
基于形态学与灰度分布的序列虹膜质量评价算法
2018-10-09 10:57:04刘元宁朱晓冬刘文滔程垚松
吉林大学学报(理学版) 2018年5期
刘 帅, 刘元宁, 朱晓冬 , 刘文滔, 程垚松
(1. 吉林大学 符号计算与知识工程教育部重点实验室, 长春 130012;2. 吉林大学 软件学院, 长春 130012; 3. 吉林大学 计算机科学与技术学院, 长春 130012)
虹膜具有稳定性、 唯一性和非入侵性[1]等特点, 是目前生物识别技术的主要方法之一. 虹膜识别过程分为图像采集、 预处理、 特征提取与识别. 因为虹膜的处理主要在系统后台进行, 拍摄质量较差的虹膜图像会使虹膜所携带的纹理信息不能很好地被提取出来, 对虹膜识别产生干扰. 因此在处理虹膜图像前, 需要系统自行对虹膜质量进行评价[2], 判断其是否可用于虹膜识别. 对于序列虹膜(连续采集的虹膜)的质量评价, Daugman[3]提出了一种基于二维Fourier频谱中高频能量评价虹膜质量的算法; Gao等[4]提出了基于SVM的综合虹膜评价算法; 潘胜男[5]提出了一种基于BP神经网络的质量评价算法. 这些算法虽然在实验中性能表现优越, 但也存在一些缺陷, 首先这些算法步骤繁琐, 评价指标过多, 因此运行时间较长, 有效虹膜幸存率较低, 错误删除了大量可以进行虹膜识别的图像, 导致虹膜数据的浪费. 针对上述问题, 本文提出一种基于形态学与灰度分布的序列虹膜质量评价算法. 通过虹膜形态学方法对序列虹膜进行活体检测. 然后通过清晰度、 虹膜区域有效性、 超界偏移度和斜视离心度4个指标评价虹膜质量. 该算法步骤简单, 耗时较短, 可在保证排除不合格图像的同时, 尽可能多地保留虹膜, 提高有效虹膜幸存率.
1 基于形态学的虹膜活体检测
1.1 清晰度检测
首先需对序列虹膜进行清晰度检测, 本文使用Tenengrad梯度法[6], 图像为M×N维图像. 利用Sobel算子分别计算水平和垂直方向的梯度, 计算经过处理后图像的平均灰度值, 以此作为清晰度评价值F,F越大, 图像越清晰. 将F值与设定的阈值Z相比较,F (1) 其中Ga(a,b),Gb(a,b)分别为各像素f(a,b)与Sobel算子的卷积值. 各类清晰度图像如图1所示. 在虹膜采集中, 虹膜图像直接从视频流中截图, 不法分子可能利用虹膜图片、 假眼球等假虹膜拍摄, 因此, 有必要对虹膜进行活体检测, 判断拍摄虹膜是否为活体的人类虹膜. 本文提出基于形态学的序列虹膜活体检测. 形态学分为灰度形态学和二值形态学[7], 本文用二值形态学对序列虹膜进行活体检测. 