
不确定条件下配送回收中心选址配送问题研究
2018-09-18 02:12王小宇马艳芳
计算机工程与应用 2018年18期
康 凯,王小宇,马艳芳
河北工业大学 经济管理学院,天津 300401
1 引言
资源紧缺和环境恶化已威胁到人类的生存和发展,我国做出了“发展循环经济、建设节约型社会”的重大战略决策,再制造不仅节约资源还有助于保护环境,受到政府的重视和社会各界的关注,闭环供应链将正向物流与逆向物流相结合,解决产品回收再制造的问题。在闭环供应链的管理中,选址配送是闭环供应链网络设计与运营的重要问题。
不确定闭环供应链问题引起了学者的广泛关注,在闭环供应链网络中存在很多不确定因素,逆向物流中的不确定因素要多于正向物流。现阶段对闭环供应链中不确定因素的考虑集中在正向物流中的需求不确定及逆向物流中的回收数量不确定。Keyvanshokooh等[1]用模糊随机表示需求和回收量不确定,建立混合整数线性规划(MILP)模型解决闭环供应链网络设计问题。Khatami等[2]运用基于场景的随机MILP模型研究了市场需求和产品回收数量不确定的多阶段多产品闭环供应链网络设计问题,并运用Benders和Cholesky’s分解求解。范小三等[3]探究了需求和回收随机条件下分散决策与集中决策中产品定价策略,在产品回收波动性增大时,第三方物流可以提高回收价格转嫁风险。仍有部分学者关注到回收产品质量的不确定,但关于回收质量的不确定多采用对回收产品分类的方法。高阳等[4]将废旧产品分为可维修、可拆解、可分解三类,研究了回收渠道选择问题,得出制造商的风险偏好对回收渠道选择有重要影响的结论。刘枚莲等[5]通过设定回收产品质量类别,研究了回收质量不确定的逆向供应链定价问题。本文采用回收产品可再利用率表示回收产品质量的不确定,更具有现实意义。
由于环境污染严重,社会的关注及政府的政策法规要求,企业开始关注运营过程中的环境问题。注重环保要求并采取措施改善,有助于提高企业的社会形象。同时有很多文献在闭环供应链优化中考虑减少碳排放和成本优化双重目标。高举红等[6]研究了市场不确定有碳补贴政策的闭环供应链网络优化设计问题。戴卓等[7]人以碳排放与成本最低建立多目标优化模型解决需求不确定闭环供应链网络优化设计问题。Garg等[8]提出了交互多目标优化算法解决闭环供应链网络设计中的环境问题,确定了最优设施间流量以及最优运输车辆数量。Talaei等[9]以碳排放和供应链总成本最低为目标,运用ε-约束法解决可变成本和需求率不确定条件下多产品闭环供应链中的选址配送问题。Jindal[10]运用模糊随机理论处理不确定变量,考虑经济和环境因素建立了多目标闭环供应链网络设计模型。
闭环供应链选址与配送问题是NP难问题。模糊随机环境下闭环供应链中配送回收中心选址配送问题更为复杂。粒子群算法由于实现较为简单,自适应能力强的特点已成为一种重要的智能算法并广泛应用于各个学科及领域。粒子群算法在解决NP难问题中有明显优势,改进粒子群算法在解决供应链管理问题应用更加广泛。Ai和Kachitvichyanukul[11]提出的全局-局部-邻域粒子群算法,Xu等[12]提出的双层模糊随机仿真全局-局部-邻域粒子群算法,为本文模型求解提供了方法基础。本文提出基于优先级的全局-局部-邻域粒子群算法设计求解方案并求解。
2 问题描述和模型建立
2.1 问题描述
本文以含制造商、零售商、一个废弃处理中心和多个配送回收中心构成的闭环供应链为研究对象,如图1所示。产品在工厂完成生产,运往配送回收中心进行调度配送,零售商在接收新产品的同时把回收的废旧产品交给运输车辆运回配送回收中心,在配送回收中心检测、分类,可再利用的运回工厂进行再制造,不可再利用的运往废弃处理中心按国家环保要求进行废弃处理。配送回收中心选址的目标是考虑现有约束情况下,确定配送回收中心的数量和位置,为后期网络运营奠定良好的基础,节约成本。

