
基于键盘距离和依存分析的拼写纠错方法
2018-10-09 10:57谢文慧易荣庆
吉林大学学报(理学版) 2018年5期
谢文慧, 易荣庆, 彭 涛,3
(1. 吉林大学 计算机科学与技术学院, 长春 130012; 2. 国网吉林省电力有限公司, 长春 130022;3. 吉林大学 符号计算与知识工程教育部重点实验室, 长春 130012)
文本拼写纠错在搜索引擎(如百度、 Google)、 在线查询及Word拼写校对等领域应用广泛. 拼写纠错就是查找并纠正在文本输入过程中出现的错误. 英文文本错误类型一般分为非词错误和真词错误两类. 非词错误, 即文本中的单词在词典中并不存在, 单词拼写有误, 这类错误一般是由于打字输入错误, 或作者对所需字词的正确拼写不清楚所致, 非词错误的检错、 纠错方法相对成熟. 真词错误, 即拼错字符串为有效单词, 该单词在词典中存在, 但由该单词所在的句子存在句法或语义错误, 真词错误的检查及校对要比非词错误的检查及校对更困难.
网络的发展使得资源输入形式多样化, 但键盘输入仍是最主要的输入方式. 而键盘输入难免会遇到疏忽遗漏, 导致文本的拼写错误和内容错误. 这类错误通常是结合单词间的相似度及单词间的编辑距离进行纠正. Levenshtein[1]提出了4种编辑操作: 插入、 删除、 置换和交换. 对真词错误的校正通常是根据上下文进行拼写校正, 通过待纠错单词前后的单词及其词性检错和纠错. 句法分析(Parsing)[2]是对句子中的词语语法功能进行分析. 对文本处理需求的增加使得句法分析的作用更突出, 句法分析在自然语言处理中应用广泛, 如机器翻译[3]、 信息抽取[4]、 问答系统[5]等. 因此, 句法分析的概念可以运用到真词纠错中, 利用待纠错单词与其前后词的搭配判断该单词是否使用正确, 若不正确, 则进行纠错. 依存分析[6]能弥补n-gram模型仅适用于局部纠错的缺陷, 可以分析远距离词语之间的关系, 对文本全局纠错有较好的效果. 此外, 对于一个依存分析器, 无论输入的句子语法结构是否正确, 都会返回该句子对应的依存关系列表.
目前, 已有许多针对不同语言的拼写校正模型, 如匈牙利语[7]、 阿拉伯语[8]、 哈萨克语[9]、 希腊语[10]、 汉语[11]等. 本文研究英语文本的拼写纠错. Kukich[12]提出的拼写纠错包括非词错误和真词错误. Levenshtein[1]提出了使用Levenshtein距离对候选单词进行评分, 即计算一个字符串进行编辑操作得到候选单词的操作次数. Levenshtein算法对不同单词进行一次编辑操作得到的编辑距离为常数, Lhoussain等[13]为克服这个限制, 对编辑距离进行加权, 提出了基于语言模型的加权拼写纠正系统, 用于阿拉伯语的拼写纠错过程. Soleh等[14]使用反向词典(forward reversed dictionary)和相似概率两种替代方法进行纠错, 并将拼错字符串视为观察状态, 候选词视为隐藏状态, 通过使用隐Markov模型对候选词进行排序, 进而进行拼写纠错. 对于真词错误, Bergsma等[15]提出一个基于上下文的n-gram拼写校正模型, 利用有监督和无监督方法, 对具有多个上下文语义信息的拼错字符串进行拼写校正任务, 其中, 有监督方法将消歧误差减少了20%~24%. Lapata等[16]将词汇消歧算法用于与上下文有关的真词纠错过程, 例如“defect”和“detect”都是有效单词, 均可以在词典中找到, 该方法基于上下文词汇和语法语义信息, 从候选词集合中选择最适合的单词进行拼写纠错. Samanta等[17]将候选词及其相邻单词构成三元组, 进而得到二进制推荐分数, 若单词某一位置出现拼写错误, 则拼错的字符串通过在错误字符的位置进行一次编辑操作生成一组真实单词, 最后使用基于规则的方法对候选词排序得到拼写纠错建议.