针对清晰度合格的图像, 根据虹膜与瞳孔之间的灰度值差异, 将虹膜图像二值化, 并将二值图像进行开运算, 断开狭窄的连接, 去掉突出部分. 然后采用Canny+Hough圆检测方法[8], 描绘出瞳孔轮廓, 画出虹膜内圆, 得到瞳孔圆心与半径. 对圆心半径大小设置阈值, 若半径过小, 则将图像视为闭眼图像, 这类图像是不合格图像. 确定圆心与半径各阶段示意图如图2所示. 正常情况下, 因为活体瞳孔对光照的变化十分敏感, 所以图像采集过程中瞳孔的圆心和半径会随光照的强弱进行收缩和扩张[9]. 观察实际采集后的虹膜图像序列, 发现连续数十帧清晰睁眼图像中, 其圆心位置与半径大小虽然不断地变化, 但差距相对较小, 这一点单纯靠用虹膜图片或假眼球等很难完美模仿. 基于此, 本文根据视频流中连续24帧(1 s相当于24帧图像)图像中前后两帧图像间圆心与半径的差距判断虹膜活体性, 检测公式为 图2 确定圆心与半径各阶段示意图Fig.2 Schematic diagram of determining center and radius of circle at all stages (2) 其中:hi表示第i帧的判定值;ri表示第i帧的瞳孔半径;σ1表示半径阈值;xi表示第i帧的瞳孔圆心横坐标;σ2表示圆心横坐标阈值;yi表示第i帧的瞳孔圆心纵坐标;σ3表示圆心纵坐标阈值. 如果活体检测值H>10, 则视为该序列虹膜为活体虹膜, 即为活人拍摄的虹膜, 而非图片及假虹膜, 并且眼睛睁的足够大, 可支持后续的虹膜识别. 虹膜图像受眼睑及眼毛的干扰较大, 序列图像中一般会有半闭眼及虹膜被眼毛、 眼睑遮挡较多的情况, 因此需对虹膜区域的有效性进行判定. 本文在对瞳孔进行定位后的基础上, 根据瞳孔左右两侧固定区域的灰度直方图反应的灰度分布情况, 对睫毛覆盖情况进行判断. 因为正常情况下, 虹膜左右两侧受眼睑与眼毛的影响应该最小, 并且眼毛的灰度值介于瞳孔与虹膜之间. 基于此, 本文从瞳孔最左端与最右端两侧截取两块20×20维的子图, 比较子图的灰度直方图中的灰度分布与眼睛图像的灰度分布, 找到眼毛与眼睑在子图中的分布, 并计算眼毛、 眼睑的占有比作为遮挡度, 根据遮挡度判断虹膜区域的有效性, 遮挡度过高的虹膜, 则认为虹膜区域有效性差, 进而判定为不合格图像. 遮挡度较高虹膜的有效性判定示意图如图3所示. 遮挡度计算公式为 (3) 图3 遮挡度较高虹膜及灰度直方图Fig.3 High occlusion iris and gray histogram 将灰度直方图分成三部分, 从左到右依次为: 瞳孔睫毛区, 大小a×m维; 虹膜区, 大小b×m维; 眼睑皮肤区, 大小c×m维. 