
基于关联规则的热点事件时序分析方法
2018-09-06 01:54王奕文
计算机与现代化 2018年8期
王奕文,刘 昕,曹 帅,王 丰
(中国石油大学(华东)计算机与通信工程学院,山东 青岛 266580)
0 引 言
随着Internet的广泛普及与飞速发展,已经从根本上改变了人们获取信息和事件传播的形式。由于越来越多的人倾向于利用网络表达自己的态度和观点,催生出大量社会化媒体平台,如微博、微信、知乎等,促使数据中蕴含的正面或负面的信息急剧膨胀形成舆情[1-2]热点。热点事件的内容在增长和扩散的过程中会形成多个相关话题,因此发现话题之间潜在的关联关系,进而跟踪热点事件的演化趋势和传播路径,从而把握热点事件发展的来龙去脉和重要传播节点,对政府有关部门监控和引导正向舆论具有十分重要的现实意义。
大数据环境下的热点跟踪主要结合数据挖掘知识,利用大数据相关处理技术从海量数据中提取有用的信息用于决策支持。其中,热点评估与跟踪[2]是根据热点事件中公众的情感和行为反应对舆情进行等级评估。热点检测与跟踪[3-4]是将话题转化成中心向量模型,然后对中心向量计算相似度,进而实现舆情信息的分类,从而区分新话题与原来出现过的话题,达到热点跟踪的目的。
基于社会化媒体的舆情传播不同于传统的信息传播,其特点是在较短时间内节点间的连接呈指数级增长,而新连接的产生与节点之间的相似性密切相关[5]。然而现有方法多数通过语义距离或语义相似度分析话题之间的相似性与差异性,来挖掘关键词之间的潜在关联关系。
针对上述问题,本文提出一种基于关联规则的热点事件时序分析方法。通过引入时间片,将关联规则算法并行实现并借助关键词的时序信息直接获取大规模频繁关键词集,在此基础上获取关联规则集,进而筛选和组合得到多个话题关键词集合,从而跟踪热点事件的演化和传播路径。该方法不仅能够发现关键词之间隐藏的关联关系,还能够提升频繁关键词集的挖掘速度。
1 相关工作
热点跟踪方法主要是借鉴数据挖掘中的一些文本分类算法[6-8],如K-最近邻(K-Nearest Neighbor,KNN)算法、朴素贝叶斯(Naive Bayes Classifier,NBC)算法、支持向量机(Support Vector Machine,SVM)等。但是该类方法只能区分多个话题,不能将话题合理有序地组织起来,直观清晰地跟踪热点事件的演化。