拼写错误是在搜索引擎查询过程中的常见现象. Gao等[18]将用于标准书面文本的噪声拼写模型进行扩展, 增加了特征合并、 分布式训练和基于短语的纠错模型, 以解决搜索查询中具有挑战性的问题, 该方法中每个扩展方法相对于基准方法都有显著改进. Duan等[19]对查询完成时的在线拼写校正问题进行了研究, 训练一种以无监督方式获取用户拼写行为的模型, 结合多种启发式算法扩展搜索空间. Hasan等[20]提出了基于统计的机器学习算法来纠正电子商务领域的用户搜索查询错误. Leacock等[21]提出的编辑辅助工具对于第二语言学习者非常有益, 不但在写作方面有所改进, 且可通过有价值的反馈学习语言. Xu等[22]将依存分析用于具有网络规模语料库的n-gram模型中, 使数据稀疏性问题得到改善, 将语法、 语义特征引入n-gram纠错模型会使错误的修正率较当前最先进水平提高了12.4%.
基于上述分析, 本文提出一种基于键盘距离和依存分析的拼写纠错模型SpellKD, 从键盘输入和句法分析上对英文文本进行拼写纠错. 键盘按键距离较近以及输入者的粗心, 经常会导致输入单词字母的拼写错误, 鉴于此, 本文采用基于键盘按键距离的单词拼写纠错方法, 通过编辑操作构造候选词, 根据键盘距离和编辑距离得到候选集中每个候选词的邻近权值. 由于输入者的英文水平存在差异, 输入的单词可能为不符合语法或语义的单词, 因此, 本文将依存分析引入到拼写纠错中, 结合上下文的词汇, 从语义的角度对候选词进行排序, 通过拼错字符串与句中单词间的依存关系, 将其与依存关系对库中的依存关系对进行匹配, 得到依存关系权值. 此外, 利用词频特征提高拼写纠错的准确率. 最后, 结合邻近权值、 依存关系权值及词频对候选词的推荐总分进行排序, 给出拼写建议.
1 基于键盘距离和依存分析的拼写纠错过程
1.1 键盘距离计算
非词错误是指拼写错误的字符串不是一个有效的单词, 词典中不包括该字符串. 将输入的英文单词与词典中单词进行匹配, 若匹配, 则将其视为正确单词; 若不匹配, 则将其视为拼写错误的字符串, 并对其进行纠错. 对于拼写错误的字符串, 使用替换、 插入、 删除和交换4种操作[23]进行候选集构造, 若构造的候选字符串在词典中存在, 则留作候选词; 若构造的候选字符串在词典中不存在, 则将其删除. 在构造候选集前, 本文根据如图1所示的键盘布局, 定义键盘距离.

图1 键盘布局Fig.1 Keyboard layout
定义1(键盘距离,KeyboardDis) 给定键盘上的两个字母li和lj, 键盘距离的计算方法如下:
1) 若li与lj相邻, 则KeyboardDis(li,lj)=1;
2) 若li与lj不相邻, 则li和lj的键盘距离为它们之间的最短路径值;
3) 若li与lj相同, 则KeyboardDis(li,lj)=0.5.
当编辑距离为1时, 候选集构造方法如下:
1) 替换. 将拼错字符串每个位置的字母依次替换成其他25个字母构成候选词, 候选词与拼错字符串的单词距离为替换的两个字母之间的键盘距离. 例如, 单词“red”被拼错为字符串“rwd”, “red”和字符串“rwd”的单词距离为字母“w”和字母“e”的键盘距离, 即为1.
2) 插入. 将拼错字符串不同位置依次插入26个字母构成候选词, 候选词与拼错字符串之间的单词距离为插入的字母与其相邻两个字母之间的最小键盘距离, 若插入字母仅有一个相邻字母, 则插入字母与该相邻字母之间的键盘距离为候选词与拼错字符串之间的单词距离. 例如, 单词“alone”被拼错为字符串“alne”, “alone”与字符串“alne”的单词距离为字母“o”与其相邻的字母“l”和“n”的最小键盘距离, 字母“o”和“l”的键盘距离为1, 字母“o”和“n”的键盘距离为2, 所以候选词“alone”与拼错字符串“alne”的单词距离为1.