分别计算瞳孔睫毛区和眼睑皮肤区中各灰度级具有数值fi的总和(几何意义为各区域中灰色部分的面积和), 并乘以相应的权重(α,β)后相加, 得到遮挡度D. 遮挡较少的图像中,D值较小; 反之,D值较大. 权重α,β和区域的维数a,b,c,m均根据虹膜实际采集情况制定. 虹膜质量评价中, 还有两个问题需要解决, 即超边界和斜眼问题, 超边界问题是指图像中眼睛位置超过图像自身边界, 而斜眼问题则是在拍摄图像时, 眼睛出现翻白眼等现象. 这类图像在后续预处理过程中, 易导致系统崩坏, 因此需要排除. 超边界及斜眼图像如图4所示. 首先根据M×N维图像的中心点O(M/2,N/2)将图像分为4个区域, 依次为左上区域、 右上区域、 左下区域、 右下区域. 图4 超边界与斜眼图像Fig.4 Ultra-boundary and squint images 本文用超界偏移度评估虹膜是否会超出图像边界. 首先找到内圆圆心所在区域. 以右上区域为例, 计算中心点O(xo,yo)与虹膜内圆(瞳孔)中最右端点A(xa,ya)的距离IOA及中心点O与虹膜内圆(瞳孔)中最上端点B(xb,yb)之间的距离IOB. 分别计算点A、 点B到图像对角线右上端的点Sr1(xr1,yr1)之间的距离IAS1,IBS1, 并分别计算IOA与IAS1、IOB与IBS1之间的比值, 根据图像维数M和N的比例, 设计权重大小, 将计算结果加权相加得到超界偏移度S, 计算公式为 (4) 超界偏移度S越大, 瞳孔偏离越大, 瞳孔超边界可能性就较大, 判定为不合格图像, 判定阈值根据不同虹膜库进行设定, 在其余3个区域求S的过程与右上区域类似, 只是比较的点发生改变, 对应到各区域内不同方位上的点即可. 超界偏移度根据内圆的圆心与半径完成, 斜视离心度根据外圆圆心完成, 首先根据瞳孔定位结果对虹膜外圆进行粗定位, 本文采用文献[10]中的一维灰度均值法进行外圆粗定位, 然后找到外圆圆心所在区域. 以右上区域为例, 计算中心点O(xo,yo)与虹膜外圆中最右端点C(xc,yc)的距离IOC及中心点O与虹膜外圆中最上端点D(xd,yd)之间的距离IOD, 同时计算点C与点D的距离ICD, 计算∠COD的余弦, 并将其作为虹膜斜视离心度. 因为根据实际拍摄效果, 斜眼图像中的眼球形状呈椭圆形, 因此, 斜眼图像的夹角会增大, 余弦值会减小, 本文基于此判断斜眼, 计算公式为 (5) 斜视离心度L越小, 说明虹膜径向收缩和偏转强度越大, 虹膜斜眼越厉害, 将此图像判定为不合格图像, 判定阈值根据不同虹膜库进行设定. 