
并行科学计算应用中采样数据的聚集I/O*
2018-10-08 07:23曹立强罗红兵
计算机工程与科学 2018年9期
曹立强,罗红兵
(北京应用物理与计算数学研究所,北京 100088)
1 引言
科学计算应用不仅输出可视化(Visualization)和检查点(Check Point)数据,也输出采样数据(Sample Data)。一般的串行科学计算应用中,数据场规模较小,采样输出量少,不容易发生采样数据的I/O瓶颈。然而,一些并行科学计算应用设定的采样点数量较多,I/O较为频繁,采样数据I/O容易发生瓶颈制约。以美国模拟惯性约束聚变的pF3D程序[1]为例。在超算TOP500上榜的Intrepid系统[2]中,16 000个进程的pF3D程序在完整的运行周期中输出3.43 GB采样点数据,耗时245 s,约占程序总运行时间的20%。采样数据I/O的平均带宽为14 MB/s,远低于该机并行文件系统I/O带宽[3]。在一些与实际问题密切相关的算例中,国内的电磁场仿真程序JEMS-TD等也出现了采样数据I/O的性能瓶颈。
通常,可视化与检查点数据在空间上是数据场的全集,采样数据是数据场的子集。采样数据以几何拓扑或者其它形式约束在数据场的特定区域,价值密度高于可视化数据[4]。通过对可视化数据与采样数据的统计分析,用户可以发现代表性的科学规律。然而一些并行科学计算应用可以设置数以万计的采样点,并且在迭代循环中频繁输出采样数据,因此它的I/O次数较多。
高性能计算机中,规模较小而读写较为频繁的数据不容易发挥并行文件系统的性能[5]。除了pF3D程序外,国内的一些大规模并行应用,例如模拟三维电磁场的JEMS-TD程序[6]、电磁耦合程序LAP3D[7]等,也在一定程度上遇到采样数据I/O的带宽制约。此外,当并行程序发生动态负载平衡与重启动运行时,一些应用还出现采样数据存储的不一致问题。优化采样数据的并行I/O效率、确保并行采样数据的I/O一致性成为提高并行程序运行效率、保障并行程序正常运行的关键问题。
面对大规模并行科学计算应用采样数据快速存储需求,本文研究采样数据的并行聚集I/O优化方法。
2 采样数据并行I/O
现有采样数据的并行I/O可以分为应用采样和数据输出两个步骤。首先,应用采样。应用程序从数据场中选择、读取、记录采样点位置的数值,记录在〈key,value〉对中;然后程序查找采样点对应的文件,将变量值写入其中,形成与采样点一一对应,按时间、列序存储的采样数据文件集合。
大部分科学计算应用中,每个采样点每次仅仅输出几十到几百字节数据。参与I/O的进程多,每次读写数据量少是造成采样点I/O瓶颈的主要原因。通常,文件访问开销可分解为数据I/O开销和文件系统元数据开销两部分[8]。前者主要与数据块大小和I/O带宽相关;后者主要与目录(Directory)中的文件数量相关。在单机系统中,进程数量、计算规模受到结点计算能力、内存容量和存储容量的限制,文件数量少。元数据操作较少成为瓶颈。
并行文件系统与单机文件系统的性能特征不同。它一方面具备较高的并行I/O带宽,另一方面有较高的元数据访问延迟。此外,并行应用的计算规模可以比串行应用高出4个以上量级,其中采样点数量也远远超出串行程序,与之对应的采样点文件数量也会增长。较多的文件数量增加了并行文件系统元数据访问延迟[9]。
领域专家对元数据访问性能与文件数量的关系已经有一定认识。在pF3D程序采样数据的并行I/O过程中,Langer等人通过多级目录存储采样文件等方法减少同一层次的文件数量,提高文件系统元数据的访问效率。测试表明,该方法可以有效缩短元数据访问延迟,从而提高并行I/O效率。虽然该方法有一定效果,但是使用多级目录后采样数据管理的难度增加,而且I/O调用数量与每次读写的数据大小没有变化,有进一步优化的空间。
