
融合词语共现距离和类别信息的短文本特征提取方法*
2018-10-08 07:25马慧芳邢玉莹张旭鹏
计算机工程与科学 2018年9期
马慧芳,邢玉莹,王 双,张旭鹏
(1.西北师范大学计算机科学与工程学院,甘肃 兰州 730070;2.桂林电子科技大学广西可信软件重点实验室,广西 桂林 541004)
1 引言
随着微博、社交网站等应用的发展,越来越多的信息以短文本的形式存在且呈爆炸式增长。快速有效地从海量短文本数据中获取所需要的关键信息,短文本挖掘技术发挥着非常重要的作用。短文本特征极度稀疏且难以提取。通常来说,特征获取主要有两大类方法:一类称为特征选择[1],指的是从原有的特征中提取出少量的、具有代表性的特征,但特征的类型不发生变化;另一类称为特征抽取[2],是指从原有的特征中重构出新的特征,新的特征具有更强的代表性。
传统的词条加权方法主要分为两种:无监督的词频TF(Term Frequency)、词频-逆文件频率TF*IDF(Term Frequency*Inverse Document Frequency)[3,4]和有监督的tf*χ2(term frequency*chi-square)、tf*ig(term frequency*information gain)[5]等。采用无监督的方法能够给词条加权,却忽略了短文本的类别信息。有监督的词条加权方法[6,7]将其考虑进来,并在一定程度上提高了短文本特征提取的表现力。
与长文本相比,短文本具有特征高度稀疏的特点。从词项共现角度来看,两个词项的关联性可从词项共现的角度体现,且短文本所包含的词语稀少,两词项之间相隔词项的距离对语义信息的计算也造成了一定的影响;从类别信息的角度来看,特征词在类间的分布以及在类内部文档中的分布情况可以考虑进来进行综合加权。一方面,若特征词在各个类间分布比较均匀,这样的词对分类基本没有贡献,若特征词比较集中地分布在某个类中,而在其它类中几乎不出现,这样的词就能够很好地代表这个类的特征。如何将这种词语的类别信息挖掘出来是至关重要的。
基于以上考虑,本文提出了一种新的短文本特征提取方法,即融合词语之间的共现距离和类别信息的短文本特征提取方法CDCISE(Combining term co-occurrence Distance and Category Information for Short text feature Extraction)。首先,计算词项之间共现距离相关度,同时结合词项在整个文本的共现区分度,并以此为依据对词项进行加权;其次,改进期望交叉熵计算方法,充分考虑短文本的类别信息,使得在对短文本进行特征提取时更加合理;再次,将共现区分度和类别信息结合计算词条权重,避免了传统的基于词频的文本特征提取方法表现力较差的问题;最后,使用该方法分别在中文、英文的数据集上进行实验,实验结果表明,该方法有效地提高了短文本特征提取的效果。
2 相关理论
2.1 特定文本中词项的相关度
给定短文本集合D={d1,d2,…,dm}和词项集T={t1,t2,…,tn},词项ti与词项tj在特定短文本ds中的相关度的计算公式如下:
(1)
其中,distds(ti,tj)为词项ti与词项tj在短文本ds中的共现距离[8],由这两个词项之间相隔的词项数计算得出,即|j-i|-1。例如,短文本d1“社交网络环境下的隐私保护策略”在经过停用词过滤、文本分词的预处理过程后变为“社交 网络 环境 隐私 保护 策略”,词项“社交”与词项“隐私”之间的共现距离distd1(社交,隐私)=2。传统的距离计算方法在计算两个词项之间的距离时忽略了两词项与其相隔词项之间的语义联系,采用共现距离的计算方法,将词项的上下文语境考虑进来,使得计算结果更为可靠。利用词项之间的共现距离来计算两个词项之间的相关度与传统的计算相关度的方法[9]相比也显得更为合理。由于计算公式(1)时需要遍历语料库中所有词项,因此计算的时间复杂度为O(n2)。
2.2 期望交叉熵
期望交叉熵ECE(Expected Cross Entropy)是一种基于信息论的特征选择方法,它反映了文本类别的概率分布以及在包含某个特征词时文本类别概率之间的距离,考虑了词频以及词项和类别之间的关系。ECE值越大,表明该特征词越能表示一个类的特征,即该特征词对类别分布的影响越大。词项ti的ECE值计算公式如下:
