
基于转移学习改进低开销指纹的室内定位算法研究
2018-09-11 01:39常雪琴
重庆科技学院学报(自然科学版) 2018年3期
常 雪 琴
(亳州学院电子与信息工程系,安徽 亳州 236800)
随着感知、通信和计算技术的迅速发展,智能家居、智慧医院、智慧商场等众多定位服务和智能应用已经出现在日常生活中,影响着人们的生活方式。室内定位就是这些应用的关键推动力之一,并受到学术界和工业界的广泛关注[1]。
室内定位问题的解决方法主要有2种方案,即基于距离的方案和基于指纹的方案[2]。与基于距离的技术相比,基于指纹的定位由2个部分组成,即离线训练和在线定位。在离线训练中,系统在每个预先部署的参考点(即RP)收集无线信号,并从Wi-Fi接入点(AP)中提取具有一定信号强度指标(RSSIs)的指纹用来构建指纹数据库。在在线定位中,基于本地在线点(即OP)实时采集的RSSIs和指纹数据库可以采用KNN[3]等算法估计目标位置。 尽管基于指纹的室内定位系统有很多优点,但在离线训练阶段可能会使现场测量开销过大[4],从而阻碍其在实际应用中的进一步推广和大规模的应用。
随着计算技术的进步和定位服务的普及,许多专家学者的研究热点集中在室内定位系统的开发上。 Wang等人提出了一种基于曲线拟合(CF)和位置搜索的室内定位方案[5],采用了一系列线性无关的主要函数构建了一个通用的RSSIs距离模型,针对不同的应用提出了2种位置搜索算法。Banerjee等人提出本地化系统的概念,并称之为虚拟罗盘,它通过检测附近用户的相对坐标来构建网络拓扑[6]。基于指纹的技术是室内定位最流行的方法之一。最近,一些研究人员已经将转移学习用于提高室内定位的主要性能指标。Pan等人提出通过二次约束和二次规划(QCQP)转移本地领域的知识,用来改善算法在室内环境中的定位性能[7]。
本次研究提出了一种基于转移学习框架的室内定位算法,并利用实验数据进行测试,从而实现将从源域转移的知识通过转移学习来重塑目标域的逻辑分布,从而降低目标域的站点测量开销,但不会降低定位的准确性。
1 系统原型
基于指纹的室内定位算法由离线训练和在线定位2部分组成。首先,在离线训练中,根据室内空间的物理特征(如规模、部署等)和具体的应用需求,预先部署了多个AP和RP;将移动设备放置在已知坐标的每个RP处,使得周围的AP可以从移动设备接收RSSIs;然后,每个AP通过有线网络将其收集的信息发送到服务器;最后,服务器再根据每个RP收集的信号特征构建并维护一个指纹数据库。
在线定位中,每个AP将其实时捕获的RSSIs从移动设备发送到本地服务器。基于构建的指纹数据库和实时采集的RSSIs,服务器根据一定的定位算法计算移动设备的估计位置。