3) 删除. 将拼错字符串每个位置的字母依次删除构成候选词, 候选词与拼错字符串之间的单词距离为删除的字母与其相邻两个字母之间的最小键盘距离, 若删除字母仅有一个相邻字母, 则删除字母与该相邻字母之间的键盘距离为候选词与拼错字符串之间的单词距离.
4) 交换. 将拼错字符串相邻位置字母交换构成候选词, 候选词与拼错字符串之间的单词距离为交换的两个字母之间的键盘距离.
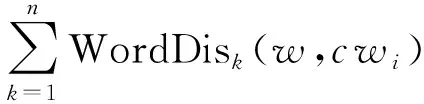
(1)
(2)

1.2 依存关系计算
依存分析文法[24]分析了句子结构, 从语法上描述了句子中词与词之间的依存关系, 这种关系有方向且不受距离限制. 主要包含acomp,advcl,amod,conj及appos等49种依存关系. 例如, 一个句子“Bills on ports and immigration were submitted by Senator Brownback, Republican of Kansas”的依存关系结构如图2所示. 图2中两两单词间对应的依存关系对列于表1.

表1 图2对应的依存关系对

图2 例句对应的依存关系Fig.2 Dependency relationship of corresponding sentence
无论输入的句子是否符合句法结构, 依存分析器都会给出句中单词间的依存关系, 基于此, 本文构建依存关系对库, 对有依存关系的词对进行依存关系权值计算. 若w为拼错字符串, 则w构成的候选集为CS={cw1,cw2,…,cwk,…,cwm}. 在一个句子中, 与候选词具有依存关系的单词集合为RW={rw1,rw2,…,rwi,…,rwp}, 其中p为与候选词具有依存关系的单词总数, 它们之间相应的依存关系序列为R={r1,r2,…,ri,…,rp}, 则与候选词cwk具有依存关系ri的单词rwi和候选词cwk的依存关系概率dw的计算公式为
(3)
其中:N(cwk,rwi|ri)表示依存关系库中候选词cwk与单词rwi具有依存关系ri的依存关系对数量;N(*,rwi|ri)表示依存关系库中与单词rwi具有关系ri的所有单词数量. 依存关系库是按照依存原则组织在一起的关系对集合. 由于语料库的规模及其所包含的语言现象有限, 从而导致产生数据稀疏现象, 即在语料库规模较小的条件下, 构建的依存关系库不够完善, 大多数候选词和与其具有依存关系的单词对在依存关系库中出现的次数很少, 甚至不出现. 在实际应用中, 由于数据稀疏性, 会出现大量依存关系对为空的现象, 进而影响拼写纠错性能和效果. 因此, 本文采用加一平滑方法[25]解决数据稀疏性问题. 应用加一平滑方法得到的依存关系权值计算公式为
(4)
其中:V表示和单词rwi具有依存关系ri的单词集合; |V|表示集合中单词的数量.
1.3 结合键盘距离与依存分析排序候选集
SpellKD模型考虑了键盘距离、 依存关系及词频进行拼写纠错, 本文给出了邻近权值与依存关系权值的计算过程. 结合以上三部分, 候选词的推荐分数score计算公式为
score=α×pw′+β×dw′+γ×fw,
(5)
其中:pw′为归一化的邻近权值;dw′表示平滑后的依存关系权值;fw为候选词的词频权值;α,β和γ分别为邻近权值、 依存关系权值和词频权值的加权因子, 且α+β+γ=1, 本文中γ=0.2. 候选词的词频权值计算公式为
(6)
其中: count(cwk)表示词典中单词cwk的数量; max {count(w)}表示词典中数量最多的单词总数. SpellKD模型的流程如图3所示.

图3 SpellKD模型的流程Fig.3 Flow chart of SpellKD model
2 实验结果与分析
下面使用SpellKD拼写纠错模型, 在Brown语料库、 Gutenberg语料库和Inaugural语料库上进行测试及对比分析.
