
基于子图像方法和稀疏表示的人脸识别算法
2018-10-08 01:41丁园园崔倩倩张翼然
科技视界 2018年22期
丁园园 郑 岩 崔倩倩 张翼然
(1.国家知识产权局专利局专利审查协作河南中心,河南 郑州 450000;2.中国人民解放军 94353部队,河南 商丘 476000)
1 基于子图像方法和稀疏表示的人脸识别算法架构
本文所述的基于子图像方法和稀疏表示的人脸识别算法中测试图像与训练图像匹配的具体过程,以一个人的人脸图像,2×2划分图像的方式,随机采样 1次为例,说明了匹配的整个过程。首先,训练图像和测试图像经过LBP预处理转换为LBP直方图图像。然后,对LBP直方图图像进行子图像划分得到相应的子图像集,再对这些子图像集进行随机采样得到新的特征子集作为基分类器的输入。最后,以并联的方式集成4个SRC分类器,测试图像最终的分类结果由这4个基分类器多数投票决定。当然,上述过程只是一个简单的举例,在实际操作中本文算法对于不同人脸库中的图像有不同的子图像划分的方式,并且对子图像集进行了多次的随机采样,从而构造出更加具有差异性的基分类器。
2 实验
为了验证基于子图像方法和稀疏表示的人脸识别算法的有效性,本文首先在ORL和Yale两个规模较小的人脸数据库上进行了相关实验,并对该算法涉及到的各项参数进行了探究;然后在此基础上与当前的一些人脸识别方法在规模较大的Extended Yale B和CMU PIE人脸数据库上进行了对比实验。
本文仅选取了每个人在5种近似正面姿态下(C05、C07、C09、C27、C29)的 170 张图像(除去 存在损 坏的一些图像)共11554张图像进行实验。本文实验使用的四个人脸数据库图像均来自于Cai处理后的数据(www.cad.zju.edu.cn/home/dengcai/)。
2.1 参数设置
对于ORL人脸库,共包含来自40个人的400张灰度图像,每人10张不同的图像,图像大小为 64×64,经过预处理,得60×60预处理图像。 对于Yale人脸库,共包含165张来自15个人的灰度图像,每人11张不同的图像,图像大小为64×64,经过预处理,得 60×60预处理图像。

图1 不同采样率下的识别效果
Ho在实验中发现,RSM在特征子集的大小为原始特征集的大小的一半,即采样率为0.5时集成性能最高[2]。本文也做了相关实验进行验证,实验中,子图像以6×6的方式进行划分,共分了36块,每块子图像的尺寸为10×10;随机选取每个人的5张图像作为测试图像,其余作为训练图像,采样率分别设为0.17和0.5,重复10次实验取识别率的平均值,在ORL人脸库中的对比结果如图1(a)所示;随机选取每个人的7张图像作为测试图像,其余作为训练图像,采样率分别设为0.14和0.5,重复10次实验取识别率的平均值,在Yale人脸库中的对比结果如图1(b)所示。从图中可以看出,大部分采样次数下,尤其是采样次数较少只有5次、10次的时候,采样率为0.5时的识别结果要优于其他采样率的结果。并且随着采样次数的增加,识别率会有一个最优值,之后会有所下降,并趋于平稳。虽然当采样次数在20次以上时,其他采样率也能有不错的效果,但是采样次数过多会降低系统的性能,尤其是对于图像比较多的人脸库,如Extended Yale B人脸库和CMU PIE人脸库。因此本文算法中的采样率被设定为0.5。
