
Name Relevance and Contact Opportunity-Based Routing Strategy for Mobile Content Sharing
2018-10-10 06:27ChaoLiWeiHeandHuimeiLu
Chao Li, Wei He and Huimei Lu
(School of Computer Science and Technology, Beijing Institute of Technology, Beijing 100081, China)
Abstract: With the rapid advancement of smart devices and mobile computing technologies, content sharing in dynamic wireless networks is in substantial demand. To address this problem, in our former work, we presented the Delay/Disruption-tolerant Mobile Content Sharing Network (DMCSN). In this paper, we further examine the routing strategy under the DMCSN framework. We first design the composite interest for organizing user interests. Then, an interest routing strategy based on incremental name relevance (IRINR) and a content routing strategy based on incremental contact opportunity (CRICO) are devised to correspond to the two stages of the content acquisition process: the spreading of the interests and the returning of the contents. Our simulation results validate the following: first, the composite interest can reduce redundant dissemination of content; second, matching of interests and contents are accomplished in a more cost-effective manner under the guidance of IRINR compared with baseline methods; and finally, the integration of IRINR and CRICO achieves a good balance between cost and performance.
Key words: opportunistic routing; content-based; name relevance; contact opportunity; composite interest
Mobile devices have become indispensable in people’s common daily lives because of their portability, versatility and computational capability. However, most mobile users still rely on cellular or Wi-Fi connection to obtain content and rarely share it among peers. On the one hand, free public hotspots are seldom available outdoors, so users usually have to be charged for a large amount of data traffic. On the other hand, a considerable amount of content may reside in devices of neighboring ones, and non-private contents could be made public for sharing, such as news, weather reports, announcements, and so forth. Currently, these massive and diversified resources are not fully exploited. In addition, the limited communication range and inherent mobility of mobile devices make the connectivity in the network constructed by such devices highly intermittent, which is quite challenging for content routing and exchanging. Moreover, although users can utilize device-to-device communication methods, e.g. Bluetooth and Wi-Fi direct, to contact with neighboring people, procedures of content discovery and connection establishment are not automatic.
To provide a solution to this issue, in our previous work[1], by borrowing properties inherited from the Delay/Disruption Tolerant Network (DTN) as a remedy to highly dynamic network conditions and combining the emerging concept of content-centric networking, we proposed the Delay/Disruption-tolerant Mobile Content Sharing Network (DMCSN) to enhance collaboration among multiple devices in content sharing. The key features of DMCSN are listed below.
①Each piece of content possesses a name. Users can request the content by name, thus eliminating the need to know the explicit owner of the content.
②Content body and information in bundle header are stored separately without independent bundle encapsulation to avoid redundancy and alleviate pressure on the buffer.
③Previous transmissions can reduce costs for later requests, because they leave replicas on intermediate nodes. Requesters can fetch one of the replicas nearby, not necessarily from the source. In this way, contents in the buffer are far more valuable and users could expect to spend less time on waiting.
④Two phase routing methods, namely, interest and content routing, are more appropriate and effective for content request, matching, and delivery.
⑤Integration of transmission inits is supported to save link capacity.
In this paper, we further develop an enhanced routing protocol for the DMCSN framework. Our chief focus is to incorporate and utilize the characteristics of content naming and two-phase routing to achieve better performance. To this end, we devise two separate strategies: the first is interest routing based on incremental name relevance(IRINR), which is responsible for matching content based on interest at low cost, and the second is content routing based on incremental contact opportunity (CRICO), whose task is to effectively pass content back to the requester.
The remainder of this paper is organized as follows. In Section 1, related works are outlined and discussed. In Section 2, we first describe the naming convention based on attribute-value pairs and demonstrate how it works in representation and matching; then we elaborate the IRINR and CRICO routing strategies. Experimental evaluations and correlated analysis are given in Section 3. Finally, we end the paper with the concluding remarks in Section 4.
1 Related Works
Content sharing has attracted significant attention from scholars over the past few years. As reflected in these works, most proposals on the Internet or MANET agree on some assumptions, such as stable connections and periodic information exchanging for maintaining status and knowledge of the network. But these assumptions are often violated in mobile wireless scenarios in which, due to active mobility of participating nodes, the publisher and consumer of a content cannot be expected to establish an end-to-end connection under all circumstances. So the “publish/subscribe” paradigm, which decouples the request and content dissemination both temporally and spatially[2], is more suitable for mobile environments where the contacts of nodes are sporadic and intermittent.
