
改进的协同过滤算法在资源推荐系统中的应用研究
2018-09-29 19:47刘鑫李世杰廖逸文
科技传播 2018年18期
刘鑫 李世杰 廖逸文
摘 要 文章研究了常用的推荐系统模型及协同过滤推荐算法,综合讨论分析了协同过滤算法应用于资源推荐时存在的问题,提出了一种改进的协同过滤推荐算法,根据输入的用户属性特征等信息,使用相似性计算公式获得相似用户群,建立最佳的邻居集合,解决传统算法中的冷启动问题,同时利用k-means聚类降低用户寻找最近邻所消耗的时间,解决了资源过载而带来的速度瓶颈问题。
关键词 协同过滤算法;资源推荐;k-means聚类
中图分类号 TP3 文献标识码 A 文章编号 1674-6708(2018)219-0155-02
近年来,Internet技术的飞速发展和个性化推荐系统开发技术的不断成熟,学生可以在网络上查阅的资源数量越来越多,范围越来越广泛,对于如此庞大的网络资源,学生想要快速的找到自己真正需要的资源却越发困难。利用个性化推荐算法,可以摆脱网络资源过载问题,高效且精准把所需要的资源推送给学生,然而,针对学生提供的个性化学习资源推荐系统却不常见。大多网络资源个性化推荐系统仅仅是将大量的学习资源按照一定的排序方式简单的罗列在一起,学生用户需要时还需要自己进行关键字检索,效率低且不利于在线学习模式的发展。
文章针对新用户新项目在推荐系统初始时存在冷启动问题,评分数据稀疏也导致了推荐精度下降的现象,提出了利用k-means聚类算法首先根据用户属性对用户分类,再结合协同过滤的个性化推荐思想,设计了改进的协同过滤算法,并应用在我校的学习交流系统中的资源推荐模块中,提高了个性化学习资源推荐的效率和精度。
1 个性化推荐系统及推荐算法
1.1 个性化推荐系统模型
常见的推荐系统由用户、推荐资源信息库和推荐模块构成。其中“资源信息库”模块包含了系统中全部的用户基本信息(如用户年龄、性别、专业、爱好等)、用户对资源的浏览下载等情况的记录信息和对资源进行评分的数据。信息库模块作为推荐模块的基础为其提供输入数据。“个性化推荐模块”根据信息库提供的数据信息,设计适合资源推荐的个性化推荐算法,首先基于信息库提供的数据对用户及资源进行分类,然后在同类用户群生成资源推荐列表,并将其进行排序,取前 N 个信息对象推荐给新用户。
1.2 协同过滤推荐算法
协同过滤推荐算法的主要思想是想要为某一用户推荐学习资源,基于用户喜欢具有相同兴趣的用户喜欢的东西,因此首先找到相似用户群,然后通过用户在系统内的浏览记录或下载记录等获得用户对项目的评分,建立用户和资源评价模型,如果有新用户进入系统,则首先为新用户找到相似用户群,再根据相似群用户的评分排序为新用户推荐前N个学习资源。算法的推荐过程可以划分为3个阶段:用户-学习资源建模、生成最近邻、学习资源推荐。
1)用户—学习资源建模。根据用户对学习资源的评价建立用户-学习资源的评分矩阵如表1所示,行表示用户从User1到用户Usern,共n个用户,列表示资源从Source1到Sourcem 共m个资源,其中 Rui代表第u个用户对第i类学习资源的兴趣度评分。

3)学习資源推荐。根据生成的最近邻居,能够获得邻居用户对学习资源i的评分信息,从而在不知道目标用户对学习资源i评分的前提下,就可以通过最近邻居预测出目标用户对该资源的兴趣程度,按兴趣程度由高到低排序,将排在前面的N项学习资源推荐给目标用户。
1.3 协同过滤推荐算法存在的问题
协同过滤推荐算法当有新用户或新的学习资源出现时,因为没有用户的任何评分数据,导致推荐系统无法获取用户—学习资源评分矩阵,出现冷启动问题。
