
P2P网贷平台风险甄别研究
2018-09-21 05:43师应来张冰洁
统计与决策 2018年16期
师应来,张冰洁,姜 昊
(中南财经政法大学 统计与数学学院,武汉 430074)
0 引言
新经济业态下,P2P网络借贷融资模式不再以传统金融机构作为中介,借贷双方直接通过网络平台达成交易,平台以低门槛、高效便捷等优点吸引了大量用户,交易规模和风险也在日益扩大。截至2017年10月底,P2P网贷行业历史累计成交量达到57812.89亿元,与去年同期相比上升幅度达到94.98%。尽管自2016年8月《网络借贷信息中介机构业务活动管理暂行办法》出台以来,网贷行业正常运营平台数量一直处于下降趋势,部分平台主动退出,现有平台开始朝着“小额、普惠”方向转型,P2P网贷平台的风险仍不容小觑。截至2017年10月底,P2P网贷平台累计数量达到5949家(含破产及问题平台),累计破产及问题平台达到3974家。然而,目前国内仍缺乏对P2P平台的有效监管,如何在网贷行业加速洗牌的过程中及时有效地甄别风险显得尤为重要。本文收集整理了我国500家P2P网贷平台基础数据,在变量选取过程中,除传统结构化信息外,还通过网络爬虫、文本挖掘技术得到平台的用户评价情感得分。在模型构建过程中,为克服模型过拟合问题,利用主成分分析提取主要变量,在此基础上构建Logistic、支持向量机、随机森林模型对平台风险进行甄别。研究结果能够有效甄别和预测平台风险,有利于投资者做出理性决策,并为政府监管提供切实有效的参考意见。
1 变量测算
1.1 网贷平台运营风险因素甄别
本文主要研究平台自身运营风险,此类风险主要是由于:平台担保能力有限,不能完全保障出借人账款可以收回;平台盈利能力有限,有倒闭风险,收入可能不能覆盖成本;政府监管不到位,难以提供公平的竞争环境。这类风险可以通过两类变量加以识别:一类是平台公布的、能够直接获得的基本信息,包括平台成交量、平均预期收益率、平均借款期限、注册资本、满标用时、待还余额、资金净流入、运营时间、投资人数、借款人数、借款标数、前十大房贷人待收金额占比、人均投资金额、前十大借款人待还金额占比、人均借款金额;另一类是外部信息,包括各平台用户评论的情感得分及各平台的关注度。
网贷之家网站提供了P2P平台近期的基本信息,包括每个平台各时间段内的基本数据,本文根据网站的公开信息对平台进行标注,低风险平台定义为y=1,高风险平台定义为y=0,在选取的500家网贷平台数据中,共有366家属于低风险平台,134家属于高风险平台。根据影响网贷运营风险因素,并考虑数据的可获得性,本文计算了2017年5月至2017年11月500家平台每个指标的均值,共计15个变量。变量说明见下页表1。
1.2 平台情感得分测算
用户评论是判断用户对平台感受的重要标准之一,可以通过评论中有感情倾向的词语来反映情感得分。本文评论信息来自第三方网贷资讯平台(网贷之家、网贷天眼),通过网络爬虫技术爬取5万余条用户评论,对评论文本采取分词、去除停用词处理并进行情感分析,识别每家P2P网贷平台的用户情感得分。本文使用BosonNLP情感词典作为评论文本的匹配源,其数据来源丰富,主要有微博、新闻、论坛等。对爬取的评论数据进行缺失数据处理,最终从500家网贷平台共获取51077条评论,遍历每一家平台的评论文本,得到用户对该平台的综合评分。部分评分如下页表2所示。

表1 变量说明

表2 P2P网贷平台情感得分
2 模型建立
为利用已有数据对P2P网贷平台风险进行甄别,本文选取Logistic模型、SVM、随机森林模型展开分析。通过对比三个模型预测效果,确定合适的模型对P2P平台进行分类,并根据三个模型的结果,对影响P2P网贷平台风险的因素进行分析。
2.1 Logistic模型
Logistic回归主要用于因变量为二元变量的回归分析,自变量可以分为分类变量,也可以为连续变量。它既可以从多个变量中选出对因变量有影响的自变量,也能估计出模型用于预测。模型的基本形式为:

对其做logit变换,变形后模型形式为:

其中,x1,x2,…,xn为自变量,Y 为因变量,模型的参数估计最常采用MLE法。
2.2 支持向量机模型
支持向量机算法的依据是结构风险最小化,先由训练样本得到初步模型,模型具有较小误差,这个较小的误差在测试集中仍然可以保持。SVM分类模型可分为线性可分和线性不可分两种情况,本文数据属于线性不可分。模型求解的基本过程为:
设样本为n维空间,其k个训练样本输入为 x1,x2,…,xk,对应的所属类别为两类:yi∈{+ 1,-1},i=1,2,…,k ,其中,+1和-1分别表示两类类别标识。假定分类的超平面为:w·x+b=0。为使样本正确分类,超平面应满足约束条件:f(x)=wTx+b,且满足条件 | f(x)|≥1,求解目标要求样本与超平面的最小距离‖w‖尽可能大,由于部分样本不能被超平面正确分类,因此在必要时可以放宽约束,可以通过引入一个松弛变量来实现,此时的约束条件和目标函数分别为:
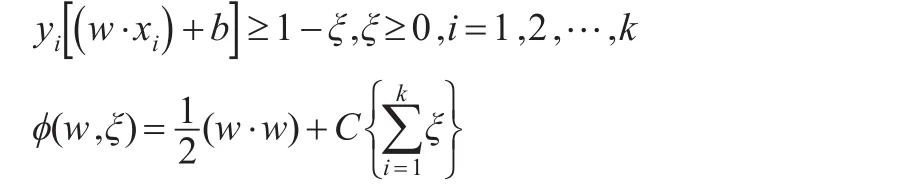
其中,C(C>0)为惩罚系数,用其控制错分样本的惩罚程度;b为分类的阈值,在约束条件下求解目标函数最优值,最终可以得到最优分类函数。
2.3 随机森林模型
随机森林是由Leo Breiman提出的一种分类算法。其运算的原理实质是对决策树算法的一种改进。单棵树分类的能力和精度都常常不能达到要求,但通过多棵决策树(随机产生),让所有树进行分类,选出支持率最高的分类结果,从而能够在分类能力和精度上取得明显的提升。
随机森林算法的实现:首先构建分类树。从训练样本中有放回地抽取样本集,未被抽到的样本则构成袋外数据。再分裂,每棵树上都有富含信息的节点,通过随机抽取和计算信息量并排序的方法选择要分裂的节点。在过程中不对分类树进行剪裁,不剪枝。最后生成随机森林,对于解决分类问题,分类结果由树分类器的投票多少而定。
3 实证分析
3.1 主成分分析
本文初步选取了17个解释变量,解释变量维数较高,且一般信用风险评估本身的复杂性及风险因素之间也往往存在密切的相关性。因此无论采用经典计量方法或者机器学习算法,都存在模型的指标具有高维性和高相关性,并会导致模型参数估计无效、模型过拟合等一系列后果。因此本文在实证分析之前先采用主成分分析法对变量进行预处理,得到9个主成分,再利用得到的主成分作为解释变量进行实证分析。
对所选取的解释变量做KMO&Bartlett球形检验,KMO值为0.683(KMO>0.6),在累计方差贡献率达80%的基础上选取了9个主成分,得到的旋转成分矩阵如表3所示。

表3 主成分旋转成分矩阵
由表3可知,第一主成分在X1、X2和X3上有较大载荷,表明F1与这三个变量具有较强的相关性,基本反映了平台的历史交易信息,定义为历史交易因子;第二主成分在X4、X5和X6上有较大载荷,根据其指标特征,定义为平台现状因子;第三主成分在X7和X8上有较大载荷,且都是反映平台发展,定义为平台发展因子;第四主成分在X9、X10和X11上有较大载荷,与交易人数具有很强相关性,定义为交易人数因子;第五主成分在X12上有较大载荷,定义为平台贷款因子;第六主成分在X13上有较大载荷,定义为客户投资因子;第七主成分在X14和X15上有较大载荷,与客户向平台贷款有较大相关性,定义为平台贷款因子;第八主成分在X16上有较大载荷,定义为情感因子;第九主成分在X17上占有较大载荷,与平台评论数有较大相关性,定义为关注度因子。
3.2 预测结果对比分析
在主成分分析提取的9个因子基础上,本文从网贷之家网络平台选取了500家平台进行风险评估分析,其中低风险平台共有366家,高风险平台有134家,样本比接近2:5,不存在样本失衡问题,模型构建具有可行性。且在使用各个模型进行分析时通过软件选择相同的训练集和测试集(其中训练集与测试集样本量比为7:3),从而保证各模型的分类结果具有可比性。
首先利用SVM模型对平台进行分类,为了使得SVM模型能够根据提供的训练集训练出最佳模型,本文选择多类模型参数、核函数进行训练,训练得到的模型对预测集预测的正确率如表4所示。

