
基于时间序列的音乐流行趋势预测研究*
2018-10-08 07:25郁伟生李蜀瑜
计算机工程与科学 2018年9期
郁伟生,邓 伟,张 瑶,李蜀瑜,
(1.陕西师范大学网络信息中心,陕西 西安 710119;2.陕西师范大学计算机科学学院,陕西 西安 710119)
1 引言
音乐是反映人类现实生活情感的一种艺术,当下音乐的流行趋势成为了众人关注的话题。在如今的大数据时代,音乐听众将会决定音乐的流行趋势。听众在众多音乐平台上试听、下载、收藏、分享音乐,以及在各大社交网络、视频网站、贴吧、论坛上对音乐进行关注、评论、转发、点赞,这些行为反映出听众对音乐的喜好。当今音乐的流行趋势,可以通过对听众的喜好趋向进行深度挖掘和分析预测获得。利用庞大的曲库资源和用户行为形成音乐大数据,通过精准的大数据分析,可以有效预测音乐的潮流走向,真正实现听众喜好的聚合决定音乐的流行发展趋势。
阿里音乐经过7年发展,现已拥有了数百万的曲库资源,及数亿次的用户试听、下载、收藏等行为。阿里举办的音乐流行趋势预测大赛基于阿里云平台强大的数据计算能力,通过用户的历史行为数据,预测下一阶段艺人播放量,挖掘出即将成为关注热点的艺人,从而准确把控未来音乐的流行趋势。本文以大赛复赛提供的音乐用户从2016年3月~8月的历史播放数据为基础,借鉴STL、Holt-Winters模型中的分解思想,分别从长期趋势、周期两个方面进行分析,对长期趋势编码和分类,并基于类别最优值选择和子序列模式匹配法,提出了E-TSMP(Extend-Time Series based Music Prediction)算法,最终在阿里音乐平台上实现了对2016年9月~10月艺人播放量较为准确的预测。
2 准备工作
对音乐流行趋势的预测可以采用时间序列、回归等预测模型来实现[1 - 7]。Li[8]提出的自回归积分滑动平均模型ARIMA(Auto Regressive Integrated Moving Average model),虽能很好地根据动态数据及自身的相关特征进行预测,但因ARIMA中差分次数d和p、q参数的选取不具备通用性,需对每个艺人数据预处理分类后逐一进行参数调整。