在其余3个区域求L的过程与右上区域类似, 只是比较的点发生改变, 对应到各区域内不同方位上的点即可. 首先基于人的主观评价对虹膜原始图像进行主观评价实验, 再运用算法对虹膜原始图像进行算法评价实验, 对比两种评价的结果, 根据虹膜识别率与其他算法的对比, 进而评判本文算法的性能. 这样既可以从主观认知上进行实验, 又通过客观数据进行判别, 增加了实验评估结果的可信度. 采用JLU-IRIS-V4(http://www.jlucomputer.com/Irisdb.php)的原始虹膜库作为实验虹膜库, 由45类虹膜样本组成, 每种类别包含1 000张虹膜图像, 共45 000张图像. 其中, 闭眼图像、 斜眼图像、 模糊图像、 眼毛眼睑遮挡严重图像等因素综合人为筛选后, 主观认定质量不合格的图像8 821张, 主观认定质量合格的图像36 179张. 将本文算法与文献[3]的Fourier评价法、 文献[4]的SVM评价法、 文献[5]的神经网络评价法进行对比. 将认定合格数、 认定不合格数, 与主观认定合格数、 主观认定不合格数进行比较, 同时计算平均单张图像的评价时间(单位ms), 对算法性能进行初步比较. 实验结果列于表1. 由表1可见, 本文算法将很多主观认定为不合格的图像改为质量合格图像, 主观认定合格的图像则很少被评价为不合格图像, 并且单张图像消耗时间较短. 因为本文算法仅针对图像本身特性进行处理, 减少了神经网络训练及空域转频域的过程, 同时只针对关键指标进行判别, 避免了因指标过多而导致的时间浪费. 以较宽泛的指标最大限度地增加有效虹膜的幸存率, 基本满足了尽可能多的保留图像, 不浪费虹膜数据, 同时运行速度要尽可能快的要求. 相对于文献[3]的Fourier评价法、 文献[4]的SVM评价法、 文献[5]的神经网络评价法, 本文算法的计算量和复杂程度均有降低. 表1 实验结果 因为质量评价本质是为了保留特征多、 好采集的虹膜, 进而提高虹膜识别的准确性. 因此虹膜质量评价算法的性能最终还要通过虹膜的识别率判断, 根据表1认定的各类图像, 将图像分为4类: 1) 主观、 算法均认定合格; 2) 主观认定不合格, 算法认定合格; 3) 主观认定合格, 算法认定不合格; 4) 主观、 算法均认定不合格. 各情形的虹膜图像数量列于表2. 表2 图像分类结果 针对在4种质量评价方法评价后的4种情形虹膜进行定位、 归一化、 增强, 并进行虹膜识别. 