
基于卷积神经网络与迁移学习的油茶病害图像识别
2018-10-10 06:33龙满生欧阳春娟
农业工程学报 2018年18期
龙满生,欧阳春娟,刘 欢,付 青
基于卷积神经网络与迁移学习的油茶病害图像识别
龙满生,欧阳春娟,刘 欢,付 青
(1. 井冈山大学电子与信息工程学院, 吉安 343009;2. 流域生态与地理环境监测国家测绘地理信息局重点实验室,吉安343009)
传统的植物病害图像识别准确率严重依赖于耗时费力的人工特征设计。该文利用深度卷积神经网络强大的特征学习和特征表达能力来自动学习油茶病害特征,并借助迁移学习方法将AlexNet模型在ImageNet图像数据集上学习得到的知识迁移到油茶病害识别任务。对油茶叶片图像进行阈值分割、旋转对齐、尺度缩放等预处理后,按照病害特征由人工分为藻斑病、软腐病、煤污病、黄化病和健康叶5个类别。每个类别各选取750幅图像组成样本集,从样本集中随机选择80%的样本用作训练集,剩余20%用作测试集。利用随机裁剪、旋转变换和透视变换对训练集进行数据扩充,以模拟图像采集的不同视角和减少网络模型的过拟合。在TensorFlow深度学习框架下,基于数据扩充前后的样本集,对AlexNet进行全新学习和迁移学习。试验结果表明,迁移学习能够明显提高模型的收敛速度和分类性能;数据扩充有助于增加数据的多样性,避免出现过拟合现象;在迁移学习和数据扩充方式下的分类准确率高达96.53%,对藻斑病、软腐病、煤污病、黄化病、健康叶5类病害的F1得分分别达到94.28%、94.67%、97.31%、98.34%和98.03%。该方法具有较高的识别准确率,对平移、旋转具有较强的鲁棒性,可为植物叶片病害智能诊断提供参考。
病害;分类;作物;油茶病害;图像识别;深度学习;迁移学习
0 引 言
油茶是四大木本油料植物之一,主要产品为茶油,副产品包括茶枯、茶壳和茶粕,具有较高的综合利用价值,在保健、医疗、生物农药、生物饲料、杀菌消毒及化学工业等方面都有广泛的应用[1]。在国家政策的大力扶持下,油茶种植面积不断扩大,但由于粗放经营导致油茶病害频发,严重影响了油茶的产量和品质。危害油茶的病害多达50余种,主要有炭疽病、软腐病、煤污病和藻斑病等[2]。油茶病害的发生受到油茶品种、栽培环境、气候条件和经营管理水平等多种因子综合作用的影响,及时准确识别病害类型是有效防治的关键。大多数植物病害在可见光波段会产生某些可见症状,为人工识别诊断提供了可行性。由于植物病害症状复杂多变,往往需要经过专业训练的植保专家才能准确识别诊断,而对于业余人员则容易出现诊断错误。此外,人工识别诊断植物病害耗时费力并且具有一定的主观性,因此亟需研究植物病害智能诊断系统,提高病害识别准确率。
为了提高病害识别的准确率与效率,研究人员尝试利用图像处理、机器学习等方法自动识别水稻[3-4]、玉米[5]、小麦[6]、棉花[7]、番茄[8]、黄瓜[9-12]、甘蔗[13]等作物病害[5-13]。利用图像处理技术[14]获取目标的颜色[15]、形状[16]、纹理[17]等特征[14-17]后,再利用人工神经网络[18]、支持向量机[19]等方法对病害特征向量进行分类[18-19]。为了减少环境光照对病害检测的影响,常将病害图像由RGB变换到Lab、HSI、YCbCr等颜色空间进行病斑分割。常用的颜色特征主要有颜色均值、方差、峰值、偏度、能量、熵等,形状特征主要有矩形度、偏心率、致密度等,纹理特征主要有基于灰度共生矩阵的对比度、相关性、能量、惯性矩等。
传统的基于机器学习的植物病害识别方法,需要针对病害类型精心设计病害特征。由于植物类型、生长阶段、病害种类、环境光照等因素的影响,导致植物病害症状复杂,特征提取相当困难。卷积神经网络(convolutional neural network, CNN)通过引入局部连接、权值共享、池化操作、非线性激活等方法,允许网络从数据中自动学习特征,比传统机器学习方法具有更强大的特征学习和特征表达能力。CNN在图像分类、语音识别等方面取得了突破,AlexNet[20]和GoogleNet[21]在ILSVRC[22](imageNet large scale visual recognition challenge)图像分类比赛中将分类错误率分别降低到了16.4%和6.7%,VGG[23]和ResNet[24]都取得了较好效果。Mohanty等[25]收集了5万多幅病害图像,涉及14类作物、26种病害,利用CNN将其分为38类的准确率高达99.35%。