
基于可见/近红外光谱技术的新鲜茶叶叶片含水率快速测定
2018-09-10 11:19张筱蕾唐善虎
西南民族大学学报(自然科学版) 2018年4期
张筱蕾,夏 威,唐善虎
(西南民族大学生命科学与技术学院,四川 成都 610041)
中国是茶叶的消费大国,茶叶的品质受到众多因素的影响.在茶叶加工过程中,水分对于茶叶品质的形成起着非常重要的作用.原料的物理状态和化学反应进程直接受其内部水分含量影响[1-2].当水分含量小于5%时,茶叶香气变化比较小;而当水分含量高于6.5%时,茶叶品质则下降得比较快[3].传统检测茶叶中含水率的方法是烘干法[4],此法费时费力、效率低,不能实现在线检测.由于茶叶的营养成分在高温烘干过程中被破坏,以致样本测试后不能再食用,因此烘干法无法满足茶叶加工过程实时检测的需要.研究新型的检测方法对提高检测效率、改善茶叶品质都具有重要意义.
光谱技术具有操作简单、效率高、价格低和无损检测等优势,目前此技术已在众多领域中使用[5-12].但是在茶叶加工工序中利用可见-近红外光谱技术对其含水率检测的研究大多基于全谱段光谱数据,具有信息量大、波谱冗余重叠等特征,不利于开发快速、高精度、实时的分析监测系统.本文利用可见-近红外光谱技术检测新鲜茶叶叶片中的含水率,并提取特征波长建立优化模型.研究的主要目的是:(1)建立光谱信息与含水率的定量关系模型;(2)基于回归系数法(Regression Coefficients,RC)提取特征波长;(3)利用特征波长建立预测模型;(4)比较基于全波段和特征波段模型的预测效果.
1 材料与方法
1.1 光谱仪和烘箱
本研究采用的可见/近红外光谱仪型号为ASD FieldSpec Pro FR(Analytical Spectral Device Inc.,Boulder,CO,USA),其光谱范围为 350 ~2500 nm.为了减少室外光和日光灯对试验的影响,在采集光谱信息时应关闭室内电源,使样本处在一个黑暗的环境中,只使用卤素灯.样本采集前将仪器预热20分钟,先进行白板校正,然后再进行样本采集.烘箱型号为GHD-9070A,JingHong,Shanghai,China.分析软件采用Unscrambler V10.1和MATLAB R2009a进行数据分析处理.
1.2 实验流程
试验流程如下:首先采集177个新鲜茶叶叶片样本,依次编号后逐一采集其光谱信息作为X变量,然后通过称重法检测得到每个样本的含水率,作为Y变量.将叶片光谱数据进行预处理之后,建立不同的水分预测模型,再基于回归系数法提取特征波长,利用特征波长建立相应的预测模型.
1.3 预处理
本研究采用5种方法对原始光谱信息进行预处理,包括S.G平滑(Savitzky-golay smoothing)、归一化法(Normalization)、变量标准化(Standard normal variate,SNV)处理、多元散射校正(Multiplicative scatter correction,MSC)以及去趋势(De-trending).每一种预处理方法都代表不同的含义.
平滑是消除噪声的一种有效方法,本研究中使用S.G卷积平滑法对光谱进行降噪处理,该方法通过多项式来对移动窗口内的数据进行多项式最小二乘拟合,因此,也被称为多项式平滑[13].
归一化处理是将所有数据转化为0和1之间的值,具体计算公式如下:

式中x0是原始值,x是归一化处理后的值,xmax是最大值,xmin是最小值.
SNV的作用是校正散射造成的样品间的误差,具体计算公式是将原始光谱xi与平均光谱x-的差值除以原始光谱的标准偏差s,即标准正态化处理.

经SNV处理后,光谱数据的均值为0,标准差为1.
MSC的目的是消除散射对光谱数据的影响,这些散射通常是由于样本的不均匀及颗粒大小差异造成的.