W个AP与N个已知坐标的RP通过有线网络与本地服务器连接在同一个部署环境中。在离线训练中,移动设备在每个RP上放置一段时间(即保证Wi-Fi开启)。在此期间,周围的AP将捕获其探测请求帧,并获取包括具有时间戳的RSSIs的信号信息。 另外,每个AP将自己的ID(即AP_ID)以及相应RP的ID(即RP_ID)标记到每个记录中,并将其发送到由MySQL实现的样本数据库。在此基础上,基于Node.js环境实现聚合器,其操作步骤为:首先,基于RP_ID(例如i)和AP_ID(例如j)的组合主键,选择具有不同时间戳的一组RSSIs;其次,给定一段时间,计算RSSIs值的平均值,用Rij表示;最后,将RP的坐标插入其相应的ID记录中。基于聚合器处理,指纹数据库中的第i个记录由〈Ri1,Ri2,…,RiW,xi,yi〉表示,其中i是RP的ID(1≤i≤N),W是AP的数量。
在在线定位中,移动设备的实时RSSIs测量将被AP捕获并发送到服务器。信号预处理采用过滤器,根据MAC地址过滤选择目标设备进行定位。
2 算法基本原理
转移学习是通过相关知识转移,来提高新任务领域的学习性能。假设离线训练与在线测试数据必须在同一个特征空间,而且具有相同的分布,则基于指纹的室内定位算法在实际应用场景中可以获得大量的训练数据,但是随着系统规模的不断扩大,新的环境获取的数据相对较少。为了在现场调查中不增加额外费用就能提高新环境下系统的性能,适当设计一些知识转移。基于以上背景,本次研究提出了基于传输学习(TL)的基本框架,以减轻离线培训开销,提高基于指纹的室内定位系统的可扩展性。
基于指纹定位的室内定位的聚类算法,在线测试点与离线参考点之间的逻辑距离是通过某些物理特征(如RSSIs)来衡量的。因此,这种聚类算法的性能在很大程度上依赖于测量点之间的逻辑距离。而基于TL框架的目的是通过从相关源域转移的知识来重塑目标域中的点与点之间距离的逻辑分布。在定位系统中,可以重新定位在目标域中的在线点的逻辑分布,使得这些在线点与参考点之间的逻辑距离处于相同的群集。
为了能够在不同的环境中进行传递学习,以变换矩阵的形式定义知识,可以将原始数据分布重构为与所需一致的知识定位结果。
特别地,给定一个OP,opi=(Ri1,…,RiW)T和一个RP,rpj=(Rj1,…,RjW)T,其中W是AP的数量,计算opi之间的Mahalanobis距离(dM)和rpj公式如下:
dM(opi,rpj)=opi-rpj
(1)
式中:T表示转置操作;M是协方差矩阵。如果可以从源域学到适当的M,那么在目标域中属于同一区域的OP和RP之间的逻辑距离将被缩短,而不同区域的逻辑距离将被放大。因此,通过设计知识转移策略,利用马氏距离可以获得更好的聚类效果。此外,由于M是正半定的,所以通过奇异值分解,将M分解为LLT,式(1)转化为:
(2)