另一类结合时序信息实时跟踪热点事件演化传播的方法日益增多。比如:楚克明等[9]通过自动抽取不同时间段的话题,计算相邻时间段中任意2个话题的分布距离和话题的特征向量相似度跟踪热点事件的演化。崔凯等[10]利用Kullback Leibler(KL)相对熵来衡量话题之间的相似度,从而根据话题之间的相似性与差异性跟踪热点事件的演化。Alsumait等[11]提出的在线LDA(OLDA)模型先根据时间信息将文本集划分到不同的时间片,之后使用LDA模型对每个时间片的文本集进行建模,并且采用话题的历史分布作为当前时间片话题发现的先验知识,进而研究热点内容和强度的演化。
热点事件在社会化媒体中的传播路径包括以下4大类型[12-13]:
1)线性传播的萌芽期。该时期信息流动直线且单一,信息的传递仅仅是知识获取或行为认知,通常只存在于特殊的用户之中,所以该阶段是最易有效引导和控制舆情方向的时期。
2)裂变式传播的酝酿期。该时期主要基于用户的多级转发行为,通过转发、评论、点赞等方式加速信息的传播速度,扩大信息的受众范围,增大信息的影响力,所以该阶段对政府维护社会安全稳定、安抚用户情绪是一个巨大的挑战。
3)交互性信息传播的发酵期。该时期用户将信息收集后整理、组织、加工,再次传递给其他用户,从而在事件的多角度演化后进入高潮期。
4)高度融合传播的爆发期。该时期最大化融合上述3种信息传播模式,用户既是信息接收者,又是信息发送者,从而形成事件传播的网络。
总之,跟踪话题的演化和传播路径是深度分析热点事件的2个重要研究路线。本文对此进行重点讨论。
2 基本定义
定义1关联规则a⟹b的支持度sup (a⟹b)是指数据集中出现关键词集{a,b}的数据记录占所有数据记录的百分比。其中,num(a∪b)表示关键词集{a,b}在数据集中出现的次数;num(I)表示数据集的所有数据记录的个数。
sup (a⟹b)=num(a∪b)/num(I)
(1)
定义2置信度conf(a⟹b)是指数据集中出现关键词集{a,b}的数据记录与出现关键词集{a}的数据记录之比。
conf(a⟹b)=num(a∪b)/num(a)
(2)
定义3由k个满足支持度阈值的关键词组成的集合为k_项频繁关键词集。若wx表示第x个关键词,则k_项频繁关键词集为lk={w1,w2,…,wx,…,wk}。若lk[i]表示第i个k_项频繁关键词集,则k_项频繁关键词集组成的集合Lk={lk[1],lk[2],…,lk[i],…,lk[t]},t为k_项频繁关键词集的个数。
