
多粒度粗糙集数据分析研究的回顾与展望
2018-09-05 01:59吴伟志
西北大学学报(自然科学版) 2018年4期
吴伟志
(1.浙江海洋大学 数理与信息学院,浙江 舟山 316022;2.浙江省海洋大数据挖掘与应用重点实验室,浙 江 舟山 316022)
从不同的粒度(granularity)上观察、 分析与解决同一问题, 是人类智能的特点之一。 粒计算(Granular computing, GrC)是Lin在分析Zadeh的信息粒度(information granularity)[1]基础上于1997年首次提出的[2], 它模拟人类思考问题的自然模式, 以粒(granule)为基本计算单位, 以处理大规模复杂数据集和信息等建立有效的计算模型为目标。 后来, Lin[3]和Yao[4]分别对粒计算研究的一些基本问题进行了阐述。 我国张钹院士和张铃教授提出的商空间理论[5]被公认为粒计算的另一个重要模型, 该理论明确指出“在问题求解研究中, 人类智能的一个公认特点, 就是人们能从极不相同的粒度上观察和分析同一问题。” 粒计算主要研究粒的构造、 解释、 表示、 在有不同尺度或粒度空间研究粒计算问题时, 还要考虑最优尺度或粒度的选择, 以及存在于粒之间的粒IF-THEN规则的提取和相关的理论与算法等。 目前, 粒计算已成为人工智能领域和大数据处理的重要方法[6-7]。
迄今为止,已经提出了很多涉及具体应用背景的粒计算模型和方法,而在众多粒计算研究方法中,粗糙集(rough set)[8]和形式概念分析(Formal concept analysis, FCA)[9]对粒计算研究的推动和发展起着重要的作用并取得了很多重要成果[10-17]。
粗糙集数据分析和形式概念分析的数据表示形式是属性-对象值表, 分别称为信息系统和形式背景。传统的粗糙集数据分析和形式概念分析所呈现出的对象-属性值表中大都是取单一属性值的, 即对于系统中的每一个对象和所对应的每一个属性,只取唯一的一个值,这样的信息系统或形式背景反映的是固定尺度下的对象信息,我们称为单尺度信息系统(也称单粒度标记信息系统)和单尺度形式背景。 事实上,单一粒度框架下的知识表示与数据处理方法已远远不能满足实际应用的需求。例如,在对地理信息系统中的空间遥感数据(数据以某些光谱波段反射的灰度值进行标记)分析中,对于同一个地表物(观察对象),随着观测的距离或分辨率不同,地表物会呈现出具有不同层次物理意义的对象,如某一地表物根据观测距离或分辨率的不同,可能分别呈现出陆地、植被、庄稼地、玉米地等。 又比如,对于地图上我国的某一地方,根据行政区域的不同粒度层次(如村、乡、县、地级市、省自治区等级别),其所属地分别给予不同的区域标记。 总之,在多粒度标记数据模型下,同一批数据可以被标记为不同的尺度或粒度层次,人们可以根据需要在不同的尺度或粒度层面上处理和分析数据。 因而“多尺度”或者“多粒度”近几年来成为粒计算研究的重要方向。
在基于粗糙集的多粒度数据表示与分析建模研究中,我们认为应该从引起多粒度的原因着手。本文主要介绍近几年在粗糙集数据分析中的几种多粒度知识表示和数据处理模型,并对相关问题的研究进行分析和展望。
1 相关的基础知识
设U是非空论域,对于X⊆U,X在U中的补集记为~X,即~X={x∈U|x∉X}。 本节简要介绍后面要用到的一些基本概念与知识。
1.1 信息系统与近似集
定义1[8]一个信息系统是一个二元组(U,AT),其中U是一个非空有限对象集,称为论域;AT是一个非空有限属性集,对于任意的a∈AT,满足a:U→Va,即a(x)∈Va,x∈U,其中Va={a(x)|x∈U}称为a的值域。