2.1 数据集
作为语言学类的一般文本收藏语料库, Brown语料库是一个百万词级的英文语料库. Gutenberg语料库主要包含古腾堡项目电子文本档案的部分文本, 该项目目前约有36 000本免费的电子图书. Inaugural语料库是55个文本的集合, 每个文本都是一个总统的演说稿. 表2列出了3个语料库的规模以及对应依存关系对的数量.

表2 语料库规模及对应依存关系对数量
本文在每个语料库上随机选择100个句子作为测试集, 其余文本用于构造依存关系对库. 在每个句子中随机选择一个单词, 并随机生成编辑距离为1~5的字符串作为拼写错误的单词.
2.2 参数分析与结果
对于键盘距离的计算, 共需要325对字母间的距离, 在实验中提前给出. 在依存分析处理过程中, 调用Stanford大学的JAVA语言工具包(https://stanfordnlp.github.io/CoreNLP/)对句子进行依存分析处理. 分析得到的结果经预处理后为三元组形式, 表示为(关系的名称, 主导词, 依赖词), 如句子“Bill is big”中有依存关系对(cop,big,is).
输入测试集文本对句子进行处理. 将句子中每个单词与词典匹配, 为词典中不存在的单词构造候选集, 计算候选集中每个候选词的邻近权值、 依存关系权值、 词频权值, 用式(5)计算推荐分数, 推荐分数前三名的单词作为修改建议. 计算前三个单词中包含正确单词的准确率Precision、 召回率Recall和F-Measure值. 准确率、 召回率和F-Measure值的计算公式如下:
其中:CC表示被认为拼写错误并提出正确修改意见的单词集合, 即识别正确、 且修改正确的单词集合;CW表示被认为拼写错误但提出了错误修改意见的单词集合, 即识别正确、 但修改错误的单词集合;RW表示原来正确、 但被修改错误的单词集合. 本文固定词频权值的加权因子为0.2, 邻近权值的加权因子为α, 依存关系权值的加权因子为0.8-α. 为了验证SpellKD模型的拼写纠错效果, 分别给出随着α的变化, SpellKD模型在3个不同语料库中对应的Precision,Recall和F-Measure值的变化曲线, 结果如图4所示.
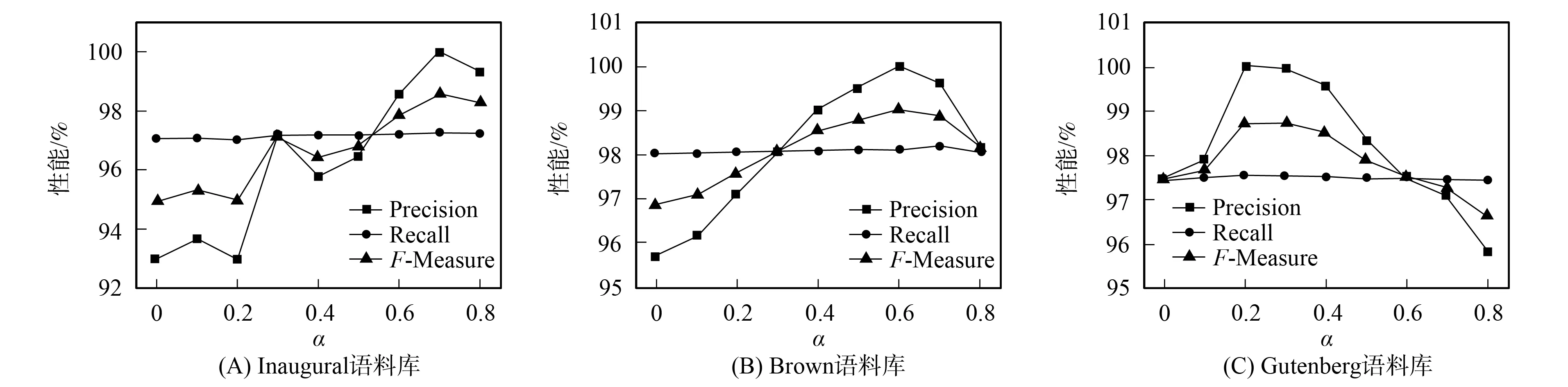
图4 随着α的变化, SpellKD模型在3个语料库中对应的Precision,Recall和F-Measure值Fig.4 Corresponding Precision, Recall and F-Measure values of SpellKD model on three corpuses with change of α