3 时序分析方法
通过引入时间片和关联规则集的概念,将关联规则算法并行实现获取关联规则,用于形成时序分析方法所需的关联规则集,从而按时间顺序组合所有关联规则集得到多个话题关键词集合,对热点事件的演化过程和传播路径进行跟踪。
3.1 关联规则集获取算法
3.1.1 1_项频繁关键词集获取
TOP关键词能够表示热点事件的绝大多数重要信息,则获取1_项频繁关键词集包括以下2个步骤:
1)根据社交网络页面获取的数据集,计算不同时间片每个TOP关键词的支持度sup _top[i]。若num(top[i])表示第i个TOP关键词出现的次数,由式(1)可知:
sup _top[i]=num(top[i])/num(I)
(3)
2)根据支持度阈值sup _min 获取1_项频繁关键词集。若sup _min ≤sup _top[i],则将sup _top[i]对应的TOP关键词保留,记为l1[j],反之舍弃。由此可得L1={l1[1],l1[2],…,l1[j],…,l1[t]},j≤i。
3.1.2 k_项频繁关键词集获取
并行是将获取频繁关键词集的一个计算任务分解成N个独立的子任务,每个子任务完成整个任务的1/N。获取k_项频繁关键词集包括以下5个步骤:
1)将Lk-1进行数据分割和任务分配,将一个或者m个k-1_项频繁关键词集分配给一个子任务,m的值由k-1_项频繁关键词集的数目确定。其中,N个子任务分配的k-1_项频繁关键词集互不重复。
2)将每个子任务的k-1_项频繁关键词集和所有1_项频繁关键词集逐一合并,得到k_项关键词集。
3)扫描相应时间片的数据集,计算每个k_项关键词集的支持度sup _k_keywords[i]。若num(k_keywords[i])表示第i个k_项关键词集出现的次数,由式(1)可知:
sup _k_keywords[i]=num(k_keywords[i])/num(I)
(4)
4)根据支持度阈值sup _min 获取k_项频繁关键词集。若sup _min ≤sup _k_keywords[i],则将sup _k_keywords[i]对应的k_项关键词保留,记为lk[j],反之舍弃。由此在每个子任务上分别生成Lk={lk[1],lk[2],…,lk[j],…,lk[t]},j≤i。
