
中文微博情感分析模型SR-CBOW
2018-09-07 01:23刘秋慧柴玉梅
小型微型计算机系统 2018年8期
刘秋慧,柴玉梅,刘 箴
1(郑州大学 信息工程学院,郑州 450001) 2(宁波大学 信息科学与工程学院,浙江 宁波 315211) E-mail:liuqhano@foxmail.com
1 引 言
微博作为一种开放的、发展迅速的社交媒体,越来越多的用户将其作为分享和交流的平台,人们不仅喜欢在微博上与朋友进行交流、互动,更愿意对即时播出的影视剧和热销的产品及热点事件发表自己的观点和看法.庞大的微博用户群,通过文本、声音、图片和视频等方式,来发表自己对产品、事件和服务等实体对象的观点和态度,产生的海量数据信息,隐藏着巨大的社会价值和商业价值,引发了很多学者积极参与到微博信息挖掘的研究工作中.
自2002年Bo Pang[1]提出情感分析以来,引起了国内外学者的广泛关注,随着社交媒体的迅速发展,微博情感分析成为当前研究的热点.从微博数据中分析和监测到的用户的信息,已经被应用到诸多领域中,例如商业部门通过分析微博数据中所包含的用户对于某产品发表的观点信息,预测产品的销售状况,帮助自动推荐系统更加准确的判断是否向用户推送广告;政府部门则通过监测到的微博信息,来实时掌握民情、民意.
微博具有便捷性和原创性,内容短小精悍一般限制在140字左右,融合了情感词、网络用语和表情符号等情感特征.构建网络用语词典、情感词表、表情符号向量空间和词向量,是学习微博情感特征的有效方法之一.本文提出了半监督的情感分析模型SR-CBOW(Softmax Regression-Continuous Bag-of-Words),利用词向量学习微博短语的情感特征,可以同时进行词向量的训练和微博情感分析.本文的章节安排为:第2节介绍相关工作,第3节介绍本文提出的情感分析模型SR-CBOW,第4介绍实验,第5节介绍工作总结与展望.
2 相关工作
微博情感分析方法归纳起来可以分为两类,有监督的学习方法和无监督的学习方法.有监督的学习方法,通过有标签的样本来训练模型,并利用训练好的模型对未见文本进行分类.起初,有监督的机器学习方法朴素贝叶斯、最大熵和支持向量机被应用于情感分类任务[2];近几年,深度学习方法被推上了热潮.无监督的学习方法不需要人工标注语料,省去了大量的人力劳动,因此,也得到了研究者的广泛关注.基于主题模型的情感分类方法,是使用最为广泛的无监督情感分类方法[3],有代表性的一些算法有,Mei[4]等人提出的主题情感模型TSM,Lin[5]等人提出的基于LDA模型的JST模型.无监督的学习方法虽然不需要付出高昂的代价来标注数据,但是其情感分析的结果往往略低于有监督的学习方法.
深度学习是机器学习的一种范式,近年来引起工业界和学术界的广泛关注[6].深度学习常见的三种基本模型为多层感知机(MLP,Multi-layer Perceptron)、循环神经网络(Recurrent Neural Network)和卷积神经网络(Convolutional Neural Network),被应用于分词、词性标注、情感分析和机器翻译等诸多自然语言处理任务中.何[7]等人提出了增强情感语义的多通道卷积神经网络(EMCNN,Emotion-semantics enhanced Multi-channel Convolution Neural Network)模型,该模型利用表情符号的向量增强多通道卷积神经网络(MCNN,Multi-channel Convolution Neural Network)模型的情感语义,来提高微博情绪识别的准确性.梁[8]等人在递归自编码网络的基础上,构建极性情感转移模型,并将其应用于微博情感倾向性分析任务中.深度学习的模型较复杂,导致模型对数据集的需求更大,模型训练需要的时间也更多.
