
基于条件随机场的地质矿产文本分词研究
2018-09-20 05:18陈婧汶陈建国王成彬朱月琴
中国矿业 2018年9期
陈婧汶,陈建国,王成彬,朱月琴
(1.中国地质大学地质过程与矿产资源国家重点实验室,湖北 武汉 430074; 2.中国地质大学(武汉)紧缺矿产资源勘查协同创新中心,湖北 武汉 430074; 3.中国地质大学(武汉)资源学院,湖北 武汉 430074; 4.自然资源部地质信息技术重点实验室,北京 100037; 5.中国地质调查局发展研究中心,北京 100037)
0 引 言
中国的地质工作自民国以来,取得了一系列的成就。与此同时,承载这些成就的地质科技文献、地质报告等地质文本数据量急剧增加。从计算机信息处理角度来讲,地质文本为利用自然语言书写的,具有鲜明的地质特色的非结构化的语义数据[1-2]。如何从海量的非结构化地质文本资料中提出有效的、简洁的、结构化的信息,并基于提取出来的结构化信息进行知识发现是目前地学信息领域极具实用价值和富有挑战性的工作。中文分词是解决信息检索、文本分类、数据挖掘、信息过滤、自动标引提取、自动文摘生成等自然语言处理问题的前提和基础。
根据方法原理的不同,中文分词方法可以分为基于词典匹配的分词方法、基于统计的分词方法和基于理解的分词方法。基于词典匹配的分词方法是针对特定领域分词的主要方法,如Jiang H J等[3]采用一种新型个性化分词词典对网络文本进行分词,但此类方法受限于专业词典,对词典中的未收录的词汇识别率低。而基于统计的分词方法将中文分词问题视为字串序列标注问题,并通过机器学习的方法预测最佳序列从而达到分词的效果,主要的统计模型有隐马尔科夫模型(hidden Markov model,HMM)[4]、最大熵马尔科夫模型(maximum entropy Markov model,MEMM)[5]和条件随机场(conditional random fields,CRFs)模型[6]等,统计分词方法能够自动从训练数据中获得知识,对未登录词具有很好的识别能力。其中,条件随机场模型在归一化时考虑数据的全局分布,消除了隐马尔科夫模型中两个不合理的假设条件,克服了最大熵马尔科夫模型标记偏置(label bias)[7]的问题。条件随机场模型能够引入多种特征,Sun等[8]将词性特征引入条件随机场模型进行分词和标注,Huang等[9]将字符特征和词语特征引入条件随机场模型。同时,条件随机场模型能够通过对引入的特征进行学习生成特征函数集合,从而预测最佳序列标注。基于理解的分词方法利用计算机模拟人类阅读中文时的理解过程以实现词汇的有效识别,从而达到分词的目的。目前,对中文分词的研究大多采用基于词典匹配和基于统计的分词方法。
中文分词方法根据应用的范围,可以分为通用领域和特定知识领域。通用领域分词方法使用灵活,不受专业领域知识的限制;特定知识领域分词是基于专业领域的知识,提高领域知识词汇的分词准确率。在通用领域中文分词中,随着文本领域内容的变化,不可避免的出现大量未登录领域专业词汇,使得分词效果欠佳。而特定领域分词方法专门针对某一领域,对该领域的专业词汇具有较好的分词效果。