Sladojevic等[26]在网络上收集了4千多幅病害图像,数据扩充后得到3万多幅图像样本,基于CaffeNet将其分为15类,分类准确率达91%~98%。Brahimi等[27]收集了约1.5万幅西红柿叶片病害图像,基于AlexNet将其分为9类病害,获得了较好的识别效果。孙俊等[28]在PlantVillage植物叶片病害图像数据集的基础上,将AlexNet的全连接层改为全局池化层,并改用批规范化进行训练,降低了模型参数量并提高了模型识别率。Lu等[29]收集了500幅水稻病害图像,构建了一个包含3个卷积层的卷积神经网络,用于识别稻瘟病、稻曲病、稻斑病、稻纹枯病等10种常见的水稻病害,正确识别率达到95.48%。上述研究为利用CNN进行植物叶片病害识别提供了参考和可行性,但CNN的特征学习与分类性能依赖于大型数据驱动,且全新训练非常耗时。2017年11月Google发布了将TensorFlow用于移动和嵌入式设备的轻量级解决方案——TensorFlow Lite,允许快速部署基于预训练模型的智能应用,为基于移动终端的植物叶片病害智能识别提供了可行性。
针对深度卷积神经网络模型训练耗时问题,本文基于经典的AlexNet模型建立了油茶叶片病害图像识别模型,利用迁移学习方法将AlexNet在大型图像数据集上学习得到的图像分类的共性知识迁移到油茶叶片病害识别模型,经过组合试验与对比分析优选模型的超参数,以期提高模型训练效率与识别准确率,为进一步开发基于智能手机等移动终端的油茶病害智能诊断系统提供模型支持,对于辅助油茶病虫害防治决策具有重要意义。
1 试验数据
1.1 病害图像数据集
在江西省永丰县瑶田镇的人工油茶林地采集了藻斑病、软腐病、煤污病、黄化病和健康叶等油茶叶片样本。7-9月为藻斑病的发病盛期,软腐病在15~25℃下发病率最高,煤污病盛行于3-5月和9-11月,黄化病则全年表现黄化症状。根据各种典型病害的发病规律,在为害症状较为显著时从油茶树上采集病害叶片样本。为保持叶片样本新鲜,将采集的叶片样本装入自封袋后带回实验室。在明亮的室内环境(自然光+日光灯)下,将叶片样本展平于白色背景上,利用安卓手机(华为NEM-TL00H,主摄像头1 300万像素)垂直拍摄叶片样本,拍摄距离约20~30 cm。
为了规范化数据集,利用OpenCV编写了图像预处理程序,对叶片图像依次进行如下预处理:
1)将叶片图像由RGB颜色空间转换为HSI颜色空间,基于色度、饱和度信息对病害图像进行阈值分割,去除背景;
2)对分割结果进行半径为3像素的形态学开闭运算,去除毛刺、孔洞等噪声;
3)填充目标区域孔洞,形成目标掩模,并计算油茶叶片目标的二阶矩和主轴角;
4)目标掩模与原始图像进行乘法运算得到彩色的叶片目标,再根据主轴角旋转叶片目标,使其主轴沿水平对齐;
5)以长边为基准,叶片目标按比例缩放为256×256像素。
根据油茶病害症状,将预处理后的叶片图像人工分为藻斑病、健康叶、软腐病、煤污病和黄化病5种类别,分别用0、1、2、3、4表示对应的类别标签,选取每类各750个样本组成数据集,病害示例样本如图1所示。从每类样本图像中随机选择80%(即每类600个样本,共3 000个)用于训练,其余20%(即每类150个样本,共750个)用于测试,分别制作成TFRecord格式的训练数据集和测试数据集。

图1 油茶病害叶片图像示例
1.2 图像数据扩充
为了提高分类准确率,深度卷积神经网络需要大量训练样本。然而,由于病害样本采集比较困难,目前还缺乏大型的病害图像数据集。通过对图像样本进行仿射变换、透视变换、颜色抖动、对比度增强、叠加噪声等操作引入轻微的扰动而实现数据扩充,可以减少训练阶段的过度拟合,从而提升网络的泛化性能。仿射变换包括平移、旋转、缩放、翻转、错切等基本变换,具有平直性和平行性,即变换后直线依然为直线、平行线依然为平行线。通过透视变换可以模拟实际场景的不同视角。
利用OpenCV实现仿射变换的方法如下:
1)指定源图像和目标图像中的3组对应点;
2)利用OpenCV的getAffineTransform函数计算仿射变换矩阵;
3)利用OpenCV的warpAffine函数对源图像应用刚才的仿射变换。
利用OpenCV实现透视变换的方法如下:
1)指定源图像和目标图像中的4组对应点;
2)利用OpenCV的getPerspectiveTransform函数计算透视变换矩阵;
