
新媒体环境下基于用户画像的智慧图书馆建设*
2018-09-21 08:38常盛
科技与创新 2018年18期
常盛
新媒体环境下基于用户画像的智慧图书馆建设*
常盛
(长春市图书馆,吉林 长春 130021)
分析了当前图书馆数字化服务形势,指明了建立读者标签库的意义,阐述了现代图书馆基于用户画像的构架、关键算法、标签库建立、高维向量相似度计算、实现路径等内容。
用户画像;智慧图书馆;新媒体;智能化水平
面对信息化时代向大数据时代的转型期,传统图书馆基于简单供给方式的粗犷服务方式难以满足公众的阅读需求,由于用户数据缺乏有效分析与训练,形成用户习惯及喜好盲区,个体阅读的差异性成为精准化服务的难点。建设以数字化、网络化、智能化的现代信息技术为基础,以互联、高效、便利为主要特征,将绿色发展和数字惠民作为本质追求的现代化图书馆[1]成为时代的必然要求,民众对图书馆服务的智能化水平要求日益提高。在海量数据中及时、有效地推送用户所需的内容,成为智慧图书馆的基础功能,而了解用户的个性化需求成为首要任务。
1 建立用户画像数据模型
相比于传统行业经验进行的简单用户特点描述,现代化的用户画像建立在数据挖掘的基础之上,通过分析用户社会属性、生活习惯、消费行为等信息抽象出用户偏好的标签[2]。基于OOA(面向对象分析)的思想,用户画像模型的建立过程是建立在数以十万普通读者阅读习惯、行为等属性的抽象过程。以OO(面向对象)为基础的用户画像类具有较好数据结构和实现性,同时,具备继承、多态、封装等属性。
1.1 唯一标识的确立
唯一标识是准确识别用户的基础。随着新媒体技术的发展,在缺乏顶端设计的情况下,各类系统被引入图书馆应用,用户唯一标识使用变得混乱。发展初期的身份证号、读者证号、电子邮箱、电话号码,逐渐转变为微信号、淘宝号、QQ号等第三方登陆标识。混乱的唯一标识虽然让数据记录缺乏唯一性、处理变得复杂,但在信息获取维度上获得了更多的扩展。图书馆可通过以下3种方式实现唯一标识的统一,进而实现用户画像数据库中记录的唯一性和完备性:①激励用户完善信息的方式(成本高,难以大规模开展);②跨平台检索ID强打通(基于平台差异性,难于实现);③提取特征向量通过机器学习模糊拉通(适合大规模数据)。
1.2 用户画像的标签
根据描绘用户特征的信息分类可分为静态数据和动态数据。静态数据是指基本属性、家庭、单位等稳定性较好的信息;动态数据是指浏览行为、查询、下载等变化性较大的信息。人的描述属性是极为复杂的,画像属性也必然伴随着高维度和高复杂性而变化,庞大的属性标签也将提高数据挖掘运算的复杂度,因此,按照目标进行适当的属性设计是一种择优策略。
一般情况下静态信息主要包含人口属性、行业属性、阅读偏好、社交数据等;动态信息一般包括访问行为、兴趣特征、场景、消费特征等。具体如图1所示。
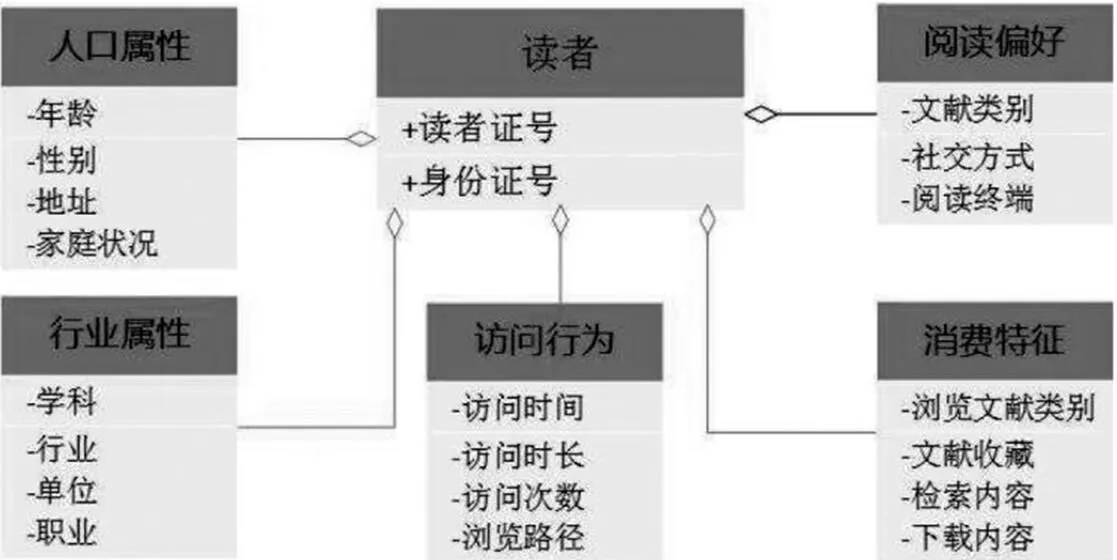
图1 主要信息示意图
1.3 标签权重
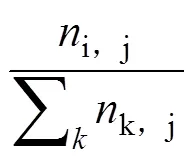
表1 文献分类标签表(单位:次)
分类A分类B分类C分类D 读者A5320 读者B2141 读者C0420
计算可得,读者A标签1的=0.5,=1.22,-=0.61,对应填入文献分类-权重表如表2所示。
表2 文献分类权重表
分类A分类B分类C分类D 读者A0.610.330.220 读者B0310.140.550.39 读者C00.730.360
其次,相对于文献分类之外,读者关于访问行为、访问触点、返回次数等标签对于预测读者获取文献内容具有较大价值,以访问时长为例,读者对于某类文献浏览时间占据其访问时间总长比例越大,说明该读者对该类文献的需求越高,因此建立权重计算方式为:
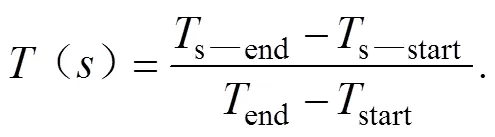
式(1)中:s—end−s—start为某类文献的驻留时间;end−start为访问平台总长。