De-trending的作用是消除漫反射光谱的基线漂移,该算法的思路是依据多项式将光谱xi的吸光度和波长拟合出趋势线li,然后将趋势线从原始光谱中减去(xi-di).一般而言,通过去趋势处理后,光谱数据的波峰和波谷的特征更加明显[14].
1.4 偏最小二乘
本研究采用偏最小二乘法PLS预测茶叶含水率.PLS是一种有效的光谱建模方法,已被广泛用于众多领域[15-20].当变量数多于样本数时,此方法极其有效[21-22].其原理是先求出光谱数据中的主因子,即隐含变量(Latent Variable,LV),这些LV中含有大量的有效信息[23].将LV按其累积贡献率大小进行排列,运用LV的得分值建立预测模型.
1.5 特征波长提取方法
为了减少模型的输入变量、简化模型,本研究采用回归系数法(Regression Coefficients,RC)提取特征波长.特征波长的提取是将原始全部变量简化为少数变量的过程,这些新的特征变量能够包含原始光谱数据的有效信息,产生与全波段变量相似或者更优的预测结果[24].RC法提取特征波长目前已被用于很多领域[25-26].在RC图中,绝对值越大的波长点代表这些波长对模型的影响越大,这些波长都处在波峰或者波谷位置[17].
1.6 模型评价标准
预测模型性能的评价参数是建模集决定系数(coefficient of determination in calibration,),交互验证集决定系数(coefficient of determination in crossvalidation,),预测集决定系数(coefficient of determination in prediction),剩余预测偏差(residual predictive deviation,RPD),预测集均方根误差(root mean square error in calibration,RMSEC),交互验证集均方根误差(root mean square error in cross-validation,RMSECV),预测集均方根误差(root mean square error in prediction,RMSV).RPD的值小于1意味着预测模型很差,介于1.0和1.4之间表明预测模型较差,1.4和1.8之间表明模型一般,1.8和2.0之间说明预测结果好,2.0和2.5之间意味结果很好,大于2.5表明预测结果极好[27-28].一个预测判定好的模型理应需要较高的,,和RPD值,以及较低的RMSEC,RMSECV and RMSEP值,同时,和值相差较小[29].
2 结果与分析
2.1 光谱曲线
将波长/nm作为横坐标,所有光谱反射率值转化为吸收值作为纵坐标,得到光谱曲线如图1所示.通过图1可以发现,波段首尾处含有较大的噪声,因此本试验截取中间一段波长450~2 400 nm进行研究.组成有机分子的各种官能团都有其特定的红外吸收峰,因此通过光谱图的各种峰可以推断出物质的分子结构.在茶叶的光谱曲线图中,550 nm左右处的波峰是绿色植物中叶绿素的吸收波段,970 nm处的波谷是由叶片水分子中O-H键引起的,970 nm,1 450 nm和1 940 nm是水的吸收波段[30-31].