随着用户访问的网络资源的数量的增加、类型更加多样化、用户与资源的关系更加复杂,使得运用协同过滤算法寻找目标用户的邻居时效率越来越低,因此会严重影响推荐效率,产生速度瓶颈问题。
2 改进的协同过滤算法
对算法存在的冷启动问题,文章设计系统登录用户时,根据注册用户输入的基本属性信息,包括用户的年龄、专业及爱好取向等建立用户基本信息表,使用K-means聚类算法进而形成用户的邻居集合,即使没有用户对资源的评分信息,系统也可以通过计算用户之间相似性,为新用户推荐需要的学习资源。为解决速度瓶颈问题,在计算相似度前,使用K-means聚类算法将用户聚类,再计算目标用户所属类别,进而在查找最近邻居时,只需要和该类别内部的用户进行相似度计算,大大降低了运算量,提高了算法效率。算法的执行过程如下:
1)输入用户属性特征描述,系统收集到的用户的属性信息包括性别、年龄、爱好、学历、专业,并为其设计二进制编码。
2)预处理用户属性特征信息,得到用户兴趣爱好向量。
3)使用K-means聚类算法根据用户提供的初始化信息进行聚类,首先随机选取用户的职业或受教育程度来设计K个聚类质心,计算每个用户与该职业或受教育程度聚类质心的距离,将用户划分到最近的簇内,循环直到所有用户都聚类完成。
4)为新用户归类到所属的簇,将簇内的用户作为目标用户查找邻居的用户群,使用相似度计算公式,找到最近邻。
5)最后根据最近邻生成学习资源推荐的序列,将前N项学习资源推荐给目标用户。
3 改进的协同过滤算法在在线学习交流系统中的应用
采用改进后的协同过滤推荐算法,可以通过对学习者年龄、专业、性别以及兴趣爱好的分析,根据用户特征向量,结合K-means聚类算法生成相似用户群,很容易解决传统算法遇到的冷启动问题。同时,引入K-means聚类算法将查找最近邻的范围缩小到聚类生成的簇中,从而大大的减少了计算最近邻所消耗的时间,提高推荐效率。改进后的算法在在线学习交流系统中执行个性化资源推荐的流程见图1,用户登录在线交流系统界面,在校师生可以根据自己的账号登录系统,首次登录的未注册的师生可以进行系统内资源浏览学习,如果想要其他操作需要完成注册。系统内部自动收集注册师生的基本信息,包括年龄、专业、爱好等,为每个注册的师生建立学习者信息库,使用K-means 算法计算用户间相似性,再通过改进的协同过滤算法预测新用户可能喜好的学习资源集合,并对该集合内部的学习资源按喜好程度排序,将前N个资源作为最终推荐集合推荐给用户。
4 结论
文章在个性化推荐算法的基础上,为了在我校设计开发的在线交流系统实现学习资源的个性化推荐功能,针对协同过滤算法存在的不足,利用K-means聚类算法首先对用户和学习资源进行分类,然后在进行相似性计算,在数据量逐渐增大的形势下,实现资源的个性化推荐。通过验证,推荐效率与推荐质量都有所提升。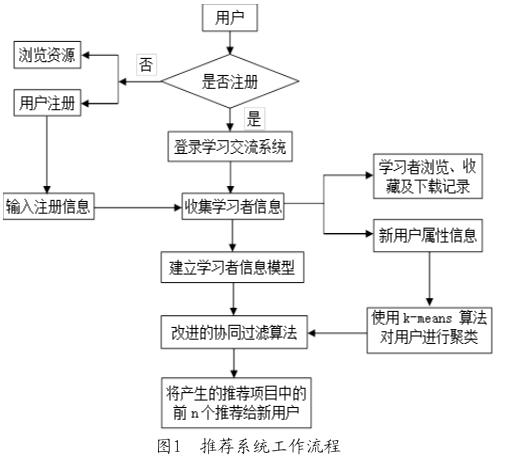
参考文献
[1]冯永,陈显勇.基于评分信息量的协同过滤算法研究[J].计算机工程与应用,2013,49(20):198-201.
[2]韦素云,业宁,等.基于项目聚类的全局最近邻的协同 过滤算法[J].计算机科学,2012,39(12):149-152.
[3]王龙.教育资源推荐服务中若干关键技术的研究[D].长春:吉林大学,2013.
[4]孙歆,王永固,等.基于协同过滤技术的在线学习资源个性化推荐系统研究[J].中国远程教育,2012,32(8):78-82.
[5]赵宁,王学军.推荐系统中协同过滤技术的研究[J].河北省科学院学报,2013,30(2):62-65.