MPI(Message Passing Interface)的集合并行I/O优化方法可以提高小块数据的并行I/O效率[10]。常用的集合并行I/O加速方法包括两阶段I/O[11]和Data Sieving[12]等,它们可以重组大量小块数据I/O成为少量大块数据I/O。
两阶段I/O首先从参与并行计算的进程中选择若干进程存取数据。输出时,被选中的进程按一定规则接收其余进程的数据,合并原本小而非连续的数据块成为大而连续的数据块,再输出到磁盘中达到加速目的。数据输入的过程与输出过程相反,被选中进程从文件系统获得数据,然后将数据分配给参与计算的进程。虽然有多种并行I/O性能读写优化方法,但是这些优化方法往往局限在进程间的数据合并与拼接方面,不适用于迭代生成、逐渐累积的采样数据。
3 采样数据的并行聚集I/O方法
科学计算程序在一个迭代步可以从一个采样点获得几个到几百个字节的数据,一般并行输出方法在采样点与文件之间建立映射,然后按迭代步向文件中增加数据,形成按文件存储的采样数据集合。这种I/O方法不仅产生较多文件和小数据I/O,降低并行I/O效率,还难以处理动态负载平衡与并行应用重启动等较复杂的并行程序运行态[13]。
动态负载平衡与重启动是并行程序,尤其是大规模并行程序特有的运行状态,它们影响采样数据存储的一致性。在并行程序的动态负载平衡过程中,采样点所在进程编号随负载的调整而变化,它们改变了进程与文件的对应关系,增加了数据失效的风险。在并行程序重启动运行过程中,部分进程的时序发生变化,一些计算过程被重复执行,如果其中包含采样输出,将导致采样数据的不一致。
针对上述现状,我们设计了采样点数据并行聚集I/O方法,它的主要特点在于:(1)使用共享文件(Shared-one-file)并行I/O模式存储采样数据,降低文件数量;(2)在客户端内存中设置采样数据缓存,临时存储数据,降低小块数据的I/O次数;(3)使用HDF5(Hierarchical Data Format release 5)数据格式库[14],提供高效率、增量式的I/O支持。
3.1 采样点数据的共享文件I/O
在并行应用中,根据进程与文件关系,并行I/O主要分为共享文件与进程-文件对应(File-per-process)两种模式。如果参与并行计算的进程同时向一个文件输出数据,那么这种并行I/O模式是共享文件I/O模式;如果参与并行计算的进程同时向多个文件输出数据,那么这种并行I/O模式是进程-文件对应并行I/O模式。
对比两种并行I/O模式,共享文件并行I/O模式输出的文件少,可以减少文件系统元数据操作时间,但是它存在文件描述符等共享资源,在一定程度上影响数据传输效率。进程-文件对应模式的进程间没有共享的资源,但是它创建较多文件,元数据开销高,对并行可扩展性有一定影响。
采样数据一般具有存储量较少、数据来源较多等特点,元数据操作延迟是主要的开销来源。本文在两种并行I/O模式中选择共享文件并行I/O模式,减少文件数量,降低文件系统元数据开销。
共享文件并行I/O模式在采样点与文件之间建立多对一的映射关系。使用这种并行I/O模式,我们实现了采样数据的聚集I/O方法。该方法中,不同的采样点存储于不同的数据集,多数据集存储到一个文件。为了提高并行I/O效率,并行聚集I/O方法将采样数据I/O分解为数据采集与数据输出两个过程,两者以聚集缓存耦合在一起。数据采集过程中,采样数据按遍历序排列;在多个时间步之间,数据按时间步采样顺序缓存。输出时,各进程首先转置采样点数据缓存,将数据排列顺序调整为按时间步存储,然后输出数据到文件,如图1所示。