图1 闭环供应链网络结构示意图
制造商采用按订单生产模式生产。由于顾客可能会将产品丢弃或作为他用,废旧产品回收率考虑为模糊随机变量;在运输以及搬运过程中可能会导致回收产品受损甚至破碎,或者已回收产品中存在有损产品不可再修复,产品可再利用率考虑为模糊随机变量。运输成本和运输碳排放与运输距离以及运输产品数量有关。本文提出如下假设:(1)只考虑单一产品单一阶段[13],从制造商开始的正向物流作为起点,再到产品回到制造商进行再制造结束;(2)配送回收中心的备选点已知,工厂、零售商和废弃处理中心的位置已知;(3)配送回收中心和制造再制造工厂有能力上限[14],考虑有能力上限的设施规划更加符合实际情况;(4)回收产品再制造的成本低于购买新的原材料进行再生产的成本[15];从经济利益的角度出发使得企业愿意采取回收行动,推动闭环供应链的建立与运营;(5)企业采取需求拉动的生产模式,零售商需求根据订单已知[16];(6)交通运输导致的碳排放量在全球碳排放中占有重要比例,是供应链减排中最为关键的环节,故仅考虑运输过程中的碳排放量,且与运输距离以及运输量有关[17]。
2.2 符号说明
Ω:配送回收中心备选点集,Ω={1,2,…,I};
Ψ :工厂地点集,Ψ={1,2,…,J};
Φ:零售商集合,Φ={1,2,…,K};
Y:废弃处理中心集合,Y={1,2,…,N};
i:配送回收中心备选点,i∈Ω={1,2,…,I};
j:已知工厂位置,j∈Ψ={1,2,…,J};
k:已知零售商位置,k∈Φ={1,2,…,K};
n:已知废气处理中心位置,n∈Y={1,2,…,N};
U:配送回收中心数量上限;
Dk:零售商需求;
αi:配送回收中心i的处理能力上限;
γj:工厂 j的生产能力;
Pji:从工厂 j运往配送回收中心i的产品数量;
Qik:从配送回收中心i运往零售商k的产品数量;
C0:碳排放目标系数;
βij:配送回收中心i到工厂 j之间的单位产品碳排放量;
βik:配送回收中心i到零售商k之间的单位产品碳排放量;
βin:配送回收中心i到废弃处理中心n之间的单位产品碳排放量;
xi:为0-1变量,备选点i被选中建立配送回收中心为1,否则为0;
yik:为0-1变量,零售商k由配送回收中心i服务为1,否则为0。
2.3 模型构建
2.3.1 目标函数
本文以建设配送回收中心的经济成本和产品配送回收运输过程碳排放最低为目标建立如下模型。
经济目标:

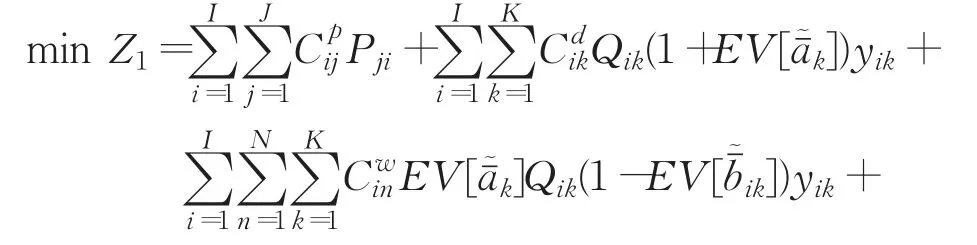


碳排放目标:

2.3.2 约束条件
约束条件主要包括流量均衡约束,配送回收中心数量约束,处理能力上限约束。
(1)由工厂运往配送回收中心的新产品与由零售商处回收的废旧产品之和不超过配送回收中心的处理能力上限。