Routing protocols based on the pub/sub model in opportunistic wireless networking are well studied by numerous researchers. Context-based methods, as represented by Refs.[3-4], emphasize the social or contact relationship of users and consider them as the solid bases for determining a better carrier. However, context-oblivious methods, such as the one discussed in Ref.[5], do not need much knowledge about surroundings or the neighboring nodes, nor do they require a data collection phase. Meanwhile, past works like Ref.[6] and Ref.[7] use content popularity as the central metric. Each interest explicitly specifies a demanded piece of content, and this one-on-one relationship is the foundation of calculating content popularity. As it can be seen, the relationship of multiple interests and contents are not taken into consideration. In our work, a more flexible relevance between interests and contents can be quantified and exploited. Of these, Ref.[8] proposes an agent-assisted method, which utilizes nodes that could discover or retrieve content more easily to provide services for others. We can learn that the majority of the aforementioned routing protocols still rely on address to perform routing, i.e., they always try to track the specific nodes instead of seeking desired contents, which is proven to be inefficient for distributed content sharing[9-10].
Haggle[11]is a search-oriented framework, in which content and interest can be described by users by attaching flexible “attribute-value” labels to them. All labels form a relation graph as the foundation of local search operations. The proportion of matched labels represents the relation strength. Here, the interests of nodes can be learned by far-away counterparts through dissemination. Clearly, the relationship between nodes is quite concentrated on content, and this represents a major difference from traditional routing proposals. In the current work, we are interested in following this new content-centric approach to design an appropriate routing strategy.
Despite numerous advantages achieved through the principle of “content from anywhere”, such as fast fetching of popular contents and the optimization of bandwidth consumption, the new approach also makes the network susceptible to new cache- and content-based attacks. This problem, also known as “content poisoning”, jeopardizes the safety of users and causes harmful effects to the network. Although it is beyond the scope of this study to solve this problem, reviewing related solutions on attack mitigation is still a noteworthy subject as it may be a chief concern of readers and a future working direction of us.
A basic and passive method for addressing such a problem is by incorporating a signature in packet[12]. A user can clearly be aware of whether or not the received content is trustworthy by simply verifying the signature using the public key of the producer. However, this method only protects users, to some extent, by enabling them to distinguish and discard poisoned contents. Due to the caching nature of the networking, the contents still exist in the intermediary caches and, if not handled properly, these will be served continuously to more victims. Therefore, more proactive methods are proposed. In Ref.[13], upon detecting poisoned content, nodes will propagate a feedback message upstream to warn the others. Then, the path to the poisoned content is treated as a bad choice. In Ref.[14], a ranking algorithm for cached contents is applied based on statistics collected from consumers. Apart from user reports, other studies theorized that routers or intermediary nodes can undertake inspection jobs along with forwarding. However, performing on-the-fly checking of every packet is a computationally heavy and time-consuming task. To reduce the overhead, Ref.[15] only performs verification on popular content and Ref.[16] employs probabilistic verification during the data packet forwarding process. Furthermore, Ref.[17] notes that well-designed caching strategies also have effects on relieving poisoned content attacks. In delay-tolerant networks, where the network topology is highly dynamic, it is even more difficult to control poisoned contents. In Ref.[18], a node tries to detect poorly behaving nodes by observing the suspicious activities of its neighbors. If a node is considered to be malicious, it will be quarantined, i.e. others will cease to connect with it in the future.
2 Name Relevance and Contact Opportunity-Based Routing
2.1 Composite interest
Interest is an important indicator in content dissemination, as it allows nodes to be aware of the needs of others and forward contents accordingly. In our design, users can express their interests or describe features of contents via attribute-value pairs, and the attribute field can be left empty. The name of interest or content consists of a series of such pairs. We do not assign priorities to pairs and treat them equally for simplicity. We take this flat naming scheme mainly because of two reasons. First, it can provide the flexibility allowing users to show their requirements through arbitrary keywords. In this way, the well-known taxonomy of contents does not become a mandatory prerequisite. Second, the compactness and conciseness of the flat naming scheme are expected, because the name information are carried in each bundle header in forwarding process. Once a name is assigned to a piece of content at the source node, it will stay unchanged unless some modifications are made to the content body. In this way the purity of names is kept and the computational complexity is reduced. This aspect is different from Haggle in which anyone can put labels on content at will.