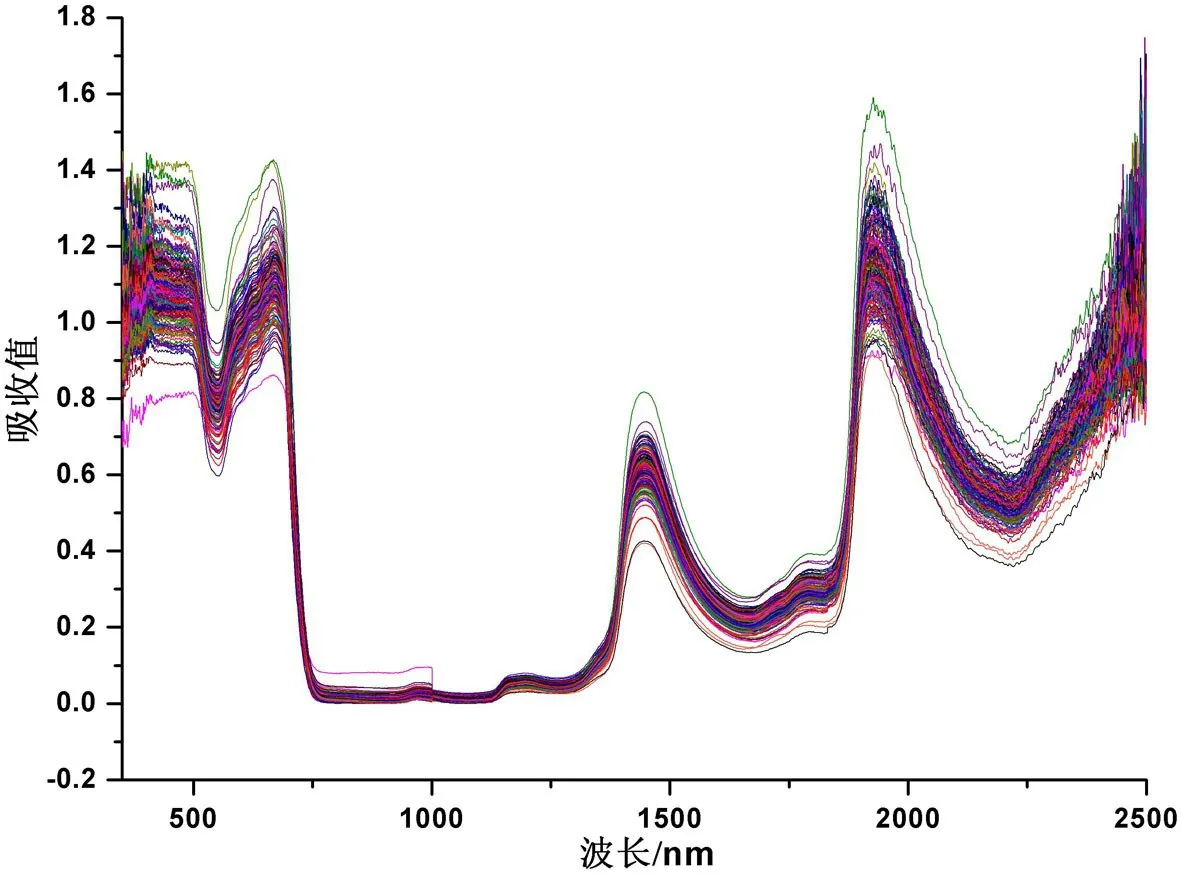
图1 茶叶样本光谱图Fig.1 Spectral absorbance of all tea samples
2.2 含水率
将177个新鲜茶叶叶片依次编号、称重,然后依据国家标准Chinese National Standard GB8304-87烘干至恒重,得到每一个叶片的水分含量.为了使建模集和预测集样本的分类更合理精确、同时也为了使所见模型稳健性更高[1],将所有样本按照Y变量从小到大的顺序依次排列,按照2:1的比例将全部样本分为建模集和预测集,每一个集合中的最小值、最大值、平均值和标准偏差值见表1.建模集和预测集中没有任何一个样本是重复的,这有助于提高模型的稳定性[32].同时根据留一法将建模集样本进行交互验证,即建模集样本同时作为验证集样本,如果建模集和交互验证集的预测结果相差较大,说明模型不可信,反之,模型稳健性高[29].

表1 茶叶叶片水分含量统计分析Table 1 Descriptive statistics of moisture content in tea leaves
2.3 预处理预测结果
为了消除噪音、降低基线漂移等因素对所建模型的影响,本试验采用5种不同预处理方法对原始光谱信息进行处理,并分别将预处理后的数据建立PLS预测模型.预处理和原始光谱模型的预测结果如表2所示,每一个PLS模型中建模集和交互验证集的预测结果相差不大,说明模型可信.所有模型的RPD值均大于2.0,其中前5个模型的RPD值大于2.5,说明所有模型的预测结果都非常好.和原始波段变量模型相比,经预处理之后的模型(基于去趋势模型除外)的预测结果变化不大.然而由于预处理过程本身也增加了数据运算时间,降低了效率,因此综合考虑之后,利用原始数据的建模效果最好.