(2)新产品的需求量和废旧产品的可再利用量不超过工厂的生产能力上限。

(3)产品回收总量不超过产品生产总量。

(4)零售商k的需求被满足。

(5)可再利用产品数量不多于回收产品数量。

(6)配送回收中心的数量不少于1个。

(7)配送回收中心的数量不超过设定的上限。

(8)每个零售商都有且只有一个配送回收中心向其提供服务。

(9)xi是0-1变量,备选点i被选中建立配送回收中心为1,否则为0。

(10)yik是0-1变量,零售商k由配送回收中心i服务为1,否则为0。

模型中所涉及的配送回收中心经济成本最小和碳排放最小,由于其属于不同范畴,量纲不同,故进行加权平均求解[20]。本文采用改进加权平均求解法,给碳排放目标赋予系数C0,将其理解为碳排放产生的经济成本,构成目标函数min F=Z1+C0Z2,将多目标规划转化为单目标规划问题。
3 算法改进方案
粒子群算法是对鸟群觅食行为模拟仿真的智能算法,由Kennedy和Eberhart[21]在1995年首次提出。粒子群算法经常被用来解决NP-难问题。近些年的研究发现标准粒子群算法存在一定缺陷。在标准粒子群算法当中,每个粒子在每次迭代过程中都要进行两个方面的学习,个体最优以及全局最优,并通过学习到的数据调整自己即将飞行的方向和速度。但是一个种群中的粒子易向全局最优粒子附近聚集,导致该种群频繁陷入局部最优解且不再更新。为了处理这种过早收敛于局部最优解的缺陷,Ai和Kachitvichyanukul[11]提出了全局-局部-邻域粒子群算法,有效地解决了这一问题。本文在此基础上,提出基于优先级的全局-局部-邻域粒子群算法来解决多目标配送回收中心的选址配送问题。
3.1 粒子群算法中的符号
基于优先级的全局局部邻域粒子群算法中的符号如下所示:
τ:迭代代数,τ=1,2,…,T ;
d:维度,d=1,2,…,D;
l:粒子,l=1,2,…,L;
ωτ:第τ代粒子的惯性权重;
vld(τ):第l个粒子在第τ代在d维度上的速度分量;
cp:个体加速度;
cl:局部加速度;
cg:全局加速度;
cn:邻域加速度;
Pmax:粒子的最大位置分量;
Pmin:粒子的最小位置分量;
Vl:粒子的速度向量;
Pl:粒子的位置向量;
Gbest(τ):第τ代粒子群的历史最优位置向量;
r1,r2,r3,r4:[0,1]上的相互独立的随机数;
Fitness(Pl):第l个粒子所在位置对应的适应值函数值。
3.2 初始化及适应值计算
根据Gen和Altiparmak[22]提出的优先级编码解码方法进行编码设计。分两阶段设置优先级,第一阶段是配送回收中心与零售商共同设置优先级,优先级为粒子,对应配送回收中心和零售商,优先级最高的配送回收中心选择距离最近的零售商进行配送(优先级最高的零售商选择距离最近的配送回收中心服务),具体过程如下:
步骤1随机生成I+K个数字表示对应零售商与配送回收中心备选点。
步骤2判断最高优先级对应的是配送回收中心备选点或零售商的位置。
步骤3选择距离最近得零售商(或备选点)进行配送,如果是配送回收中心选择距离最近的零售商进行配送后,仍有剩余则选择下一个距离近的进行配送,直到不够配送新的零售商;完成配送后零售商需求为0,对应位置的距离变为无穷大。
步骤4重复前两步,直到所有零售商的需求被满足。
第二阶段过程与第一阶段相同,优先级设定是选中的备选点和工厂。
3.3 约束处理
根据公式计算适应值之后,对于非可行解引入惩罚因子,使其适应度值表现较可行解相差很多,这样可以减少在后续优化过程中非可行解的出现概率[23]。针对本文中的问题,针对流量均衡约束以及处理能力约束采用拒绝法将其取值限制在给定数值范围内[24],针对配送回收中心数量约束设立惩罚因子μ,当选择的配送回收中心备选点多余上限值时,则在适应值计算结果上加一个极大值作为惩罚因子,将非可行解淘汰。如果配送回收中心数量满足要求,则适应值计算函数为:

若配送回收中心数量不满足约束条件,则适应值计算函数为:

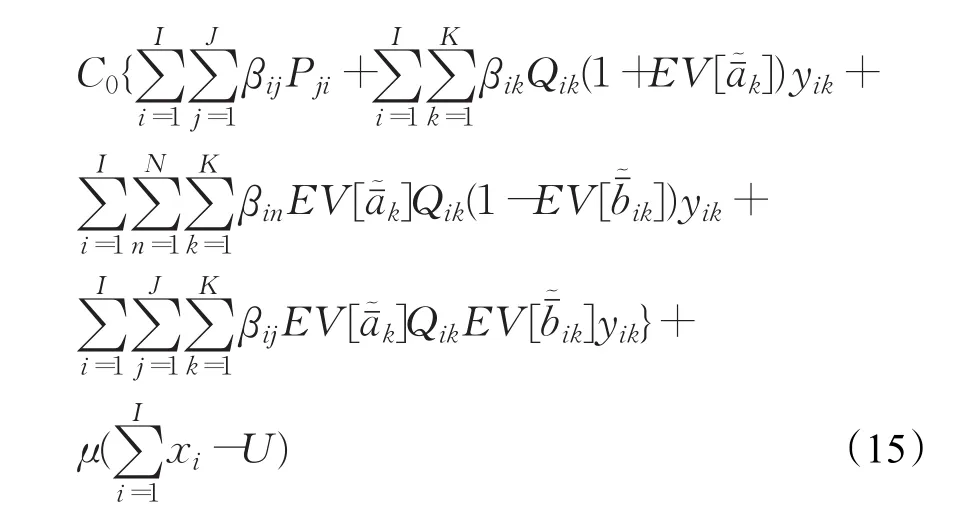
3.4 更新公式
根据Ai和Kachitvichyanukul[11]提出的全局局部邻域粒子群算法中的符号,惯性权重和粒子速度以及位置根据以下公式进行更新。
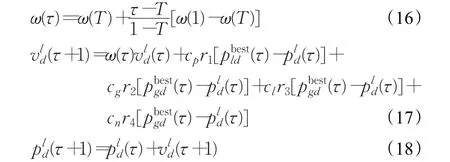
3.5 算法流程
本文中,上述全局-局部-邻域粒子群算法被用于解决设施选址及配送问题。由于不确定性的存在和问题的独特性,提出基于优先级的全局-局部-邻域粒子群算法来解决本文模型。如图2所示。

图2 算法流程图
步骤1初始化粒子(即优先级)。
步骤2约束检查,是否满足约束要求,满足则进入步骤3,不满足,返回步骤1。
步骤3计算目标函数值。
步骤4根据更新公式更新粒子速度及位置。
计算每个粒子的适应值,并记录个人最优位置,并在所有最优位置中选择最好的最为全局最优位置;更新粒子的个体最优位置,种群最优位置,局部最优位置,生成邻域最优位置,更新每个粒子的速度与位置,检查粒子是否超出边界。
步骤5检查是否满足终止条件,若满足,则进入下一步,若不满足返回步骤4。
步骤6根据得出的优先级解码得出选中的备选点。
4 案例分析
4.1 数据收集
本文以D制造商的某种产品为例,根据T地区的相关情况构建一个闭环供应链网络。顾客将结束使用的产品送回零售商,然后在配送回收中心检测、分类、简单修护,可进行再制造的送往制造商,不可再利用的送往配送回收中心进行废弃处理。本闭环供应链网络中有3个制造再制造工厂,6个备选点作为建设配送回收中心的可选项,为10个零售商服务,一个废弃处理中心负责处理废弃物。根据《2006年IPCC国家温室气体清单指南》提供的方法,二氧化碳排放量的计算公式为:单位化石燃料二氧化碳的估算值=低位发热量×碳排放因子×碳氧化率×碳转换系数,建议开征碳税成本为每吨20元[25-26],故本文碳排放目标函数系数C0取值为20。配送回收中心备选点的相关信息如表1所示;各零售商的坐标及需求见表2;工厂和废弃处理中心的坐标以及能力上限如表3所示。本文中产品回收率及可再利用率为模糊随机变量,两个变量用三角模糊数表示,如表4、5所示。