在特定领域中文分词方法上,学者们做了大量的工作,均取得了较好的分词效果,如岳金媛等[10]将领域词典与链式条件随机场模型相结合对专利文献进行分词,杨晓军等[11]提出基于改进的正向最大匹配算法的中文分词算法并应用于GIS领域,邱冰等[12]采用基于计算机自动分词的统计方法对古代汉语分词。
由于地质矿产文本中含有大量的专业术语,通用领域方法无法很好识别其未登录词,而其他特定领域中文分词方法移植性较差,不适用于地质矿产文本分词。目前,针对地质领域的中文分词研究不多,张思发等[13]采用“庖丁解牛”中文分词算法实现对地学信息领域文本进行了分词研究,但其算法对未登录词汇识别能力较差。Huang等[14]基于条件随机场构建地学领域分词方法,其训练语料库的标注采用的是人工自定义的方法,其方法虽然对地矿专业术语具有很好的识别能力,但训练语料库对于地矿专业术语的标注、定义在规范程度方面仍需提高。为了提高训练语料标注的规范程度,本文基于条件随机场模型方法,引入地质大辞典和地质矿产术语等标准规范词汇,采用半自动标注的语料处理方法制作地质领域语料库,将地质语料库和通用语料库结合训练条件随机场模型的分词规则,对地质矿产文本进行分词研究。
1 地质矿产文本的特点
地质矿产文本数据主要包括地质矿产报告和地质科技文献,其中,地质矿产报告是用于描述地质矿产调查项目进展和成果的特殊文本,其严格按照中国地质调查局的编写规范进行撰写,主要由现代汉语常用词汇和地质矿产专业术语组成。地质矿产文本数据在用词上具有以下特点。
1.1 编写规范,用词准确
由于地质矿产文本是为报道地质矿产研究成果而撰写的具有科学性的文本,其严格遵循编写规范,描述性语句居多,用词严谨,较少出现歧义词,如“区内含矿地层主要为下三叠统永宁镇组下段和飞仙关组上段”。
1.2 专业的术语应用
除了大量地质矿产专业术语,地质矿产文本应用统计学、计算机等学科研究方法的频率高,存在学科交叉领域词汇,如“层次分析法”“因子分析”“非线性耦合”等。
1.3 中英文混编
在地质矿产文本中,一些专业术语可用英文缩写代替,文本中存在纯英文词汇和中文、英文、数字组合词汇,如“Cu”“EH4”“SE向”等。
1.4 地名
地质矿产文本具有针对性,对某一地区进行调查研究,故文本中包含大量地名,如“沱沱河地区”“个旧”“张家口”等。
1.5 术语嵌套
存在大量专业术语嵌套现象,如“阿尔卑斯”“阿尔卑斯地槽”“粉砂岩”“粉砂岩包裹体”等。
2 基于CRFs模型的地质矿产文本分词方法
2.1 技术路线
