分类标准,使用eCognition软件,通过面向对象分类与目视解译相结合的方法,调查研究区土地利用类型状况,结合野外实地调查结果评价解译成果的精度为94.5%;地面高程使用ASTER GDEM数据,空间分辨率为30 m;地下水埋深数据采用银川平原2012—2016年共458个测井的地下水静态水位数据,在ArcGIS中选择球面模型进行Kriging[11]处理得到研究区地下水位埋深的连续表面;地下水溶解性总固体数据采用银川平原2010—2016年间共325个钻孔的地下水溶解性总固体数据进行插值计算得到的连续表面。
2 研究方法
本次研究从灾害预测的角度展开,选取6类指标作为模型的预测指标,经过处理形成相应的数字地面模型作为指标数据源。根据野外土壤样点的实测含盐量结果制定训练数据集与检验数据集,根据样点的经纬度提取每个点对应的6类指标值。利用2个数据集对模型进行训练及检验建立SVM神经网络灾害预测模型。最后,将研究区内的预测样本集输入模型中,经模型预测得到分类结果,将分类结果插值后得出银川平原盐渍化预测图,研究的整体流程见图2。

图2 基于异质SVM神经网络的土壤盐渍化预测流程图Fig.2 Flow chart of soil salinization prediction based on heterogeneous SVM neural network
2.1 评价指标的选取与提取
常用的评价指标[13]主要包括:土壤含盐量、土壤水分、植被覆盖度等。在气候干燥蒸发量大、地下水埋藏较浅的地区,地下水中的盐分会随着土壤水分的蒸发不断向地表迁移聚集。当地下水溶解性总固体相同时,地下水位埋深是影响土壤盐分分布的主要因素,水位埋深越浅,土壤盐渍化程度越高;当地下水位埋深相差不大时,高溶解性总固体水分布区土壤盐渍化程度较高。土壤盐渍化的发生会威胁周围的生态环境,地表盐分过度积累会导致植被覆盖度降低、干旱指数升高。综合以上造成土壤盐渍化的原因,本次研究选择地面高程、地下水位埋深、地下水溶解性总固体、植被指数、盐分指数、干旱指数作为模型的预测指标[14]。图3为研究使用的6类指标数据源。
2.2 数据处理
野外采样时间为2017年5月,在研究区内随机采集土壤样本208个,采样时每个取土点用GPS定位并记录经纬度坐标,取表层0~30 cm土壤,剔除土样中的植物茎叶、砾石等杂质,送实验室测定土壤的碱化度,根据土壤碱化度[15]对土壤盐碱化程度进行划分,样点土壤的盐碱化程度分为:1级,非盐渍化(土壤碱化度≤5);2级,轻度(5<土壤碱化度≤15);3级,中度(15<土壤碱化度≤30);4级,重度(土壤碱化度>30)。经实验室测定后,根据土样的盐碱化程度,筛选出108个土壤样本作为本次实验的样本数据集(样点的分布情况见图1),剩余100个样点用作检验预测结果的精度。在SVM神经网络预测模型中,土壤盐渍化的分级情况分别用标签1,2,3,4表示。
从土样中筛选非盐渍化土壤、轻度盐渍化土壤、中度盐渍化土壤、重度盐渍化土壤样本各27个,每一类中17个作为训练样本,另外10个作为检验样本,共计108个样点。在ArcGIS软件中,根据点的经纬度坐标,使用值提取至点工具得到每个点对应的6类指标值,组成训练数据集和检验数据集。
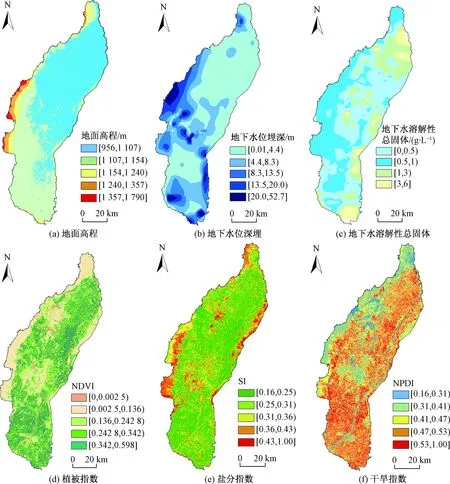
图3 土壤盐渍化评价指标Fig.3 Evaluation indexes of soil salinization
2.3 SVM神经网络分类原理
SVM神经网络[16]的训练方法属于监督学习,原理是建立一个分类超平面作为决策曲面,使得不同类别间的隔离边缘被最大化。算法利用已知点的类别求出它和类别之间的对应关系,利用对应关系将训练集分类,或者预测新的数据集中每个点对应的类别。SVM算法的关键是构造支持向量x(i)和输入空间抽取的向量x之间的内积核,SVM神经网络原理是由算法从训练数据中抽取的小的子集构成的,K为核函数。最大隔离边缘在二维分类中被称为最优分类线,推广到多维分裂问题中为最优分类面,使得分类间隔最大。二维分类是容量为n的训练样本集{(xi,yi),i=1,2,…,n}由2个类别组成,xi为第一类,yi为第二类,设xi=1,yi=-1。设分类超平面为:
(1)
可知平面wTxi+b=1和wTxi+b=-1为该分类问题的分类超平面,转化为求超平面的参数:

(2)
依据拉格朗日对偶论转化为对偶问题,求得的最优解为:

(3)
其中,xr和xs为两个类别中任意的一对支持向量,求得最优分类函数为:
(4)
式中:ai*、b*——最优化过程求解的参数;
yi——类别标签;
K(X,xi)——核函数,当核函数采用线性(Linear)、多项式(Polynomial)、径向基核函数(Radial Basis Function)等不同算法时,SVM神经网络被称为异质SVM神经网络。
3 模型的建立和结果
使用Matlab R2013a软件编程[17]建立基于SVM神经网络的土壤盐渍化预测模型。首先,将训练样本输入模型中对SVM神经网络进行训练,然后选取适当的核函数与参数提升分类器的性能[18],验证分类器精度是否满足实验要求,最后将研究区内随机样点数据输入模型,得到预测结果。核函数与参数的选取对模型预测精度有着直接的影响,是本次建模过程中的关键步骤。
3.1 参数选取
核函数和参数c、g是SVM模型的重要参数,SVM神经网络计算精度与核函数及参数c、g的选择有着直接关系[19]。常用的核函数有线性、多项式、径向基核函数3种,本文分别使用3种核函数对SVM模型进行测试,结果显示3种核函数的准确率分别为70.4%、82.7%和89.6%,准确率最高的核函数为径向基核函数,线性核函数准确率最低。因此,选定径向基核函数为该模型的核函数。
参数c、g的取值是通过交叉验证(Cross Validation,CV)计算得出的,实验使用的CV[20]方法包括:H-CV,K-CV和LOO-CV,分别得出3组c、g值。用RBF核函数与3组c、g参数配置SVM神经网络得到3种模型,将检验样本输入模型中对3种分类器的精度进行验证。分类器的分类精度如表1所示,“实际类别”代表实验室测出的盐渍化类别的对应标签,“预测类别”代表SVM分类器预测的盐渍化类别的对应标签,当预测类别与实际类别相同时,代表预测结果与土壤盐渍化真实情况一致,说明SVM分类器的预测结果正确。3种模型的分类精度分别为85%、75%和72.5%,因此选择分类精度最高的模型作为本次实验的盐渍化预测模型,其参数c=100,g=3。

表1 不同c、g值的模型分类精度对比Table 1 Model classification accuracy with different values of c & g
3.2 分类结果
在研究区内随机且尽量均匀地选择317个点作为预测样本集,将预测样本集输入具备最优核函数的SVM神经网络中进行预测,得到研究区预测样本集的分类结果。图4(a)为317个随机点的分类结果,纵轴1~4类别标签分别对应土壤盐渍化程度由非盐渍化—重度的等级。在ArcGIS中选择Natural Neighbor[2]方法对分类结果做插值处理,得出研究区的土壤盐渍化程度预测图(图4b)。使用ArcGIS的空间统计功能对4类盐渍化土壤的面积进行统计,结合自然资源状况(图4c)对研究区盐渍化分布情况进行综合分析,结果表明:非盐渍化土壤主要分布在研究区西边的贺兰山周边、利通区以及青铜峡地区,该地区地下水位埋藏较深,地物类型以草地为主,盐渍化土壤几乎未见分布;轻度盐渍化土壤面积约854.08 km2,主要分布在黄河滩涂及耕地周边,该地区植被覆盖度高,干旱指数较低,灌溉方式主要为引黄灌溉,由于地势较高排水顺畅,农田土壤不易积累过多盐分;中度盐渍化土壤面积约985.52 km2,主要分布在研究区中北部,东部的中度盐渍化土壤沿黄河滩涂分布,西部的沿贺兰山呈带状分布,惠农及平罗的部分地区在开垦耕地时破坏土壤覆盖的原生植被导致植被覆盖度较低,干旱指数多在0.42~0.48之间,土壤水分消耗的增加导致土质盐分增多,盐渍化程度较高;重度盐渍化土壤面积约231.97 km2,主要在平罗县西大滩、银川芦花和吴忠苦水河地区的耕地周边呈点状集中分布,该地区地势低洼、地下水溶解性总固体高埋藏浅且易渗出地表,植被覆盖度低,干旱指数集中在0.62~0.89之间,由于农业耕种过程中人为填埋排水沟,造成农田排水不畅导致土壤盐分积累,农业灌溉后残余田间的水难以排出,加之强烈的蒸发作用,引起土壤表面盐分聚集,盐渍化程度严重。
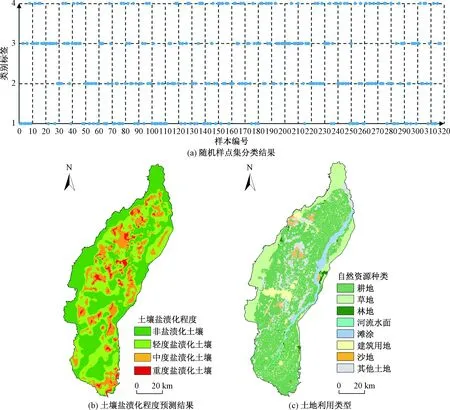
图4 分类结果Fig.4 Classification results
3.3 精度验证
以野外采集的100个土壤样本的实际盐渍化类别的对应标签作为横坐标,以模型预测得出的盐渍化类别的对应标签为纵坐标,求实际值与预测值之间的相关系数,R2为0.834,表明模型预测精度较高,满足本次研究的预测精度。