针对子图像块数的设定问题,本文做了如下实验,对于ORL和Yale人脸库,LBP直方图图像的子图像尺寸分别设为 30×30,20×20,12×12,10×10,6×6, 对应的子图像的块数分别为 4,9,25,36,100; 采样次数均为15,采样率均为 0.5;实验中,ORL人脸库中随机选取每个人的5张图像作为测试图像,其余作为训练图像,重复10次实验取识别率的平均值;Yale人脸库中随机选取每个人的7张图像作为测试图像,其余作为训练图像,重复10次实验取识别率的平均值;实验结果如图2所示,不同子图像块数下识别率曲线的总体趋势相同,都是随着子图像块数的增加先上升后下降。这是因为当子图像块数较少时对应的子图像尺寸比较大,随机采样提取的特征容易受到局部变化地影响;而当子图像块数较多时对应的子图像尺寸比较小,多次随机采样提取的特征容易产生冗余。因此本文对不同的人脸库的子图像划分方式有所不同,具体的可见表 2。
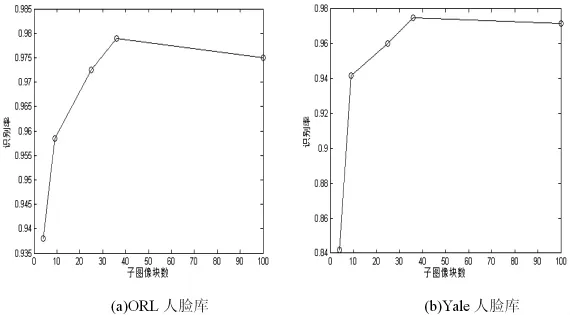
图2 不同子图像块数对应的识别效果
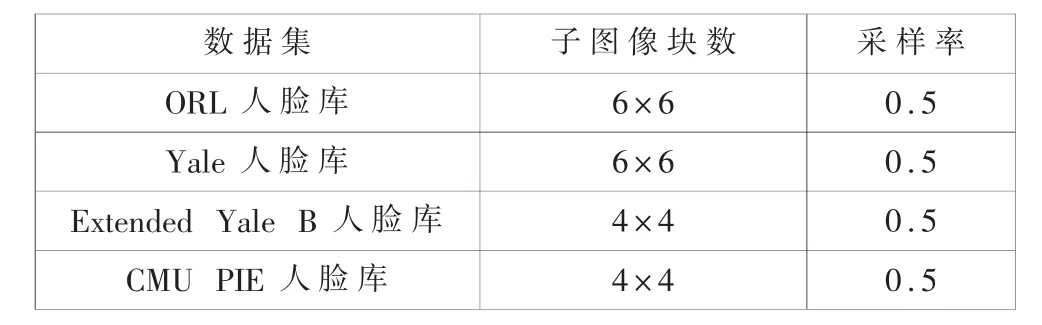
表2 不同数据集的参数设置
2.2 在ORL和Yale数据集上的结果对比
表3给出了在ORL和Yale两个数据集上,POriginal-RS-SRC取得的最好结果,并与文献[3]中的Semi-RS(包括 PSemi-RS和 HSemi-RS),和文献[4]中的RS(Random Subspace)、R-QT(Random Quad-Tree)给 出 的结果进行了对比。表3中展示的结果均为重复10次实验所取得的识别率的平均值。

表3 本文算法与其他方法在ORL和Yale上的识别率对比
从表3中可以看出,本文方法能取得不弱于同类的RS和Semi-RS的效果,针对ORL数据集,本文算法略优于其他算法;针对Yale数据集,本文算法能取得的最好的识别效果。
2.3 在Extended Yale B和CMU PIE数据集上的结果对比
由于Extended Yale B数据集规模较大,因此实验过程中使用的采样次数较小(K=15)。每次实验随机选择一个人的p(p=5,10,20)张图像作为训练,剩余的作为测试,重复进行10次实验,取10次实验的识别率的平均值作为最后的结果。实验结果如表4所示,表中给出了POriginal-RS-SRC取得的最好结果,并与文献[4]中的 RS、R-QT的结果和文献[5]中各种方法的结果进行了对比。
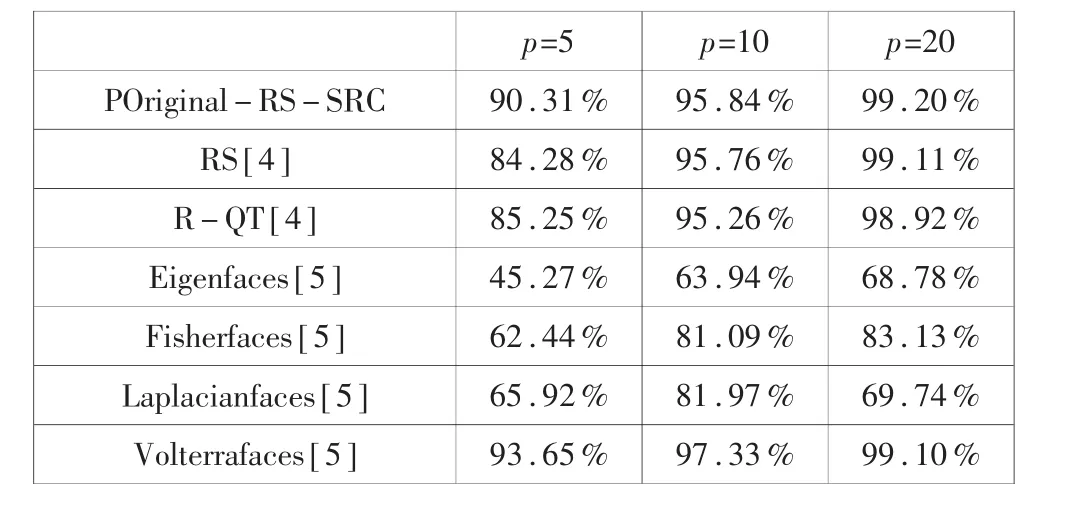