F-Measure值为准确率和召回率的调和平均值, 图4(A)为在Inaugural语料库上使用SpellKD模型对测试集进行拼写纠错得到的Precision,Recall和F-Measure值, 当α=0.7时,F-Measure值达到最大, 同时准确率最高, 为100%. 由图4(A)可见, 当α=0.7时, 给出对于错误单词的拼写意见排序, 前三个拼写意见中必包含正确的单词; 图4(B)为在Brown语料库上使用SpellKD模型对测试集进行拼写纠错得到的Precision,Recall和F-Measure值, 当α=0.6时,F-Measure值达到最大, 同时准确率最高; 图4(C)为在Gutenberg语料库上使用SpellKD模型对测试集进行纠错得到的Precision,Recall和F-Measure值, 当α=0.3时,F-Measure值达到最大, 同时准确率最高. 在3个语料库中, 当α=0时, SpellKD模型采用依存分析和词频信息进行纠错; 当α=0.8时, 模型采用基于键盘距离和词频信息进行纠错, 这两种情形对应的拼写纠错效果都不理想. 当语料库规模较小时, 如Inaugural语料库, 此时构造的依存关系库中关系对较少, 依存关系对于拼写纠错模型的影响相对较小, 邻近权值的加权因子较大, 可得到较好的纠错效果. 当语料库规模较大时, 构造的依存关系库中关系对较多, 此时, 结合键盘距离和依存分析可获得较好的纠错效果.
下面将SpellKD模型与Word纠错方法进行对比实验, 将SpellKD模型和Word纠错方法分别在3个语料库中进行测试. 模型对应的准确率分别列于表3和表4. 当第一个候选词为正确单词时, SpellKD模型和Word纠错方法对应的准确率列于表3; 当前三个候选词中包含正确单词时, SpellKD模型和Word纠错方法对应的准确率列于表4. 由表3可见, 当α选取合适值时, SpellKD模型的准确率明显高于Word纠错对应的准确率, 准确率约提高14%; 由表4可见, SpellKD模型结合键盘距离和依存分析可显著提高拼写纠错的准确率.
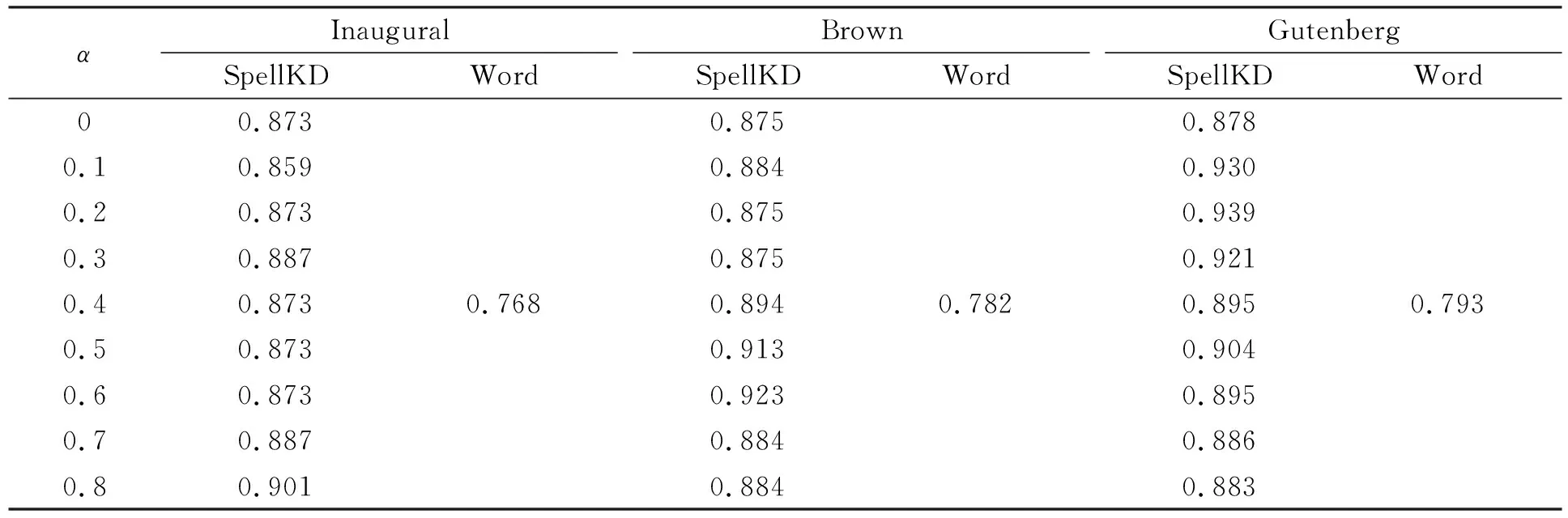
表3 当第一个候选词为正确单词时, SpellKD模型和Word纠错方法的准确率
下面给出一个利用SpellKD模型进行拼写纠错的案例分析. 例如: 句子“They would still be paic by the patient”中, 单词“paid”被错拼为字符串“paic”, SpellKD模型的运行结果列于表5. 由表5可见, 推荐分数最高的候选词为paid, 为正确的修改意见.