Chatfield等[9]提出的三次指数平滑TOES(Three Order Exponential Smoothing)模型可以对同时含有趋势和季节性的时间序列进行预测,但该模型对数据集和时间段的选取比较敏感,此外针对高于二阶拟合的曲线会出现不可控的发散状态。Cleveland等[10]提出的STL分解(Seasonal and Trend decomposition using Loess)模型虽兼具通用性和鲁棒性,但只适合加法模型,且不能根据数据突然变化进行自动处理。Jain等[11]提出的递归神经网络RNN(Recurrent Neural Network)虽可以根据之前的数据给出相应反馈,并采用非线性动力系统,但收敛性差,即使加入相应的特征,预测效果也不理想。
采用ARIMA等时间序列模型中标准的时间序列函数对每个艺人的日播放量曲线进行拟合和预测,若需要预测的日期较长,容易出现过拟合等问题。在大数据环境下,对音乐进行流行趋势预测,应当对模型建立、算法设计、实验优化等方面进行综合考虑。
预测效果表示预测值和真实值之间的差距,通常定义一个打分函数来衡量预测效果。因此,阿里大赛给出相应的评估指标,用于判断预测值的准确度。设艺人j在第h天的实际播放量为Dj,h,艺人集合为A,算法预测得到艺人j在第h天的播放量为Sj,h,则艺人j的归一化方差σj可以根据艺人N天的实际播放量和预测值的方差求得:
归一化方差σj反映了预测结果Sj和实际播放量Dj之间的差距,(1-σj)值越大,表示预测越精准。根据当前艺人j的每日实际播放量相加后的算术平方根求对应权重φj:
定义打分函数F:
*φj
并以此作为预测标准,F值越大,预测值越接近实际值。
3 音乐流行趋势预测算法
在音乐的流行趋势预测过程中,借鉴了STL、Holt-Winters模型中的分解思想,在类别最优值选择法的基础之上,提出TSMP(Time Series based Music Prediction)算法。为了实现对音乐流行趋势更为精准的预测,基于子序列模式匹配法及对近期发布新专辑的附加处理,提出E-TSMP算法,针对2016年8月中下旬某些艺人的日播放量突然成倍增加的情况,有效地解决了该类情况下预测趋势后续走向问题。
3.1 TSMP算法
为了实现音乐更精准的流行趋势预测,需要对每个时间序列分别从长期趋势、周期、随机干扰项三部分进行分析。因为随机干扰项的不确定性,因此所有的研究都忽略了该部分。