微博数据中表情符号、网络用语和无情感色彩字符的出现,严重制约微博情感分析性能的提高.表情符号作为情感表达的方式之一,在微博文本中出现的概率超过7%,模型对于表情符号的理解是情感分析任务的难点之一,Jiang[9]等人提出表情符号空间模型(ESM,Emoticon Space Model),利用一维向量空间表示一个表情符号,将词替换为与之相似度最高的表情符号,并用其进一步构建微博的向量表示,该方法通过将文字语言替换为更简洁、直观地表情达意的表情符号,巧妙的把高维的词向量转换为低维的表情符号向量,使之在少量手工标注的数据上有更好的表现;网络用语的自主化、个性化、全息化、符号化、创新化等特性,使其信息传递的方式更形象、使用也越来越广泛,按照其来源网络用语被分为谐音词、缩略词、象形词、转义词和新词五大类[10],如谐音词“厚厚”表达的涵义为“吼吼”表示开心,缩略词“请允悲”为“请允许我做一个悲伤的表情”的简写,象形词“orz”像一个人跪在那里,表示自己很无奈,新词“我去”表示对于某事感到惊讶,而统计模型较难学习该类词明确的语义信息,网络词汇词典的构建,为此问题的解决提供了帮助;微博文本中数字、URL等无情感色彩的字符的出现,影响了分词和词性标注等情感分析基础任务的准确性,通过删除文本中的该类字符,降低噪声的干扰以提高情感分析的准确性.
针对微博数据的特点及中文微博情感分析任务中人工标注数据相对较少的情况,本文提出了半监督的情感分析模型SR-CBOW.与受限于具体语境的基于语料库的方法相比,该模型对大规模无标注的微博语料进行学习,利用自动获取的语义信息,辅助完成情感分析任务.对于不平衡的微博情感分析数据集,本文对语义相似度最高的微博进行合并,通过减少所占比重较高的情感类的样本数量,解决数据集的不平衡问题;为提高SR-CBOW模型情感分析的准确性,采用否定扩散的方法突出否定词的重要性,利用对词语添加的否定标记,来获取关键的词序信息,协助SR-CBOW模型实现情感转移.
3 情感分析模型SR-CBOW
SR-CBOW模型在对微博的向量表示进行情感分类的同时,利用微博中词语的上下文信息进行词向量的训练,从而使模型得以有效地利用包含在文本中的语言信息,更好地完成情感分类任务.SR-CBOW模型进行情感分析的主要流程,如图1所示.
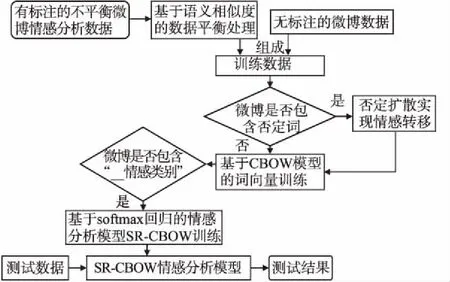
图1 SR-CBOW模型流程图Fig.1 SR-CBOW model flowchart
首先,通过基于语义相似度的数据集平衡方法,均衡微博情感分析数据集中不同情感类的样本数量,将得到的均衡数据集和大量无标注的微博数据,作为模型的训练数据;其次,对训练数据中包含否定词的微博进行否定扩散,通过添加否定标记,来标识关键的词序信息,缓解SR-CBOW模型构建过程中,微博向量表示方式造成词序信息丢失的问题,协助模型对包含否定词的微博进行情感转移;最终,CBOW模型根据窗口内的上下文信息预测当前词,进行词向量的训练和语义信息的获取,通过查找向量表,得到微博中所有词的向量表示,并对其进行累加取平均,作为微博短语的向量表示,并通过 softmax回归方法对微博的向量表示进行情感分类.
为了提高词向量的质量,本文在训练语料中加入了大量未标注的微博数据,并以“__情感类别”区分有标注的情感分析语料以及未标注的纯文本语料,在进行词向量训练之后,如果数据中包含“__情感类别”标记,则对该微博进行情感分析模型的训练.
3.1 基于语义相似度的数据平衡处理
不平衡数据集使SR-CBOW模型预测的结果往往倾向于样本数量较多的情感类,严重影响了情感分析的结果.针对此问题,本文采用基于微博语义相似度的数据平衡方法,通过合并相似度最高的微博,缓解数据集的不平衡性.
定义1.本文将情感类别相同的微博twg和twh的相似度函数Sim(twg,twh)定义为:
(1)
其中,wgi与whj表示微博twg和twh中出现的动词、形容词或副词,ng和nh分别代表上述三类词语在微博twg和twh中总的数量,sim(wgi,whj)[11]表示基于知网的词语wgi和whj的相似度计算.首先给定某一情感类别,然后遍历数据集中该情感类的所有微博,并将相似度最高的两条微博进行合并,每进行一轮,该情感类的微博样本数减半.该方法在没有数据损失的情况下,降低了训练数据集上所占比重最高的情感类的样本数量,增加了低频情感类别的权重,从而均衡模型预测结果的分布、提高情感分析的性能.
