
基于高校官网的校情简介数据分析方法
2018-09-06 01:28王松松高伟勋
计算机与现代化 2018年8期
王松松,高伟勋
(上海师范大学信息与机电工程学院,上海 200234)
0 引 言
在高等教育大众化、国际化、信息化的不断发展过程中,高校在教育管理、人才管理等方面都面临着巨大的挑战。为了促进高校的发展,更好地进行高校的管理工作,教育部组织了高校本科评估工作,构建了评估指标体系来对高校的建设和发展进行评估。
在评估指标体系[1]的建设中,主要有武书连、校友会、网大和武大4个指标体系。4个指标体系都以多级指标为研究方式,通过对高校结构化数据进行统计,与评估指标相对应,从而实现高校评估指标下的高校评估建设。数据挖掘技术的发展为高校评估分析带来了新的研究方式,它不仅可以对高校结构化数据进行分析,同时也能够对高校的非结构化数据进行挖掘分析,实现评估分析的持续性和完整性。
高校官网是高校在发展过程中展示自身发展状况的重要平台,在高校官网中,概况信息和新闻信息占据重要的地位。概况信息是高校的整体介绍,包括发展历史、师资队伍、学生情况、学科建设以及科研成果等诸多成就。新闻信息是高校发展过程中的重要信息,是高校发展过程中具有重要意义的新闻事件,对高校的评估研究具有重要的作用。对高校官网信息进行挖掘,通过数据爬虫技术自动获取高校官网数据中的文本信息,使用文本挖掘技术对高校官网信息进行挖掘分析,实现高校评估过程中的数据自动化处理。这种评估方式通过数据挖掘技术获取大量的数据,受时间和空间的限制。
1 相关工作介绍
数据挖掘技术在对高校的研究有广泛的应用,主要包括教学培养、教师队伍建设、教育资源分配、图书馆管理和校园管理建设等方面。
任高举等[2]面对高校数据规模较大、更新速度较快、复杂度较高等特点,使用数据挖掘算法对高校数据进行了特征挖掘和提取,提出了一种基于多元特征数据挖掘和嵌入式Linux内核的高校管理信息系统设计方法。许丽卿[3]在处理高校教学、管理工作中出现的问题时,提出使用数据挖掘的方法来进行高校教学质量评估,使用改进的Apriori建立教学质量评估模型,对教学中的信息进行分析,实现教学质量的评估。李景奇等[4]在对高校知识管理进行分析时,面对数据集成困难、成果难以应用、知识难以管理等问题,结合知识管理与软件工程方法,设计了基于数据挖掘的高校知识管理系统,对数据集成方法和挖掘技术进行了设计,实现了高校大数据的应用。叶莉等[5]在分析了传统信息服务所面临的挑战后,提出将数据挖掘技术应用到高校图书馆信息服务中,探讨了高校图书馆的信息服务、阅读推广、个性化服务以及一站式信息资源共享等手段,推进了高校图书馆信息服务的发展。
本文分析数据挖掘方法在高校中的不同应用,提出使用短语相似度计算方法对高校官网校情简介数据进行分析。在短语相似度计算方法的研究中,闫红等[6]提出一种基于HowNet的计算短语相似度的方法,通过知网来计算词语的相似度,并进行词语的消歧,实现短语的相似度计算。田堃等[7]基于已标注好语义角色的语料资源,以动词为分析核心,通过语义标注、相似度匹配来实现短语语义的相似度计算。李峰等[8]使用Word2vec来训练词向量模型,考虑重叠词的词语数量和词语顺序,运用词向量模型计算相似度,实现短语相似度的计算。李晓等[9]利用Word2vec模型将对短语的处理简化为向量空间中的向量运算,利用向量空间的相似度实现短语的相似度计算。