由于质量评价中已对虹膜内圆和外圆进行了粗定位, 因此下面使用Daugman[3]提出的微积分圆模板法进行内圆、 外圆的精定位, 采用橡皮圈模型[11]进行虹膜图像归一化, 将环形虹膜展开成一个512×64维矩形. 增强图像纹理[12], 截取左上角中纹理最强的部分, 截成256×32维矩形. 实验环境: CPU主频为双核2.5 GHz, 8 GB内存, 操作系统为WindowsXP sp3. 在特征提取前, 先对所有归一化虹膜图像进行水平移位消除虹膜旋转问题[13]. 采用二维Gabor滤波提取特征纹理信息, 通过比较样本间的Hamming距离[14]判定虹膜类别. 虹膜预处理过程如图5所示. 图5 虹膜预处理过程Fig.5 Iris preprocessing process 图6 ROC曲线Fig.6 ROC curves 计算4类图像中可进行虹膜识别的图像(能提取虹膜特征并给于结果的图像)数量以及与所属情形相符的图像所占百分数(相符率), 并将可进行虹膜识别的图像进行虹膜识别时的正确识别率(correct recognition rate, CRR)、 等错率(equal error rate, EER)、 ROC曲线作为评价指标[15], 从实际识别效果上对虹膜质量评价算法进行评价. 4类图像中可进行虹膜识别的图像数量列于表3. 可进行虹膜识别的图像进行虹膜识别时的每种算法的类间、 类外及总匹配次数列于表4. 情形2)的CRR和EER列于表5, ROC曲线如图6所示. 表3 可进行虹膜识别的图像数量 表4 实验匹配数(个) 表5 正确识别率与等错率 由表1、 表3、 表5及图6可见: 文献[3]提出的基于二维Fourier频谱中的高频能量评价虹膜质量的算法, 是利用频域内的虹膜特征对虹膜质量进行判断, 该方法在其他空域转频域的过程中易失去一些信息, 对虹膜识别产生消极影响, 因此导致出现虹膜质量判定错误的问题, 并且因为频域特征不易被人类视觉所观察, 因此做虹膜活体检测时有些不便; 文献[4]提出的基于SVM的综合虹膜评价算法是以多种指标对虹膜进行粗分类与精分类, 该算法准确度高, 正确率达99.56%, 但计算复杂, 且虹膜合格条件过于严苛, 导致合格图像过少, 相比本文算法全部判定合格的情形, 该算法判定失误情形较多; 文献[5]提出的基于BP神经网络的质量评价算法使用神经网络进行虹膜识别, 进而模拟人的视觉认知, 更有助于识别算法的智能化, 但其需要使用大量虹膜进行测试, 调整相关结构与参数, 