3.2 否定扩散实现情感转移
模型对于包含否定词的微博短语,较难做出准确的分类.针对此问题,采用否定扩散的方法来突出否定词的重要性,与传统的TF-IDF[12]相比,该方法不仅可以突出重要词语、抑制次要词语,还可以利用添加的否定标记,来获取关键的词序信息.
SR-CBOW模型的构建过程中,通过向量累加来构建微博向量表示的方式,会导致词序信息的丢失,尤其是对于有否定词出现的微博,关键的词序信息决定了是否对该微博进行情感极性转移.例如微博“我/rr 送/v 的/ude1 礼物/n 你/rr 喜欢/vi 不/d”和“我/rr 送/v 的/ude1 礼物/n 你/rr 不/d 喜欢/vi”有相同的向量表示,如公式2和3所示,但要表达的情感信息却截然不同.
(v我+v送+v的+v礼物+v你+v喜欢+v不)/ 7
(2)
(v我+v送+v的+v礼物+v你+v不+v喜欢)/ 7
(3)
针对上述问题,本文采用否定扩散的方法,对出现在否定词之后的词语添加否定标记,例如,原有的情感词“喜欢”,添加否定标记后得到新的词“喜欢
(v我+v送+v的+v礼物+v你+v喜欢+v不)/ 7
(4)
(v我+v送+v的+v礼物+v你+v不+v喜欢< neg >)/ 7
(5)
从公式(4)和公式(5)中可以看出,否定扩散的方法通过对微博中相应的词语添加否定标记,来标识动词、形容词和副词与否定词的前后位置,为SR-CBOW模型提供关键的词序信息;同时通过添加否定标记,将原有的情感词“喜欢”改变为新的词“喜欢
本文收集建立的否定词表,如表1所示.

表1 否定词表Table 1 Privative words table
考虑到一个否定词只能影响它所在的短句,而不是整条微博,因此,将否定扩散的范围限定到否定词所在的短句中,例如,对于微博“不/d 舒服/a./wj 拉肚子/v./wj 还/d 低烧/n.”只需对第一个短句进行否定扩散.本文收集建立了标点符号表,将否定扩散限制在一定的范围内,所包含的符号如表2所示.

表2 标点符号表Table 2 Punctuation table
一个词语之前可能存在多个否定词,本文假定双重否定表示肯定,当已记录否定词的数量为奇数,且当前词语属于动词、形容词或副词时,才对其添加否定标记,进行否定扩散,具体实现过程如算法1所示.
算法1.否定扩散
输入:微博tw,否定词表privative_table,标点符号表Punctuation_table
输出:否定扩散后的微博
1. 首先使用NLPIR分词工具进行分词和词性标注工作
2. 初始化否定标志flag=False
3. forwintwdo
4. ifwinprivative_tablethen
flag=flag取反
5. else ifwinPunctuation_tablethen
flag=False
else
6. ifflagandw∈{verb,adjective,adverb} then
w=w+“
end if
end if
更新tw
end for
7. returntw
3.3 SR-CBOW模型实现情感分类
3.3.1 基于CBOW模型的词向量训练
目前微博情感分析的语料较少,模型难以充分获取低频词的语义信息,导致情感分析模型无法得到有效的训练.针对此问题,CBOW模型通过周围的词来预测当前词,有效地利用了包含在文本中的语言信息,协助SR-CBOW模型完成情感分析任务;并采用欠采样的方法,均衡数据中的高频词和低频词,提高词语和微博向量表示的质量,为情感分析奠定基础;为了提高模型的训练速度,采用了近似于-log softmax的噪声对比估计方法.
CBOW模型通过上下文来预测当前词,共分为输入层、投射层和输出层三部分,CBOW模型的结构如图2所示.

(6)
为了均衡微博文本中高频词语及低频词语的影响,使出现频率较低的词语仍然能够得到充分的训练,在取上下文词语时,对其进行欠采样处理,按照公式(7)所示的概率舍弃词语wt+i:

图2 CBOW模型结构图Fig.2 CBOW model structure diagram
(7)
其中f(wt+i)表示词语wt+i在训练语料中出现的频率,λ为预设定的阈值,实验中使用10-5.