根据地质矿产文本的特点,对地质矿产生语料进行预处理,首先将地质词典与生语料进行匹配,将生语料中与词典匹配的词汇进行机械标注,形成粗加工语料,然后对没有进行匹配的汉字进行人工校对与标注,形成完整序列标注的地质矿产熟语料。结合通用领域熟语料对分词规则进行训练,形成地质矿产分词模型。在分词模块中,利用地质矿产分词模型对输入文本进行序列标注,再通过模型解码,从而进行分词。条件随机场模型的训练与测试采用CRF++-0.58工具包[注]CRF++:Yet another crf toolkit,http:∥crfpp.sourceforge.net/.。根据序列标注集和特征模板,CRF++0.58工具包会自动生成一系列特征函数,形成一个分词模型,进而实现对地质矿产文本进行分词(图1)。
2.2 地质矿产文本领域知识构建
本文利用地质词典对地质矿产语料进行处理,从而构建地质矿产文本领域知识。地质词典由地质大辞典和地质矿产术语分类代码表共同组成。地质大辞典是我国建国以来第一部综合性地质辞典,全书共包括四十多个学科的名词、术语一万一千多条。地质矿产术语分类代码表主要是由地质矿产生产、科学研究中的各种地质现象所涉及到的属性和对属性特征进行定性描述用的名词、术语组成,共有地球物理学、岩矿鉴定等三十五个部分约八万个词条。本文采用地质大辞典及地质矿产术语分类代码表中的名词、术语约九万个词汇构建一个适用于地质矿产生语料预处理的地质词典。
地质矿产文本是专业性很强的文本,含有大量专业术语,这些专业术语在现有分词系统中多为未登录词。本文首先利用正向最大匹配(forward maximum matching,FMM)算法[15]对地质矿产生语料进行地质词典匹配,将生语料中与地质词典中相匹配的专业术语进行机械标注并将语料进行分句。对经过粗加工的语料进行人工校对及标注,标注的前提是对字串进行词语切分,切分规范参考北京大学计算语言学研究所公布的《现代汉语语料库加工规范——词语切分与词性标注》。
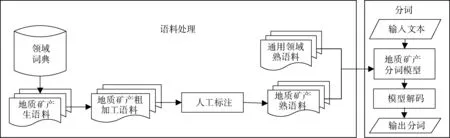
图1 分词方法总体结构图
2.3 条件随机场模型
条件随机场是一种判别式概率图模型[16],用于标注和切分有序数据。
给定一个无向图G=(V,E),其中V是非空的顶点集合,E是V中元素构成的无序二元组的边集合(图2)。
在前提条件为X的情况下,若无向图G=(V,

图2 无向图示例
E)中每个随机变量Yv均服从马尔科夫独立性,即式(1)。
P(Yv|X,Yu,u≠v)=P(Yv|X,Yu,u~v)
(1)
则(X,Y)就构成一个条件随机场,其中u~v表示u和v是无向图中相邻的边。
在进行中文分词时,最常用的是一阶链式结构的条件随机场模型。设字串x={x1,x2,…,xn}为观察序列,字串标注y={y1,y2,…,yn}为有限状态集合。在给定输入序列的情况下,一阶链式结构的条件随机场状态序列的条件概率见式(2)。
(2)
式中:fj(yi-1,yi,x,i)为一个可选的特征函数;λj为每个特征函数的权值;Z(x)为归一化因子,其计算公式为式(3)。
(3)
2.4 序列标注集与特征模板设置
序列标注集是指字串中每个字对应的词位信息的标注。序列标注集的选定与特征模板的设置关系到条件随机场模型的分词效果,特征模板中的每个特征分别对应一组特征函数,根据特征函数可以计算输出最佳标注序列。