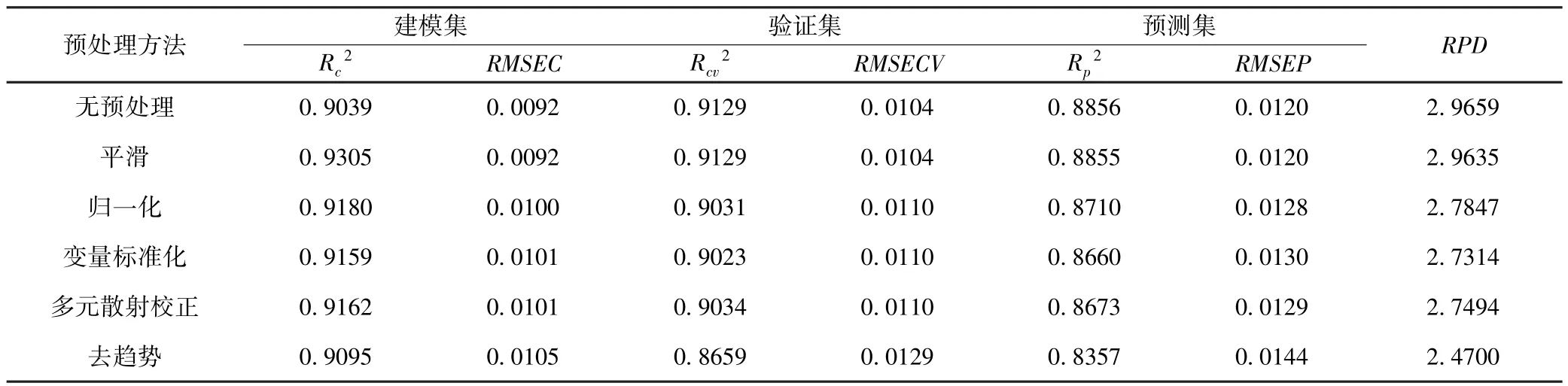
表2 基于不同预处理方法的全谱段数据PLS模型预测结果Table 2 Prediction results by PLS models with different preprocessing using whole spectra
2.4 特征波长提取
为了提高运算效率、简化模型、为后续在检测仪器开发提供理论依据,本研究通过回归系统法提取特征波长,并将提取的特征波长作为新的X变量建立预测模型.新得到的特征波长如图2所示,其中977和1945nm是水吸收的特征波长.被提取的9个特征波长数仅占原始全波段变量数的0.42%,较少的输入变量减少了运算时间,优化了模型.
2.5 基于特征波长的预测结果
为了研究新的特征变量的预测效果,同时和经过不同预处理的全波段变量模型相比,本研究进一步将特征变量进行 Savitzky-Golay Smoothing、Normalization、SNV、MSC和De-trending预处理,然后建立相应的PLS模型,预测结果如表3所示.每一个PLS模型中建模集和交互验证集的预测结果相差不大,说明模型可信.未经预处理建立的模型最优,建模集和预测集中 R2分别是 0.9070和 0.8199,RMSE分别是0.0107和0.0151,RPD是2.3701.所有模型(除去趋势模型)的RPD值均大于2.0,说明模型的预测结果都很好.基于去趋势模型的预测效果一般,这和基于全波段变量中去趋势模型的预测结果是一致的.和全波段模型相比,基于特征波长的模型预测结果有所下降,基于去趋势模型预测结果的下降较为明显.然而,特征波长的选择使输入变量大大减少,这不仅提高了运算效率,也为仪器开发提供理论支持.