Figure 1 Aggregation and transposition I/O of sampled data图1 采样数据的转置与聚集I/O
图1中,每个方框代表了一个采样点数据。假设0进程是输出进程,部署聚集缓存。0号进程有2个采样数据,1号进程有3个采样数据,n号进程有1个采样数据。聚集输出过程中,采样数据按行序从应用中读出,然后以列序缓存在各个进程。输出前,各进程将缓存数据聚集到0进程,输出到HDF5。
3.2 采样数据缓存的状态管理
采样点数据缓存在应用层,它合并采样数据,减少I/O次数。使用采样缓存过程中,需要保障采样点数据存储的一致性。用户可以根据内存容量与采样点数量等参数设定刷新步间隔,提高采样点数据的存储效率。
根据设置,系统使用生产者-消费者模型管理采样数据缓存,当缓存未满时,它可以不断地接受数据;当缓冲区满时,系统输出采样数据并清空缓存,然后才能暂存数据。与一般的生产者、消费者控制流程不同,采样点数据的生产者-消费者模型有多源控制的特征。这里的多源控制是指:消费者不仅考虑缓存使用情况,还需要考虑动态负载平衡、重启动等因素的影响。
负载平衡过程中,采样点的处理器编号有可能变化,因此需要刷新缓存,重新计算采样点在进程间的分布情况。在重启动运行过程中,一些进程需要重演重启动步与失效步之间的计算,在此过程中,数据已经采样并存储,需要跳跃部分时间步,以保障存储的一致性。我们使用图2的自动状态机控制采样点缓存。
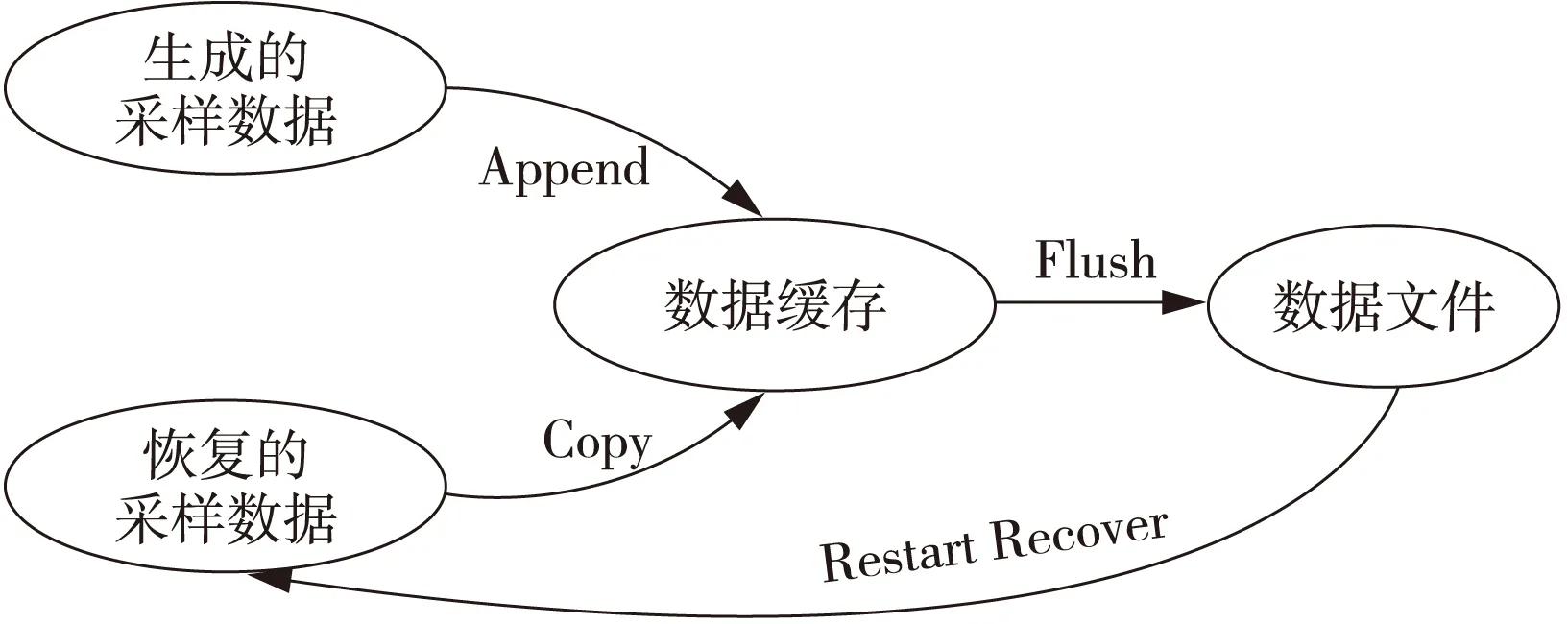
Figure 2 FSM of aggregated buffer图2 缓存的自动状态机
运行过程中,并行程序不断地生成采样数据,这些数据被增加(Append)到缓存中,直到缓存满,数据被刷新(Flush)到文件。如果是重启动运行(Restart Recover),那么需要首先判断采样点数据文件状态,获取已经输出采样数据的名称、状态和位置;然后根据状态拷贝(Copy)数据到缓存中,保证采样数据一致性。如果发生负载平衡,那么采样点数据也要被刷新到文件中,同时清空缓存。
3.3 增量式的数据存储
采样数据一般根据来源按列存储成数据集合,集合大小随着迭代步的增加逐渐增长。一般的I/O库递增数据集合需要读出原始数据,添加数据后再输出,覆盖或删除原始数据集。上述过程不仅操作步骤较多,效率也受到一定影响,为此,我们使用HDF5的Chunk I/O功能实现数据集的递增式输出[15,16]。HDF5有数据块的空间管理功能,它可以将分散的数据块虚拟成逻辑上连续的数据块。使用Chunk I/O后,向数据集合增添数据只需要分配新的数据块,不需要回读数据,因此效率较高。
跨平台、跨应用的数据存储是使用HDF5数据格式的另一个优点。使用HDF5存储的浮点数据,可以在不同平台、不同应用间共享,提高了采样数据的应用范围。
通过共享文件并行I/O模式、用户层的采样数据缓存和HDF5的Chunk I/O方法,我们不仅扩展了采样数据的应用范围,还可以在保持采样数据存储一致性的同时减少采样文件数量和I/O次数,优化I/O流程。上述方法可以提高采样数据的并行I/O效率。
4 软件实现
我们在北京应用物理与计算数学研究所研制的JASMIN并行编程框架中集成采样数据并行I/O库[17]。JASMIN框架有比较完善的软件体系结构,其中的状态变量可以反映程序的运行状态。例如,本次迭代之前是否发生过负载的动态调整,或者是否是从重启动运行等,这些状态可以辅助调整采样数据的I/O策略。