序列标注集中字的词位信息设定决定了条件随机场模型最终得到的分词精度。根据实际研究需求,可自由选择不同的序列标注集。地质矿产文本中含三字以上的词汇较多,故本文选择四位词序列标注集{B,M,E,S}作为字标注方法,其中,B代表词语首字,如“成矿预测”中的“成”;M代表词语中字,如“成矿预测”中的“矿”“预”;E代表词语尾字,如“成矿预测”中的“测”;S代表单字词,如“的”“是”(表1)。标注及其对应的定义见表1。如将“基于GIS的证据权重法在成矿预测中的应用”这个句子进行标注,标注结果见表2,即分词结果为“基于/GIS/的/证据权重法/在/成矿预测/中/的/应用”。
特征模板的设置是进行词位标注时最重要的一个环节。条件随机场模型不仅可以学习字本身的特征,还可以学习字的上下文特征。将上下文约束与序列标注集结合,即可设置特征模板。
特征模板有一元特征模板和二元特征模板两类,根据地质矿产文本的特点,选用基于字的一元特征模板[17]作为特征描述模板,其原理为给出一个模板“U00:%x[-3,0]”,假设当前位置为“地”字,其左数第三个位置x为“矿”字,则生成一个特征函数集合(func1…funcL×N)(图3)。

表1 四位词序列标注集的定义

表2 上文句子标注后数据

图3 特征函数集合
其中,模型生成的特征函数的个数为L×N,L表示输出的类别的种类个数,N表示根据给定的一元特征模板扩展后的输入x的种类个数。通过特征模板的设置,将字面信息作为特征,可以对比不同上下文窗口以及字共现情况下的分词结果。一元特征模板的基本定义为式(4)~(6)。
Cn(n=-3,-2,-1,0,1,2,3)
(4)
CnCn+1(n=-3,-2,-1,0,1,2)
(5)
Cn-1CnCn+1(n=-2,-1,0,1,2)
(6)
式中:C为一个字;n为当前字的相对位置。
3 试验结果及可靠性分析
3.1 试验方案
为了验证采用双语料库构建条件随机场分词模型对地质矿产文本分词的性能,笔者采用北京大学计算语言学研究所提供的《人民日报》标注语料和地质矿产熟语料作为试验语料。在中国知网上检索、下载地质矿产类文献,随机选取其中50篇地质矿产文献,经处理后形成地质矿产熟语料,包含汉字284 572频次。抽取30%的地质矿产熟语料作为测试语料集,70%作为训练语料集的一部分,训练语料集的另一部分为《人民日报》标注语料。
采用三种加入不同语料的条件随机场分词模型对测试语料进行对比分析:①CRF-pku:利用北京大学的语料库构建条件随机场模型对测试语料进行分词;②CRF-geo:采用地质矿产训练语料构建基于条件随机场的分词模型对测试语料进行分词;③CRF-geo+pku:结合地质矿产训练语料与北京大学语料库,构建基于条件随机场的地质矿产分词模型对测试语料进行分词。通过准确率(Precision)、召回率(Recall)和综合指标F值(F-Measure)等指标对以上三种分词模型得到的分词结果进行评测,各指标的计算公式为式(7)~(9)。
(7)