(2)
其中,P(ti,ds)表示词项ti在短文本ds中出现的概率;P(Cr)表示Cr类短文本在短文本集D中出现的概率;P(Cr|ti)表示短文本ds包含词项ti时属于类别Cr的概率。
3 融合词语共现距离和类别信息的短文本特征提取方法
3.1 基于词语共现距离的词条加权方法
短文本特征提取是短文本挖掘技术的关键步骤,可以帮助人们快速有效地从海量数据中获取关键信息。
特征提取实质上是一个文本降维[10]的过程,其目的是通过剔除决策意义不大的词项进而提高短文本分类的准确性和效率。传统的词条加权方法未充分考虑词语之间的语义信息和类别分布信息,本文提出的融合词语共现距离和类别信息的短文本特征提取方法的总体流程如图1所示,具体由如下几个步骤构成:
步骤1对k类测试短文本集合D′进行预处理得到k类短文本集合D和词集T;
步骤2利用词语之间的共现距离计算每个词项的关联权重;
步骤3利用期望交叉熵对某个类中的每个词项计算其ECE″值;
步骤4结合步骤2和步骤3的计算结果得到某个类别中所有词项的权重值,分别将不同类别中的词项按权重值进行降序排序,取前K个作为特征词,构造出新的特征词项集合。

Figure 1 Flow diagram for short text feature extraction combining term co-occurrence distance and category information图1 融合词语共现距离和类别信息的短文本特征提取方法流程图
传统的词条加权方法在计算词项共现情况时没有考虑到词项之间的距离,本文提出的利用词项共现距离的方法来计算某个词项的关联权重可以有效地解决这一问题。本阶段用到的符号定义如表1所示。
由公式(1)可计算:
(3)

Table 1 Notation definition表1 符号定义表

(4)
则词项ti在特定短文本ds中的关联权重计算公式如下:
(5)
(6)

(7)
其中,cowr(ti)反映了词项ti在第Cr类短文本集中关联权重的整体情况。
3.2 构造特征词典
如何从短文本中选取最能代表类别特征的词项作为特征词项是构造特征词典的关键。所选的特征词应该满足以下两个条件:一是能够较好地概括短文本的内容信息;二是有较好的局部指示性,即该词项能较好地揭示短文本所在类别的信息。第一个条件采用关联性加权策略即可满足,第二个条件可以采用ECE"值[11]来权衡所选的特征词的局部指示性。
在公式(2)中,词项ti在所有的类别中具有综合的权重值。然而,在大多数情况下,一个能代表A类信息的词项,很有可能对类别B分布的影响不大。因此,应该将该词项在不同类别中的权重值考虑在内。词项ti在类别Cr中的权重值计算公式如下:
(8)
由公式(8)可知,当P(Cr|ti)的值越大,即词项ti和类别Cr相关性越强时,P(Cr|ti)/P(Cr)越大,则词项ti对类别Cr的作用就越大。当词项ti与某一类别强相关,且与其他类别的相关性较弱时,被选中的可能性也就越大。词项ti在除类别Cr外的其它类中的权重值计算公式[12]如下:
(9)
其中,ECE′(ti,Cj)表示词项ti在剩下k-1个类别中的平均权重。
(10)
其中,ECE″(ti,Cr)反映了词项ti在类别Cr中的整体权重值。该值越大,说明词项ti对类别Cr的指示性越强。利用公式(10)对类别Cr中的所有词项计算其ECE″值。在类别Cr中词项ti的最终权重计算公式如下:
Wti=cowr(ti)×ECE″(ti,Cr)×idf(ti)
(11)
(12)
其中,cowr(ti)揭示了对于第Cr类短文本集而言词项ti的重要程度;ECE″(ti,Cr)反映了词项ti对短文本所属类别的指示性;idf(ti)为词项ti的逆向文档频率,表现了词项ti对短文本的区分程度,可以由第Cr类的短文本总数|Dr|除以其中包含词项ti的短文本数,再将得到的商值取对数计算可得。如果包含词项ti的短文本数越少,则idf(ti)的值越大,说明词项ti对类别区分的能力也越强。
对类别Cr中的词项按Wti值进行降序排列,取前K个词项作为特征词项。对短文本集中的每个类别进行相同的处理,并把得到的每一类别的特征词项进行合并构造出新的特征词典。