3)利用OpenCV的warpPerspective函数应用刚才的透视变换。
试验中,对训练图像样本应用随机裁剪、随机旋转变换(0°、90°、180°、270°)、随机透视变换(上、下、左、右4个方向)来扩充训练数据集。对于AlexNet模型,将256×256像素的图像随机裁剪成227×227像素,相当于数据集扩充了29×29=841倍。加上随机旋转和随机透视变换,极大扩充了训练数据集的多样性。为了避免变换后的图像严重失真,将透视变换中对应点的位移限制在图像边长的10%以内,目标图像的画布尺寸与源图像保持一致。
2 试验方法
2.1 迁移学习
AlexNet和GoogleNet等深度卷积神经网络模型在图像分类中取得巨大成功,在大型图像数据集ImageNet上获得了充分训练,学习到了图像分类识别所需的大量特征。因此,可以运用迁移学习思想[30],充分利用AlexNet、GoogleNet等预训练模型在ImageNet数据集上学习到的大量知识,将其用于优化油茶病害图像分类识别问题。一种常用的迁移学习方法是特征迁移,去掉预训练网络的最后一层,将其之前的激活值(可看作是特征向量)送入支持向量机等分类器进行分类训练;另一种是参数迁移,只需重新初始化网络的少数几层(如最后一层),其余层直接使用预训练网络的权重参数,再利用新的数据集对网络参数进行精调。本文采用参数精调的迁移学习方式,将AlexNet修改为用于油茶病害识别的AlexNet_Camellia(AC)。相比于全新学习(即随机初始化网络所有层的权重参数,利用训练数据集对网络从头开始全新训练),精调有助于网络快速收敛。
2.2 模型结构
AC模型采用AlexNet模型结构,由5个卷积模块和3个全连接模块堆叠而成,最后1个全连接层的输出数为5,对应目标类别数,采用SoftMax计算损失,如图2所示。卷积模块conv1和conv2均是由卷积层、局部响应归一化层(local response normalization, LRN)、最大池化层组成,卷积模块conv5由卷积层和最大池化层组成。全连接模块fc6和fc7均包含了dropout层,在训练时随机丢弃一些连接,参照AlexNet,丢弃概率设为0.5。池化降采样保持了一定的平移不变性,重叠池化、dropout减轻了过拟合[20]。神经元的激活函数采用线性整流函数(rectified linear unit, ReLU),其单侧抑制特性使得神经元具有稀疏激活性,可以有效解决梯度弥散,有助于加速网络收敛。
2.3 模型优化
网络模型优化的实质是迭代最小化损失函数的过程。本文采用随机梯度下降法(stochastic gradient descent, SGD)来实现模型优化,学习率更新策略采用指数衰减法。训练初始阶段设置较大的学习率,以期快速到达最优解附近,随后逐步降低学习率,避免因学习率较大而产生激烈振荡。指数衰减法的学习率更新见式(1):

式中为衰减后的学习率,0为初始学习率,d为衰减系数,为当前的迭代次数,d为衰减步长(即每迭代指定次数更新一次学习率),ëû表示向下取整。
采用交叉熵计算分类损失,附加L2正则化对权重参数进行惩罚,以减轻过拟合现象。损失函数见式(2):
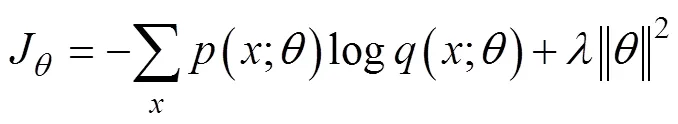
式中为训练损失,为权重参数,为正则项系数,为批次训练样本,为期望的类别概率,为模型预测的类别概率,类别概率由Softmax计算。
注:输入层的图像尺度为227×227像素;卷积层conv1~conv5的卷积核数目分别为96、256、384、384、256,卷积核大小分别为11×11、5×5、3×3、3×3、3×3像素,滑动步长分别为4、1、1、1、1,填充类型分别为VALID、SAME、SAME、SAME、SAME;池化层pool1、pool2、pool5的池化类型均为最大池化,核大小均为3×3像素,滑动步长均为2,填充类型均为VALID;全连接层fc6、fc7、fc8的输出单元数分别为4 096、4 096、5;卷积层、全连接层的激活函数均为ReLU。