(8)
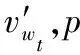
(9)
其中σ(·)为sigmoid函数,负例集合N为:
N={wi|wi∈V&wi∉{wt-k…wt+k}}
(10)
3.3.2 基于softmax回归的情感分类
softmax回归是逻辑回归在多分类问题上的扩展,是常用的有监督的多分类方法.本文采用softmax回归模型对微博的向量表示进行情感分类,通过最优化负对数似然惩罚函数,对情感分析模型SR-CBOW进行训练.
定义2.本文将微博短语的向量表示定义为,微博中所有词语向量累加的均值,如公式(11)所示:
(11)
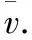
(12)
其中W2为权重矩阵,m表示情感类别数,b为偏置,s的维度为m.微博属于各个情感类的成绩分别为s1,s2…sm,并利用softmax函数计算微博属于每个情感类别的概率:
(13)
其中yi表示第i维是否为微博的目标情感类别,如果第i维是微博的目标情感类,yi为1,否则yi为0.p的每一维代表模型预测微博为相应情感类别的概率,概率最大的情感类别为该微博情感分析的结果.模型训练的目标是使目标情感类别的概率尽可能的大,使用的惩罚函数为:
(14)
情感分析模型SR-CBOW在大量无标注的微博数据和少量标注的情感分析数据上进行训练,其过程如算法2所示.
算法2.SR-CBOW模型的训练
输入:微博训练数据集D,初始学习速率start_lr,无监督训练周期cbow_epoch,词向量矩阵M,系数矩阵W1,W2
输出:训练好的情感分析模型SR-CBOW
1. 初始化训练周期epoch=1
2.D1=对D进行基于语义相似度的数据平衡处理
3. while 误差下降 do
lr=start_lr/ epoch
4. fortwinD1do
5.tw=对包含否定词的tw进行否定扩散
string_tag=获取tw的第一个标记
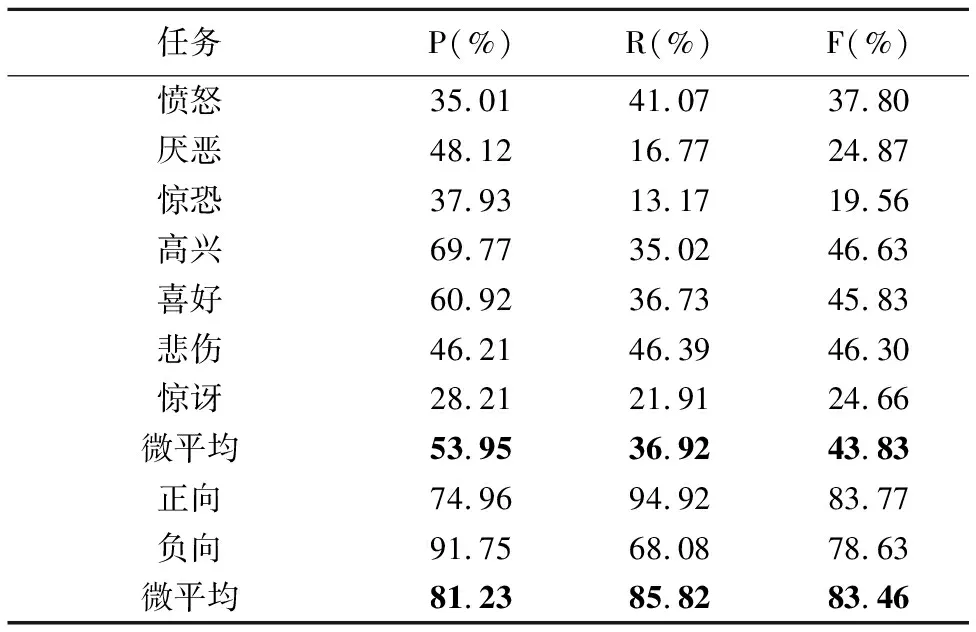
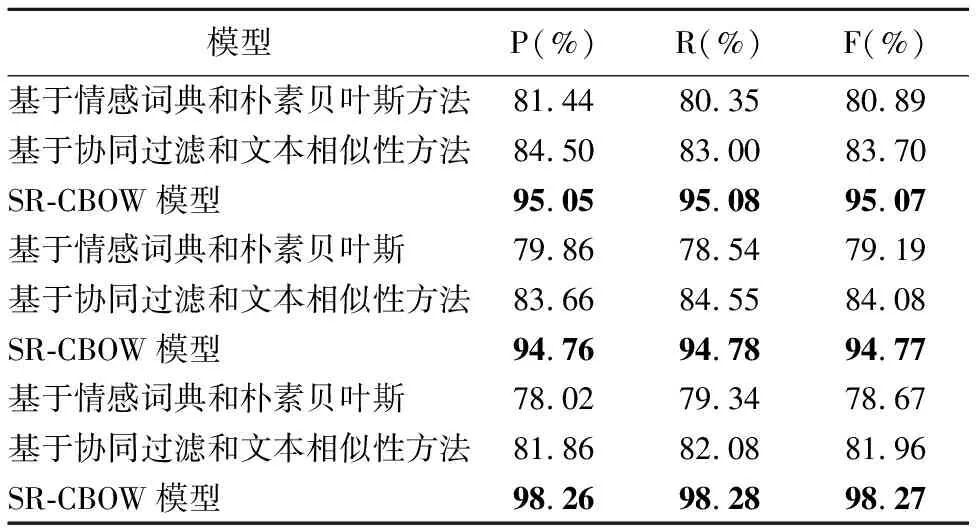
6. ifepoch 7. forwintwdo w左右各取k个词作为CBOW模型的输入,预测w,计算惩罚函数对M、W1的导数△M、△W1 M=M-lr* △M W1=W1-lr* △W1 end for end if 8. ifstring_tag==“__情感类别” then tw中所有词向量通过情感分析模型预测情感类别,计算惩罚函数对M、W2的导数△M、△W2 M=M-lr* △M W2=W2-lr* △W2 end if end for epoch=epoch+1 end while 9. return SR-CBOW模型 本文实验所使用的数据是NLP&CC2013情绪识别任务和CCIR2014情感倾向性分析任务的评测数据,无情感标签的微博语料来源于中国爬盟网站,共整理得到约30G的微博文本.情绪识别任务将情感分为7类,分别对应愤怒(anger)、厌恶(disgust)、惊恐(fear)、高兴(happiness)、喜好(like)、悲伤(sadness)和惊讶(surprise),情感倾向性分析任务将情感分为两类正向和负向,训练集中每个情感类及对应出现的频次(样本的数量)如表3所示. 