且BP神经网络过于复杂, 本身没有明确算法进行确定, 导致确定神经网络的结构需花费大量时间, 且一旦更换新的采集环境就要重新训练, 导致该算法实时性较差; 本文算法所保留的虹膜图像比其他3种算法多, 且保留下来的虹膜都可用作虹膜识别, 在识别中识别率也比其他3种算法高, 说明本文算法保留的虹膜确实可以进行虹膜识别, 且未对虹膜识别产生消极干扰, 属于有效虹膜, 有效扩充了虹膜数据, 增加了序列虹膜中的有效虹膜幸存率, 避免了过度删除而导致的虹膜信息流失, 同时节省了时间. 综上可见, 本文针对序列虹膜提出了一种基于形态学与灰度分布的虹膜质量评价算法, 利用Tenengrad梯度法去掉虹膜序列中模糊的图像, 采用二值形态学找到虹膜的内圆圆心, 进而根据连续帧的圆心半径的微小变化判断虹膜活体性, 利用瞳孔周边区域的灰度分布对虹膜区域进行判断, 提出超界偏移度和斜视离心度两个概念, 判断虹膜是否超出边界及虹膜斜眼情形. 使用不同的虹膜评价算法进行评价, 本文算法可在尽可能排除质量不合格虹膜的同时, 保留能进行虹膜识别的虹膜, 提高了有效虹膜的幸存率, 且时间相对较短, 步骤简单, 合格条件更宽泛.1.2 形态学与活体检测
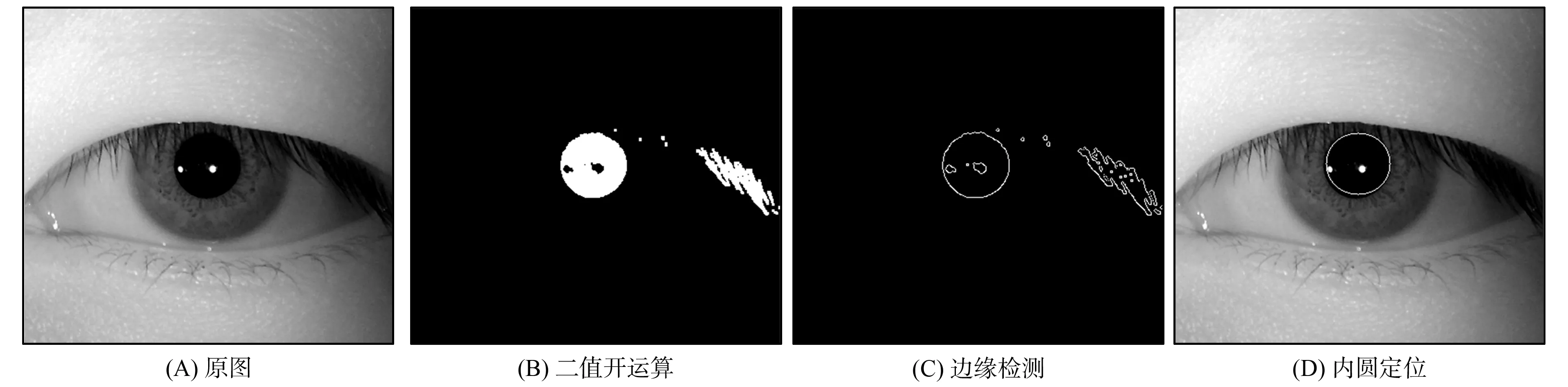
2 虹膜区域有效性的判定
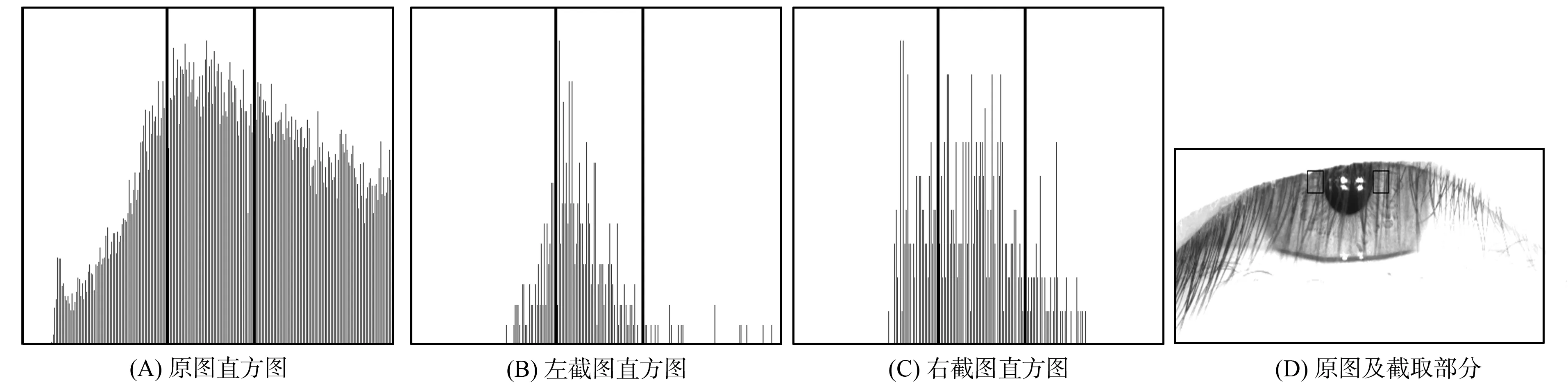
3 斜视与虹膜超边界问题
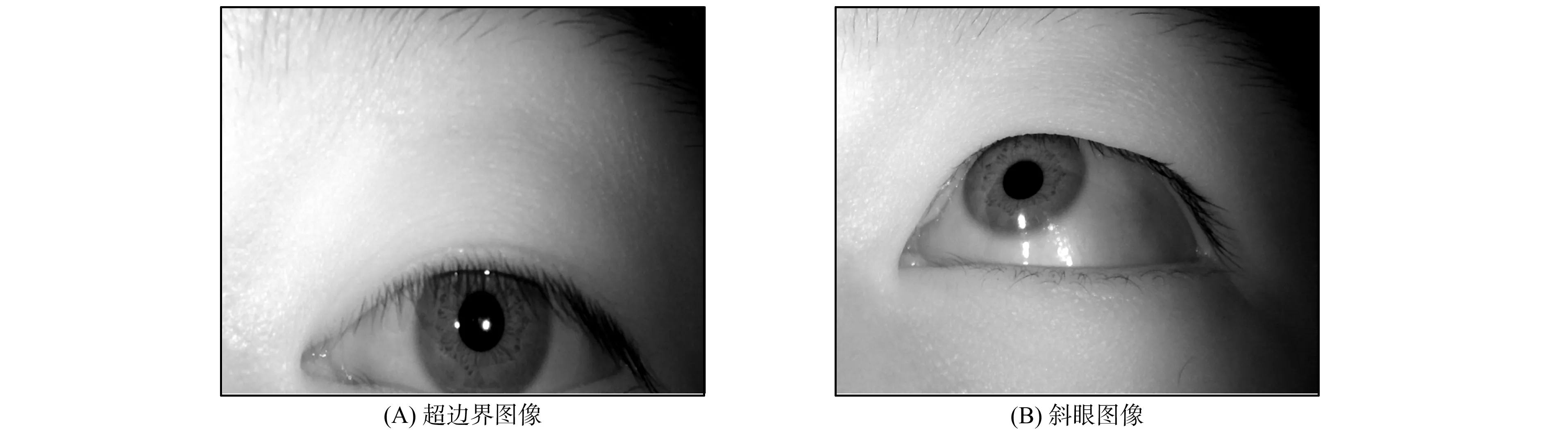
3.1 虹膜超界偏移度检测
3.2 虹膜斜视离心度检测
4 实验与分析
4.1 主观评价实验

4.2 算法评价实验






4.3 实验结果分析与算法评估
猜你喜欢
福建中学数学(2023年5期)2024-01-25 17:41:36
军事文摘(2023年20期)2023-10-31 08:42:40
中国典型病例大全(2022年11期)2022-05-13 17:54:50
青年歌声(2018年2期)2018-10-20 02:02:50
文萃报·周二版(2018年51期)2018-08-04 06:05:18
中等数学(2018年1期)2018-08-01 06:41:04
阅读与作文(初中版)(2017年6期)2017-07-05 17:17:15
学苑教育(2015年16期)2015-08-15 00:53:16
警察技术(2015年3期)2015-02-27 15:37:15
电视技术(2014年19期)2014-03-11 15:38:23