Note: Image shape of input layer is 227×227 pixels; For conv1, conv2, conv3, conv4, and conv5 layers, the number of convolution kernels are 96, 256, 384, 384, and 256 repectively, convolution kernel size are 1×11, 5×5, 3×3, 3×3, and 3×3 pixels respectively, strides are 4, 1, 1, 1, and 1 respectively, and padding type are VALID, SAME, SAME, SAME, and SAME respectively; For pool1, pool2 and pool5 layers, pooling type is max, kernel size are 3×3 pixels, strides are 2, padding type are VALID; Output units of fc6, fc7 and fc8 layers are 4 096, 4 096 and 5; Activation fuctions of all convolution and fully connected layers are all ReLU.
图2 油茶叶片病害识别模型
Fig.2 Recognition model forleaf disease
3 结果与分析
3.1 模型训练与测试结果
模型训练与测试均是在TensorFlow框架下完成的。硬件环境:Intel Xeon E5-2643v3 @3.40GHz CPU, 64GB内存;Nvidia Quadro M4000 GPU,8GB显存。软件环境:CUDA Toolkit 9.0,CUDNN V7.0;Python 3.5.2;Tensorflow-GPU 1.8.0;Windows 7 64bit操作系统。
模型训练与测试均通过GPU加速。综合考虑硬件性能和训练时间,测试和训练的批次样本数均设置为50。测试间隔和显示间隔均设为1个epoch(执行完1次全部训练样本,称之为1轮),快照保存间隔设为50个epoch,最大训练轮数设为300个epoch。参照经典AlexNet模型[20]的参数设置,综合考虑试验复杂度,组合2种学习方式(全新学习、迁移学习),3种数据扩充方式(无扩充、随机裁剪、随机裁剪+随机透视+随机旋转),3组正则项系数(0、0.000 5、0.001),3组初始学习率(0.001、0.005、0.01),共进行54组组合试验。
全新学习时,网络模型的权值参数初值用均值为0、标准偏差为0.01的截断正态分布随机生成,在(-2,+2)区间内取值,保证了其值在均值附近,偏置参数则初始化0。
迁移学习时,fc8层的权值参数与偏置参数按上面的方式随机初始化,其他各层的与则从在ImageNet图像数据集训练得到的AlexNet模型中加载。AC模型经过300轮训练后,各组试验的训练与测试结果如表1所示。
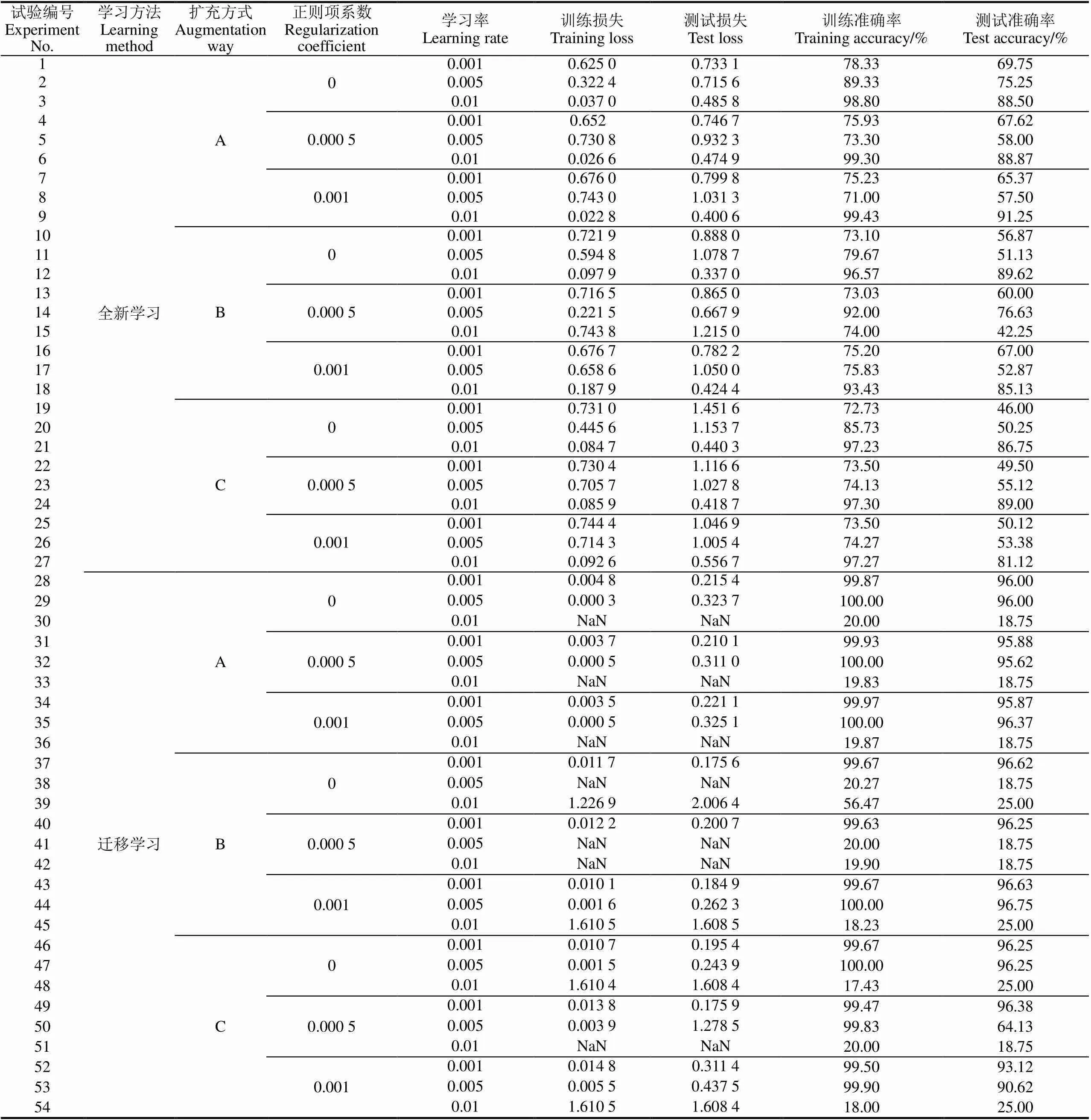
表1 模型训练与测试的损失及准确率
注:A、B、C为数据扩充方式,A—无扩充,直接将输入图像由256×256像素居中裁剪为227×227像素;B—将输入图像由256×256像素随机裁剪为227 ×227像素;C—先随机裁剪为227×227像素,再进行随机透视变换,最后随机旋转0°、90°、180°或270°。NaN表示因训练发散导致损失无穷大。训练轮数为300。
Note: A denotes no data augmentation, where input images are centrally cropped from 256×256 pixels to 227×227 pixels; B denotes that input images are randomly cropped to 227×227 pixels; C denotes that input images are fist randomly cropped to 227×227 pixels, then random perpective transformation is performed, and images are finally randomly rotated 0°, 90°, 180°, or 270°. NaN indicates training divergence resulted in infinite loss. Training epochs are 300.
3.2 模型性能的影响因素分析