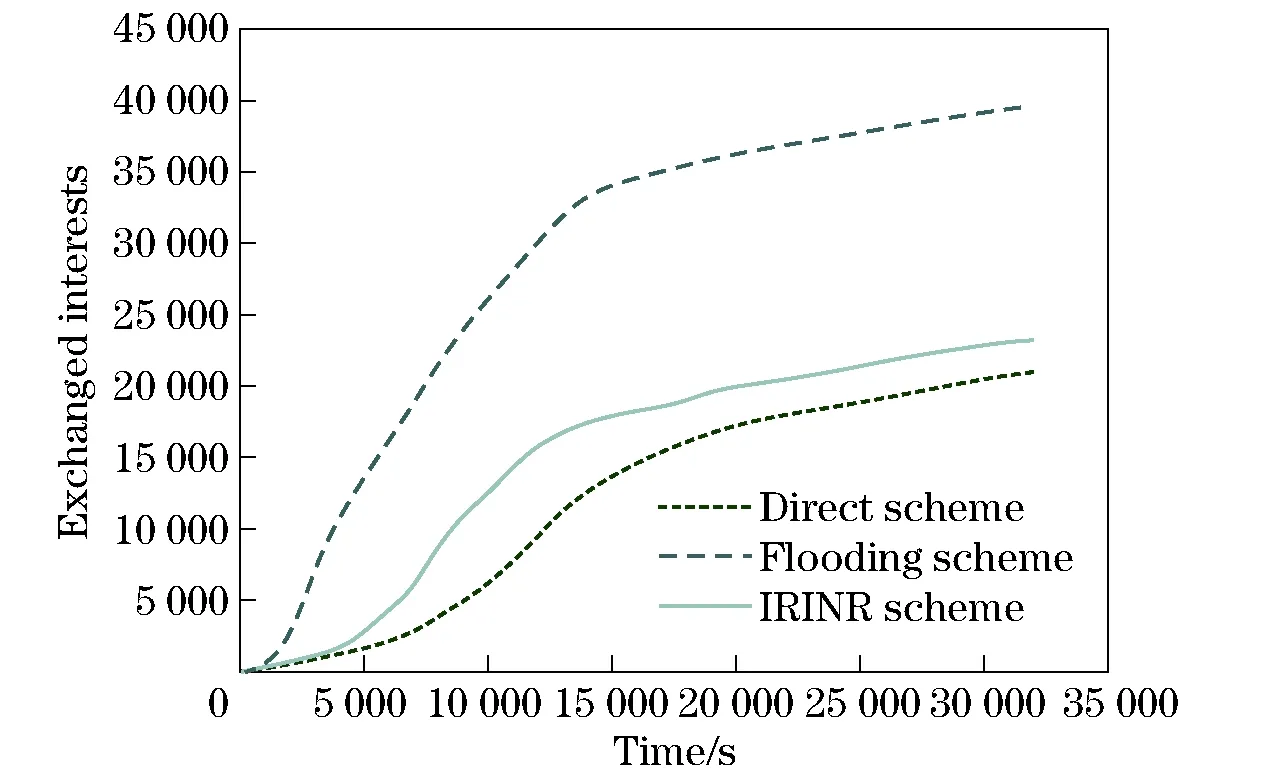
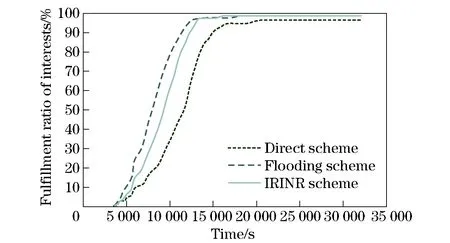
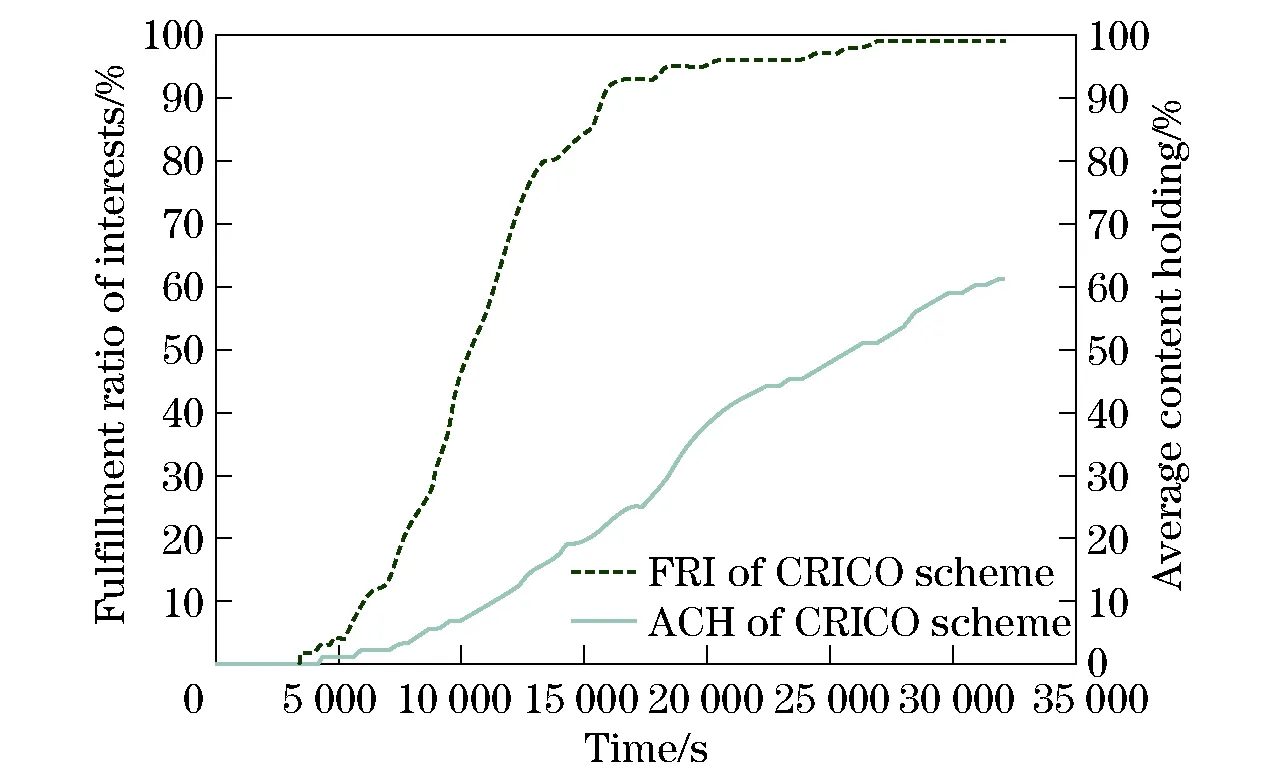
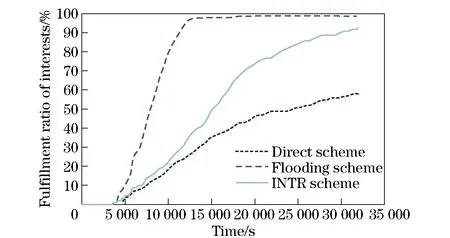
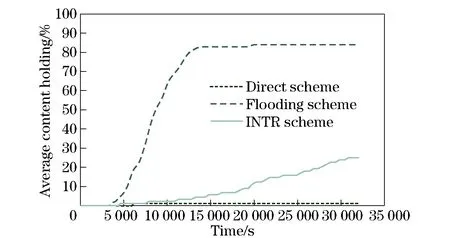
However, as the number of requests increases, the interest units are produced in greater quantity. Even after a content is delivered to the requester, corresponding interests would not disappear if they are not yet expired or removed deliberately. This will continuously incur more redundant transfers. It would be quite difficult and implausible to locate all of them and inform owners to remove them immediately under a distributed situation. To alleviate this problem, we propose the concept of “composite interest”. From the viewpoint of form, as Figs.1-2 shown, this is an aggregation of all valid single interests of a node. Using the composite interest, we are able to express multiple individual interests at one time. Hence, the transmission times of interests can be reduced and the local management of interests is much easier. More importantly, the composite interest can function implicitly as a notification message of invalidation. For example, if composite interestP1, which consists of single interestI1andI2, comes at timeT1, then later,P2comes containingI1andI3atT2(T1 Fig.1 Structure of single interest Fig.2 Structure of composite interest Fig.3 Structure of response content We define the metric as “name relevance” to measure the matching degree between two objects, one of which can be either an interest or a content. For example, if the name of interestIaisnaand the name of contentCbisnb, then the name relevance is calculated as (1) which yields a value between 0 and 1. The bigger the value is, the stronger the relation between the interest and content. The cardinality of the name is the number of “attribute-value” pairs it includes. Meanwhile, the result of the intersection is the number of pairs that the two names have in common. Next, we extend the equation to calculate the relevance between two objects containing multiple name entries as Algorithm 1. Algorithm1Calculation of relevance between two composite interests repeat rAB←rAB+(1-rAB)ri,∀ri∈T T←T-{ri} untilTis ∅ The setRis defined as R={rij|rij=f(ni,nj),∀ni∈A,∀nj∈B} (2) To acquire content, a node should initially announce its interests to let others know what it actually demands. In our strategy, we provide two ways to disseminate interest to avoid flooding interests to the regions where required contents do not likely exist. The first is by broadcasting beacons which include the interests of the node itself. The beacons are forwarded within 1-hop for neighbor discovery and connection establishment. If the desired contents are found at the direct neighbor, then they can be delivered immediately. The second way is by storing and forwarding the interests of other nodes in a multi-hop manner to largely expand the reachable scope of interests. With the aim of helping improve the proportion of successful matching and controlling the dissemination of interests within a reasonable area, we propose interest routing based on incremental name relevance (IRINR). Our primary goal is directing interests to nodes, including but not limited to, those with demanded contents. The nodes that have highly similar interests or contents are deemed as good forwarders as well, because they share common preferences and also have high possibility to obtain demanded contents in the near future in their neighborhoods. The composite interest can facilitate the finding of such nodes as it can reflect the overall requirements of the source node. Moreover, with the name relevance metric, the interests have more opportunities to approach the regions, in which the contents needed possibly reside, along the direction of increasing name relevance without the location knowledge of node or content. For example, we presume the names of composite interestI1andI2aren1andn2, respectively. Then, according to Eq.(1), the relevance betweenn1andn2is given by (3) If contentC3, whose name isn3, completely matchesI2, it means that (4) Then, we can have n2∩n3=n2 (5) Furthermore, n1∩n2∩n3=n1∩n2 (6) From Eqs.