表1 配送回收中心备选点相关参数

表2 零售商相关参数

表3 工厂及废弃处理中心相关参数
4.2 算法参数实验
对模型进行求解前,首先要设置算法参数值。对算法运行效果的验证,探索不同的种群大小及迭代次数对计算结果和运行时间的影响。在不同的种群大小和迭代次数组合下,分别运行10次基于优先级的全局-局部-邻域粒子群算法。表6给出了不同种群大小和迭代次数组合下算法的最优解、最差解、标准差和平均计算时间。从表6中可以看出,种群大小为10时,在给出的迭代次数范围内,虽然计算时间短,但是结果较差且不稳定。由表可知,种群大小一定,迭代次数从100增加到300,计算时间变长,但结果不一定更优。在粒子数为20,迭代次数为200代时取得最优值。当粒子数增加到30时,随着迭代次数的增加,计算时间增加,但计算结果及标准差无明显规律,且没有更优于20个粒子,200代的运行结果。通过对比,发现当迭代次数一定时,粒子数增加,计算时间增加,但是计算结果不一定更优。

表4 回收率
4.3 结果分析
基于上述数据,通过MATLAB编程,基于优先级的全局-局部-邻域粒子群算法有效求解了模型。对于算法中的参数设置如下:粒子种群大小:N=20,最大迭代次数:T=200,惯性权重:ω(1)=1,ω(T)=0.1,加速常数cp=cg=cl=cn=2。