对于一般的并行程序,JASMIN框架预定义了hierarchy-level-patch三层数据组织结构。Patch内部包含数据片(Patch Data),数据片与变量对应。变量和数据片等定义提高了领域编程的代码重用率。我们集成采样数据并行I/O库如图3所示,其中VizCurveWriter是JASMIN框架与并行I/O库的耦合模块,中间SamplingVariable定义采样点数据类型,SamplingData是采样点数据来源。

Figure 3 Class diagram of writing sampled data图3 采样数据输出模块类图
JASMIN框架中,PatchData是数据容器。采样点数据由变量类SamplingVariable、数据片工厂类JSamplingDataFactory和数据片类SamplingData定义,它们分别派生自框架的Variable、PatchDataFactory和PatchData基类[18]。
采样点变量(SamplingVariable)是为采样点数据设置的变量,它说明从一个采样点可获得的数据类型、数量等信息。采样点数据片(SamplingData)为采样数据分配空间,每一个迭代步,用户程序向采样点数据片赋值。VizCurveWriter基于HDF5数据格式库研制,它以行序缓存采样迭代步的数据。输出前,输出转置成列序,然后调用HDF5接口输出数据。
5 性能测试
使用JEMS-TD并行科学计算应用,在工作站和高性能计算机中比较采样数据的聚合输出与直接输出性能。JEMS-TD是基于时域有限差分方法求解Maxwell方程组的全矢量三维电磁模拟仿真软件。通过精确建模及全波电磁模拟获得时域电磁近场和远场信息,可实现天线分析、飞机、舰船等大型复杂装备的电磁耦合及散射特性。在计算实际问题时,用户通常希望获得某些关键点的电磁场时域波形,这需要在每个迭代步输出采样数据。
我们使用的工作站包含1个Intel i7-3770四核处理器、8 GB内存和1个500 GB SATA3硬盘,其上安装Fedora18 Linux操作系统,内核版本号为3.6.10-4,编译器版本为gcc-4.7.2。设定JEMS-TD程序的数据场规模为60×60×60,采样点在三维数据场中均匀分布。其中,x方向和y方向最少部署1个,最多部署8个,z方向最少部署1个,最多部署16个。采样点数量从1扩展到1 024。使用4进程并行执行350个迭代步,每次迭代过程中,每个采样点输出32 B数据,总采样数据量从11.2 KB扩展到11.2 MB。聚集与非聚集输出带宽比较如图4所示。

Figure 4 Bandwidth comparison of the sampled data for JEMS-TD program图4 JEMS-TD程序采样数据输出带宽比较
图4中,buffer代表并行聚集输出,direct代表传统输出方法。在采样点数量逐渐增加过程中,并行聚集输出带宽比直接输出带宽平均高49倍。聚集缓存不仅减少了I/O次数,也增加每次I/O数据量,这是并行聚集输出方法提高性能的主要原因。
我们使用的高性能计算机包含128个计算结点,每个计算结点包含双路12核Xeon 2680处理器和64 GB内存。总计包含3 072处理器核,峰值计算性能约120 TFlops。网络系统由Intel OMNI网络组成,理论带宽100 GB/s。并行文件系统包含6组I/O服务器,总存储容量590 TB,峰值I/O带宽可达8.3 GB/s。
设定并行进程数量从24到1 536,采样点数量从128个增加到8 192个。程序运行350步,每步采样,每个采样点输出4个双精度浮点数,总计输出1.4 MB~175 MB采样数据。传统的非聚集I/O方法将产生128~8 192个采样文件,每个文件只有11.2 KB。聚集I/O方法设定每100步刷新采样缓存,如果不发生负载平衡与重启动运行,通信聚集数据后,16次HDF5调用存储所有的采样数据到一个文件中。通过弱可扩展性对比采样点数据的并行聚集I/O与直接输出性能,如图5所示。