随着特征词典大小的增长,本文方法的计算时间会呈现出指数的增长趋势。这是由于在词项集中,每计算一个词项与其余词项之间的相关度与共现度需要遍历一次文本库,故在特征词典长度为n时,该算法的时间复杂度为O(n2)。
4 实验与结果分析
4.1 实验数据集及预处理
为了验证本文提出方法的有效性,分别收集中国计算机学会CCF(China Computer Federation)会议推荐列表中的A类会议与B类会议中的15类共750篇文章标题作为英文数据集,中国科学引文数据库CSCD(Chinese Science Citation Database)中的5类共12 534篇文章标题作为中文数据集进行实验。本文采用5折交叉验证的方法,将所有类别中的数据样本随机划分成五个大小相等的子样本,交叉验证过程重复五次。每次一个样本被保留作为测试集的验证数据,其余四个样本作为训练数据。训练集主要用来训练使用本文方法学习所得的模型,测试集主要用来验证本文方法是否能对短文本进行准确分类。
对短文本集进行预处理,包括数据去噪、文本分词、停用词过滤等处理。其中对中文分词的处理采用了jieba中文分词工具。得到新的短文本特征词项集后,将实验中的短文本以向量形式进行表示并采用支持向量机SVM(Support Vector Machine)与k-NN(k-Nearest Neighbor)分类器进行分类。其中,SVM采用Libsvm包,将k-NN中的近邻数设置为61进行比较。
4.2 评价指标
本文涉及的评价指标包括准确率Accuracy和F1-measure[13],其定义如下:
(13)
其中,TP、TN、FP、FN分别为真正(事实上是正样本,被判定为正样本)、真负(事实上是正样本,被判定为负样本)、假正(事实上是负样本,被判定为正样本)、假负(事实上是负样本,被判定为负样本)。P是精确率,R是召回率,其计算公式如下:
(14)
(15)
4.3 实验结果与相关分析
为了验证本文方法的有效性,共设计了三个实验。实验1使用SVM和k-NN分类器来验证使用本文方法获取到的特征词典的大小对短文本分类准确性的影响;实验2将本文方法与其他方法得到的特征词典进行对比;实验3将不同方法得到的特征词典应用到SVM分类器中,验证使用不同策略的特征提取方法对短文本分类的影响。本文将只考虑类别信息不考虑词语之间的共现距离的特征提取方法CISE(combining Category Information for Short text feature Extraction)、考虑共现距离但不考虑类别信息的特征提取方法CDSE(Combining term co-occurrence Distance for Short text feature Extraction)、考虑词语之间的共现情况但不考虑类别信息的特征提取方法TCSE(combining Term co-occurrence Condition for Short text feature Extraction)以及TF*IDF方法与本文方法得到的特征词项集进行比较,验证使用本文方法所构造的特征词典对短文本进行分类的高效性。
选择以上四种特征提取方法作为对比方法是基于以下几点考虑:(1)本文的方法是在传统的特征提取方法基础上通过融合词项之间的共现情况以及短文本的类别信息改进而来的,CDSE方法和CISE方法与本文的方法最为相似;(2)选用CISE方法将短文本的类别信息考虑进来而不考虑词项之间的共现情况可以显示出类别信息对构建特征词典的重要性;(3)TF*IDF方法则是将共现距离与类别信息均忽略的传统特征提取方法。
4.3.1 特征词典大小对短文本分类的影响
为了验证使用本文方法获取到的特征词典的长度对短文本分类造成的影响,分别取特征词项集中的前30、40、50、60、70、80、90、100、110、130、160、180、200、230、250、280和300个特征词项构造特征词典,在SVM和k-NN分类器上进行分类测试。其中,SVM分类器使用了Libsvm-3.2.1版本的插件,通过调整相应参数并最终选用非启发式线性核函数作为训练支持向量机模型的主要函数。在使用k-NN分类器进行模型训练时,通过调整K近邻数发现当特征词典长度一定时,以20为基数,步长为2的速度增长所得到的准确率和F1-measure值在近邻数为61时能较好地反映出所训练模型的高效性。