5)将N个子任务的所有k_项频繁关键词集合并后约简得到全局Lk。
3.1.3 形成关联规则集
关联规则集是由所有k_项频繁关键词集的满足置信度阈值的关联规则组成的集合。其形成包括以下4个步骤:
1)获取全局Lk中所有k_项频繁关键词集的关联规则。由于lk[i]表示第i个k_项频繁关键词集,本文定义lk[i[s]]表示由lk[i]中s个关键词组成的关键词集,lk[i[k-s]]表示去掉lk[i]中s个关键词后剩余的关键词组成的关键词集。则任何k_项频繁关键词集都可以产生多个关联规则lk[i[s]]⟹lk[i[k-s]],其中1≤s≤k。
2)计算每个关联规则的置信度conf(lk[i[s]]⟹lk[i[k-s]])。若num(lk[i])表示lk[i]在数据集中的出现次数,num(lk[i[s]])表示lk[i[s]]在数据集中的出现次数。由式(2)可知:

(5)
3)根据置信度阈值conf_min 筛选关联规则。若conf_min ≤conf(lk[i[s]]⟹lk[i[k-s]]),则将对应的关联规则lk[i[s]]⟹lk[i[k-s]]保留,反之舍弃。
4)将筛选后的所有关联规则合并后约简,形成关联规则集。
3.2 基于关联规则的时序分析算法
算法1基于关联规则的时序分析算法
输入:获取的社交网络页面的所有数据
输出:多个话题关键词集合
1)按照数据的时间序列,分割得到每个时间片对应的数据集。
2)扫描相应时间片的数据集,得到满足sup _min 的L1,此时k=1。
3)令k=k+1,将所有k-1_项频繁关键词集进行任务分割,在每个子任务上独立得到满足sup _min 的k_项频繁关键词集。
4)将所有子任务的k_项频繁关键词集结果合并后删除重复项,得到全局Lk。
5)重复步骤3和步骤4,直到得到的k+1_项频繁关键词集为空,将存在频繁关键词集的最大项数记为n。
6)对k_项频繁关键词集(2≤k≤n)的所有满足conf_min 的关联规则合并后约简形成关联规则集。
7)按照时间序列将每个时间片的关联规则集筛选和组合得到多个话题关键词集合。
4 实 验
4.1 实验数据
通过网络爬虫工具,使用20种关键词组合,如:“中国 印度 对峙”“中国 印度 边界”“印度 洞朗,对峙”等,集中收集2017-06-26~2017-08-28微信公众号中关于“中印洞朗对峙事件”的新闻报道,每天报道个数约为300篇。