Figure 5 Bandwidth comparison of parallel writing sampled data图5 并行输出采样数据带宽比较
图5表明,24~1 536进程的并行聚集输出方法平均提高7.5倍I/O带宽,最高可达15.3倍。机群系统网络测试中发现384进程通信存在性能奇点。由于网络性能影响,对应的并行聚集I/O方法加速效果受到限制。如果排除网络通信的性能奇点,那么并行聚集I/O方法的平均加速效果可以进一步提高。
6 性能分析
通常,一次I/O操作的时间可分为元数据操作时间和数据操作时间两部分。前者与文件数量相关,文件数量越多,元数据操作需要的时间越长;后者与传输的数据规模成正比,在采样数据I/O过程中,虽然每次读写数据量较小,但是由于采样点文件的数量较多,每次I/O的元数据开销较高,造成每次I/O过程中时间开销较高。在应用程序的执行过程中,采样数据的读写通常比较频繁。上述因素是采样数据I/O时间较长的主要原因。
串行测试中,虽然采样点文件数量少,但是较多的I/O调用、较小的数据块导致非聚集输出性能较低。使用缓存后,原始的小块数据被合并,大量较小的I/O调用转化为少量的大块I/O调用,这是提高性能的主要原因。
并行测试中,聚集缓存一方面减少采样点文件数量,另一方面将大量较小的I/O调用转化为少量的大块I/O调用。对于每一个较小的采样数据,使用并行聚集I/O方法时首先被缓存,然后通信,聚集到输出进程,写入到文件。这虽然增加了操作步骤,但是聚集缓存输出不仅提高数据传输和数据I/O的粒度,还减少文件数量,降低文件系统元数据操作开销。对于采样数据这种对大量文件中的小块数据频繁I/O的场景,能够提高性能。
大规模并行计算应用的进程数量可以达到数万以上,全应用采样数据的并行聚集时间开销高,可以采用分组并行I/O的形式提高并行聚集I/O的扩展性。在分组并行I/O中,数百至数千进程分为一组,组内聚集输出,组间无共享信息,不需要同步,进一步提高大规模并行应用的采样数据输出效率。
7 结束语
与科学计算可视化数据和检查点数据相比,采样数据具有不同特征,它们的数据来源分散,每次采样产生的数据量往往较小。一般的采样数据读写方法不仅产生较多文件,还以小块数据频繁增量I/O模式为主。这些I/O特征不能在高性能计算机中发挥文件系统的性能。本文设计了采样点数据的聚合并行I/O方法,并在JASMIN框架中实现。该方法首先使用采样缓存合并采样数据,将小块数据I/O改变为较大块数据I/O;然后聚集输出到文件,减少文件数量。在I/O过程中,我们控制缓存状态,以保障并行I/O过程中采样数据的一致性。实际应用表明,该方法可以高效率地支持科学计算应用并行输出数百上千采样点数据。在串行平台测试中,对于不同的采样点数量,该方法平均提高I/O带宽49倍;在并行平台的测试表明,对于不同的进程数量,该方法平均提高并行I/O带宽7.5倍。
猜你喜欢
中国外汇(2019年20期)2019-11-25
家庭影院技术(2019年8期)2019-08-27
中国外汇(2019年8期)2019-07-13
小学生学习指导(低年级)(2019年3期)2019-04-22
小猕猴智力画刊(2016年6期)2016-05-14
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
现代企业(2015年5期)2015-02-28
火炸药学报(2014年1期)2014-03-20
民主与科学(2014年3期)2014-02-28