(8)
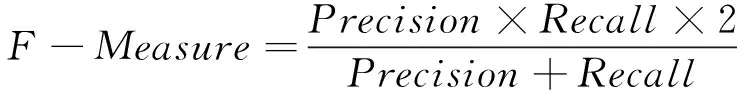
(9)
3.2 试验结果
采用字信息作为特征,比较上下文窗口为±1~3个字,以及二字、三字共现情况下的分词结果。从表3可以看出,增加二字、三字共现特征比单字上下文关系特征的分词效果有一定程度的提升。在窗口为[-2,2]、三字共现的情况下,三个分词模型的精度均达到最高,分别为83.74%、、93.42%、93.73%(表3)。
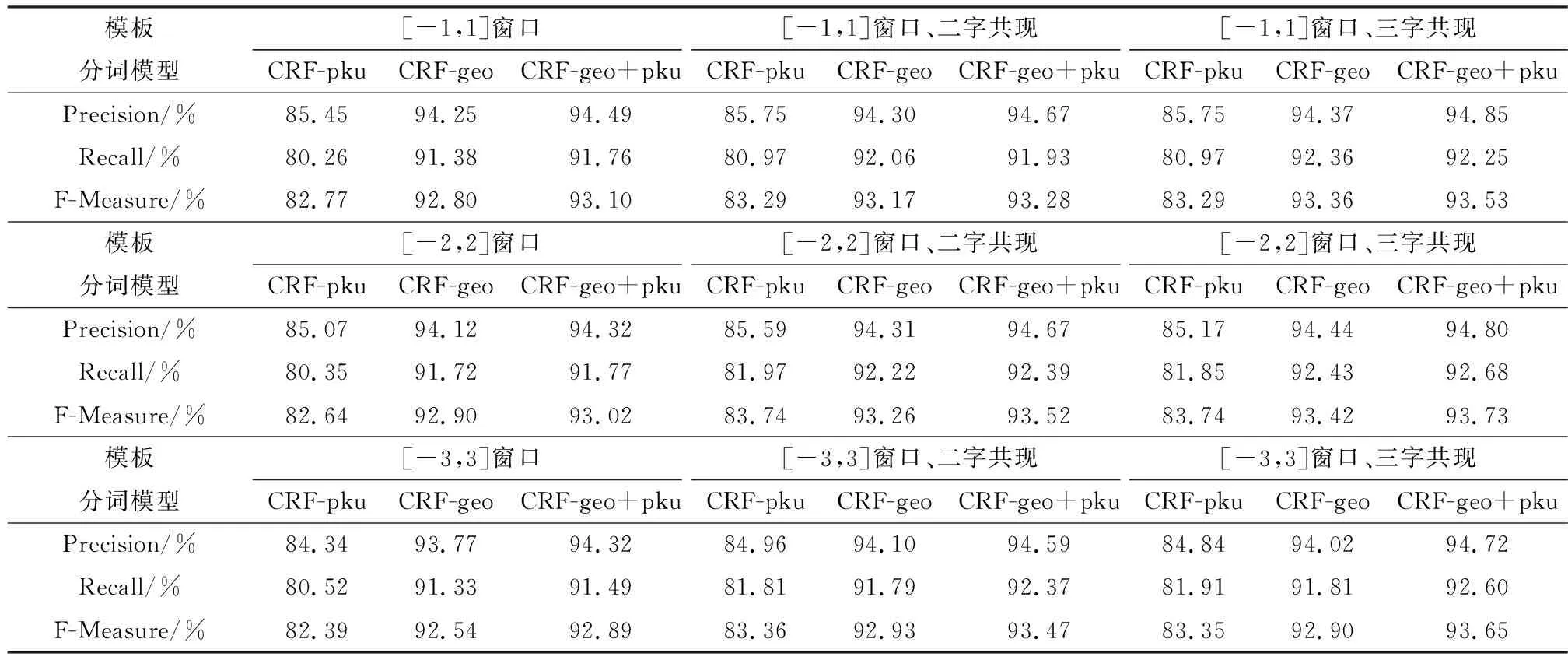
表3 基于字面特征的分词评测结果
为了探究分词效果差异产生的原因,选取分词效果最好的“[-2,2]窗口、三字共现”模板对不同分词模型进行深入分析。
从图4中可以看出,CRF-geo和CRF-geo+pku这两种分词模型取得的分词效果明显优于CRF-pku分词模型。其中,CRF-geo+pku分词模型的分词效果最好,F值至少比CRF-pku提高了9.99个百分点。CRF-geo+pku分词模型与其他两种分词模型相比,准确率、召回率和F值都有不同程度的提高(表4)。
试验结果表明,CRF-geo+pku分词模型较其他分词模型更加准确,该分词模型既能很好的识别地质矿产专业术语,又能对地质矿产文本中的常用词汇准确分词。CRF-geo分词模型准确率略低于CRF-geo+pku分词模型,原因是CRF-geo对地质矿产文本中的常用词汇分词不够准确。在地质矿产语料基础上加入通用领域语料进行训练的CRF-geo+pku分词模型弥补了CRF-geo对常用词汇分词准确率较低的不足。以地质矿产语料训练的CRF-geo+pku和CRF-geo分词模型比仅采用通用领域语料进行训练的CRF-pku分词模型在准确率、召回率和F值上都有大幅提升,因为CRF-geo+pku和CRF-geo在分词时考虑了地质矿产专业术语的特征,对地质矿产专业术语识别率高,如CRF-pku将“燕山早期”切分为“燕山”和“早期”两个部分,而CRF-geo+pku和CRF-geo则正确的将“燕山早期”识别为一个词。

图4 开放测试下各分词模型的分词结果
表4 各分词模型的分词结果对比
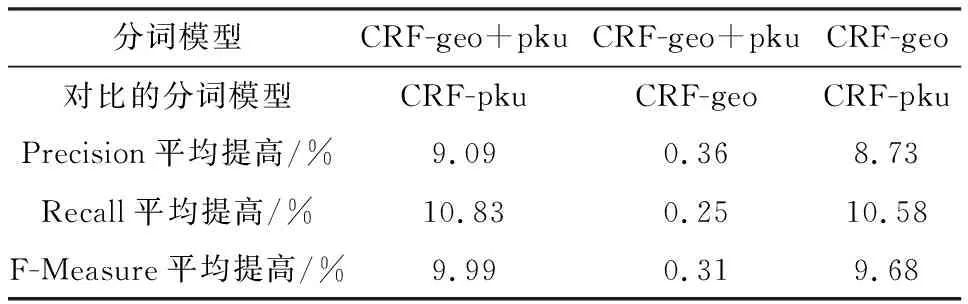
分词模型CRF-geo+pkuCRF-geo+pkuCRF-geo对比的分词模型CRF-pkuCRF-geoCRF-pkuPrecision平均提高/%9.090.368.73Recall平均提高/%10.830.2510.58F-Measure平均提高/%9.990.319.68
由此可见,影响分词效果的主要原因是能否正确识别地质矿产术语,次要原因是对地质矿产文本中的常用词汇的识别。本次试验中采用的CRF-geo+pku分词模型可以有效的识别地质矿产术语和现代汉语常用词汇,准确的对地质矿产文本进行中文分词。
3.3 新词发现