3.2.1 学习率对模型性能的影响
训练过程中,学习率按照公式(1)呈阶梯式指数衰减。参照TensorFlow的默认值,结合试验经验,衰减系数设为0.9,衰减步长设为10轮,即训练过程中每10个epoch调整一次学习率。在迁移学习方式下,与fc8层相比,其他层均已得到充分训练,训练时只需微调,因此根据经验将fc8层的初始学习率设置为其他层的10倍。
由表1可知,学习率对训练与测试结果影响较大。在全新学习方式下,由于所有层的参数均是随机初始化,较大的学习率可以使得训练快速接近最优解,因而在相同的训练轮数下可以获得更高的训练准确率和测试准确率。例如,第9组试验,初始学习率为0.01,经过300轮训练后,训练与测试准确率分别达到99.43%和91.25%,比相同条件下的其他学习率试验高出约20~30个百分点。然而,如果初始学习率设置不当,将导致训练振荡甚至发散,如图3。全新学习方式下,初始学习率为0.005的几组试验(试验编号为2、5、8、11、14、17、20、23、26)均出现了如图3a所示的振荡。
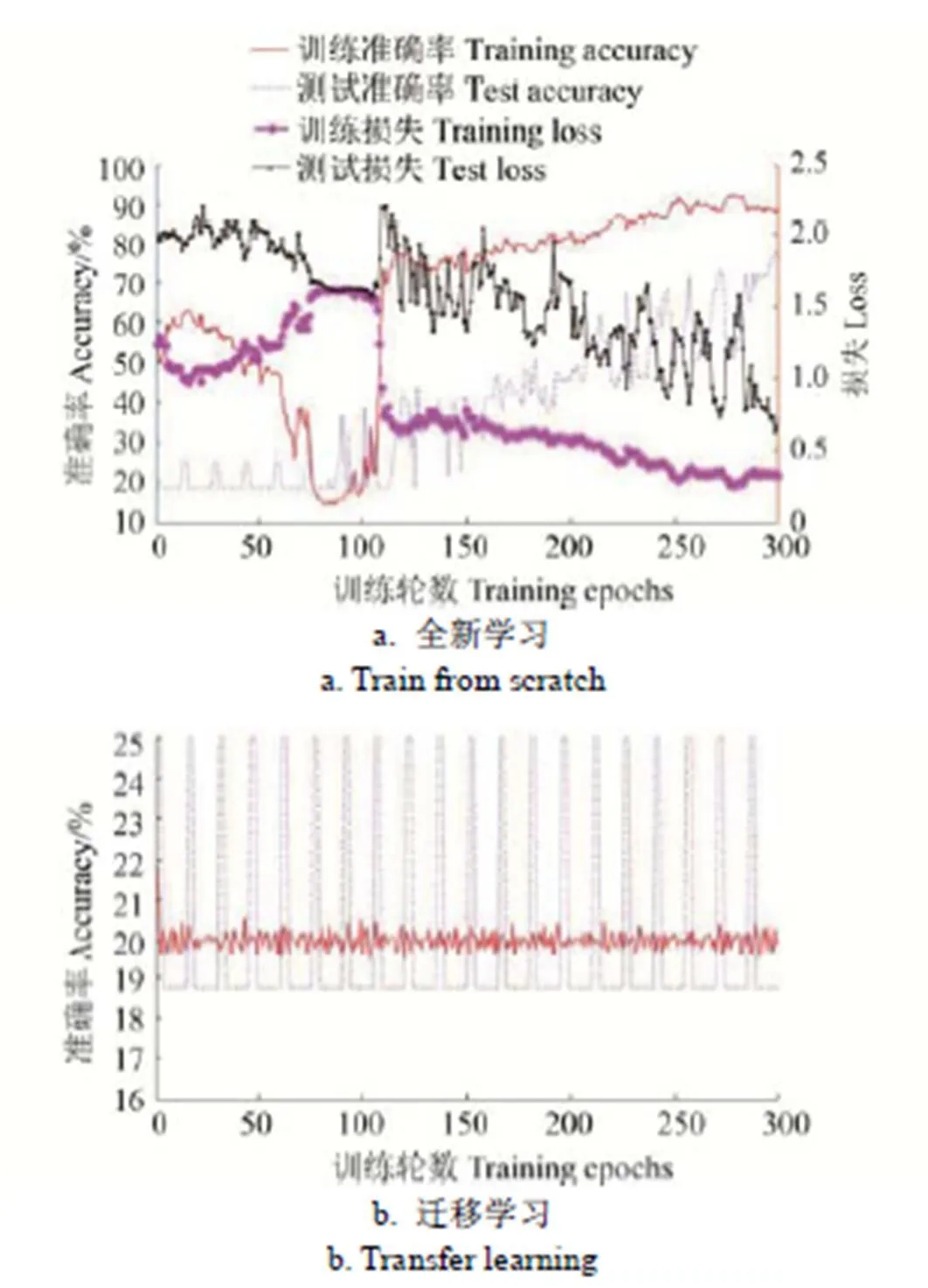
图3 学习率设置不当情形下的损失及准确率曲线
在迁移学习方式下,由于网络前端各层均已获得良好训练,训练初始时刻已接近最优解,使用较大的学习率容易导致跳过最优解,从而产生较大的损失、较低的准确率或剧烈振荡。学习率为0.01的各组试验(试验编号为30、33、36、39、42、45、48、51、54)以及学习率为0.005的2组试验(试验编号为38、41)均产生了剧烈的周期性波动,训练与测试准确率均只达到随机猜测水平,部分试验因训练过程发散而导致训练损失无穷大(NaN值),如图3b所示。学习率为0.001的各组试验(试验编号为28、31、34、37、40、43、46、49、52)则表现出了良好性能,训练300个epoch后的测试准确率高达96.63%。经验表明,迁移学习方式的初始学习率取为全新学习方式的1/10或1/100,一般能取得比较好的训练效果。
3.2.2 正则化对模型性能的影响
本文采用L2正则化,通过在损失函数中添加对权重参数的惩罚项(公式(2))来降低权重参数引起的过拟合。试验中,通过设置3组正则项系数(0、0.0005、0.001)来依次强化对权重参数的惩罚。由表1可知,在全新学习方式下,当进行数据扩充和以低学习率训练时,正则化可以提高测试准确率约4~10个百分点(如编号为10、13、16与19、22、25的试验);而其他情形下则表现不稳定(如编号为12、15、18的试验),原因在于正则化无法克服高学习率下训练波动的影响。在迁移学习方式下,正则化的影响则很微弱,原因在于预训练模型的权重参数已获得良好训练而降低了因较大权重参数而产生过拟合的风险。
3.2.3 数据扩充对模型性能的影响
在其他参数相同的条件下,分别针对3种数据扩充方式(A-无扩充,居中裁剪为227×227;B-随机裁剪为227×227;C-先随机裁剪为227×227,再随机透视,最后随机旋转0°、90°、180°或270°)进行训练与测试,准确率曲线示例如图4所示。

图4 不同数据扩充方式下的训练与测试准确率曲线
图4a是在相同的学习方式(全新学习)、初始学习率(0.01)和正则项系数(0.001)以及不同的数据扩充方式(A、B、C)下的3组试验(试验编号为9、18、27)的训练与测试准确率曲线。图4b是在相同的学习方式(迁移学习)、初始学习率(0.001)和正则项系数(0.001)以及不同的数据扩充方式(A、B、C)下的3组试验(试验编号为34、43、52)的训练与测试准确率曲线。
由图4可知,在全新学习模式下,数据扩充对于增加数据的多样性,避免出现过拟合现象有较大的促进作用;在迁移学习模式下,数据扩充对于提升模型分类性能的促进作用较弱,是由于预训练模型在大型图像数据集上学习到了大量知识,弱化了数据扩充作用。在数据扩充方式下,测试准确率曲线表现出较大的波动,如图4a,A、B、C扩充方式下的测试准确率的波动率分别为0.0919、0.1481、0.0818。准确率的波动性可以用邻点准确率差值的均方根来度量,见式(3)。
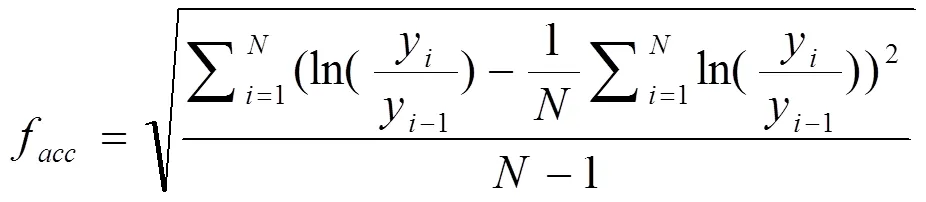
式中f为准确率的波动率,y为第点的准确率,为准确率点数。