(1) and (6), we have Therefore, we can deduce that p3=r13≥p1=r12 (7) We can conclude that, if the source ofI2getsC3, then the probability thatC3can satisfyI1is greater than the relevance ofI1andI2. This indicates that interests should be forwarded along the direction of higher relevance to approach the expected contents. The procedures of how nodes forward interests to neighbors and how they react to the incoming interests are given in Algorithms 2 and 3. Algorithm2Procedure of forwarding the interests of other nodes in IRINR localInterestList=getLocalInterestList() for eachiin local Interest List do ifi.source ≠ localNode then neighborInterest = getInterest(currentNeighbor) selfInterest = getInterest(localNode) if relevance(i, neighborInterest) > relevance(i, selfInterest) then sendInterest(i) end if end if end for Algorithm3Procedure of receiving the interests in IRINR incomingInterest = receiveInterest() if localExistInterest(incomingInterest.source) then localInterest = getInterest(incomingInterest.source) if incomingInterest.timestamp > localInterest.timestamp then updateLocalInterest(incomingInterest) updatelocalMatchingRecords() end if end if When two nodes initiate a connection, all local matching records, content digest, and predictions of contacting other nodes will be exchanged. The exchanging of content digest will clarify to both sides what useful contents they could obtain from each other. The content digest is valid only during the current session and will not be passed to the third party. Next, both sides will take the same operations. Here we just take one side to explain. The node will first receive the matching records from the neighbor. For the interest in each record, if the current node has not seen it before or has an older version of it, then an update should be applied. Otherwise, if the interest the current node has is relatively new and the content in the record cannot satisfy any of the interests of the current node, this indicates the matching information provided by the neighbor may be outdated, so the content will not be retrieved. In this way, only contents that can satisfy the latest version of interests can be forwarded. Next, if the content is not stored locally, and if the current node has a higher probability to meet the destination of compared with the neighbor, the content will be pulled back. For those contents that are already present locally, only corresponding matching records will be updated. Matching will also be performed upon the arrival of new content to satisfy the needs of more awaiting interests. To calculate contact opportunity, prediction-based routing methods, which have been extensively studied in DTN research[19-21], can be applied to our framework. However, our method differs from that proposed by Haggle in terms of routing in that Haggle uses an identical method for forwarding interest and content, but here we use separate methods for different purposes. In addition, Haggle considers contents as interests and may misguide them to sources of similar content instead of to the actual requesters. By contrast, we make content gradually come closer to the nodes that really need them. The complete procedure of CRICO is given in Algorithm 4. Algorithm4Procedure of CRICO matchingRecords = receiveMatchingRecords() check ← false for eachrin matchingRecords do incomingInterestInfo = r.getInterestInfo() incomingContentInfo = r.getContentInfo() if localExistInterest(interestInfo.source) then localInterestInfo = getInterest(interestInfo.source) if localInterestInfo.timestamp > incomingInterestInfo.timestamp then check ← true else updateLocalInterest(incomingInterestInfo) end if end if acceptContent ← true if check then if not matching(incomingContentInfo, localInterestInfo) then acceptContent ← false end if end if if localExistContent(incomingContentInfo) then acceptContent ← false end if if acceptContent and hashigherContactProbability(currentNeighbor, incomingInterestInfo.source) then receiveContent(receivedContentInfo) matchingLocalInterests(incomingContentInfo) end if updateLocalMatchingRecords() end