将程序运行10次后,获得最优目标函数值,即最低成本为2 975.71万元,为与之对应的计算结果是选择备选点2,4,5建设配送回收中心。由D2负责配送回收R1,R2,R5;D4负责配送回收R3,R4,R6;D5负责配送回收R7,R8,R9,R10。如图3所示。
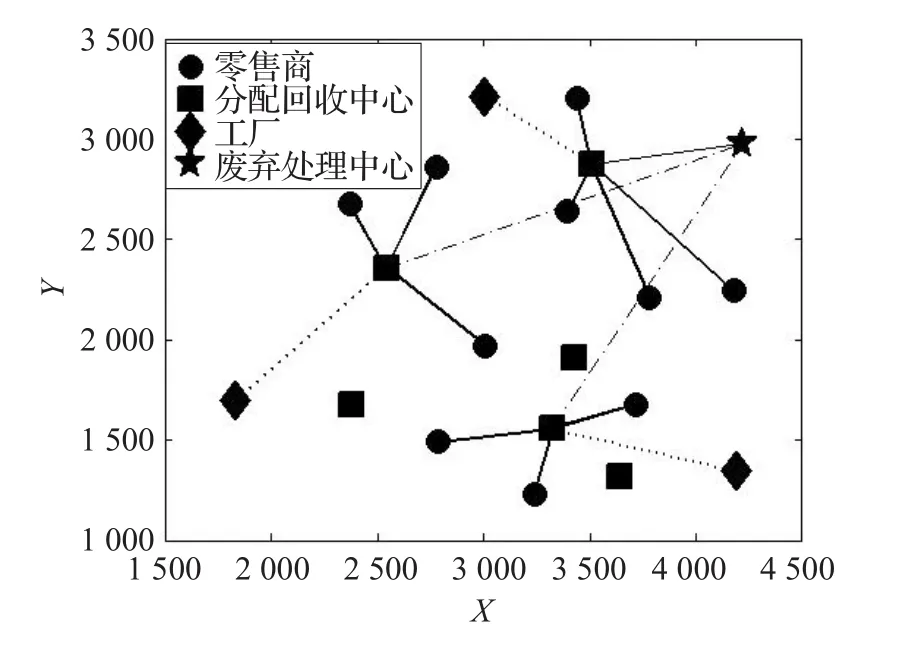
图3 最优选址配送结果
4.4 算法对比
为验证算法的有效性和实用性,对基于优先级的全局-局部-邻域粒子群算法,遗传算法,蚁群算法以及免疫优化算法之间进行对比。同样使用MATLAB对算法进行编译,每种算法在粒子数为20,迭代次数为200的条件下运行10次。在全局-局部-邻域粒子群算法中,惯性权重ω(1)=1,ω(T)=0.1,加速度cp=cg=cl=cn=2;在遗传算法中交叉概率为1,变异概率为0.1;在蚁群算法中信息素重要程度因子为1,启发函数重要程度因子为5,信息素挥发因子为0.1,常系数1;在免疫优化算法中交叉概率为1,变异概率为0.1。
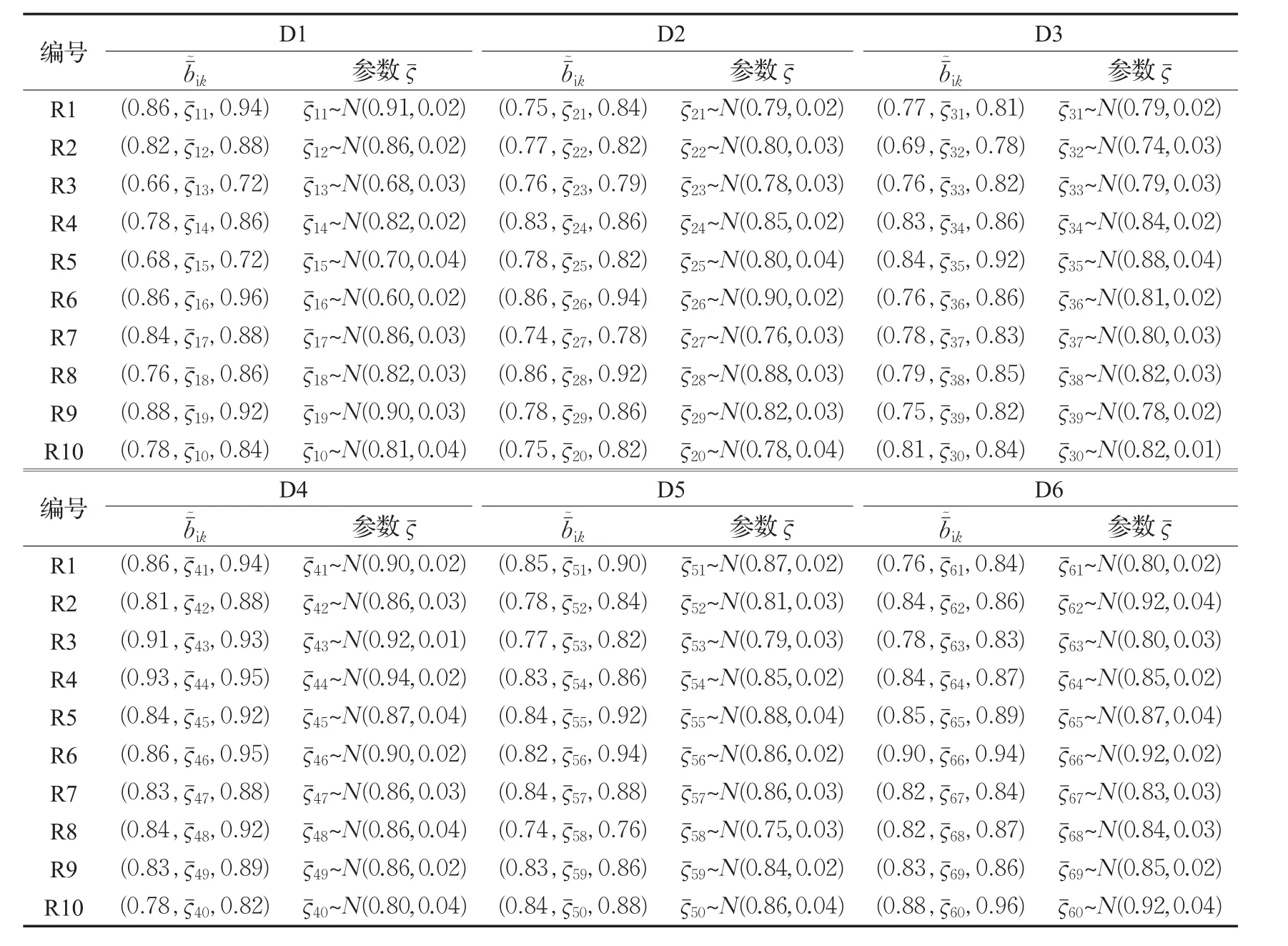
表5 零售商到配送回收中心的产品可再利用率