准确率波动性大主要是因为试验中为了节省扩充数据集所需的巨大存储空间而采用了在线动态的数据扩充方式,即训练过程中,对从训练数据集获取的样本顺序叠加随机裁剪、随机透视、随机旋转等扰动,一定程度上破坏了原数据集的样本分布,但随着训练轮数的增加,参与训练的原样本和随机样本增多,将逐渐聚集在原样本分布的中心,因而波动幅度逐渐缩小,模型的鲁棒性也会逐渐提高。
3.2.4 迁移学习对模型性能的影响
由图4可见,迁移学习对于加速网络收敛和提高训练与测试准确率具有明显的促进作用。在全新学习模式下,训练初始阶段的测试准确率为0.2,仅达到随机猜测水平,经过300个epoch后,模型的测试准确率才逐渐趋于稳定。在迁移学习模式下,训练初始阶段的测试准确 率便达到0.4以上,之后网络迅速收敛,经过约10个epoch便达到训练准确率峰值,经过约100个epoch后接近测试准确率峰值,节省了约2/3的训练时间。由表1可知,全新学习方式下,初始学习率为0.01的各组试验的模型性能相对较好,而在迁移学习方式下,初始学习率为0.001的各组试验的模型性能相对较好。将初始学习率0.001、迁移学习方式下的各组试验与初始学习率0.01、全新学习方式下的各组试验对应相比,容易发现迁移学习的各组试验的模型测试准确率高出全新学习的各组试验约5~54个百分点。
对性能较优的第43组试验(学习方法为迁移学习,初始学习率为0.001,正则项系数为0.001,数据扩充方式为随机裁剪)中经过300个epoch训练获得的模型进行测试,计算得到的混淆矩阵、查准率、查全率、F1得分如表2所示。由表2的混淆矩阵可知,模型的平均分类准确率为96.53%,分类性能(按F1得分)从高到低依次是黄化病、健康叶、煤污病、软腐病、藻斑病。由混淆矩阵可以看出,分类错误主要为将藻斑病错分为软腐病,主要是因为藻斑病晚期的色泽与软腐病类似,病斑纹路不清晰,在低分辨率图像下较难区分。

表2 模型的混淆矩阵与分类性能
4 结 论
针对传统识别方法存在特征提取耗时费力的问题,本文利用迁移学习方法和深度卷积神经网络对油茶病害叶片图像进行了分类试验,并对学习方法、数据扩充方式、学习率、正则项系数等因素对模型性能的影响进行了对比分析,得到如下结论:
1)深度卷积神经网络可以较好地自动提取油茶病害特征,具有较高的分类性能,平均识别准确率达到96.53%以上;
2)相对于全新学习而言,迁移学习可以充分利用在大型数据集上学习得到的知识,可以显著加速网络收敛和提高分类性能,可以节省约2/3的训练时间。在各自较优的初始学习速率下,迁移学习的测试准确率高出全新学习约5~54个百分点;
3)相对于正则项系数和数据扩充方式,学习率对模型的稳定性与分类准确率有较大影响,迁移学习的初始学习率一般取为全新学习的1/10可以取得比较好的训练效果;
4)数据扩充对全新学习的影响大于迁移学习。在线动态的数据扩充方式节省了存储扩充数据所需的巨大空间,丰富了数据的多样性,可以减轻模型的过拟合现象,但一定程度上破坏了原数据集的样本分布,增加了训练的波动性。
目前的模型局限于背景简单、病害单一的油茶病害叶片图像。实际应用可能需要直接在林地现场识别,同一叶片可能会有多种病害类型的症状特征。今后应进一步丰富油茶病害图像数据集,充分利用病害症状的多尺度特征,建立端到端的病斑分割与识别模型,以进一步提升模型的识别率与实用性。
[1] 赵丹阳,秦长生. 油茶病虫害诊断与防治原色生态图谱[M]. 广州:广东科技出版社,2015.
[2] 黄敦元,王森. 油茶病虫害防治[M]. 北京:中国林业出版社,2010.
[3] 刘涛,仲晓春,孙成明,等. 基于计算机视觉的水稻叶部病害识别研究[J]. 中国农业科学,2014,47(4):664-674. Liu Tao, Zhong Xiaochun, Sun Chengming, et al. Recognition of rice leaf diseases based on computer vision[J]. Scientia Agricultura Sinica, 2014, 47(4): 664-674. (in Chinese with English abstract)
[4] Phadikar S, Sil J. Rice disease identification using pattern recognition techniques[C]// International Conference on Computer and Information Technology. IEEE, 2008: 420-423.