本文通过对比分析不同的短语相似度计算方法,将SimHash算法与短语结构相结合,提出基于树形结构与CilinSimHash算法相结合的短语相似度计算方法。将短语相似度算法应用到高校官网校情简介数据处理中,对高校官网数据进行聚类分析,并与高校评估指标数据进行对比分析,提取出与高校评估指标体系中的指标相对应的结构化数据,从数据分析的角度对数据进行分析,实现了高校官网评估指标数据的自动化处理。
1.1 局部敏感哈希
局部敏感哈希(LSH)最早是由Indyk等[10]提出的,用来解决高维空间最近邻搜索问题,其搜索的时间复杂度低于线性复杂度。
LSH算法就是将高维空间的数据通过相同的映射,使得在映射前后,相似度较大的数据映射到同一个桶内的概率较大,而不相似的2个数据映射到同一个桶内的概率较小。也就是在对高维数据进行哈希映射之后,所得到的哈希表中,越相似的数据距离越近,而差异越大的数据,距离越远。
在LSH的计算中,设2个数据点为x、y,d(x,y)为2个数据点之间的距离,在这个过程中使用多次哈希处理,哈希函数f构成的函数簇f(d1、d2、p1、p2),对于每一个函数f而言,满足以下2个条件:
(1)若d(x,y)≤d1,则f(x)=f(y)的概率至少为p1;
(2)若d(x,y)≥d2,则f(x)=f(y)的概率至少为p2。
在词语相似度的计算中,使用LSH算法对词语进行降维,不仅能保持词语的特性不变,而且在计算词语相似度时还可以提高计算效率和精度。
1.2 同义词词林
《同义词词林》[11]是1983年梅家驹等人编著而成,将同义词、相似词以及相关词都按照类别进行整理,形成一套系统的中文词典。哈工大研究学者在同义词词林的基础上更新了现在常用的一些词语,同时剔除了部分罕见的词语,编著成《同义词词林(扩展版)》,这套词典在中文文本处理过程中起到了重要的作用。在《同义词词林(扩展版)》中,共包括17817组同义词,每一组同义词都由一个词林编码构成,其中包括77492个词语,一词多义词语8860个。
词林的结构是按照树形结构[12]来组织的,共有5层结构。在词林树形结构中,随着层数的增加,词语类别划分越来越细。在词林编码中,每一层都对应着词林的编码,第一层使用大写字母来表示,第二层使用小写字母来表示,第三层使用2位十进制来表示,第四层使用大写字母来表示,第五层使用2位十进制来表示。同时在词林中,使用“=”来表示词义相等的词语,“@”表示既无同义词,也没有相关词的词语,“#”表示相关词语,但是词义不相同。例如:“Aa01C02= 人丛 人群 人海 人流 人潮”,“Aa01C02=”是同义词的词林编码,“人丛 人群 人海 人流 人潮”就是词林编码所对应的同义词词组。
1.3 基于同义词词林的词语相似度算法介绍
本文在短语相似度计算的过程中,使用结合路径与词林编码的词语相似度计算方法[13]来计算词语相似度,该方法将词语的词林编码与词林的路径结构相结合,并使用LSH算法来进行转换,实现了2个词语之间的相似度计算,对于2个词语w1、w2,其相似度计算如式(1)~式(3):
Hamming(w1,w2)=LSH(code(w1))[i]⊕
LSH(code(w2))[i]
(1)
(2)
Sim(w1,w2)=Norm(PathHamming(w1,w2))
(3)