从式(2)可知,RP与OP之间的距离由矩阵M缩放。当目标域中没有足够的RP时,可能导致不正确聚类结果出现。然而,如果可以从源域获得合适的M,那么属于同一个簇的数据点则更接近重新定位目标域中数据点的逻辑分布。因此,利用学习矩阵M重新获得的数据分布,给出所需的定位结果。
基于TL的定位框架关键点主要有2个:度量学习和度量转移。
(1) 度量学习。为了从具有丰富标签数据的源域获得学习矩阵M,本次研究根据希尔伯特 - 施密特独立性准则,最大化所有数据点(即RP)的数据分布R之间的相关性来制定学习问题,即:
(3)

(4)
其中,第1个约束为强制学习矩阵M,为正定式,第2个约束调节正定矩阵M的容量p和B,p和B为预定义的常量参数。为了解决式(4)中的学习问题,令A=RHYHRT,显然,A是一个对称矩阵。A可以通过本征分解为Vdiag(δ)VT,其中V包含A的正交特征向量的列,δ是向量相应的特征值。根据命题,式(4)中M的封闭解为:
(5)
其中,A+=Vdiag(δ+)VT,δ+是一个带有条目的向量,等于max(0,δ[i])。对于p=1,最优解M可以表示为:
M=BA1
(6)

(2) 度量转移。假设q个不同矩阵Ms={M1,M2,…,Mq},其中,所选择的Mt被定义为q个矩阵的线性组合。
∀i=1,2,…,q}
(7)
这样,选择最合适的Mt的任务被转换成系数向量μ∈Q,μ=[μi,…,μq]的学习。基于HSIC和最大均值差异标准,本次研究制定了度量选择问题:
(8)
其中,知识度量Mi∈Ms,Yt是表示RP与OP关系的核矩阵。具体而言,如果opi和rpj位于同一个块中,Yt(i,j)= 1。否则,Yt(i,j)= -1。Si=-(c1*MMDi+c2Difi)。Si是源域Rs和目标域Rt之间的相似性度量,代表2个域之间块号的不同值(例如Rs与Rt),MMDi表示最大平均差异,其通过测量每个域平均最大差异来给出2个域的定位数据的差异,计算公式如下:
(9)
式中,Φ(·)表示将原始输入映射到高维空间。为了简化计算采用线性映射,因此Φ(x)=x。考虑这些约束条件,可得到以下公式:


(10)

最后在在线定位阶段,被识别的Mt根据式(1)用来调节RPs和OPs之间的距离,提高定位性能。
3 性能评估
将基于TL的框架嵌入到基于指纹的室内定位系统中,并在实际测试中给出综合性能评价。选择5个不同尺寸和配置的实验室,根据不同的评估目的将这些环境以不同的方式(例如源和目标域的划分、房间部署、离线数据分发、干扰插值等)进行设置。此外,为了定量评价系统性能,还考虑了精度比和现场测量开销2个指标。(1) 精度比。在在线定位阶段,假设m点设置为本地化(如一次将移动设备设为一个点),系统输出n个正确的位置,则精度比由n/m计算得出。(2) 现场测量开销。在目标空间中给定p个RP,假设在每个RP中收集RSSIs测量值的时间为kmin。为简单起见,考虑一个常数时间在每个RP和设置设备移动,用ε表示,然后,现场调查开销通过p*(k+ε)计算得到。