根据新闻报道的篇幅长度利用Ansj技术对每篇报道提取适当个数互不重复的关键词作为本文的实验数据集。
4.2 实验环境和工具
通过结合requests和etree库,根据页面文本的URL,利用Python语言编写爬虫工具进行数据采集,并将采集后的数据利用改进的Ansj算法提取关键词。
提取关键词后的实验数据存储在文本文件中,每个文本文件存储一天的数据。算法开始时需要设定支持度阈值和置信度阈值。
多个线程并行处理,一个线程处理一个文本文件。计算每个词的支持度以获取频繁关键词集,计算关联规则的置信度获取关联规则集。最后合并后筛选所有的关联规则集获取话题关键词集合。
4.3 阈值设置的实验及结果
支持度阈值与置信度阈值的设置方法类似,实验以2017年6月27日数据的支持度阈值设置为例,不同支持度对应的L1结果如表1所示。由于多个相同语义的关键词导致结果过于冗长,只保留其中一个关键词。如“中国 中方”只取“中方”。

表1 不同支持度下的L1结果
1)当sup=12.6%~12.8%时,L1能够获取当前时间片的全部有价值的关键词信息。
2)当sup =12.5%时,L1不仅能够获取当前时间片的全部有价值的关键词信息,还包括“合作 工作 取消 文化 市场”与“中印洞朗对峙事件”无关的关键词信息。
3)当sup =12.9%时,当前时间片的有价值的关键词“和平 越界 国防部”被筛选掉,事件发生的重要原因以及国防部的态度信息不能体现。
由上述可知,实验选取临界值12.6%作为支持度阈值,且实验部分的所有支持度阈值和置信度阈值均采用上述方式进行选取。
4.4 事件演化的实验及分析
热点事件在社会化媒体中的话题演变包括以下3级:
1)话题传播初期酝酿阶段。由于社会化媒体是许多个体因兴趣、认同、知识等方面构成的社会网络集合。他们之间存在人与人、人与信息、信息与信息3种直接或间接的连接方式。事件在该阶段开始萌芽并进行酝酿,透过多个节点开始裂变传播。
2)社会网络的关键传播节点。由于社会化媒体中的传播者并不具备同等地位,这就因社会地位、专业知识、传播能力等因素形成少数关键节点。他们在内容传播、话题放大、舆论营造、流量导向等方面具有决定作用。事件在该阶段发酵并全面爆发,形成时下多个热点话题。