阿里比赛提供了用户行为信息和歌曲艺人信息,其中用户行为信息记录用户对歌曲进行的播放、下载、收藏等操作,歌曲艺人信息包含歌曲专辑收录时间、初始播放量、歌曲语言、歌曲类别等内容。只有在提供的众多信息中提取出有效信息,才能更好地对数据进行分析,实现对每个艺人音乐播放量更为精准的预测。因此,把信息处理成每个艺人对应的日播放量序列、周播放量均值序列、月播放量均值序列及日变化率序列,对数据进行的预处理为TSMP算法的实现奠定了基础。
在对每个艺人日播放量曲线进行拟合和预测的过程中,曲线趋势发展成为了至关重要的问题,而重要的外部事件是影响曲线趋势发展的一大关键因素,比如:预测期间艺人发布新专辑、开演唱会、参加选秀节目等。在排除外部事件干扰的前提下,计算每个艺人播放量的月平均值、周平均值、日平均值并进行编码处理,这些编码处理的均值可以作为每个艺人播放量趋势的预测。定义基本趋势和增量趋势作为编码规则,例如月度编码:若当月播放量均值高于前一月均值,则基本趋势对应的编码值为1,否则为0;若当月播放量均值高于前一月均值,则以当月均值除以上月均值的商值取整作为增量趋势编码值,否则增量趋势编码值为上月均值除以当月均值的商值取整。具体编码过程如图1所示。

Figure 1 Coding method图1 编码方法
根据月编码、周编码、日编码中的基本趋势和增量趋势两部分,基于k-means聚类算法[12,13],最终将阿里提供的数据集划分成24个基本类别。通过对不同类别进行大量测试与分析,最终采用类别最优值选择法对不同类别的艺人进行日播放量预测。类别最优值选择法的思想是:选取时间序列的某个特征值作为其预测值[14],例如百分位数、后3天均值、后7日均值等,构成的如图2所示的候选方法预测集合用来选取特征值。
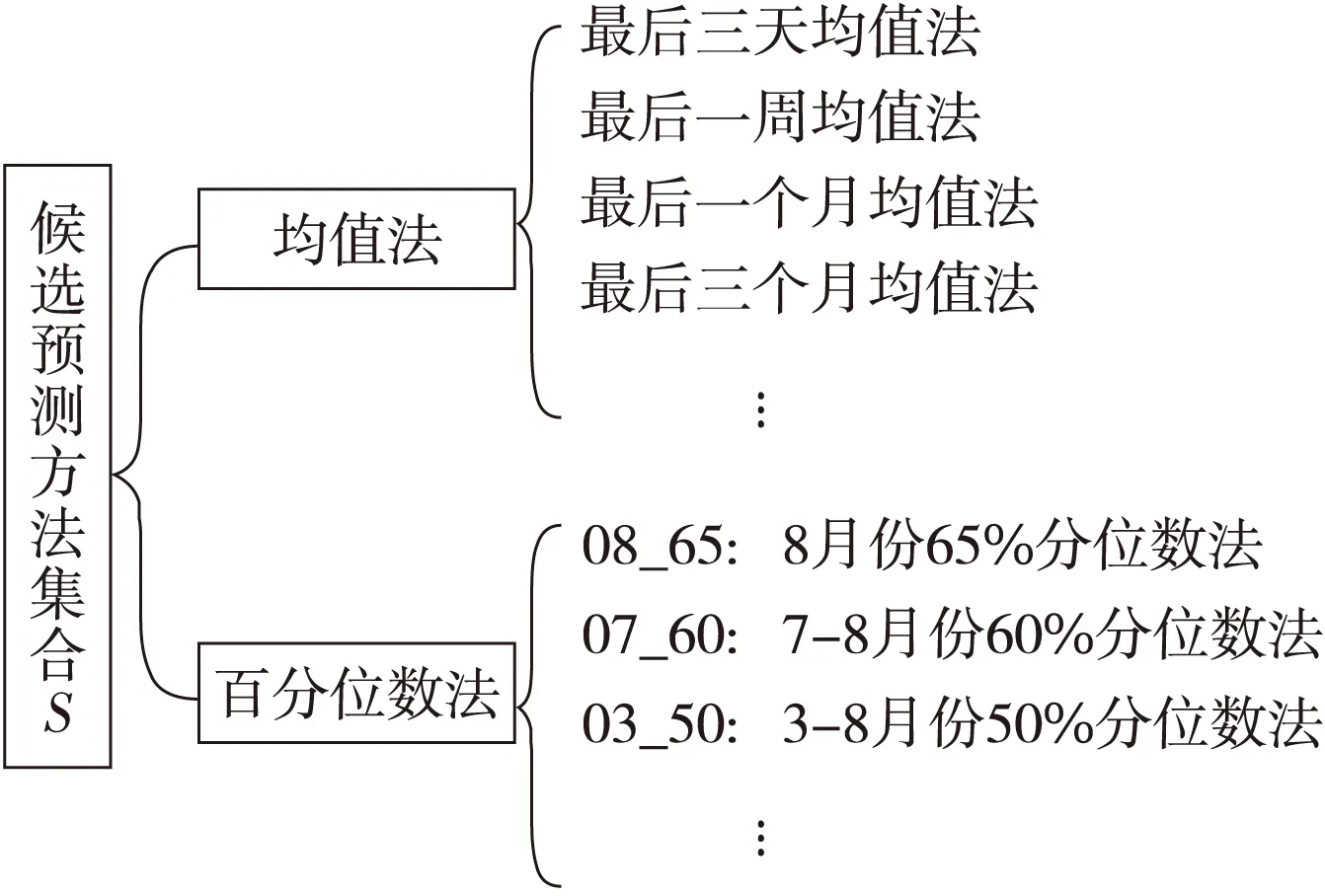
Figure 2 Candidate prediction method set based on eigenvalue图2 基于特征值的候选预测方法集合
大多数艺人的时间序列相对比较平稳,实验证明,若预测的天数较长,与波动性的曲线相比,均值的预测效果更好。采用3~7月数据作为训练集,8月数据作为测试集,进行预测值的特征值选取,将打分函数F计算的结果作为依据,并进行最大化选取,以便做最优预测。