[5] 张善文,张传雷. 基于局部判别映射算法的玉米病害识别方法[J]. 农业工程学报,2014,30(11):167-172. Zhang Shanwen, Zhang Chuanlei. Maize disease recognition based on local discriminant algorithm[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2014, 30(11): 167-172. (in Chinese with English abstract)
[6] 李冠林,马占鸿,王海光. 基于支持向量机的小麦条锈病和叶锈病图像识别[J]. 中国农业大学学报,2012,17(2):72-79. Li Guanlin, Ma Zhanhong, Wang Haiguang. Image recognition of wheat stripe rust and wheat leaf rust based on support vector machine[J]. Journal of China Agricultural University, 2012, 17(2): 72-79. (in Chinese with English abstract)
[7] 毛罕平,张艳诚,胡波. 基于模糊C均值聚类的作物病害叶片图像分割方法研究[J]. 农业工程学报,2008,24(9):136-140. Mao Hanping, Zhang Yancheng, Hu Bo. Segmentation of crop disease leaf images using fuzzy C-means clustering algorithm[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2008, 24(9): 136-140. (in Chinese with English abstract)
[8] 柴阿丽,李宝聚,石延霞,等. 基于计算机视觉技术的番茄叶部病害识别[J]. 园艺学报,2010,37(9):1423-1430. Chai Ali, Li Baoju, Shi Yanxia, et al. Recognition of tomato foliage disease based on computer vision technology[J]. Acta Horticulturae Sinica, 2010, 37(9): 1423-1430. (in Chinese with English abstract)
[9] 张芳,王璐,付立思,等. 复杂背景下黄瓜病害叶片的分割方法研究[J]. 浙江农业学报,2014,26(5):1346-1355. Zhang Fang, Wang Lu, Fu Lisi, et al. Segmentation method for cucumber disease leaf images under complex background[J]. Acta Agriculturae Zhejiangensis, 2014, 26(5): 1346-1355. (in Chinese with English abstract)
[10] 江海洋,张建,袁媛,等. 基于MDMP-LSM算法的黄瓜叶片病斑分割方法[J]. 农业工程学报,2012,28(21):142-148. Jiang Haiyang, Zhang Jian, Yuan Yuan, et al. Segmentation of cucumber disease leaf image based on MDMP-LSM[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2012, 28(21): 142-148. (in Chinese with English abstract)
[11] 王树文,张长利. 基于图像处理技术的黄瓜叶片病害识别诊断系统研究[J]. 东北农业大学学报,2012,43(5):69-73. Wang Shuwen, Zhang Changli. Study on identification of cucumber leaf disease based on image processing[J]. Journal of Northeast Agricultural University, 2012, 43(5): 69-73. (in Chinese with English abstract)
[12] 王献锋,张善文,王震,等. 基于叶片图像和环境信息的黄瓜病害识别方法[J]. 农业工程学报,2014,30(14):148-153. Wang Xianfeng, Zhang Shanwen, Wang Zhen, et al. Recognition of cucumber diseases based on leaf image and environmental information[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2014, 30(14): 148-153. (in Chinese with English abstract)
[13] 赵进辉,罗锡文,周志艳. 基于颜色与形状特征的甘蔗病害图像分割方法[J]. 农业机械学报,2008,39(9):100-103. Zhao Jinhui, Luo Xiwen, Zhou Zhiyan. Image segmentation method for sugarcane diseases based on color and shape features[J]. Transactions of the Chinese Society for Agricultural Machinery, 2008, 39(9): 100-103.
[14] Arnal Barbedo J G. Digital image processing techniques for detecting, quantifying and classifying plant diseases[J]. SpringerPlus, 2013, 2(1): 1-12.
[15] Chaudhary P, Chaudhari A K, Cheeran A N, et al. Color transform based approach for disease spot detection on plant leaf[J]. International Journal of Computer Science and Telecommunications, 2012, 3(6): 65-70.
[16] 贾建楠,吉海彦. 基于病斑形状和神经网络的黄瓜病害识别[J]. 农业工程学报,2013,29(增刊1):115-121. Jia Jiannan, Ji Haiyan. Recognition for cucumber disease based on leaf spot shape and neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2013, 29(Supp.1): 115-121. (in Chinese with English abstract)
[17] Patil J K, Kumar R. Feature extraction of diseased leaf images[J]. Journal of Signal and Image Processing, 2012, 3(1): 60-63.
[18] Hiary H A, Ahmad S B, Reyalat M, et al. Fast and accurate detection and classification of plant diseases[J]. International Journal of Computer Applications, 2011, 17(1): 31-38.
[19] Jian Z, Wei Z. Support vector machine for recognition of cucumber leaf diseases[C]// International Conference on Advanced Computer Control. IEEE, 2010: 264-266.
[20] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. 2012: 1097-1105.
[21] Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//IEEE Computer Society. IEEE Conference on Computer Vision and Pattern Recognition, 2014: 1-9.
[22] Deng J, Berg A, Satheesh S, Su H, et al. Imagenet large scale visual recognition competition 2012[EB/OL]. [2017-11-03]. http://image-net.org/challenges/LSVRC/2012.
[23] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C]// International Conference on Learning Representations (ICLR), 2014,arxiv: abs/1409.1556.
[24] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
[25] Mohanty S P, Hughes D P, Salathé M. Using deep learning for image-based plant disease detection[J]. Frontiers in Plant Science, 2016, 7:1-10.
[26] Sladojevic S, Arsenovic M, Anderla A, et al. Deep neural networks based recognition of plant diseases by leaf image classification[J/OL]. Computational Intelligence andNeuroscience, 2016, 2016: 1-11. DOI: 10.1155 /2016 /3289801.