其中,LSH(code(w1))和LSH(code(w2))表示词语编码的LSH处理,LSH(code(w1))[i]⊕LSH(code(w2))[i]表示按位计算海明距离,weight([i/8]+1)表示按位增加路径权重,i表示编码的位数,Norm表示对海明距离计算结果进行归一化处理,Sim(w1,w2)表示词语w1和w2之间的相似度。
2 短语相似度计算方法
2.1 数据来源
以985、211和普通高校3类不同层次的高校简介为研究对象,本文收集了全国各个高校2017年以来最新的高校官网校情简介数据共1062条。数据内容包括在校生人数、本科生人数和研究生人数等27个维度。首先从简介数据中获取相对应的数据,其次通过构建数据提取模型提取数据,为了更好地进行高校对比,使用数据挖掘的方法对提取的数据进行数据分析,从而研究不同层次高校在高校发展中所具有的特点。
2.2 数据预处理
对高校官网校情简介数据进行分析,将简介数据按短语划分,以提高数据提取的方便性。将逗号、分号、句号和冒号等全部转换成逗号,以逗号分隔符作为短语的分割标准,对简介数据进行划分。使用正则表达式对短语中的量词进行匹配,通过增加、删除和替换逗号来对短语进行分割,保证每个短语中只有一个量词存在,同时对应修饰词。
以重庆大学为例,对简介数据进行数据预处理。表1为预处理后的部分结果,仅保留带有结构化数据的短语作为研究对象。
2.3 基于树形结构与CilinSimHash算法的短语相似度算法
短语相似度[14]计算在文本处理中占有非常重要的地位,在各个领域的应用非常广泛。在已有研究中,主要使用的是向量空间模型(VSM)[15],运用余项系数法来实现短语相似度的计算。VSM使用TFIDF[16]计算特征权重,具有非常好的效果,VSM的缺点是通过短语中词语的出现次数和短语间相同词语的出现概率进行相似度计算,并未考虑短语的语义问题、短语中特征词的位置问题等。
2.3.1 基于树形结构的短语相似度计算方法
高校官网数据中包含有关键的数据,对于官网数据的挖掘,主要是高校评估指标体系所对应的数据。对高校官网数据进行预处理,将文本全部转换成短语,构建短语的树形结构,以实现短语的相似度计算。
短语结构树和依存结构树[17]是自然语言中2大树库建立方式。短语结构树对短语构建层次结构,使用二叉树的形式表示。依存结构树在短语结构树的基础上,对短语中词语之间的关系进行分析,从词性、词语搭配等角度建立树形结构,在自然语言的结构化研究中占据重要的地位。本文在对短语结构树和依存结构树进行分析的基础上,仅从短语结构的角度来建立树,构建以数词为根节点的树形结构,在对短语结构相似度的研究上更具一般性。
对于一个短语,首先对其分词,去除停用词,然后将短语中的词语对应到树形结构中,以短语中的数词为树的根节点,数词左右两边的词语依此排列在树形结构的左右子树中。例如:ESI国际学科前1%、4个国家重点一级学科、医学技术等9个专业为重庆市特色专业,分别用树形结构来表示,如图1所示。
基于短语的树形结构是从短语的结构方面来计算2个短语的相似度。将树形结构转换成数值表示,如图2所示。

图2 短语树形结构标注
图2中,根节点的数字使用0来标注,左子树按照距离根节点的距离依次减小标注,距离根节点越近,标注值越大;右子树按照距离根节点的距离依次增大标注,距离根节点越近,标注值越小。
使用短语的树形结构来计算2个短语之间的相似度,2棵树中相同词语越多,树的结构越相似,2个短语相似度越高,短语相似度计算如式(4):