对任意类Ck,候选方法集为S={s(1),s(2),…,s(n)},最优预测方法的选取公式为:
s=
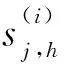
算法1类别最优值选择算法COVSA(S,Dk1,Dk2)
输入:S:候选方法预测集合;Dk1:类别Ck内所有艺人3~7月内日播放量序列(训练集);Dk2:类别Ck内所有艺人8月内日播放量序列(验证集)。
输出:m:类别Ck的最优预测方法。
Begin
f←0;m←s(1);/*定义打分函数初始值为0,m为最优预测方法*/
Fors(i)∈Sdo//遍历候选方法预测集合
S←Ss(i)};
P←s(i)(Dk1);/*对训练集采用候选方法s(i)得到8月份类别Ck内所有艺人的预测集*/
fi←F(P,Dk2);/*计算采用候选方法s(i)后的分数fi*/
iffi>fthen/*分数fi比之前方法获得的分数f高,重设s(i)作为最优预测方法*/
f←fi;
m←s(i);
end
end
Returnm;//输出最优预测方法。
End

Figure 3 Classification rules图3 分类规则
随机选出类别Ck中3~8月艺人j的音乐播放量作为数据集,应用类别最优值选择算法最终输出类别Ck的最优预测方法m,对于类别k中的其他艺人,用其最优预测方法m预测9~10月份的日播放量。具体分类规则及对应最优预测方法如图3所示。基于类别最优值选择方法,提出了TSMP算法,实现了对9~10月艺人总播放量的预测,伪代码如下所示:
算法2音乐流行趋势预测算法TSMP(U,A,S)
输入:U:3~8月用户行为数据集合;A:艺人基本信息集合;S:候选预测方法集合。
输出:P:9~10月所有艺人总播放量预测值。
Begin
P←0;//设初始预测值为0
(D,W,M)←Pre(U,A);/*把数据集U,A预处理为日、周、月播放量均值序列集D,W,M*/
(DT,WT,MT)←Cod(D,W,M);/*对数据集D,W,M进行日、周、月编码形成编码序列集DT,WT,MT*/
Ck←Sort(DT,WT,MT);/*采用k-means算法对DT,WT,MT进行划分构成类别Ck,及与类别对应的日播放量序列集DCk*/