3.1 有效性验证
在有效性验证实验中,选择房间1~4个,通过检查不同的源和目标域组合来验证基于TL的框架的有效性。共设计了2套实验,分别将房间2和房间4作为目标域。相应地,将房间1,3,4和房间1,2,3分别设置为源域。对于基于TL的框架,式(5)中的参数p分别被配置为3和1 000,设c1=0.8、c2=0.2用于计算式(8)中的Si。另外,实现了2种经典的基于距离的聚类算法(即KNN和WKNN)。相应地,根据是否采用基于TL的框架将每个算法分为2个版本。即在实验中不是比较不同的算法,而是通过比较每个算法的2个版本(即有TL和没有TL)关于减轻站点调查开销来验证基于TL的框架的有效性。
不同精度要求下的现场测量开销见图1。图1中,X轴表示实现的定位精度即精准率,而Y轴表示达到相应精度的最小离线开销即现场测量开销。由图1可知,随着精度要求的提高,KNN的2个版本都需要较高的现场测量开销,因为需要更多的RP来实现更高的准确性。 尽管如此,通过本次实验观察到,与同等精度要求的对应版本相比,基于TL的版本的KNN可以显著减少现场调查开销。

图1 不同精度要求下的现场测量开销
在扩展性实验中,选择一个较大的新实验室评估基于TL框架的可扩展性。图2显示了2种KNN版本在不同精度要求下的现场测量开销。 如前所述,即使学习的矩阵来源于规模小得多的源域,如果可以学习并转移到新的更大规模的环境中,那么它们仍然是有用的。
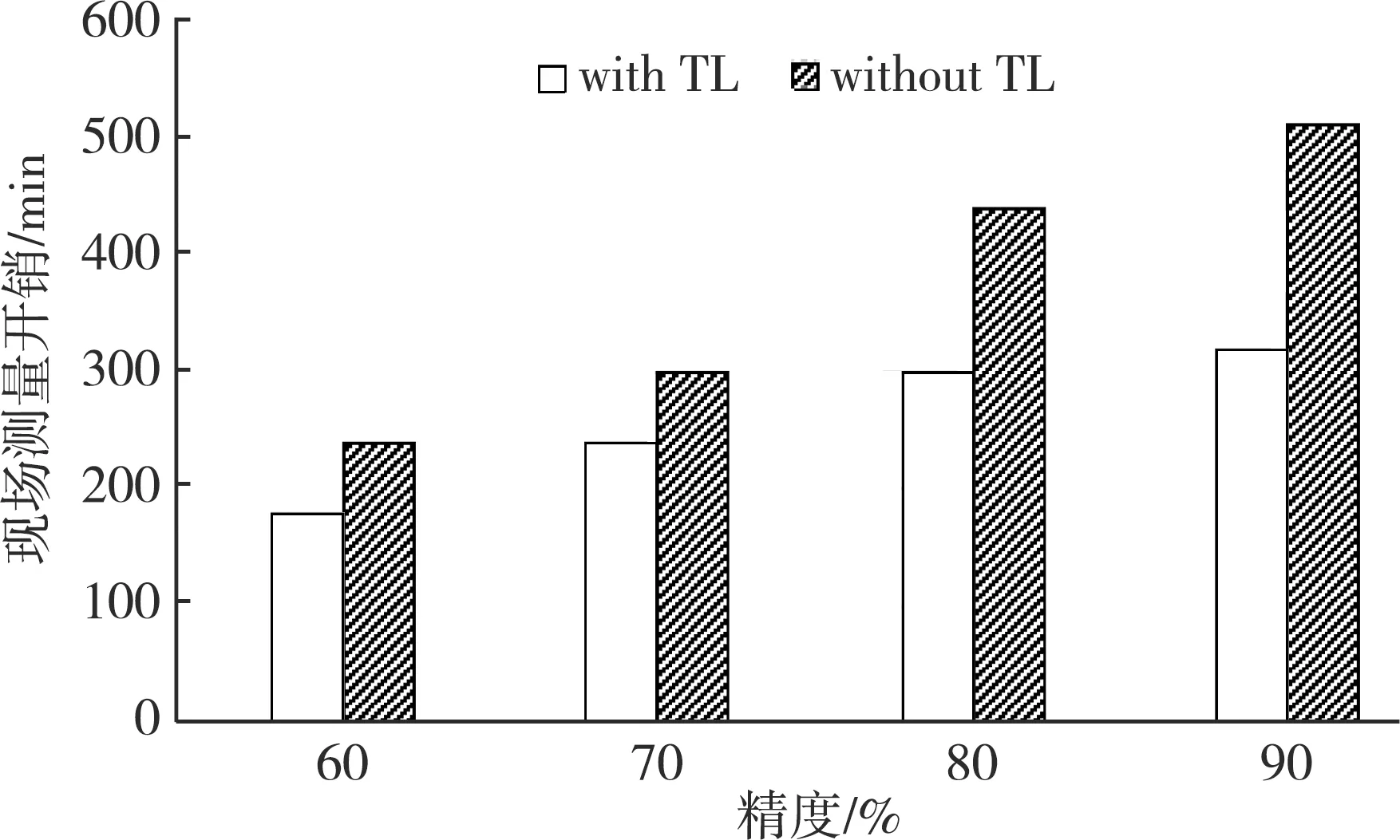
图2 不同精度要求下的现场测量开销
4 结 语
提出了一种通过减少离线训练开销,但是不影响定位精度的基于TL框架的室内定位算法。其基本原理是根据源域的知识转移重构目标域中的数据分布,使得属于同一个簇的数据在逻辑上彼此接近,而剩余数据则彼此分开。基于TL的框架由2部分组成:度量学习和度量转移,分别用于从源域学习距离度量,并分别为目标域确定最合适的度量。最后利用仿真实验数据,通过精度比和现场测量开销性能比较,证明了基于TL框架定位系统的有效性。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
防爆电机(2021年4期)2021-07-28
计算机技术与发展(2020年11期)2020-12-04
铁道通信信号(2020年6期)2020-09-21
数学年刊A辑(中文版)(2019年3期)2019-10-08
铁道通信信号(2019年3期)2019-04-25
中成药(2018年2期)2018-05-09
青年文学家(2015年29期)2016-05-09
中国学术期刊文摘(2016年1期)2016-02-13
