
Efficient ROI-based video super resolution in forensic applications
2018-10-08 06:07LIMKengPangLIUYingBIPingLIUYing
西安邮电大学学报 2018年4期
LIM Keng-Pang,LIU Ying,BI Ping,LIU Ying
(1.Siliconvision Pte.Ltd,449 Tagore Industrial Avenue#03-02,Singapore;2.Key Laboratory of Electronic Information Application Technology for Crime Scene Investigation,Ministry of Public Security,Xi’an,710121,China;3.Science and Technology Information Office,Public Security Department of Shaanxi Province,Xi’an 710002,China;4.Center for Image and Information Processing,Xi’an University of Posts and Telecommunications,Xi’an 710121,China)
Abstract:In recent years,there have been significant improvement in both the quality and speed of super resolution imaging using deep learning techniques.The focus of recent research was to recover high resolution details of general images.However,the object of interest is very specific in forensic applications.Therefore,we propose in this paper,a general framework that exploits the domain knowledge of the object of interest.The proposed ROI-based video super resolution framework is not only efficient but also able to reconstruct high quality images.The experimental results show that it is on average 35%faster and 0.44 dB better than the conventional frame-based approach.
Keywords:super fesolution,forensic image,deep learning
Super-resolution imaging is an important tool in forensic applications[1].Improvement in the quality of an image or a video to enable recognition of a digit on a car plate or a facial feature of a person for example,will greatly impact the success of any investigation.
Recently, there have been significant improvements in both the speed and quality of super resolution imaging using deep learning techniques[2-7].The focus of these researches is to recover high quality images which are as representative of the real world scene as possible. However, in forensic applications,the objects of interest are very specific.For example, fingerprints, human faces and car license plates are common objects of interest.We propose an efficient region-of-interest(ROI)based video super resolution framework that can significantly improve the quality of these specific types of images.We choose car license plate as an example but it can be applied to different forensic objects of interest using our proposed framework.
1 Related work
In the classical super resolution sparse coding methods,low resolution images in the transformed domain are viewed as down-sampled version of its higher resolution form[8-9].The high resolution equivalent can be composed by an over-complete dictionary of sub-image atoms. Similarly, the exemplar approach reconstruct higher resolution image from a database of similar sub-images or from patches of sub-images in the picture itself[10].Though these techniques can recover details in the images,it suffers from high computational cost.More recently, Dong et. al.[5]pioneered using deep learning technique on image super resolution with good results.The proposed network architecture is rather straight forward.It consists of three Convolutional Neural Networks(CNNs).Except for the last CNN layer,each CNN is followed by a RELU layer.Following this work, many variations and improvements using deep learning architectures have been proposed[2-4,6-7].More recently,the focus has shifted to speed up the processing using low resolution input image directly.Lai et.al.[4],proposes a progressive super-resolution model that super-resolves a low-resolution images in a coarse-to-fine Laplacian pyramid framework.The feature maps and the low frequencies Laplacian images were processed in two separate pipelines.Initially,the feature maps were computed from the low resolution input using CNN.Both the feature maps and low resolution input are transposed convoluted and up-sampled before adding up to form a higher resolution image.The process is repeated until the desired high resolution image is obtained.This approach is faster since the method starts from a small resolution image while the conventional approach starts from the desired image size which is much slower because it is few times the size of the original low resolution image.Another approach which is highly efficient,is to process the low resolution image in its original size throughout the whole network[2].At the last layer,its feature maps form the sub-pixel location in the original input image.Experimental results show very promising complexity-quality tradeoff improvement compared to the state-of-the-art[2].In[3],this method has been extended to process video leveraging on the spatio-temporal correlation between each INTER frame.
Proposed efficient ROI-based video super-resolution
It is very critical that evidences to be acquired in forensic application be fast and as accurate as possible.Thus,there are two objectives in this work.First,to process the low resolution images in video as efficient as possible.Second,to improve the recovered image quality given some domain knowledge of the object of interest.We extend the efficient method in [2] to process ROI based video super-resolution.
Let IHRbe the original high resolution image frame.ILRis derived by sub-sampling IHR.ISRis the computed super resolution output.Given L layers in a neural network,the network layer outputs are given by[2]:
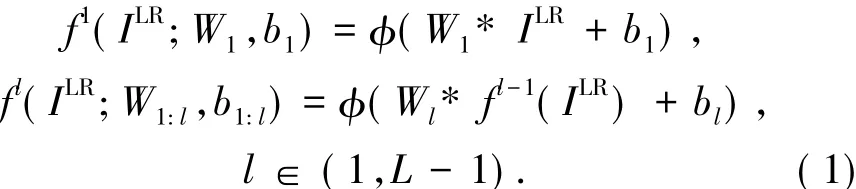
where W1,blare learnable weights and biases respectively. is the activation function and flis the output feature map at lthhidden layer.The high resolution output ISRconsisting of its sub-pixel values in the last layer,it is computed by[2]:

where H,W and C are the height,width and number of color channels in the original low resolution image ILRrespectively.r2is the number of feature maps in the last layer.PS(·)is the operation that rearranges the elements of a H×W×C×r2tensor to rH×rW×C high resolution output.x,y are the output pixel coordinates in the high resolution image space.The training is based on minimizing the following objective function:
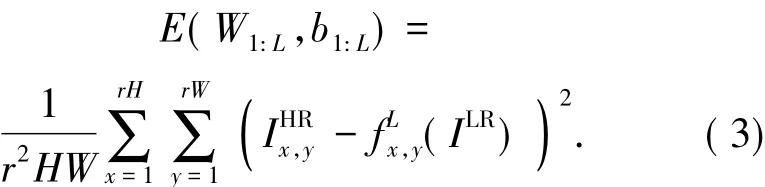
The proposed ROI-based video super resolution framework is described in Fig.1 as follows.
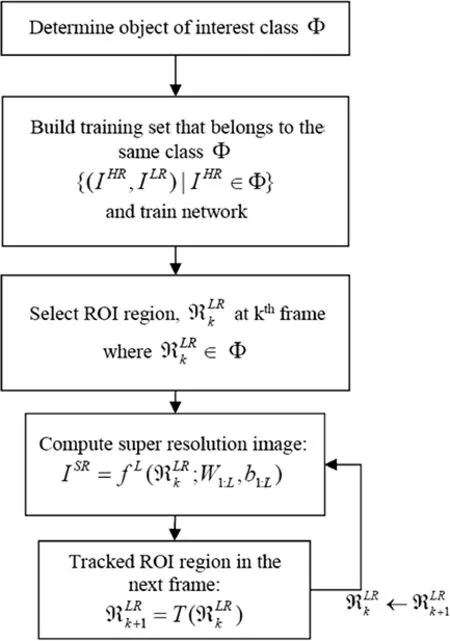
Fig.1 Proposed ROI-based Video Super Resolution Framework
The proposed formal ROI based video framework starts by specifying which class of forensic imageΦ,is to be processed.Training sets are selected based on this class to increase the accuracy of the reconstructed images.Once the network has been trained,the ROI,,in the current frame is selected manually.The ROI is processed in the trained network and the region is tracked(R)in the next frame.The region is processed again and repeated.The proposed framework is not restricted to INTRA frame processing,it can use the neural network proposed in [3]to exploit the inter-frame correlation but at the expense of higher complexity.
The ROI based video processing framework has several advantages.Firstly, it can increase the accuracy of the objects of interest significantly because the training is targeted on the same class of images.Secondly, it can improve the processing speed significantly because only a portion of the whole frame(ROI)is processed.The time saving is contributed mainly from inferencing and motion compensation(when INTER frame correlation is used[3]).
2 Experimental results
In the following experiment,car plate license number is chosen as the object of interest class since it is a very common object of interest in investigations.There are some examples of input training images in Fig.2.

Fig.2 Training images belonging to the same class Φ
Since the car plate regions are relatively flat,affine SIFT[11]is used to track ROI regions.The following shows the ROI selected and the tracked ROI in the next frame highlighted as white box.The green lines show the corresponding key feature points matched between the ROI and the next frame ROI.Note also that affine SIFT performance is robust even it is processed in low resolution images as shown in Fig.3.

Fig.3 Tracked region of interest(Rhighlighted in white box
The recovered image quality of the ROI based approach using the proposed framework is compared against the conventional frame-based approach using equation(2).For the training sets used in the frame-based approach,we follow[4]using BSDS200,General100 and T91 data sets which work very well for general images.A total of 2 216 patches of size 128×128(IHR)are used and down sampled to 32× 32(ILR).For our ROI-based approach,we use the dataset[12]and car plate images from [12].There are total of 2 211 patches of size 128×128(IHR)and similarly down sampled to 32× 32(ILR).1 000 epoches were performed during the training and learning rate is set to 0.000 2.
(1)ROI image quality comparison
64 ROI images were selected from [12] for testing.What in Fig.4 are the PSNR computed from the original high resolution with super-resolved image.
On the average, ROI method is 25.98 dB whereas frame-based method is 25.53 dB,which is 0.45 dB less.
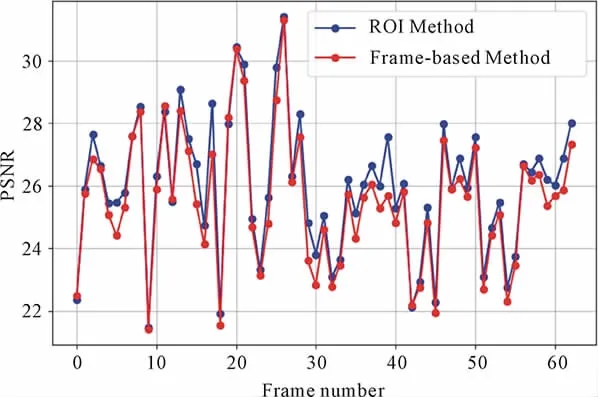
Fig.4 PSNR comparison between ROI-based and Frame-based approach
What in Fig.5 are some results for subjective comparison:

Fig.5 Subjective comparison between the ROI-based(left)and frame-based(right)approach
(2)ROI Video sequence comparison
Four ROI images are tracked in four car test video sequences.There are a total of 10 frames in each video sequence.Note that for fair comparison,the PSNR for the frame-based method is computed at the same ROI region in both methods.
The average PSNR for all test video sequences using the ROI method is 25.31 dB.On the other hand,the average PSNR is 24.87 dB using the frame-based method which is 0.44 dB lesser.It can be seen that ROI based method consistently outperforms the frame-based method in all test video sequences.
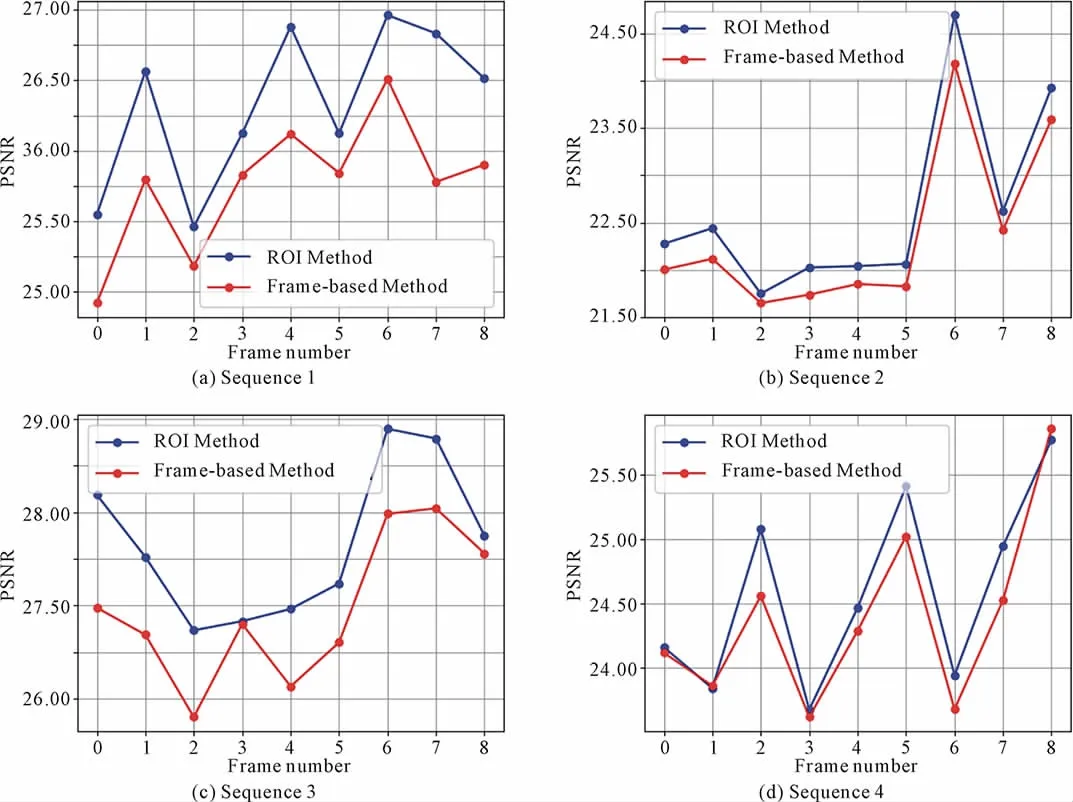
Fig.6 PSNR comparison of four test video sequences
(3)Timing comparison
The platform used is Linux Tensorflow running on Intel i7-6800k 3.4 Ghz CPU.The frame size is 384 by 640 while the ROI size is 128 by 128 pixels.The following are the time taken to process each video sequences for a total of 10 frames:

Tab.1 Timing comparison between ROI-based and frame-based approach
From the experimental results,the ROI-based approach is on average,35% faster than the frame-based approach. Interestingly, the ROI tracking time contributed to the bulk of the processing.
3 Conclusions
We have proposed a formal fast and effective video super resolution framework for forensic applications.This framework enables faster and more accurate super resolution video for targeted objects of interest.Future work will look into exploiting INTER frame correlations to further improve the quality of the high resolution video output.