for In our experiments, we adopt a modified version based on ONE[22](version 1.4.1) as the simulator. The main function we implemented is the support of content naming. The global parameters and settings are given in Tab.1. Here, we give a brief explanation on the reasoning for these parameters. We assumed that the communication interface that each node is equipped with is a widely used IEEE 802.11g Wi-Fi interface. IEEE 802.11g works at a 2.4 GHz band; it can provide transmission speed of up to 54 Mb/s and transmit at a maximum range of 100 m[23]. However, in reality, the speed and range of the wireless radio are often significantly influenced by the surrounding environment. In order not to lose generality, we set the transmission speed to 25 Mb/s and the transmission range to 30 m. The moving velocity of the nodes is set to 0.5-1.5 m/s, which is the normal speed for walking pedestrians used by numerous past studies[24-26]. The default map of ONE simulator is used, which depicts a section of downtown Helsinki, Finland. Nodes move along roads on the map and Dijkstra’s algorithm is used to calculate the shortest path from the current location to a randomly selected destination according to the shortest path map-based movement model. Tab.1 Experiment parameters and settings We compare our design with two baseline methods (i.e., the direct method and the flooding method)in order to exclude the impact of other algorithms and to discover the real defects and benefits of our work tentatively. In this part, the buffer size is set to infinite to avoid introducing too many influential factors simultaneously. We shall take this factor into consideration in the following part. In the following experiments, we evaluate the different combinations of interest and content routing components as listed in Tab.2 extensively and present the temporal result analysis. The effectiveness and cost are two major aspects of evaluating the advantages and disadvantages of routing algorithms. Therefore, we use several metrics in each of them. The description of metrics is shown in Tab.3. The metrics “Efficiency of Content Dissemination”, “Fulfillment Ratio of Interests”, and “Average Content Holding” are defined in the following equations respectively. (8) (9) (10) In these equations,Nfis the number of successfully fulfilled interests,Niis the total number of interests,Ciis the number of content items the nodeiowns,Cis the total number of distinct content items,Nis the total number of nodes, andFiis the forwarded times of contenti(including all replicas). Tab.2 Routing methods for comparison Tab.3 Evaluation metrics In this section, we use the flooding method both as the interest and content routing component to evaluate the performance of composite interest compared with the single interest. As shown in Fig.4, at the beginning, neither content nor interest appears in the network. This results in the ECD being 0 before 1 000 s. During 1 000 s and 1 800 s, no content successfully returns to the requester, so it still remains 0. With the progress of the simulation, this value begins to fluctuate severely at approximately 2 000 s. This can be attributed to the fact that the denominator, i.e., the forwarded times of contents, is too small to resist sudden change. After 3 000 s, this value becomes stable and indicates that the composite interest surpasses the single interest on the ECD for at least 10%. In other words, the redundant transmission of content is reduced, thus the efficiency and the precision of dissemination are enhanced. In the following experiments, composite interest is applied as the default type of interest. Fig.4 Comparison of single interest and composite interest on ECD In this experiment, in order to observe the performance of IRINR, we adopt the flooding method as the content routing component, although we adopt different interest routing methods as the interest routing component. The scheme settings are shown in Tab.4. As shown in Fig.5, with regards the sum of forwarded interests, IRINR is slightly more than the direct scheme and is far less than the flooding scheme. Associating