Forck∈Ckdo//遍历分类集合
Ck←Ckck};
Pck←0;/*设类别ck中所有艺人9~10月总播放量初始值为0*/
m←COVSA(S,Dck);/*根据类ck内所有艺人日播放量序列Dck中3~8月的日播放量,由COVSA获得类别ck最优预测方法m*/
Pck←m(Dck);/*预测类别ck中所有艺人9~10月总播放量Pck*/
P←P+Pck;
end
ReturnP;/*输出9~10月所有艺人总播放量预测值*/
End
3.2 E-TSMP算法
在阿里提供的3~8月份数据集里,通过分析周编码、日编码的增量趋势部分发现,在8月中下旬部分艺人的播放量突然成倍增加,若对此类艺人继续使用最优预测方法,最终预测结果与真实值偏差会较大。因此,借鉴其他艺人历史数据中出现过的类似曲线,提出了子序列模式匹配法SSPMM(Sub-Sequence Pattern Matching Method),对该类别艺人的预测方法做了相应的改进。子序列模式匹配法思想是:首先计算所有艺人3~8月份歌曲播放量日变化率序列,根据观察及大量实验进行验证,最终选择截取待预测艺人最后15天的日变化率序列并作为待匹配子序列集 ,然后根据序列集中艺人的日变化率,找出与待匹配子序列集欧氏距离最小的5个子序列,选取其中后续子序列变化比较平稳的3个子序列作为最佳子序列, 最后求取最佳子序列的日变化率均值,作为待预测艺人的日变化率序列,计算出待预测艺人9~10月份的日播放量趋势中回落后的平稳部分的预测值。在回落过程,采用n段梯度法求取回落过程中的预测值,第i个回落点的预测值为:
其中,d1为回落点艺人的日播放量,d2为预测艺人平稳点的预测值。子序列模式匹配法的具体实现过程如图4所示。

Figure 4 Sub-sequence pattern matching method图4 子序列模式匹配法
此外对部分类别的预测值做了附加处理AD(Additional Processing):针对近两个月有新专辑的艺人,根据专辑的发布时间对时间做分段处理,依据以往发布专辑的艺人的播放量变化率,分别求取对应的权重因子α,对发布专辑后一段时间的日播放量的预测值的精确度做了相应提升,AD算法具体处理过程如图5所示。