表4 SVM模型参数选择 (单位:%)
根据表4得出,在SVM模型中,选择惩罚系数为10和径向基核对预测集预测效果最佳,预测正确率为76.67%,预测效果较好。
其次利用随机森林模型和逻辑回归模型对平台进行分类,同时将这两种模型与SVM模型拟合结果进行对比,对比结果如表5所示。
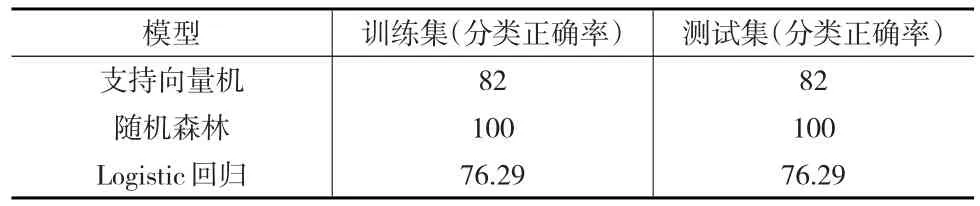
表5 模型预测结果对比 (单位:%)
由表5可知,利用Logistic模型对平台进行分类,发现在测试集上的预测正确率不到80%,低于支持向量机(82%)和随机森林(100%)对训练集的分类正确率。对于测试集,SVM的分类正确率达到76.67%,但随机森林和Logistic回归的分类正确率均未达到75%,对模型的分类效果均不如SVM,结合表4与表5,说明本文选取了相对合适的惩罚系数以及核函数来处理平台风险的分类问题。
从预测结果可以看出,利用高维变量对被解释变量进行分类时的广义线性模型预测效果低于非线性模型SVM,原因在于本文选取的风险评估变量自身往往存在复杂的相关关系,线性模型难以估计,因而对于高维变量且之间存在复杂关系的变量进行分析时,应多考虑利用非线性模型进行估计。而随机森林模型的预测效果优于支持向量机,原因在于随机森林模型不需要预先设定函数形式,不进行交叉验证,因而不易出现过拟合的现象,且可以保证预测精度。
3.3 P2P平台风险识别的整体分析
对于本文选取的模型,虽然SVM和随机森林模型对于平台的分类具有较不错的分析结果,但是缺乏可解释性。因此综合考虑模型对测试集预测的正确率及模型的可解释性,本文以Logistic模型和随机森林模型解释各变量之间存在的联系。
首先对于Logistic模型,本文将PCA得到的9个因子作为解释变量与被解释变量平台风险状况进行拟合,得到的模型参数估计如下页表6所示。
由表6的模型估计结果可以看出,平台风险状况与主成分分析得到的主成分之间的相关关系,其中模型变量的显著性检验表明,平台发展因子、平台贷款因子、情感因子以及关注度因子在5%的显著性水平下显著。原因在于:平台发展因子主要由平台资金净流入和运营时间组成,一个平台现持有的资金是其发展的基础,其对一个平台的持续发展具有极大的影响。而与经营时间短的平台相比,经营时间长的平台在一定程度上处理风险的能力更强。综合该因子主要包含的两个指标及该因子的参数正负性可知,该因子与平台的风险大小负相关;对于平台贷款因子,该因子主要由前十大放贷人待还金额占比和人均借款金额组成。对于某个平台如果发放的贷款越多,在一定程度上可能会收到更多的佣金,但是平台自身持有的资金将会大额减少,平台应对突发事件的能力会随着平台持有资金减少而下降,对一个平台的稳定性将产生很大影响。综合考虑这两项指标及因子的参数正负性可知,该指标越大,该平台风险越大;对于情感因子,该因子主要由情感得分因子组成,显示网民对于平台的情感评价该指标越大表示网民对于该平台的评价越好,即在一定程度上可根据网民正向评论反映该平台风险较小。其次根据该参数的系数为正,综合该指标大小及参数的正负可以得出情感因子越大,则平台的风险较小;对于关注度因子,该因子主要由各平台的评论数组成,因为客户进行投资的主要目的是盈利或至少是保值。因此如果一个平台出现严重问题,则客户一般会在该平台下简要介绍自己遇到的各种问题,为后续投资者提出警示,且实际查看各平台的评论发现网民主要针对平台存在的问题发出评论。因此综合该指标大小及参数正负得出关注度因子越大,该平台风险越大。