with Fig.6, in which the FRI of IRINR can compete with that of the flooding scheme, we can say that it is fairly cost-effective. Another point in Fig.5 that needs explanation is that, a few interests are already forwarded before 1 000 s. These interests are empty beacons used for discovering neighbors. In another viewpoint, they are special empty interests announcing that their hosts do not desire anythingat that moment. Tab.4 Scheme settings for the comparison of interest routing Fig.5 Comparison of interest schemes on exchanged interests Fig.6 Comparison of interest schemes on FRI In this experiment, we use the prediction model in Prophet[21]as the core of CRICO. We adopt the flooding method as the interest routing component, although we use different content routing methods as the content routing component to clarify the performance of CRICO. The scheme settings are shown in Tab.5. The flooding scheme exchanges contents in an uncontrolled manner; hence, it can reach high FRI in a short time, as shown in Fig.7. Meanwhile, the buffer resource is exhausted rapidly as depicted in Fig.8. Comparatively, the increase speed of the FRI of CRICO is not so fast, but it saves approximately 30%-40% of buffer space, on average. In addition, most of the interests can be fulfilled in an acceptable delay. Take the 60% line in Fig.7 as example, the elapsed time before overall FRI reaches 60% of CRICO is approximately 10 000 s, which is only 30% more than that of the flooding scheme (approximately 6 600 s), and on the other hand is greatly less than that of the direct scheme (approximately 27 000 s). In Fig.9, we bring the results of CRICO on FRI and ACH together and discover that the increase speed on FRI is faster than that of ACH, indicating that a small addition in storage cost can pay more in terms of the successful content deliveries by CRICO. Tab.5 Scheme settings for the comparison of content routing Fig.7 Comparison of the content schemes on FRI Fig.8 Comparison of the content schemes on ACH Fig.9 Comparison of the CRICO scheme on FRI and ACH In this section, we integrate IRINR and CRICO and label it as INTR, to assess their performance as a whole. The scheme settings are shown in Tab.6. Fig.10 illustrates that, with respect to FRI, the flooding scheme still has superiority over other approaches. The INTR also behaves well and has a good trend: it ascends almost linearly under 80% and achieves final results that close to the flooding scheme at the end of the simulation. Figs.11-12 demonstrate that INTR has an effect on controlling overhead. First, the forwarded times of interests are less than a half of those in the flooding scheme, indicating only selected interests are forwarded towards promising directions. Correspondingly, the ACH of INTR is maintained at a very low level, suggesting that redundant content exchange is suppressed and a considerable amount of buffer space could be saved. To summarize, the integration of IRINR and CRICO is effective in achieving a good balance between performance and cost. Tab.6 Scheme settings for the evaluation of INTR Fig.10 Evaluation of the INTR scheme on FRI In this section, we will evaluate the performance of INTR with the constraints of limited buffer size and shorter simulation time,in order to determine whether INTR performs well under these conditions. The scheme settings are the same as those shown in Tab.6 in Section 3.6. The parameters are unchanged as in Tab.1 in Section 3.1, with the exception of the simulation time being reduced from 36 000 s (10 h) to 21 600 s (6 h). The buffer size ranges from 100-200 MB, which we believe is acceptable for most user devices. The replacement policy is to remove the oldest content first. Each experiment is repeated for 10 times with different trajectories of nodes. The result presented is the mean number of all the derived values. Fig.11 Evaluation of the INTR scheme on exchanged interests Fig.12 Evaluation of the INTR on ACH From Fig.13, we can see that the buffer size has great impact on the delivery ratio of the flooding scheme. With the decreasing buffer size, the delivery ratio of flooding