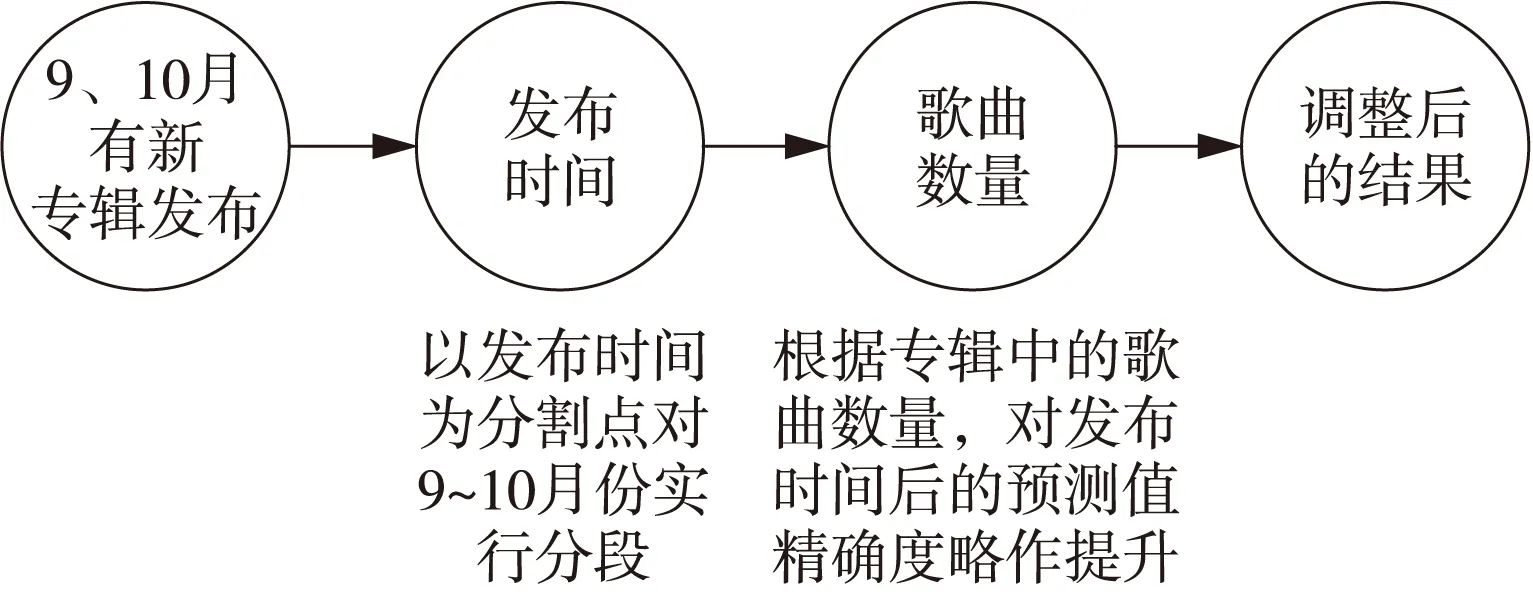
Figure 5 Additional processing图5 附加处理
在对所有艺人播放量的时间序列进行周期性叠加的实验中,预测效果并不理想。为了能得到良好的实验效果,在预测所有艺人的播放量的实验过程中,没有考虑周期性的叠加。基于类别最优值选择和子序列模式匹配法提出的E-TSMP算法,实现了对2016年9~10月艺人播放量更为精准的预测,伪代码如下所示:
算法3扩展音乐流行趋势预测算法E-TSMP(U,A,S)
输入:U:3~8月用户行为数据集合;A:艺人基本信息集合;S:候选预测方法集合。
输出:P:9~10月所有艺人总播放量预测值。
Begin
P←0;//设初始预测值为0
(D,W,M)←Pre(U,A);/*把数据集U,A预处理为日、周、月播放量均值序列集D,W,M*/
(DT,WT,MT)←Cod(D,W,M);/*对数据集D,W,M进行日、周、月编码形成编码序列集DT,WT,MT*/
Ck←Sort(DT,WT,MT);/*采用k-means算法对DT,WT,MT进行划分构成类别Ck,及与类别对应的日播放量序列集DCk*/
Forck∈Ckdo//遍历分类集合
Ck←Ckck};
Pck←0;/*设类别ck中所有艺人9~10月总播放量初始值为0*/
m←COVSA(S,Dck);/*根据类ck内所有艺人日播放量序列Dck中3~8月的日播放量,由COVSA获得类别ck最优预测方法m*/
Forckj∈ckdo//遍历ck类所有艺人
ck←ckckj};
Pckj←0;/*设置ck类中艺人j在9~10月总播放量的初始预测值为0*/
if suddenly increase then/*艺人j在8月中下旬的播放量突然成倍增加*/
Pckj←SSPMM(Dckj);/*用子序列模式匹配法预测ck类中9~10月艺人j的总播放量*/
else
Pckj←m(Dckj);/*用m预测ck类中艺人j在9~10月的总播放量*/
end
if publish then/*若艺人j近两个月发布新专辑,略提升发布专辑后的预测值*/
Pckj←AD(Pckj);/*采用AD算法,重新预测ck类中艺人j在9~10月的总播放量*/
end