表6 计算结果
由图4可知,四种算法都有同样的移动趋势,随着迭代次数的增加,算法结果越来越好。四种算法在迭代初期结果都比较差,可能是探索空间超出可行域并造成了对函数适应值的惩罚。随着程序继续运行和迭代次数的增加,函数适应值减小,在迭代结束时,算法结果趋于稳定且变得更好。
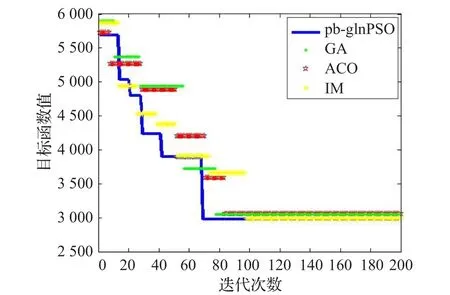
图4 算法对比图
基于优先级的全局-局部-邻域粒子群算法优于遗传算法、蚁群算法以及免疫优化算法。基于优先级的全局-局部-邻域粒子群算法相较其他算法结果更优收敛更快。基于优先级的全局-局部-邻域粒子群算法和全局-局部-邻域粒子群算法在70代左右开始收敛,遗传算法与蚁群算法在80代左右开始收敛,免疫算法则在100代后趋于稳定。将四种算法的计算结果放在表7中通过对比发现,基于优先级的全局-局部-邻域粒子群算法相较于其他算法的优越性。

表7 算法对比结果
5 结论
本文以成本最低和碳排放最小为目标,考虑能力约束,流量约束以及顾客需求约束,运用模糊随机理论,构建了闭环供应链配送回收中心选址配送模型;提出了基于优先级的全局-局部-邻域粒子群算法,并通过案例验证了算法的先进性以及模型的有效性。本文提出的结合分配中心和回收中心功能的配送回收中心,不仅可以降低企业建设成本还可降低运输车辆空载运输成本,同时降低运输碳排放。同时考虑产品回收率及可再利用率的模糊随机性,建立的以成本最低和碳排放最小为目标的闭环供应链选址配送模型,为模糊随机环境条件下考虑碳排放的闭环供应链选址配送决策提供理论依据与方法。多阶段、多产品考虑零售商需求不确定性的闭环供应链选址配送是进一步研究的方向。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
农业工程学报(2022年7期)2022-07-09
数学物理学报(2022年2期)2022-04-26
中国交通信息化(2020年4期)2021-01-14
吉林大学学报(理学版)(2020年3期)2020-05-29
金桥(2018年4期)2018-09-26
自动化学报(2018年7期)2018-08-20
黑龙江电力(2017年1期)2017-05-17
周口师范学院学报(2016年5期)2016-10-17
浙江理工大学学报(自然科学版)(2015年4期)2015-03-01