scheme declines evidently. The delivery ratio of the direct scheme is not influenced much by buffer size changing because it does not need much buffer resources to work and thus has a relatively low delivery ratio. Notably, the INTR surpasses the flooding scheme when the buffer resource is in a shortage. This indicates that the INTR can utilize limited buffer size with greater efficiency in order to deliver more contents. Meanwhile, augmenting the buffer size has a positive effect on the INTR as the delivery ratio increases gradually with the increase in buffer size. In addition, INTR shows better adaptability to the limitation of buffer size, because the difference of the delivery ratio between the maximum and the minimum buffer sizes is only approximately 7%. Fig.13 Delivery ratio with different buffer sizes In terms of average delay, as shown in Fig.14, the flooding scheme is the lowest among the three schemes. It can be observed that the average delay goes up first and then goes down with the increase in buffer size. This is mainly due to several reasons. ① When the buffer size is small, the stay duration of contents is very short as they are to be replaced soon. As such, those contents that are near the requesters have a higher possibility of successful delivery. Therefore, the average delay is low at the beginning. ② With the increasing buffer size, each node can possess more contents. This makes it possible for more deliveries to be completed at a later time, which contributes to the higher value of the average delay. ③ With the further increase in buffer size, due to the rapidly spreading nature of the flooding scheme, the possibility of demanded contents locating in the local buffer or nearby nodes also increases. Therefore, the average delay keeps decreasing when the buffer size is larger than 140 MB due to such immediate deliveries. The average delay of the direct scheme is also unaffected by variations in the buffer size. For the direct scheme, the buffer size is sufficient and the delay largely correlates with the routes and movements of nodes, for which we use the same 10 sets data across different experiment groups of buffer size. The average delay of the INTR is the highest of all schemes: it keeps increasing gradually as the buffer size increases. From this point, combined with the result of the delivery ratio, we can see that INTR can find and deliver contents efficiently in the long run. The longer delay reveals that, in the INTR, contents that are located far from the requesters or need multiple relays to be found and delivered are well-supported. This point is more clearly observable when the buffer size is limited, as we know that the flooding scheme provides poor support for such far-away contents. This finding validates the correctness of IRINR, as it can find demanded contents in potential directions. The increasing buffer size further strengthens such abilities. Fig.14 Average delay with different buffer sizes Next, we examine the results from the aspect of the amount of content. Tabs.7-8 provide the comparison of the transmitted and removed content amounts, respectively. As can be seen, the flooding scheme has an overwhelming amount of transmitted data, but most of them are removed. The severe turbulence greatly affects the performance of the flooding scheme and leads to wasted link resources when the buffer size is small. In comparison, when the buffer size becomes larger, as stated previously, local or nearby content replicas relieve such phenomena. In the direct scheme, both the transmitted and removed content amounts are extremely low as contents are exchanged in an overly conservative way. Therefore, the direct scheme does not fully utilize the buffer resource. As for the INTR, we can see that the transmitted content amount is only approximately 10% of the flooding scheme, and the removed content amount is only approximately 5% of the flooding scheme. This demonstrates the coaction effects of both the IRINR and CRICO. To avoid a great number of content replicas being generated, IRINR only selectively disseminates interests based on the matching