Pck←Pck+Pckj;/*预测ck类中9~10月艺人j的总播放量*/
end
P←P+Pck;
end
ReturnP;/*输出9~10月所有艺人总播放量预测值*/
End
4 实验分析
本文以阿里比赛复赛提供的1 000位艺人10 842首歌曲,从2016年3月~8月的历史播放量作为实验数据,采用E-TSMP算法预测2016年9月~10月这1 000位艺人歌曲总播放量。基于阿里云的Map-Reduce框架,使用Java语言,实现E-TSMP算法。另外,使用Echarts实现报表的可视化,形象地展示艺人日播放量序列变化及预测值。在复赛中,参赛团队凭借提出的E-TSMP算法获得大赛第2名,大赛复赛排行榜如图6所示。
在E-TSMP算法中的类别最优值选择过程中,将均值及百分位数作为其预测方法集,而不是将波动曲线作为预测方法集,实验表明本文方法对均值预测的效果更理想。如图7分别采用后7天均值、后3天均值作为其特征值。
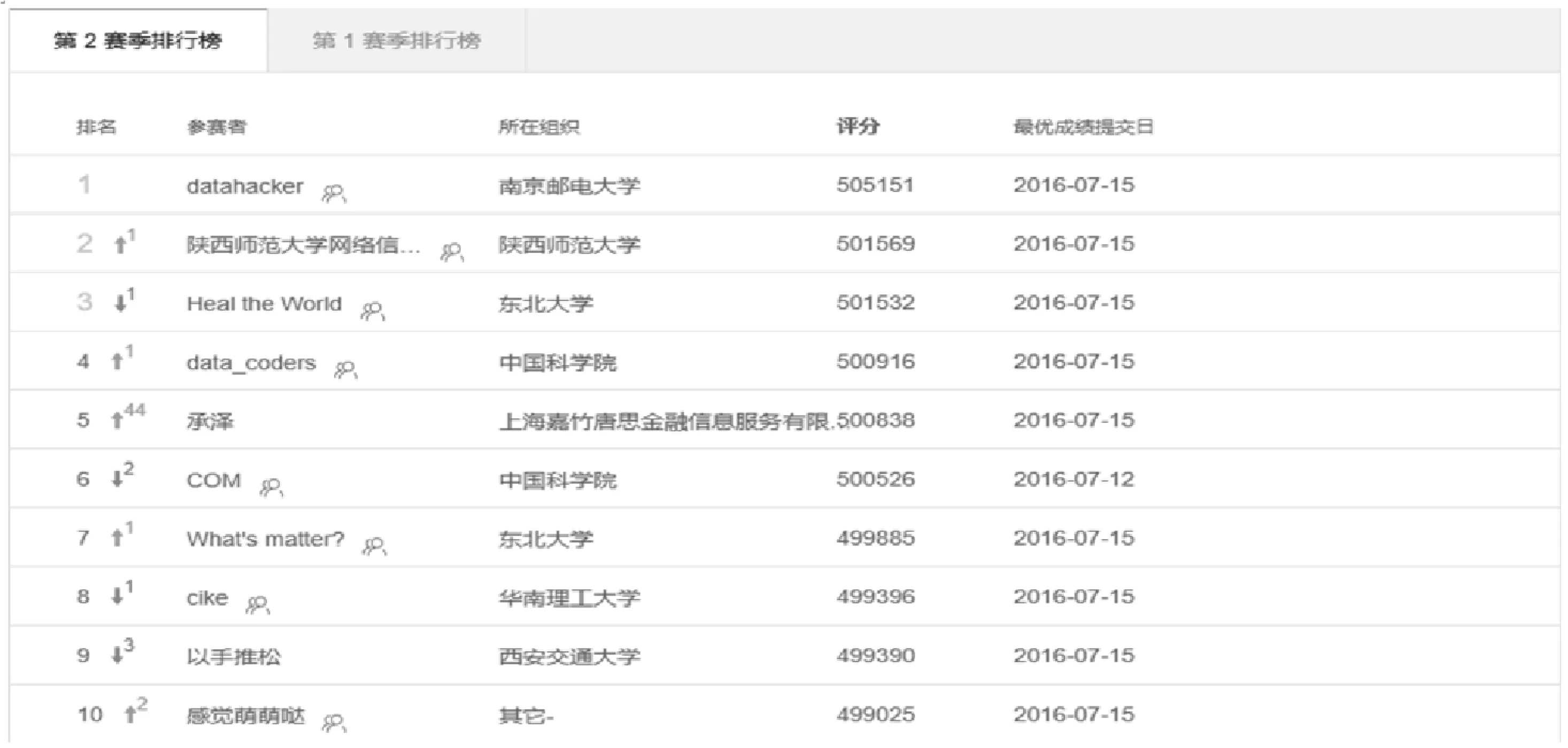
Figure 6 Competition ranking图6 比赛排名
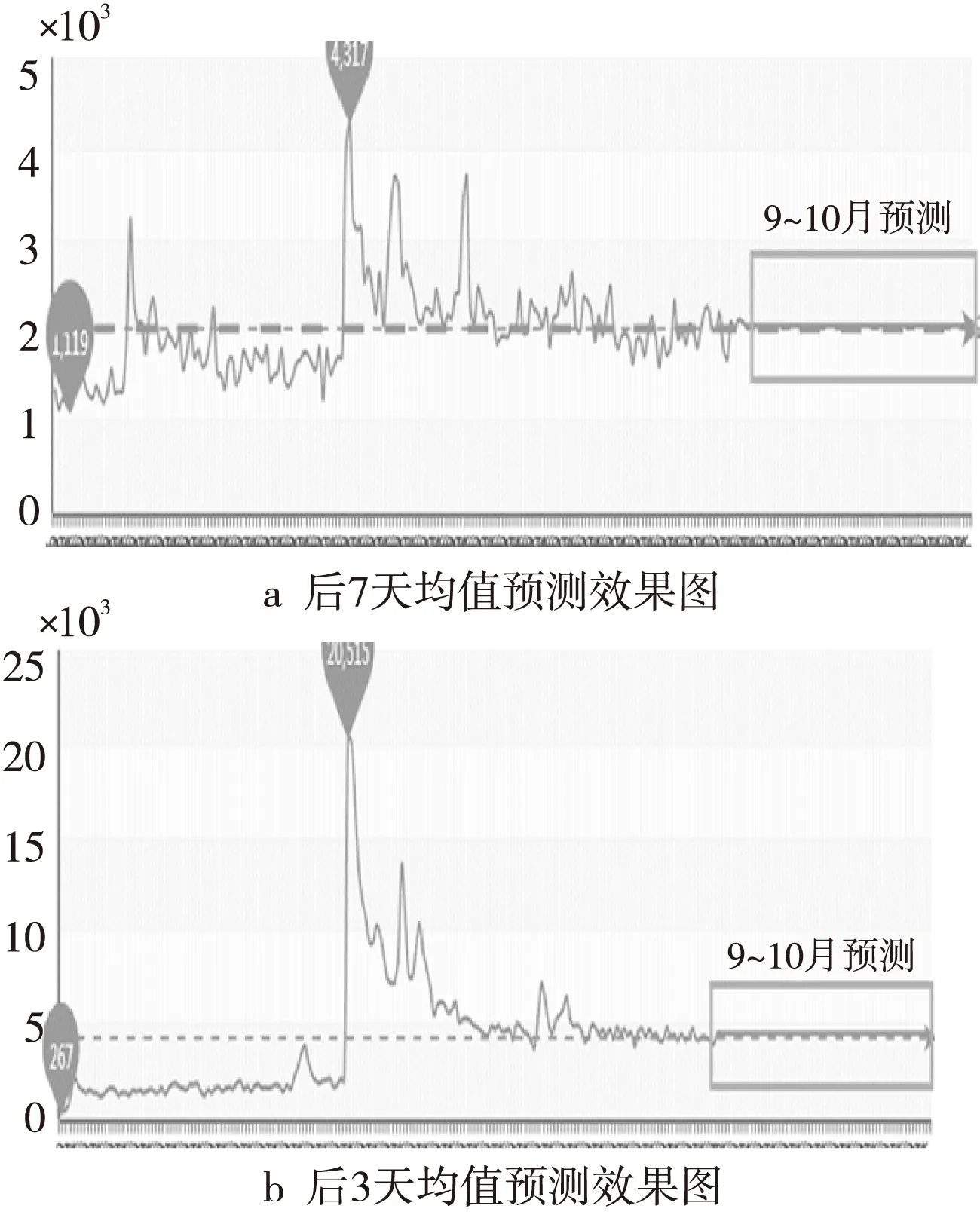
Figure 7 Experiment results of the category optimal value selection method图7 采用类别最优值选择法的实验结果
针对8月中下旬某些艺人播放量突然成倍增加的情况,采用E-TSMP算法中的子序列模式匹配方法进行预测,如图8所示,在回落的过程中,不同分段中预测值的变化以梯度回落方式来体现,为了对均值预测的精确度进行改进,使预测值更符合播放量的实际变化趋势;根据处理后的3个最佳匹配子序列的样本序列的变化率求得。

Figure 8 Experiment results of the sub-sequence pattern matching method图8 采用子序列模式匹配法的实验结果
通过对训练集中的数据进行分析发现,当艺人有新专辑发布时,在随后的20~30日内其播放量会有明显的提升。针对9~10月有新专辑发布的艺人,在E-TSMP算法中对此类别的预测值做了附加处理。如图9所示,艺人在9月有新专辑发布时,则对发布专辑后一段时间的日播放量有相应提升。