表4 当前三个候选词为正确单词时, SpellKD模型和Word纠错方法的准确率
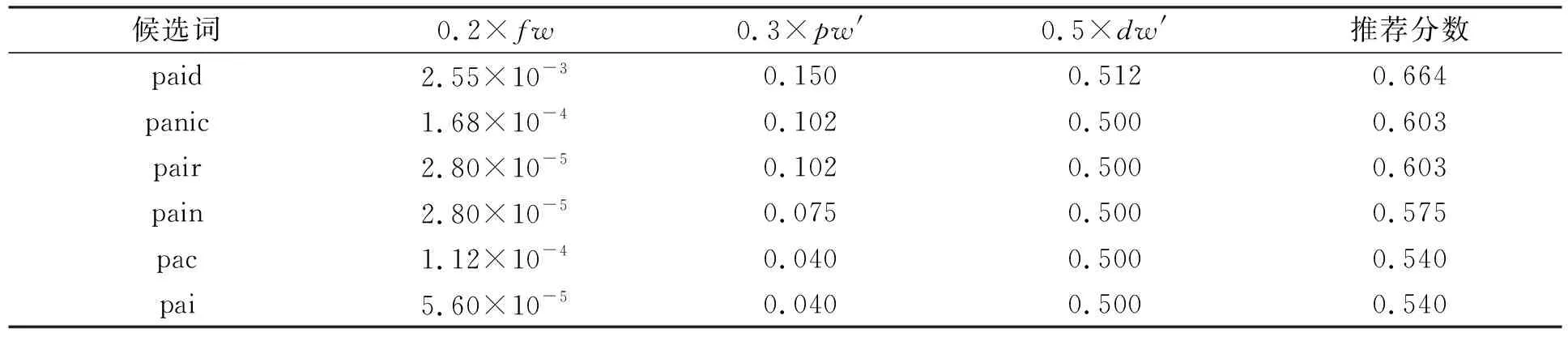
表5 句子“They would still be paic by the patient”运行结果
综上可见, 本文提出的拼写纠错模型SpellKD, 主要考虑了键盘结构和单词间的语义关系. 根据键盘距离进行拼写纠错可发现很多在输入过程由于失误而产生的拼写错误. 通过依存分析构建语料库中的依存关系对, 能识别单词间的语义关系, 进行拼写纠错. 将依存分析应用到拼写纠错中是一个新的尝试, 可从语义关系的角度发现并纠正产生的错误. 实验结果表明, SpellKD模型通过结合键盘距离和依存分析可有效进行拼写纠错.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
无线互联科技(2020年11期)2020-12-01
天津外国语大学学报(2020年1期)2020-03-25
江苏通信(2018年4期)2018-12-04
自动化学报(2017年7期)2017-04-18
科教导刊·电子版(2016年30期)2016-12-26
中国信息技术教育(2015年21期)2015-09-10
语言与翻译(2015年4期)2015-07-18
外语教学理论与实践(2014年4期)2014-06-13