Sim(s1,s2)=
(4)
其中,s1和s2为2个短语,w1和w2为树形结构中任意2个词语,Sim(w1,w2)为2个词语使用式(3)计算的相似度,Sim(s1,s2)为2个短语之间的相似度。
树形结构相似度算法描述:
输入:任意2个短语s1、s2
输出:2个短语之间的相似度Sim(s1,s2)
1)对2个短语进行预处理,使用中科院分词器PYNLPIR对短语进行分词,并去除停用词。
2)选择带有数字的短语,这些数字主要是高校的指标数据。以数字作为树形结构的根节点,其余词语按照短语中词语的排列顺序,分别对应到树形结构的左右子树中,将短语使用树形结构来表示。
3)对树形结构进行数据化,根节点使用0来表示,分别计算节点到根节点的距离,将树的节点按照距离使用数字来表示,形成数值二叉树。
4)使用短语相似度方法计算2个短语的相似度。
2.3.2 基于CilinSimHash的短语相似度计算方法
SimHash算法[18]是LSH算法的一种,将每一个短语生成唯一的一个指纹码,相同的短语其指纹码也是相同的。对于短语而言,首先是提取特征,将每一个特征词都转换成一个固定长度为64 bit的二进制签名,二进制签名所对应的向量就是特征向量,依据特征向量的值将特征权重进行二进制加权,并进行加法运算,最后将特征权重加权运算的结果转换成新的二进制签名,实现CilinSimHash算法在短语上的应用,CilinSimHash算法定义如式(5)、式(6):
Hamming(s1,s2)=SimHash(s1)⊕SimHash(s2)
(5)
(6)
其中,SimHash(s1)和SimHash(s2)表示使用SimHash算法对短语进行处理,maxHamming=64表示2个短语完全不相同时的最大海明距离。
CilinSimHash算法描述:
输入:任意2个短语s1、s2
输出:2个短语之间的相似度Sim(s1,s2)
1)对2个短语进行预处理。
2)将短语中的各个词语与同义词词林中词语相对应,使用词林编码替换词语,使得所有词语全部使用编码进行替换,获取特征编码。
3)将特征词的特征编码通过Hash算法转换成64 bit的二进制指纹签名。
4)将特征编码的二进制的各位指纹值与特征权重相对应,如果第i位指纹值为1,则指纹值的第i位为正权重,如果第i位指纹值为-1,则指纹值的第i位为负权重。
5)将所有指纹权重值的对应位进行求和运算,获得特征加权运算向量。
6)对特征加权运算向量进行指纹替换,若第i位数值为正,则新的指纹值的第i位为1,如果第i位数值为负,则新的指纹值的第i位为0。
7)对不同指纹值进行海明距离运算,归一化处理后的结果就是不同短语间的相似度。
2.3.3 短语相似度计算
短语相似度的计算公式如下:
Sim(s1,s2)=αSim1(s1,s2)+(1-α)Sim2(s1,s2)
(7)
式(7)中,Sim1(s1,s2)表示CilinSimHash算法下的短语相似度计算结果,Sim2(s1,s2)表示树形结构算法下的短语相似度计算结果,其中α=0.62。
本文在短语相似度算法的计算中,分别从短语结构和词语语义的角度进行分析,从短语结构的角度使用树形结构来计算短语相似度,从词语语义的角度引入同义词词林相似度计算方法,实现短语语义的分析,将短语结构与词语语义进行加权来提高短语相似度计算的准确性和完整性。