图5 样点土壤盐渍化实际类别与测试类别的关系Fig.5 Actual category and test category of the sample soil salinization
不同盐渍化程度的点密度也可用于评估区域土壤盐渍化危害的合理性。对银川平原非盐渍化、轻度、中度、重度4类盐渍化分区的灾害点数量及面积进行统计(表2),计算不同分区的灾害点密度,结果表明从非盐渍化区域到重度盐渍化区域,灾害点的密度呈增加趋势,重度盐渍化区灾害点密度为0.172是所有类型中密度最大的,表明研究区域内土壤盐渍化灾害等级分布合理。
4 结论及建议
本研究使用6类引发土壤盐渍化的指标,选取野外实测样本,利用SVM神经网络模型对银川平原土壤盐渍化的分布情况及潜在发展趋势做出预测,结果表明:
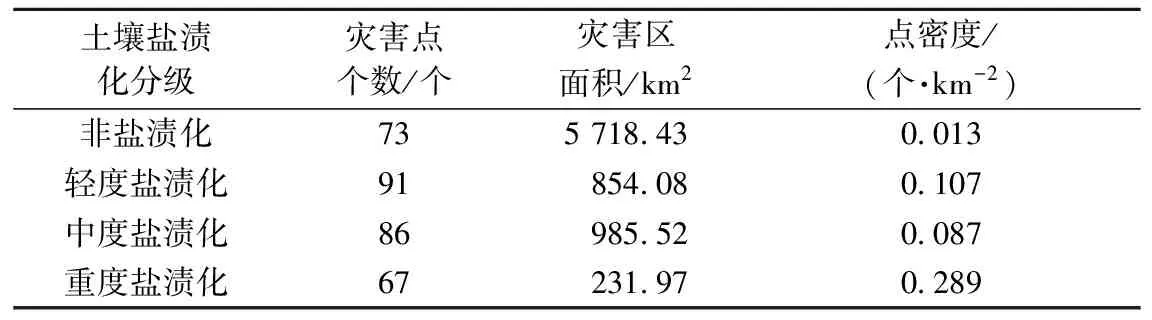
表2 四类盐渍化程度灾害点统计Table 2 Severity of salinization in 4 categories
(1)模型建立过程中,实验验证了3种核函数,结果显示径向基核函数对计算精度影响最大,当c=100、g=3时,整个模型的预测正确率最高可达85%。
(2)非盐渍化土壤主要分布在研究区西边的贺兰山周边、利通区以及青铜峡地区;轻度盐渍化在银川平原分布广泛,面积约854.08 km2,集中分布于吴忠、青铜峡、灵武地区;中度盐渍化在银川平原分布较广,北至惠农地区南至石灵武地区,面积约985.52 km2;重度盐渍化主要集中在平罗、惠农、石嘴山地区,面积约231.97 km2。
(3)银川平原土地利用类型主要以耕地资源为主,预测结果表明多数盐渍化土壤分布在耕地中,其中盐渍化土壤面积占耕地面积的51%,中度与高度盐渍化土壤面积占耕地面积的30%。由此可见,银川平原的土壤盐渍化程度已较为严重,加之耕地种植结构单一,降低了耕地对土壤灾害的抵抗力,因此在农业种植中应注重植被的丰富度。同时,应注重耕地的合理灌溉与排水,增加土壤的可持续利用性,减少次生土壤盐渍化灾害发生。此外,经野外实地考察发现,国家“十二五”期间盐碱地治理效果显著,应延续其治理方法。
基于SVM神经网络建立预测模型对银川平原土壤盐渍化程度进行了预测,实验结果表明,有效的指标数据是提高预测精度的关键,然而研究区内近年数据更新不及时导致数据获取的难度增大,以往的数据相对现在的实际状况可能已发生变化,影响了模型的预测精度,今后应注重指标数据的更新。
猜你喜欢
农业知识(2022年9期)2022-10-13
资源信息与工程(2021年5期)2022-01-15
湖北农业科学(2020年23期)2020-12-30
矿产勘查(2020年11期)2020-12-25
电子制作(2019年19期)2019-11-23
民族古籍研究(2018年1期)2018-05-21
重型机械(2016年1期)2016-03-01
新校长(2016年8期)2016-01-10
大连工业大学学报(2015年4期)2015-12-11
浙江大学学报(工学版)(2015年1期)2015-03-01