results. Meanwhile, CRICO only forwards contents with a greater delivery possibility to the next hop. The results given in Fig.15 indicate that the average content number possessed by each node in INTR is only a half that of the flooding scheme. This is a reasonable buffer use level for each node, because each node has a number of contents and also needs to simultaneously keep a portion of available space for incoming valuable contents. These results demonstrate the effectiveness of the INTR in controlling the amount of content in the network and its efficiency in maximizing the utilization of limited link and buffer resources. Tab.7 Average transferred content amount with different buffer sizes Tab.8 Average removed content amount with different buffer sizes Fig.15 Average number of contents in each node with different buffer sizes To conclude this section, we briefly review the key findings below. ①The INTR can achieve a better delivery ratio when the buffer size is limited. The overall performance is not influenced greatly by the buffer variance. ② The longer average delay of the INTR reveals that INTR supports multi-hop content finding and delivery processes more efficiently; it does so by sending selected interests towards the potential locations of demanded contents and by exchanging more valuable contents. ③The INTR is more storage-efficient compared with other schemes and is capable of efficiently utilizing the link and buffer resources with less content transfer and dropping. In this paper, based on DMCSN, the framework we have presented for improving content sharing in wireless network, we expanded on our past research by completing several tasks. First, we use the attribute-value pairs to describe the names of interests and contents. This method is flexible and allows us to quantify and exploit the relevance of multiple names. Then, we propose the composite interest structure that is used to express the interests of users. This structure facilitates both transmission and management, while simultaneously serving as an implicit acknowledgement to suppress the redundant transmission of successfully delivered contents. Next, we design the IRINR for the routing of interest. The main feature of the IRINR is that it can lead interests towards potential nodes, which either possess demanded contents or have highly relevant interests or contents, based on the matching results. Finally, we use the classical routing method prophet as the core of CRICO to function as the content routing and combine it with the IRINR to form the complete routing solution, which we call INTR. We obtained several findings from the experiments. First, composite interest can reduce the redundant transmission of contents. Second, the IRINR can effectively guide interests to existing or potential content locations. Finally, the INTR maintains a good balance between cost and performance. It also shows better tolerance on limited buffer size, can provide better support for matching across multi-hop, and is capable of utilizing link and storage resources more efficiently.


2.2 Content matching

2.3 Interest routing based on the incremental name relevance
2.4 Content routing based on incremental contact opportunity
3 Experiments and Results
3.1 Experimental setup

3.2 Evaluation metrics

3.3 Evaluation of the composite interest

3.4 Evaluation of IRINR

3.5 Evaluation of CRICO


3.6 Evaluation of INTR

3.7 Evaluation under limited buffer size and shorter time






4 Conclusions
 Journal of Beijing Institute of Technology2018年3期
Journal of Beijing Institute of Technology2018年3期
- Journal of Beijing Institute of Technology的其它文章
- Simplified Method for Joint Calibration of 3D Ladar and Monocular Camera
- Force Control of Electro-Hydraulic Servo System Based on Load Velocity Compensation
- Identification of Driving Intention Based on EEG Signals
- High-Speed Noise-Based Random Bit Generator by Removing 1/f Noise with Differential Comparison
- Radiometric Calibration Chain Design Based on Uniform Collimated Laser Source
- Numerical Investigation on the Features of Gasoline Mixture Flow Field with Rotary Jet Mixing