2.3.4 实验对比分析
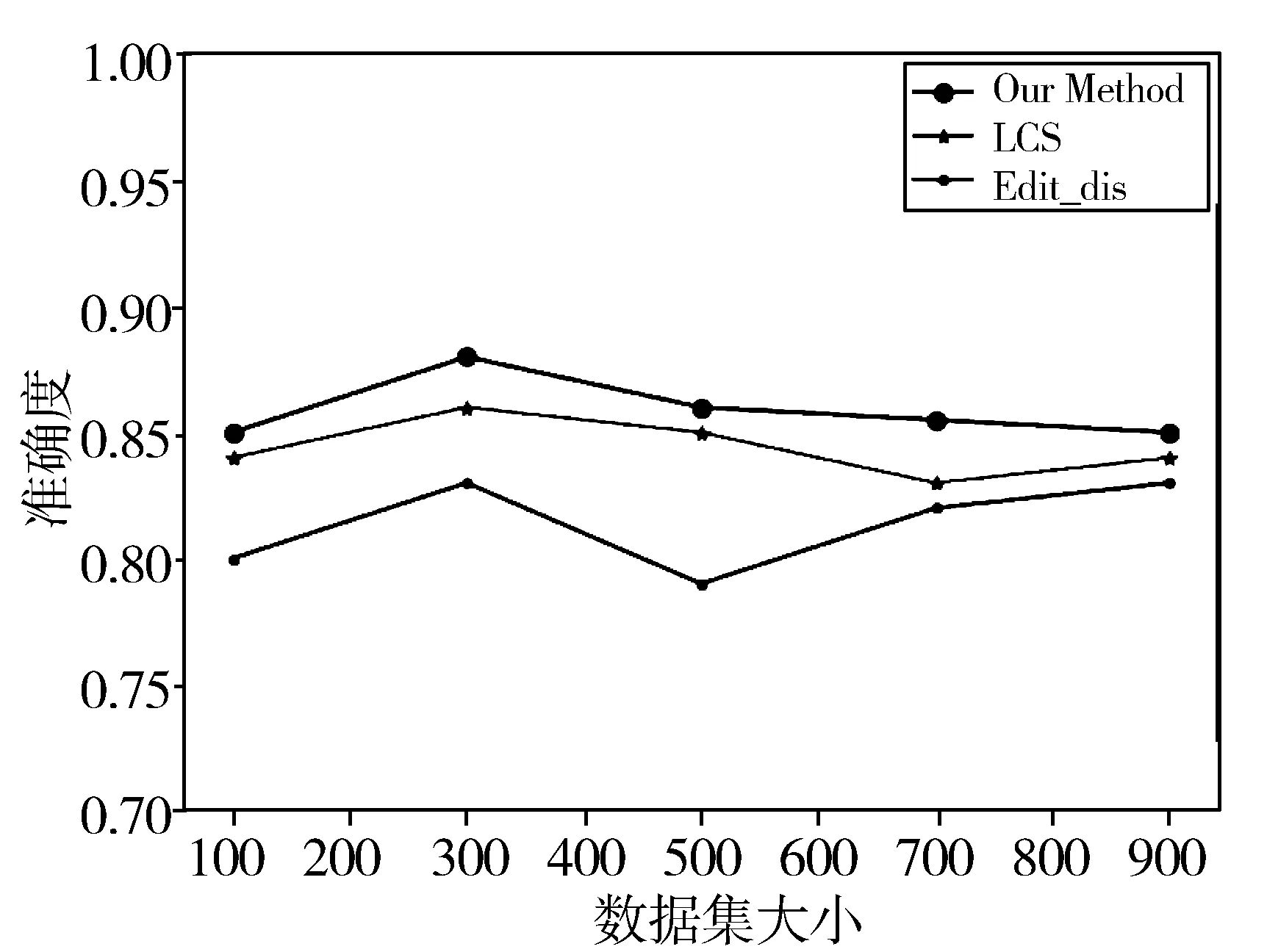
图3 实验对比分析结果
实验采用对比的方法验证算法的有效性和准确性,采用高校官网的数据对实验进行验证,将高校官网数据中的短语提取出来作为实验数据。分别使用基于编辑距离(Edit_dis)的短语相似度计算方法、基于最长公共子串(LCS)的短语相似度计算方法和本文的短语相似度计算方法(Our Method)进行实验,实验结果如图3所示。
LCS是通过比较2个短语中相同短语的长度来进行相似度的计算,Edit_dis是将一个短语转换成另一个短语需要进行的操作次数,不管是LCS还是Edit_dis,都仅仅从短语的结构上进行比较,并未考虑短语的语义问题,而本文方法对短语语义作了进一步的分析,提高了短语相似度的准确度。
图3的实验结果表明,本文的算法在准确度上比其他2种算法要高。
2.4 基于短语相似度计算的聚类分析
在短语相似度的计算中,本文使用基于短语树形结构和CilinSimHash算法相结合的方法来实现短语相似度计算。对高校官网校情简介数据进行分析,对高校简介数据进行句子划分,在数据特征中使用聚类分析的方法对数据进行聚类分析,能够更清晰地展现高校特点的数据。聚类算法分析步骤如图4所示。

图4 聚类算法分析
聚类算法的实现过程:
输入:高校简介数据集
输出:聚类分析结果,n个类别
1)给定高校简介数据集,进行分句预处理,设定聚类数据为n个,并在高校简介数据集中随机选择n个短语作为聚类中心。
2)计算数据集中除了选取的n个初始聚类中心以外的所有数据对象与n个初始聚类中心的相似度,使用基于树形结构和CilinSimHash算法的短语相似度算法作为计算方式,将与聚类中心相似度较大的短语划分到聚类中心类别中。
3)依次分配完所有数据对象,根据每一类别中的数据对象,重新调整聚类中心。
4)对连续2次划分得到的聚类中心进行比较,若聚类中心改变,则执行步骤3,否则执行步骤5。
5)输出最终聚类中心所对应的数据对象。
3 高校官网数据分析
3.1 高校官网数据聚类结果分析
对高校官网数据进行聚类分析,将聚类分析结果与高校评价指标[19]进行对比,分析高校官网数据所具有的特点。高校评价指标如表2所示,高校指标体系主要由三级指标构成,其中一级指标从高校的办学宗旨来划分,分为办学资源、教学水平、科学研究和学校声誉,二级指标从高校发展分类来划分,分为基本条件、教育经费、教师队伍和优势学科等11个类别,三级指标是高校分类指标的细化,按照高校的各项工作来进行划分。对高校官网数据进行研究,主要针对三级指标进行分析,来分析高校在不同指标下的发展状况。

表2 高校评价指标
对本文采集的1062条高校官网数据进行聚类分析,并对聚类结果进行分析,同时与高校评价指标进行对比分析,将数据总结为27类,如表3所示。

表3 高校官网数据分类
从表3中可以发现,所有类别都在高校评价指标体系中,表明高校官网数据与高校评估指标数据是非常吻合的,使用高校官网数据来对高校评估指标数据进行分析,具有非常重要的意义。
对高校指标数据进行标签云统计分析,更清晰地展现高校指标数据在高校发展过程中所起到的作用。由图5可以看出,特色、专业、国家、基地、中心、学生和人才等词语出现的频率最大,说明高校在专业发展、人才培养以及科研中心的建设上发挥着重要的作用,也体现了高校的办学宗旨。