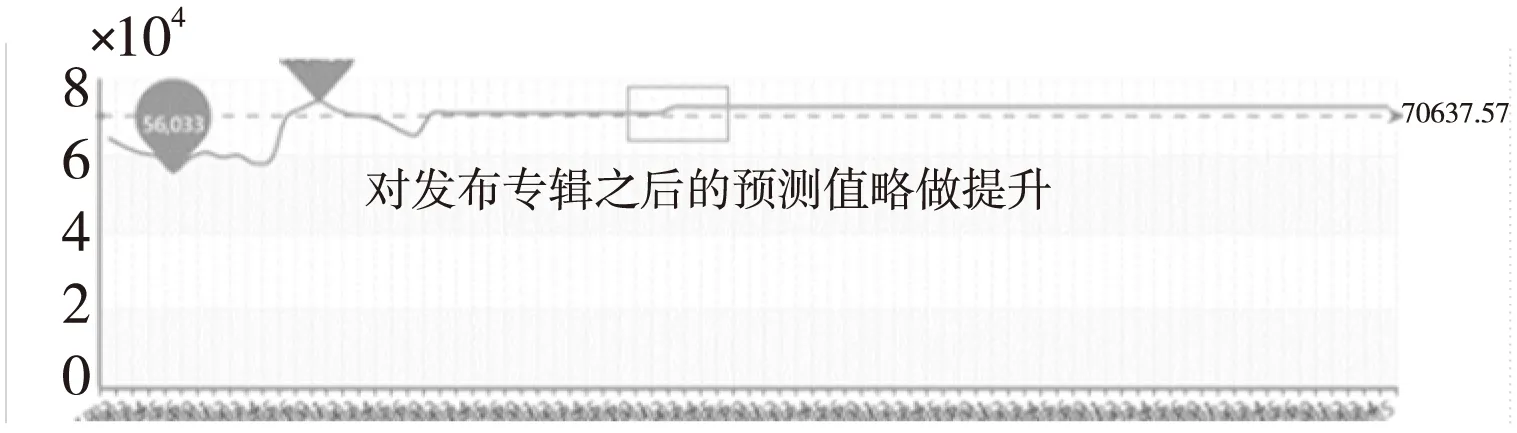
Figure 9 Experiment result of additional processing for releasing new album图9 针对新发布专辑进行附加处理的实验结果
在比赛期间曾对所有艺人做过周期性的判断和叠加处理,采用周作为提取和叠加的周期,预测结果如图10所示,叠加后导致评判分数有所下降,即降低了预测值与实际播放量的准确度,分析原因如下:
(1)周期性是根据每个艺人样本集的时间序列的最后10周70天的日播放量进行提取的,提取出来的周期性在未来60天的预测结果中不一定存在。
(2)周期性是在预测趋势的基础上进行叠加的,若预测趋势的偏差过大,进行周期性叠加的结果可能会适得其反。
故最终提出的E-TSMP算法未对所有艺人的预测值进行周期性的叠加。
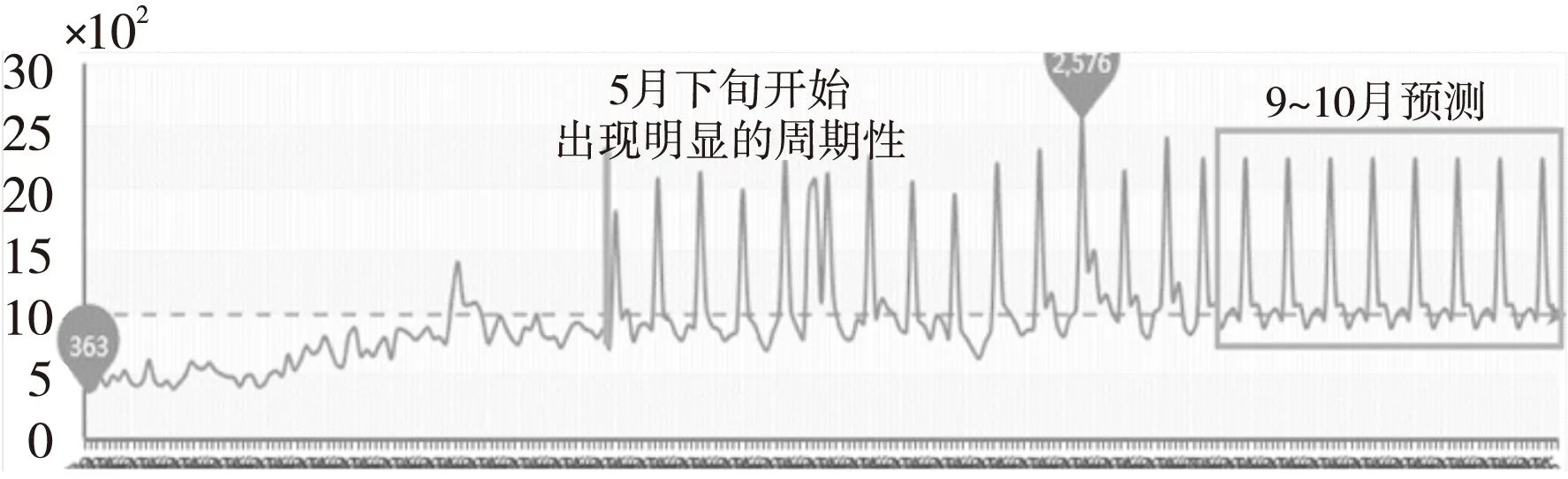
Figure 10 Experiment result of periodic overlay图10 周期性叠加的实验结果
5 结束语
在大数据环境下针对音乐的流行趋势预测,本文借鉴了STL、Holt-Winters模型中的分解思想,在基于类别最优值选择和子序列模式匹配等方法 以及对艺人近期发布新专辑的附加处理的基础之上,提出E-TSMP算法。基于阿里云的Map-Reduce框架,在阿里音乐平台上实现了对2016年9月~10月艺人播放量较为准确的预测,并使用Echarts工具实现报表的可视化,直观形象地展示了艺人日播放量序列变化及预测值。
猜你喜欢
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
电子产品世界(2021年6期)2021-02-10
学生天地(2018年32期)2018-11-07
海峡姐妹(2018年8期)2018-09-08
民族古籍研究(2018年1期)2018-05-21
海峡姐妹(2018年1期)2018-04-12
儿童故事画报·发现号趣味百科(2016年6期)2016-08-19
新校长(2016年8期)2016-01-10
浙江大学学报(工学版)(2015年1期)2015-03-01