本文使用准确率P(Precesion)、召回率R(Recall)、F值(F-measure)和微平均评估情感分析模型SR-CBOW,微平均的计算公式为: 表3 情感类别及出现的频次Table 3 Emotions and frequency of occurrence 其中sys_correct表示模型预测的结果和目标值一致的数目,gold表示微博的目标情感数目,sys_proposed表示模型标注的数目,i的取值在情绪识别任务和情感倾向性分析任务中,分别对应7类情感值和2类情感倾向值. 本文共分为5组实验,第1组实验是对向量维度的选择,以期得到能较好适应模型的向量表示;第2组实验是在第1组实验的基础上展开的,利用无标注的微博数据协助模型训练;第3组实验验证本文提出的否定扩散方法的有效性;第4组实验利用基于语义相似度的数据平衡方法,对没有情感色彩的微博样本进行合并,来缓解数据集的不平衡性,从而提高情感分析的准确率;第5组实验在电脑、酒店和书籍消费评价的语料(平衡数据集)上进行,来验证移除定制技巧后SR-CBOW模型的泛化能力和领域适应能力. 向量的维度是需要调整的主要参数,维度越高模型中的参数就越多,容易导致模型过拟合,维度过低则难以包含所需要的信息.本文以情绪识别任务为主,通过调整词语向量的维度,选取适合数据集和模型的向量维度,参数调整的过程如图3所示. 图3 向量维度调整Fig.3 Vector dimension adjustment 从图3可以看出,当情感分析模型中词向量的维度高于50时,其准确率开始下降,在向量维度为44时,Mic_P、Mic_R和Mic_F的值分别为56.1%、32.37%、41.05%,此时的Mic_F值最高,接下来的实验中向量维度都设置为44. 在向量维度为44的基础上,训练数据中加入大量无情感标签的微博数据,模型的Mic_F值提高了0.76个百分点,其结果如图4所示. 图4 加入无标签数据集的情感分析结果Fig.4 Emotion analysis results with unlabeled data set added 灰色的柱状图表示加入无情感标签微博数据后,情绪识别任务的结果.情绪识别任务和情感倾向性分析任务,每个情感类的识别结果,如表4所示. 表4 情感分析结果Table 4 Emotion analysis results 其中情绪识别任务的情感分析结果,明显低于情感倾向性分析任务,从任务本身和任务的数据特点分析,情绪识别任务中每个情感类的样本数量分布不均衡,尤其是标签为“none”的样本,约占样本总量的3/5,是导致情绪识别结果较低的主要原因. 加入否定扩散之后,在情绪识别任务和情感倾向性分析任务中,Mic_F值分别提高了2.02和1.29个百分点,几乎每个情绪类别的召回率都得到提高.因为,微博短语往往较短,数据中包含否定词语的情况也较少,所以,该方法对情感分析结果的提高程度有限.具体结果如表5所示. 从表4和表5可以看出情绪识别任务中模型的准确率较高,而召回率却很低.根据表3的统计信息可以发现训练样例中包含大量没有情感色彩的微博,数据集的极度不平衡是造成召回率低的主要原因.针对此问题,本文通过减少标签为“none”的样本数量,来降低其频率,以均衡模型的准确率与召回率.数据平衡处理对结果的影响,如图5所示. 表5 基于否定扩散的情感分析结果Table 5 Emotion analysis results with negative spreading 图5 数据平衡处理及对应的情感分析结果Fig.5 Data balancing and emotion analysis results 其中纵轴表示情感分析结果的评估值,横轴表示将没有情感色彩的微博合并后,微博样本的数量,当执行4轮数据集平衡处理时,情感分析的结果最好.