条件随机场模型具有新词发现的功能,能较好的识别未登录词。试验过程中发现三种分词模型可以在不同程度上识别一些未登录地质矿产专业术语。CRF-pku分词模型能够识别部分的未登录地质矿产专业术语,如“印支期”,但CRF-pku具有通用领域分词方法对地质矿产专业术语识别率低的缺点,如CRF-pku把“车房沟”切分为“车”“房”“沟”三个部分,由于通用领域语料及通用领域词典中不包含地质矿产专业术语“车房沟”及类似的词语,故CRF-pku无法学习其规则。地质矿产文本中包含大量的地名及地名嵌套词汇,如“车房沟”“银洞子矿床”,对此CRF-pku均无法较好的识别。同时,对于“金属硫化物”“泥化蚀变”“重力梯度带”等由多个词组成的地质矿产专业术语,分词效果也很差。CRF-geo与CRF-geo+pku分词模型对未登录地质矿产专业术语的识别效果较佳,基本可以正确识别。可见,加入地质矿产语料有助于识别未登录地质矿产专业术语。
4 讨论与结论
从上文试验的结果来看,结合通用领域语料与地质矿产语料构建基于条件随机场的中文分词模型对地质矿产文本进行分词能够显著提高分词性能,它不仅解决了通用领域分词方法对地质矿产专业术语识别率低的问题,而且对常用词汇同样具有很高的识别能力。
本文构建的基于双语料库的条件随机场分词模型具有发现未登录地质矿产新词的能力,如地层“额木尔河组”。除此之外,此方法还能对易产生歧义的句子进行准确切分,例如测试语料中有一句话为“岩体的中心为橄榄岩相”,CRF-pku的切分结果为“岩体/的/中心/为/橄榄/岩/相”,本文提出的方法的切分结果为“岩体/的/中心/为/橄榄岩相”。
本文基于条件随机场模型,选取适当的特征模板和序列标注集,结合地质词典特征,对地质矿产文本进行了中文分词研究,取得了较好的分词效果,对地质矿产文本的自然语言处理工作有着重要的意义。在语料预处理步骤中将地质词典与生语料进行匹配进行机械分词,避免了部分人工标注的误差,提高了标注效率,为以后建立大规模语料库提供了一个可行方案。研究使用多种分词模型进行对比,得出采用通用领域语料与地质矿产语料共同训练分词模型可以较好识别地质矿产专业术语和常用词汇的结论。
本文提出的地质矿产文本分词方法比通用领域分词方法对地质矿产专业术语的识别率有明显提高,但分词准确率还可以进一步提高。条件随机场模型分词效果受训练语料规模的影响,训练语料规模越大,分词效果越好。采用的地质矿产语料规模较小,分词准确率还有提高的空间。在以后的工作中,我们会重点建设一个规模化的地质矿产语料库。
猜你喜欢
通信技术(2021年12期)2022-01-25
现代电子技术(2021年14期)2021-07-16
校园英语·月末(2021年13期)2021-03-15
健康人生(2019年4期)2019-10-25
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
现代商贸工业(2016年22期)2016-12-27
外语教学理论与实践(2014年2期)2014-06-21
中文信息学报(2012年2期)2012-06-29