图5 高校官网指标数据标签云
3.2 高校官网指标数据聚类分析
对高校指标数据进行聚类分析[20],因各个指标的单位是不同的,需要对数据进行归一化,使用max-min标准化来对原始数据进行线性变换,计算公式如下:
(8)
其中,max为数据中的最大值,min为数据中的最小值,在进行归一化时,是在同一个指标下进行的,来保证数据的可靠性。
表4是部分高校指标数据,分别对应高校官网数据聚类分析得到的27个类别。不同高校的概况数据是不同的,概况数据从学生、教师、科研以及成果等各个方面来展示高校的综合水平,是高校对外展示其基本情况的重要数据来源。
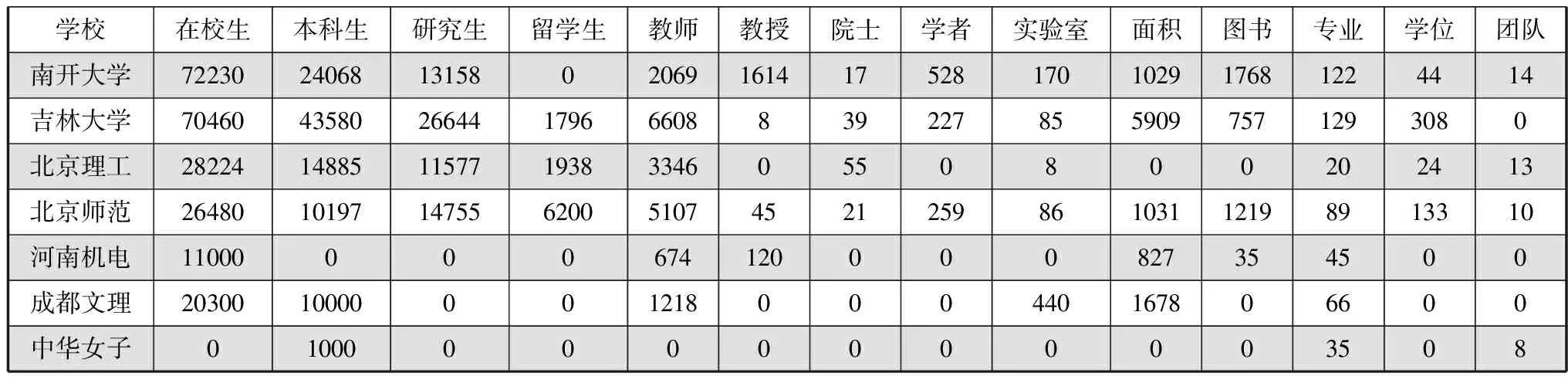
表4 高校官网指标数据
(数据来源于2017年9月的全国高校官网校情简介数据)
对高校指标数据进行聚类分析,分别从985高校、211高校和其他高校3个层次进行分析,图6为高校官网数据中,不同层次高校指标数据的聚类结果。
对图6分析可知,大多数985高校和211高校都在第一象限,表明985高校和211高校在高校的发展过程中更符合高校指标数据的标准性,第一象限以外的985和211高校是由于这些高校并未将高校指标数据体现在高校概况数据中,信息公开的发展使得部分高校会把指标数据存储到信息公开栏目,而本文并未对高校信息公开栏目的数据进行采集。
图6中同样展示了其他普通高校的指标数据情况,不管是从高校的发展情况还是从高校概况的角度来分析,大多数高校还需要进一步地发展和完善。

图6 高校官网指标数据聚类分析结果
4 结束语
本文提出了基于树形结构和CilinSimHash算法的短语相似度计算方法,首先对高校官网数据进行分析,将高校官网数据转换成短语,选择带有数字的短语作为研究对象,提出了基于短语结构的树形结构短语相似度算法。从短语语义的角度出发,将同义词词林与SimHash算法相结合,从词语相似度的角度来计算2个短语之间的相似度,提出了使用CilinSimHash算法计算短语的相似度,最后将2种方法进行加权,从短语结构和短语语义这2个角度进行相似度的计算。
将短语相似度算法应用到高校官网数据中,对官网数据进行聚类分析,实现了聚类分析结果与高校指标数据的一致性,表明高校官网数据对于高校指标数据的分析也具有重要作用。对高校官网数据进行数据提取,分别对应聚类分析类别,对类别指标数据进行聚类分析,实现了不同层次高校在高校指标体系下的发展状况研究。
高校官网数据作为高校发展的重要数据来源,对高校的发展起到重要的作用。本文主要对高校简介数据进行分析,未来还需要从高校官网信息公开和动态新闻等方面进行数据的采集。随着高校的发展,其数据也在不断更新,因此可以在不同时间段分别对高校进行评估,探索高校发展中的综合性和延展性,进一步研究高校的发展问题。
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
河北果树(2021年4期)2021-12-02
烟台果树(2021年2期)2021-07-21
小天使·一年级语数英综合(2020年4期)2020-12-16
现代园艺(2017年19期)2018-01-19
现代园艺(2017年13期)2018-01-19
海峡姐妹(2016年2期)2016-02-27
传奇故事(破茧成蝶)(2015年7期)2015-02-28