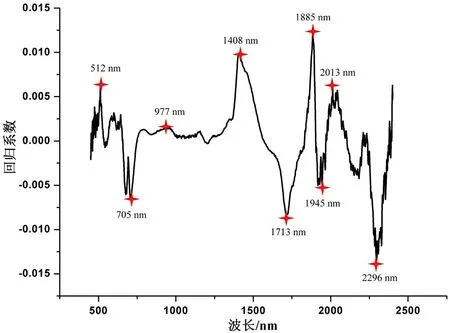
图2 利用回归系数法提取的特征波长Fig.2 Effective wavelengths selected by regression coefficient
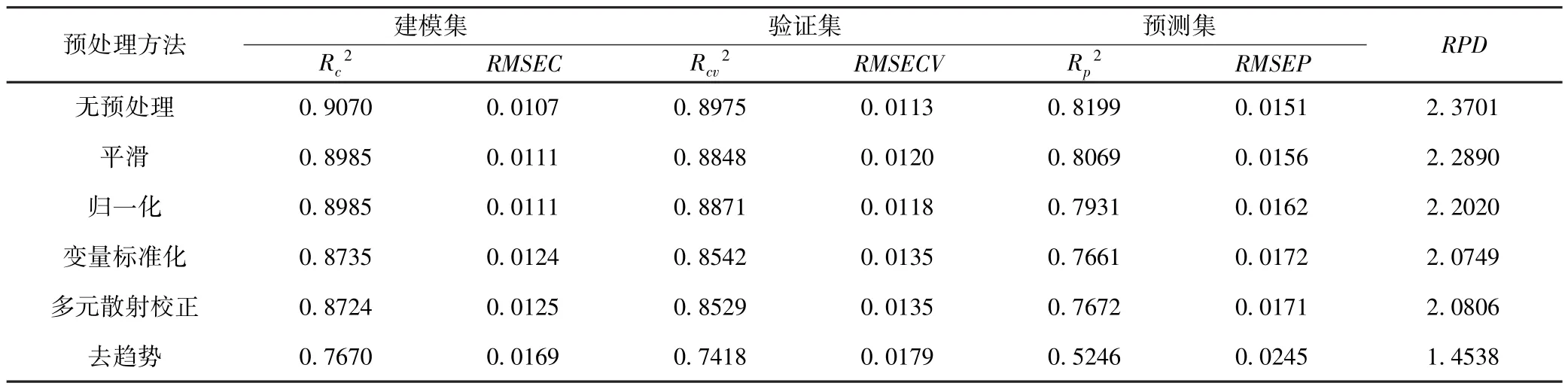
表3 基于不同预处理方法的特征波段PLS模型预测结果Table 3 Prediction of PLS models with different preprocessing using extracted EWs
3 结论
本研究利用350~2 500 nm范围内的可见/近红外光谱技术检测茶叶中的含水率,获取了177个新鲜茶叶的含水率和光谱信息,基于不同预处理方法建立相应的预测模型,每一个模型都取得了较高的预测结果.然后基于回归系数法提取特征波长,新得到的9个特征波长数只占全波段变量数的0.42%,这有利于后续仪器的开发研究.在利用特征变量建立的预测模型中,除预处理方法去趋势效果一般外,其他模型均取得了较好的预测结果.试验结果表明,利用可见/近红外光谱技术结合特征波长的提取来检测茶叶中含水率是可行的,这为茶鲜叶品质分析和等级快速评价提供了理论依据.此外,在线、实时测量还需要建立稳定的光谱测量模型,后续应针对不同类型特征的茶叶进行分析,建立覆盖样本量更广的检测模型.
猜你喜欢
电力科技与环保(2022年3期)2022-07-15
温州大学学报(自然科学版)(2022年2期)2022-05-30
林业机械与木工设备(2022年5期)2022-05-27
阅读(科学探秘)(2021年8期)2021-09-01
潍坊学院学报(2020年2期)2021-01-18
制导与引信(2017年3期)2017-11-02
中南大学学报(自然科学版)(2016年2期)2017-01-19
电子制作(2016年1期)2016-11-07
中国照明(2016年4期)2016-05-17
中国港湾建设(2015年4期)2015-12-11