随着标签为“none”的微博样本,在训练语料中比重的降低,情感分析模型的召回率快速上升,同时Mic_F值得到较为明显的提高;当该比重降低到一定程度后,情感分析的准确性开始下降,本文只取得了局部最优结果.选择Mic_F值最高的结果,作为SR-CBOW模型的最终结果,其Mic_F值提高了6.28个百分点,与其它模型的情感分析结果进行比较,如表6所示. 表6 情感分析结果对比Table 6 Comparison of emotion analysis results 其中融合显性和隐性特征的无监督聚类方法的结果要略低于其它方法,基于深度学习的MCNN模型和情感极性转移模型,虽然结果较无监督的聚类方法好,但训练模型需要的时间较多,且F值略低于未进行数据平衡的SR-CBOW模型.本文提出的半监督情感分析模型SR-CBOW,结构简单、模型训练快,并且情感分析结果优于已知模型. 由表6可以看出,在数据集不平衡的微博情绪识别任务中,通过平衡数据集,可以使SR-CBOW模型的情感分析结果得到进一步的提升. 为了验证本文提出的SR-CBOW模型的鲁棒性,本文在其它领域的平衡数据集上,使用移除定制技巧的情感分析模型SR-CBOW进行实验,来检验模型的泛化能力和处理其它领域数据的能力.该数据集为包含电脑、酒店和书籍3个领域消费评价数据的中文情感挖掘语料-ChnSentiCorp[18].对应的情感分析结果如表7所示. 表7 消费评价语料的情感分析结果Table 7 Consumption evaluation data emotion analysis results 前两种方法是文献[18]中实验及对比实验的方法.通过表7可以看出,未使用数据平衡手段的SR-CBOW模型,在消费评价数据的情感分析任务中,也可以取得理想的结果. 本文提出情感分析模型SR-CBOW,利用文本中包含的语言信息辅助模型的训练,并通过否定扩散的方法,解决生成微博向量表示时语序信息丢失所带来的问题,在情绪识别任务和情感倾向性分析任务中取得了目前已知的最好结果,并可以通过均衡数据集等手段进一步提升. 不同的词语蕴含不同程度的情感信息,对情感分析结果的影响程度也不同;否定扩散可以保留情感分析问题中较关键的语序信息,但仍会损失一些语序信息.针对这些问题,下一步将探究一种保留词序信息的、加权的微博向量表示构建方法,实现对微博向量表示的自动化学习,以期获得更好的微博情感分析结果.4 实 验
4.1 实验数据及评价指标

4.2 实验及结果分析





5 总结与展望
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
国际医药卫生导报(2022年18期)2022-09-29
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年7期)2021-08-13
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小天使·一年级语数英综合(2020年4期)2020-12-16
高中生学习·高三版(2016年9期)2016-05-14
燕山大学学报(2015年4期)2015-12-25
新高考·高二数学(2015年11期)2015-12-23
传奇故事(破茧成蝶)(2015年7期)2015-02-28