3)网络媒体传播的协同阶段。由于社会网络关键节点的延伸使传播面更广,多种传播形态相互协同。再加上话题的侧重点不同,这就使话题向多个角度、多个层次进行演化传播,从而形成热点事件的爆发阶段。
为了表示事件的演化过程,实验以1天为一个时间片分别获取关联规则集,按照时间序列筛选后,组合所有关联规则集得到话题的关键词集合,结果如表2所示。
1)6/26-6/28:事件萌芽期。中方外交部披露印方边防部队越过中印锡金段边界阻挠我方正常活动,双方形成对峙局面。
2)6/29-7/2:事件发酵期。中方解放军在西藏试验,美国呼吁中印对话和平解决冲突。
3)7/3-7/23:事件爆发期。中方外交部多次声明,警告印方的边界活动。印方造势中方入侵不丹领土。中印对峙局势持续升温。出现“增兵 作战 挑衅 反击 爆发 持续”等关键词。
4)7/24-8/11:事件高涨期。中方外交部态度强硬,发表文件多次说明印方越界背后的真实目的。印方表态随时做好作战准备。
5)8/12-8/26:事件高潮期。双方士兵互掷石块,印方民众示威游行,美印双方联合军演。出现“增兵 升级 紧张 大规模 反击”等关键词。
6)8/27-8/28:事件衰退期。印度最终撤军,中印洞朗对峙事件和平解决。
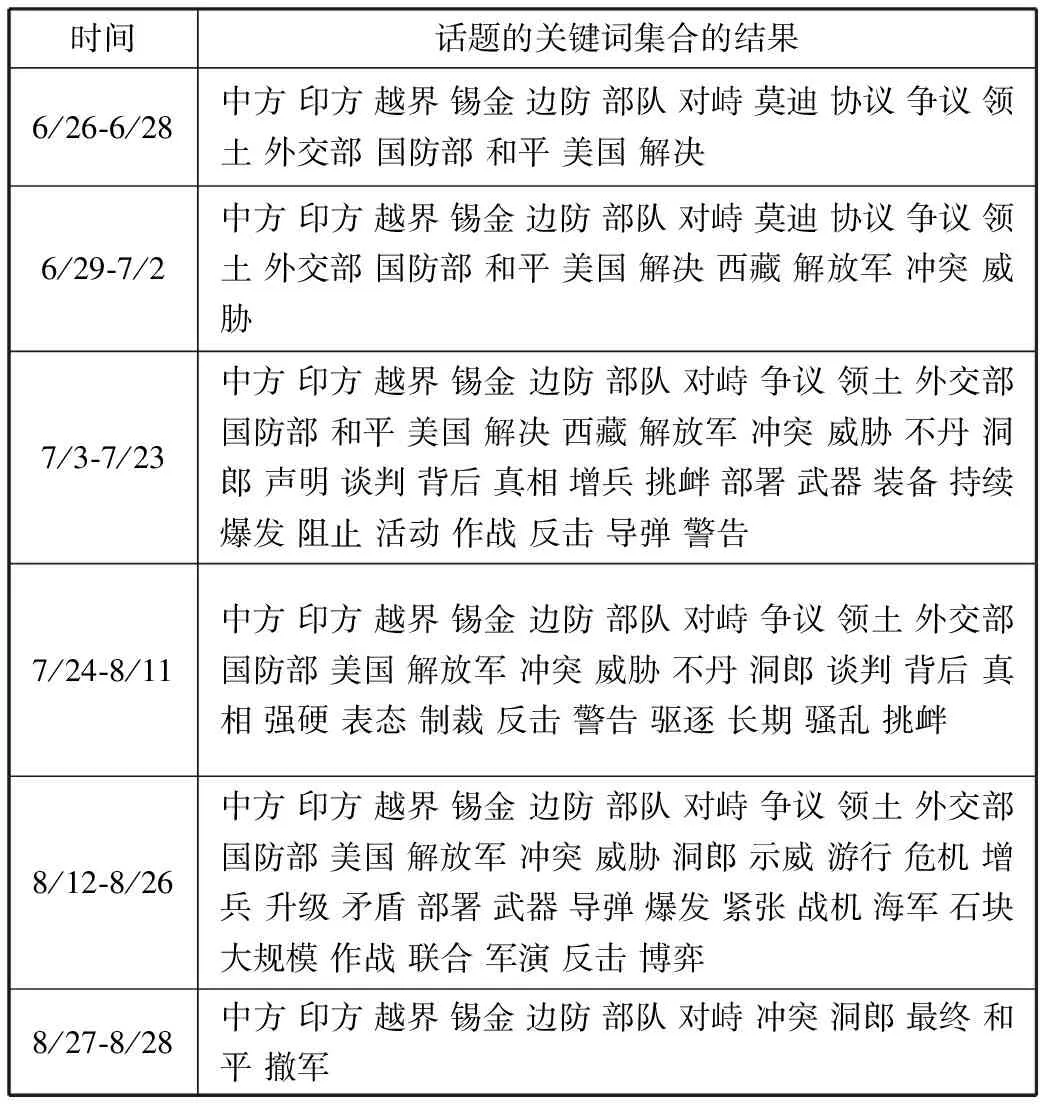
表2 话题的关键词集合的结果
结合中印洞朗对峙事件,话题演化和发展趋势如图1所示。
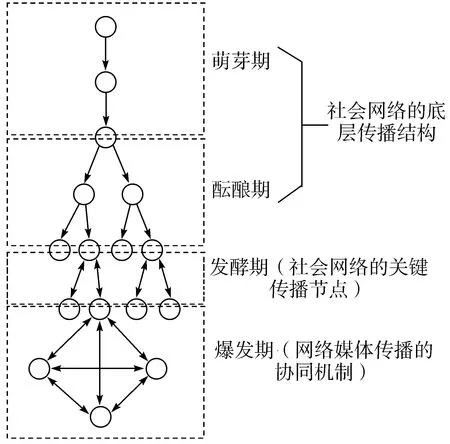
图1 话题演化和发展趋势图
4.5 事件中话题传播路径的实验及分析
实验按照时间发展顺序,以14个热点话题为代表对事件的传播路径进行跟踪。每个话题的具体内容如表3所示。事件的传播路径如图2所示。每个话题与公众号节点的传播关系如图3所示。

图2 事件的传播路径

图3 话题与公众号节点传播关系
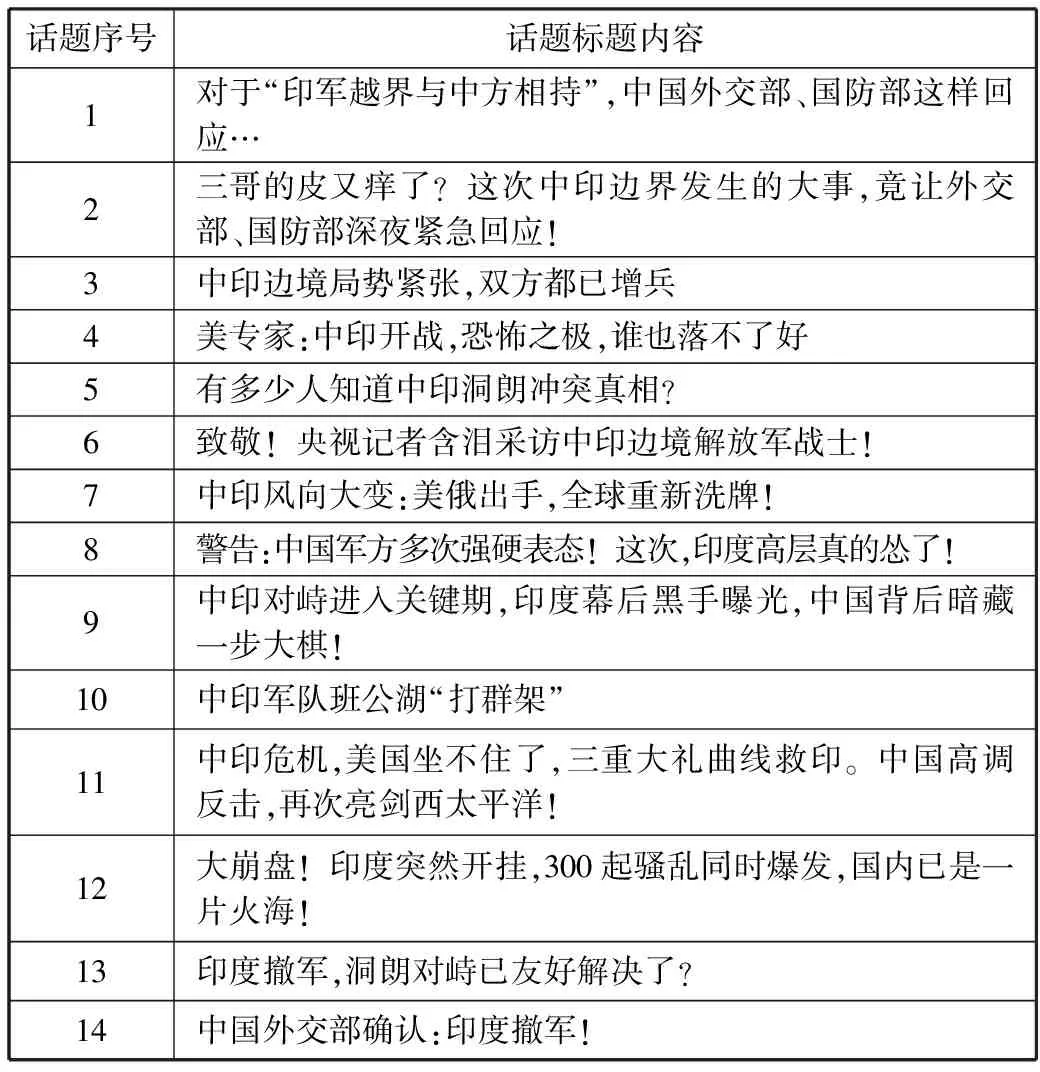
表3 热点话题的具体内容
1)结合表3和图2可知,事件发生初期的话题数量较少,但随着事件的发展,话题数量成倍增长,话题内容角度增多。
2)结合表3和图2可知,话题3是事件爆发前期出现,由各公众号陆续发布,持续时间最长的话题。形成该传播趋势的主要原因是相对于其他尖锐话题,该话题初期未被引起。
3)结合表3和图2可知,话题8是整个事件发展的制高点。形成该传播趋势的主要原因与中方多次强硬表态导致对峙局面濒临失衡,引发国民高度关注有密切关联关系,符合事件高涨期的传播趋势。