如图2所示,在SVM和k-NN两种分类器上,使用本文方法得到的特征词典均可以有效地对短文本进行分类且使用SVM分类器的分类效果明显优于k-NN分类器的。
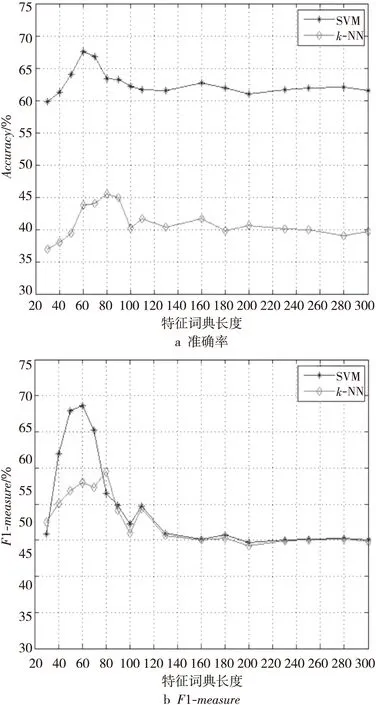
Figure 2 Effect of feature dictionary size on short text classification图2 特征词典大小对短文本分类的影响
在使用SVM训练出的分类模型进行短文本分类时,随着特征词项数目从30增加到300,准确率和F1-measure值均呈现出先增长后下降的波动走势直至趋于稳定,且当Top值在60时达到峰值,分类效果最佳。在使用k-NN训练出的分类模型进行短文本分类时,准确率和F1-measure值呈现出先增长后下降的波动趋势且特征词典长度为80时分类效果最佳。
4.3.2 特征词典比较
为了验证使用本文方法得到的特征词典对短文本分类的高效性,对比了上述5种特征提取方法所得到的特征词典。以处理后的人工智能与模式识别这一类别3 598个词项中的前30个词项为例,如表2所示,使用CDSE方法得到的特征词项与TCSE方法得到的特征词项相比,前者较能表示该类的特征,说明使用词语之间的共现距离来衡量两个词项之间的共现情况更为有效。
显然,与本文方法相比,使用CISE与CDSE方法得到的特征词典均有欠缺,证明了词语之间的共现距离与类别信息这两个因素都不可忽视,而将两个因素均未考虑在内的TF*IDF方法得到的特征词项效果最差。该实验说明了与其它4种方法相比,使用本文方法提取出来的特征词项能更好地表示特征且使用这种方法得到的结果也更为合理。
4.3.3 不同特征提取方法对短文本分类的影响
为了验证使用不同策略的特征提取方法对短文本分类造成的影响,选取不同长度的特征词典在Libsvm中训练分类模型,实验1的结果显示使用SVM分类器在特征词典长度为60时分类准确度最高,效果最好且使用该分类器的波动程度与k-NN分类器比较而言较为稳定。所以,选取SVM分类器并在中英文数据集上进行实验,观察特征词项数目为60时各个方法得到的特征词典对短文本分类准确性的影响,其准确率和F1-measure值如表3所示。
使用本文方法在中英文数据集上进行短文本分类时得到的准确率和F1-measure值均大于其它4种方法,说明本文方法更能有效地对短文本进行分类且本文提出的特征提取方法适用于不同种类的语言。
此外,词语之间的共现情况较类别信息而言对短文本分类造成的影响更大,且使用共现距离来衡量词项之间的共现程度明显优于传统共现情况计算方法。然而,采用传统的特征提取方法对短文本进行分类时,其准确率和F1-measure值最低,分类效果最差。

Table 2 Comparison of different feature dictionaries表2 不同特征词典的比较
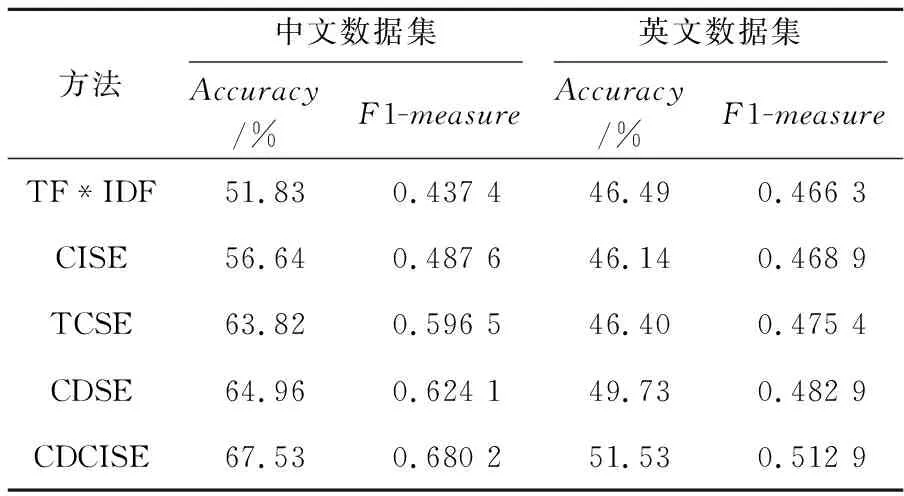
Table 3 Classification performance of the feature extraction methods表3 不同特征提取方法的分类性能
5 结束语
针对传统的词条加权方法没有充分考虑到词语之间的语义信息和类别分布信息,本文提出了一种新的短文本特征提取方法,即融合词语共现距离和类别信息的短文本特征提取方法。该方法利用词语之间的共现距离计算相关度,避免了传统方法无法判断一个特征是否有区分度以及区分度是否足够的缺点,并将词条的类别信息充分考虑在内,使得对文本提取的特征更加合理。在中文、英文数据集上的实验说明,该方法能显著提高短文本特征提取的效果。
猜你喜欢
计算机系统应用(2021年9期)2021-10-11
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
哲学评论(2018年1期)2018-09-14
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
大学教育(2017年5期)2017-05-10
西南交通大学学报(社会科学版)(2015年4期)2016-03-29
中文信息学报(2015年4期)2015-04-21