表6 Logistic模型参数估计
对于随机森林模型,根据表4可知该模型对训练集的拟合效果很好,而且该模型在进行精确分类的基础上还可以给出各个变量的重要性,得出各变量的重要性结果如表7所示。
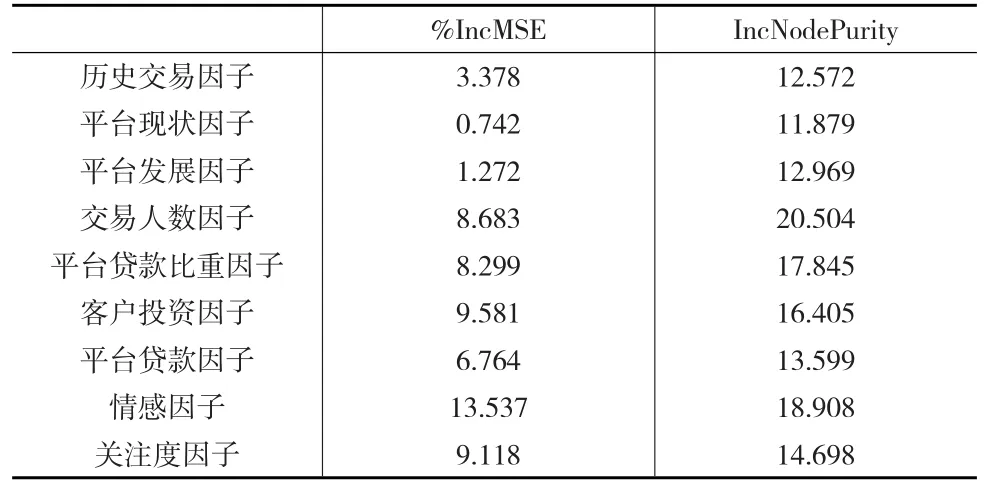
表7 随机森林变量重要性排序
从表7结果可以得出:从误差递减的角度,最重要的四个影响因子排名为情感因子、客户投资因子、关注度因子、平台贷款因子;从精确度递减的角度,最重要的四个因子排名为交易人数因子、情感因子、平台贷款比重因子、客户投资因子。将该结果与Logistic结果对比发现,二者得到的重要因素基本相同。
4 结论与建议
在对网贷平台进行风险甄别的过程中,支持向量机、随机森林非线性模型比广义线性模型预测效果更优。平台发展因子、客户投资因子、平台贷款因子、情感因子和关注度因子对平台的风险甄别具有重要意义。因此,非线性模型更适合构建P2P网贷平台风险甄别体系,想进行投资的用户更应关注平台的发展情况、资金流及投资贷款信息,同时,用户评论和平台的关注度应给予足够重视。基于上述实证分析,本文提出以下建议:
政府应该增加对网贷平台的管理力度。在数据搜集过程中,发现网络贷款作为一种与互联网相结合的新型金融形态,平台披露的信息仍然很有限,相关法律法规还不够完善,这会导致投资者面临的投资风险增大、致使网贷平台竞争环境丧失公平性。政府应尽快完善法律法规,保障P2P网贷的将抗发展环境,促使这种新型金融形态可持续发展。
建议相关部门对P2P平台进行风险监测,实现风险预警。可参考本文的分析结果,根据上述指标建立平台风险指数,促使各平台定期公布,从而使各平台良性发展。同时在大数据时代数据丰富性基础上,选取更多的信息对模型不断训练,使其对平台的风险预测更加准确,进而促使P2P交易市场更加成熟。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
中国外汇(2019年10期)2019-08-27
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
初中生世界·七年级(2017年9期)2017-10-13
商周刊(2017年17期)2017-09-08
商周刊(2017年17期)2017-09-08
少儿科学周刊·儿童版(2017年3期)2017-06-29
中国经济信息(2015年5期)2015-03-23