4)从图3可知,事件发生初期的传播节点多数集中在军政和新闻网站类的公众号;随着事件的发展,话题传播节点逐渐涉及生活和社会类的公众号。此时的军政类公众号作为话题传播的关键节点贯穿始终,如:全球军事网、环球军政秘闻、军政热点等。
5)结合表3和图3可知,由于话题角度的不同,不同类型的公众号关注的侧重点也不同。例如:话题5是关于真相分析的话题,其涉及的公众号大多是揭秘分析类。
4.6 对比实验及分析
实验选取文献[11]的OLDA算法做对比。实验结果如表4所示。
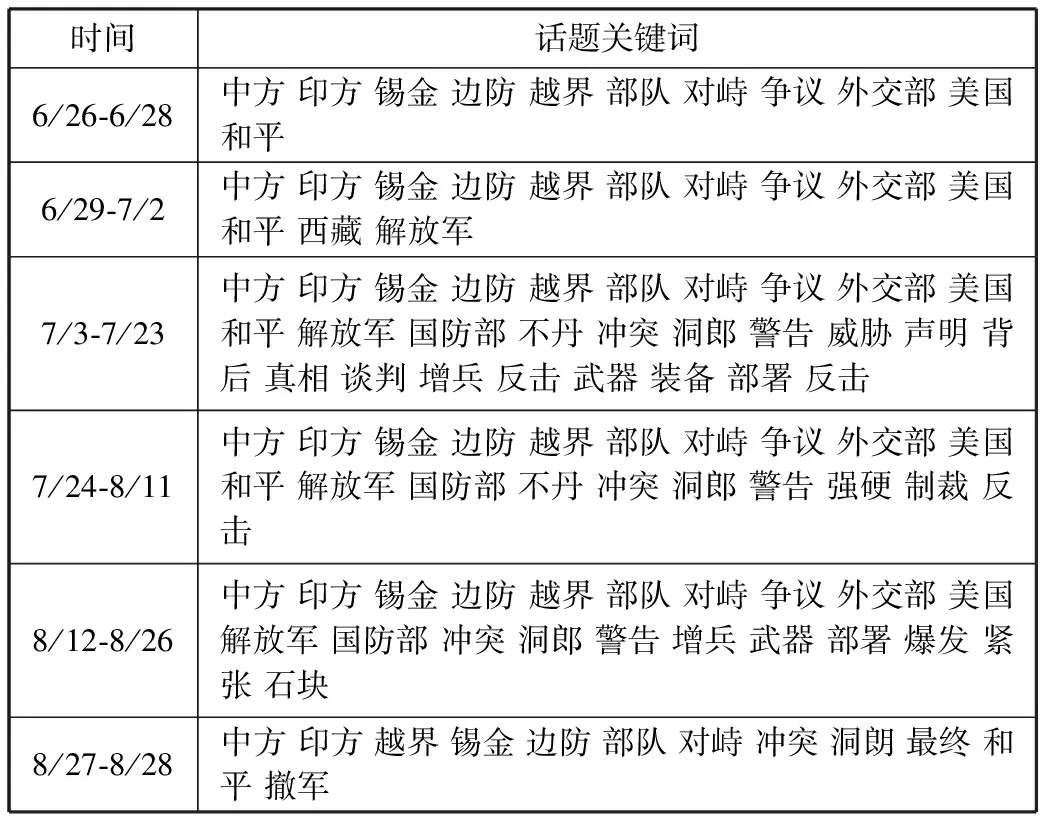
表4 各时间片OLDA算法的结果
比较表2和表4可以看出,2种方法得到的话题关键词集合基本一致,但本文提出的方法获得的话题关键词集合更丰富,内容更具体。如:7/3-7/23阶段“挑衅 持续 爆发 阻止 活动 作战”等关键词,7/24-8/11阶段“背后 真相 驱逐 长期 骚乱 挑衅”等关键词,8/12-8/26阶段“示威 游行 升级 矛盾 战机 海军 大规模 作战 联合 军演 反击 博弈”等关键词。由此可知,本文方法能够更全面完整地挖掘出与事件发展相关的关键词,以及发现更多与事件相关的细节,从而更准确有效地跟踪热点事件多个话题的动态演化趋势。
5 结束语
本文结合时序信息应用关联规则算法得到热点事件的多个话题的关键词集合,从而跟踪热点事件的演化和传播路径,通过实验与其他方法的比较,表明了该方法在时序分析方面的有效性。
本文从内容和强度上分析热点事件的演化和传播路径,未来研究工作将考虑民众的情感倾向对事件发展的影响,增强对事件的情感分析。
猜你喜欢
加油站服务指南(2022年6期)2022-07-28
新世纪智能(数学备考)(2021年9期)2021-11-24
制造技术与机床(2019年9期)2019-09-10
当代陕西(2019年15期)2019-09-02
车迷(2019年10期)2019-06-24
成都信息工程大学学报(2019年5期)2019-05-21
西南交通大学学报(2018年6期)2018-12-18
快乐语文(2018年7期)2018-05-25
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