由于文献的分类多元化,其访问时长的标签也绝非单一数值,而是一个差异化增长的一组数值,随机选取一个读者的访问时长记录制作其标签表如表3所示。
表3 访问时长标签表(单位:s)
分类A分类B分类C分类D分类E 读者A03020080
计算绘制其权重表如表4所示。
表4 访问时长权重表
分类A分类B分类C分类D分类E 读者A00.230.1500.61
2 聚类及群体画像
为提高内容预测的精准性,发掘读者阅读行为的潜在关联和规律,用户画像标签库的建立将是动态的过程,但过于精确的用户画像预测降低了投入产出比。因此,将用户画像标签进行聚类,进而形成群体画像,一方面提升了整体服务效能;另一方面,将具有相似阅读偏好的读者聚集,易于组织专题性阅读推广活动。聚类技术属于无监督学习,实现算法较多划分法、层次法、密度算法等,但在文献分类标签每个读者的阅读偏好呈现为向量形式,即可将读者偏好的聚类转化为向量相似度的检索。
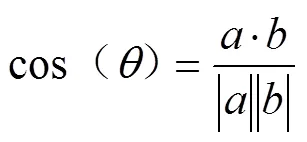

cos()的取值范围为[-1,1],值越大表明夹角越小,相反夹角越大。使用MATLAB:=1-pdist(,'cosine')可以计算其夹角余弦。
但在实际应用中,面对庞大的读者群体,该方法的遍历比较过程时间复杂度极高(^2),无法在实际中大规模应用。高维向量相似度可采用LSH(Location Sensitive Hash)位置敏感哈希函数进行算法实现。原数据样本空间临近的数据点经过映射和变形后,在新的数据空间仍有较大概率相邻。
对于任意,属于,如果从集合到的函数族={1,2,…,n}对距离函数,满足条件[4]:(,)≤,且满足[()=()] ≥1;(,)>+,[()=()]≤2这些条件,则称是敏感位置。原始数值落入不同数值桶,进而完成的读者阅读文献的喜好分类实现聚类。
3 建设路径
用户画像技术的应用是现代图书馆数据挖掘和人工智能技术应用的典型应用,要求图书馆在用户数据采集、存储、使用上要有科学的规划和系统的建设,绝非一朝一夕之功,可以按照快速原型或是迭代式的发展模式,按照一般图书馆的建设方式可以总结成以下形式:接触点数据采集→形成标签层→读者数据特征化→形成用户画像数据库。
[1]王世伟.论智慧图书馆的三大特点[J].中国图书馆学报,2012(06):22-28.
[2]王庆.基于“用户画像“的图书馆资源推荐模式设计与分析[J].现代情报,2018(03):105-109.
[3]宗成庆.统计自然语言处理[M].北京:清华大学出版社,2008.
[4]Piotr Indyk.data-dependent LSH algorithms[EB/OL].http://people.csail.mit.edu/indyk,2015.
中国图书馆学会阅读推广课题(编号:YD2016B39);吉林省图书馆学、情报与文献学科研课题(编号:WK2018C140);长春市文广新局调查研究项目“图书馆推动全民阅读战略的对策与研究”
2095-6835(2018)18-0138-02
G250.7
A
10.15913/j.cnki.kjycx.2018.18.138
〔编辑:张思楠〕
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(神奇星球)(2022年3期)2022-06-06
计算机应用与软件(2021年7期)2021-07-16
非公有制企业党建(2020年10期)2020-10-27
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
海峡姐妹(2018年3期)2018-05-09
瞭望东方周刊(2017年7期)2017-03-01
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