表4 本文算法与其他方法在Extended Yale B上的识别率对比
从表4中可以看出,传统的全局特征方法Eigenfaces、Fisherfaces容易受光照等变化的影响,所以在光照变化较大的Extended Yale B上取得的识别效果比较差;而本文算法在p=5,10时的识别率略低于文献[5]中的Volterrafaces方法,其他情况下都能取得最好的识别效果,说明本文方法对光照变化具有较强的鲁棒性。
CMU PIE数据集中的人脸图像的光照变化幅度要小于Extended Yale B,但同时还存在一定的表情变化。同Extended Yale B数据集一样,针对CMU PIE,采样次数。每次实验随机选择一个人的张图像作为训练,剩余的作为测试,重复进行10次,取10次实验识别率的平均值作为最后的结果。实验结果如表5所示。
从表5中可以看出,由于数据集中的图像受到光照、表情变化的影响,传统的全局特征方法Eigenfaces、Fisherfaces取得的识别效果较差;在p=5时由于训练样本较少,本文算法的识别效果并不好,识别率低于RQT和Volterrafaces方法。但是在训练样本增多p=10时,本文算法可以取得优于其他方法的识别率,这说明本文算法对光照和表情变化都有较好的鲁棒性。

表5 本文算法与其他方法在CUM PIE上的识别率对比
3 小结
LBP算子因为模型简单且能消除光照变化对人脸图像的影响,因此被用作光照预处理。子图像方法一方面缩小了特征提取的范围,降低了图像局部变化带来的影响,另一方面从样本特征角度构建了多分类器系统,再结合RSM,增强了基分类器之间的差异性。在特征采样过程中,使用原始随机采样方法对子图像集进行采样。在最后的分类器系统设计过程中,由于并联组合能充分利用基分类器之间的互补性,同时可以通过并行实现提高系统速度,有利于系统的集成,因此本文中分类器采用并联形式进行组合。
实验中,在 ORL、Yale、Extended Yale B 和 CMU PIE四个标准人脸数据库上对本文设计的算法进行了验证。首先对使用的数据库所包含的数据进行了说明。然后对实验参数的设定进行了探讨,通过实验的方式对采样率的选择和子图像划分方式进行详细的讨论。最后,本文算法与当前的一些人脸识别方法在四个标准人脸数据库上取得的识别率进行了对比,结果表明本文算法不仅能取得较好的识别效果,而且对于光照、表情变化具有一定的鲁棒性。
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
学生天地(2020年31期)2020-06-01
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
动漫星空(2018年9期)2018-10-26
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
计算机工程(2015年8期)2015-07-03
发明与创新(2015年33期)2015-02-27