[27] Brahimi M, Boukhalfa K, Moussaoui A. Deep learning for tomato diseases: classification and symptoms visualization[J]. Applied Artificial Intelligence, 2017, 31(4): 299-315.
[28] 孙俊,谭文军,毛罕平,等. 基于改进卷积神经网络的多种植物叶片病害识别[J]. 农业工程学报,2017,33(19):209-215. Sun Jun, Tan Wenjun, Mao Hanping, et al. Recognition of multiple plant leaf diseases based on improved convolutional neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(19): 209-215. (in Chinese with English abstract)
[29] Lu Y, Yi S, Zeng N, et al. Identification of rice diseases using deep convolutional neural networks[J]. Neurocompu -ting,2017, 267: 378-384.
[30] Pan S, Yang Q. A survey on transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345-1359.
Image recognition ofdiseases based on convolutional neural network & transfer learning
Long Mansheng, Ouyang Chunjuan, Liu Huan, Fu Qing
(1,,343009,;2,343009,)
Leaf diseases are a serious problem inproduction. The occurrence ofdisease is affected by various factors, such as variety, cultivation environment, climate condition and management level. The key to effective prevention and cure ofdisease is to identify the disease type timely and accurately. Traditional computer vision methods for plant leaf disease recognition depend heavily on time-consuming and elaborate feature design. To solve this problem, a recognition model ofleaf diseases based on convolutional neural network was proposed and transfer learning was used to improve model’s performance. Deep convolutional neural network has powerful capacities of feature learning and feature expression, which was used to learn features of diseasedleaves. Transfer learning method was used to transfer the knowledge learned from ImageNet dataset by AlexNet to the identification task ofdiseases. The proposed model was implemented with Python programming language under the deep learning framework of Tensorflow by modifying the output number of the last fully connected layers in AlexNet to 5. We collectedleaves in artificialland and took photos by mobile phone in bright indoor environment after flattening leaves. Leaf images were first converted from RGB (red, green, blue) color space to HSI (hue, saturation, intensity) color space, and then background was removed by threshold segmentation on hue and saturation channels. After segmentation, morphological open and close operations with a radius of 3 pixels were performed to remove burrs, holes and other noises, and thus the leaf mask was obtained by filling holes. Leaf mask was multiplied with the original image to obtain the colored leaf region. The colored leaf region was then rotated according to its principal axis angle and aligned horizontally. Based on the long edge, leaf image was scaled to 256×256 pixels. After these pretreatments,leaf images were manually identified as algal spot, soft rot, sooty mould, yellows and healthy leaf. A total of 750 images for each disease category were selected to form data set, 80% of samples were randomly selected for train set, and the remaining 20% for test set. To simulate different views of image acquisition and reduce over-fitting of network models, image datasets of diseasedleaf were augmented by random crop, random rotation and random perspective transformation. To save space for huge amount of augmented images, data augmentation was executed online when training. In random crop mode, image is randomly cropped from 256×256 to 227×227 pixels. In random rotation mode, image is randomly rotated by 0, 90, 180, or 270 degrees. In order to avoid serious distortion of the transformed image, the displacement of the corresponding point in perspective transformation is limited to 10% of the image width and height. A total of 54 experiments were performed on Nvidia GPU with a combination of 2 learning methods (training from scratch, transfer learning), 3 data augmentation modes (no augmentation, random cropping, sequential execution of random cropping, perspective transformation and rotation), 3 regularization coefficients (0.0, 0.0005, 0.0001), and 3 initial learning rates (0.001, 0.005, 0.01). When training from scratch, weights are randomly initialized with truncated normal distribution and biases are initialized with zero constant. In transfer learning, only the last fully connected layers’ weights and biases are reinitialized with random values, and those of other layers are assigned by the values from pre-trained AlexNet model. Experimental results show that transfer learning can significantly improve models’ convergence speed and classification performance, and data augmentation can enrich data diversity and avoid over fitting especially when training from scratch. The classification accuracy was as high as 96.53% in transfer learning, and the1 scores of algal spot, soft rot, sooty mould, yellows and healthy leaf achieved 94.28%, 94.67%, 97.31%, 98.34% and 98.03% respectively. This method has high recognition accuracy, and strong robustness to translation and rotation, and can provide references for intelligent diagnosis of plant leaf diseases.
disease; classification; crop;disease; image recognition; deep learning; transfer learning
10.11975/j.issn.1002-6819.2018.18.024
TP391.4; S431.9
A
1002-6819(2018)-18-0194-08
2017-07-20
2018-08-03
国家自然科学基金项目(41561065);流域生态与地理环境监测国家测绘地理信息局重点实验室开放基金课题(WE2015002);江西省自然科学基金项目(20151BAB203038,20161BAB204172)。
龙满生,副教授,博士,主要从事图像分析、虚拟仿真研究。Email:longmansheng@126.com
龙满生,欧阳春娟,刘 欢,付 青. 基于卷积神经网络与迁移学习的油茶病害识图像识别[J]. 农业工程学报,2018,34(18):194-201. doi:10.11975/j.issn.1002-6819.2018.18.024 http://www.tcsae.org
Long Mansheng, Ouyang Chunjuan, Liu Huan, Fu Qing. Image recognition ofdiseases based on convolutional neural network & transfer learning[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(18): 194-201 (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2018.18.024 http://www.tcsae.org
猜你喜欢
农村科学实验(2021年7期)2021-12-24
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
故事作文·低年级(2020年7期)2020-07-28
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
中国林业产业(2019年11期)2019-01-09
中国交通信息化(2018年5期)2018-08-21