对于一个给定的信息系统(U,AT),A⊆AT,记:
RA={(x,y)∈U×U|∀a∈A,a(x)=a(y)}
显然,RA是论域U上的等价关系,称为不可分辨关系,它能导出U上的一个划分
U/RA={[x]A|x∈U}。
其中[x]A={y∈U|(x,y)∈RA}称为对象x关于RA-等价类。
设(U,AT)是一个信息系统,A⊆AT,X⊆U,X关于RA的下近似和上近似定义如下:
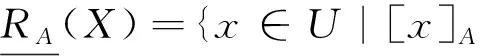
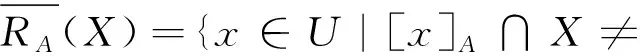
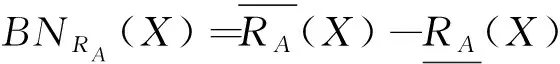
其中|X|表示集合X的基数。X关于RA的粗糙度定义如下:
ρRA(X)=1-αRA(X)。
定义2[8]一个决策表(也称为决策系统)是一个二元组S=(U,C∪{d}),其中(U,C)是信息系统,C是条件属性集,d∉C为决策属性,d:U→Vd,Vd是属性d的值域。 定义
Rd={(x,y)∈U×U|d(x)=d(y)}
U/Rd是由Rd生成的划分,它将U粒化成决策类。若RC⊆Rd,则称决策表(U,C∪{d})是协调的,否则称它是不协调的。
对于B⊆C,记
∂B(x)={d(y)|y∈[x]B},x∈U
∂B(x)称为x关于B在(U,C∪{d})中的广义决策值,∂B称为B在(U,C∪{d})中的广义决策函数。显然,(U,C∪{d})是协调的当且仅当对于任意x∈U有|∂C(x)|=1。
若信息系统(U,AT)中某些对象在某个属性的值是缺省的(其中的缺省值常用*表示),则称此信息系统是不完备信息系统,对于A⊆AT,记:
RA={(x,y)∈U×U|∀a∈A,a(x)=a(y),或a(x)=*,或a(y)=*}。
此时,RA是U上相似关系,它能导出U上的一个覆盖U/RA={SA(x)|x∈U},其中
SA(x)={y∈U|(x,y)∈RA}
称为对象x关于RA的相似类。 称决策表S=(U,C∪{d})是不完备的,若(U,C)是不完备信息系统。类似地也可以通过相似关系定义集合的下近似和上近似。
通过粗糙集属性约简方法,根据决策类关于由条件属性集导出关系的下近似和上近似,可以分别获得蕴含在决策系统中的确定性决策规则和可能性决策规则[8]。
1.2 粒计算中的基本概念和研究内容
尽管目前粒计算研究中没有统一的数学形式化的理论描述,但是有一些基本概念在粒计算研究领域中已经被普遍接受,它们是“粒”和“粒化(granulation)”。
定义3在论域中具有相同或相似性质的对象构成的集合称为一个粒,粒有时也称为信息粒。
粒是粒计算模型中的最小计算单位。在某些特定的数据分析中,粒不能再进行分解。 但是,这是一个相对的概念,在一个粒度层面上不能分解,但在更细或者更小粒度层面上还可以进行再分解。
定义4构造信息粒的过程称为粒化。
粒是粒计算知识表示和问题求解的基本计算单元,通过粒化生成由粒组成的对于论域的划分或覆盖。
信息系统中由某个属性子集导出一个对象的等价类或相似类就是粗糙集数据分析中的一个粒,每一个属性子集将论域粒化成一个划分或覆盖。
2 多粒度粗糙集数据分析模型
要研究多粒度知识表示与知识获取问题,首先要弄清楚造成多粒度的原因是什么。迄今为止,文献报道的有3种原因引起多粒度,相应地有3种粗糙集数据分析模型:
多粒化粗糙集(multi-granulation rough set)模型[18-20]:该模型是由Qian等[18]首先提出的,主要思想认为多粒度是由属性选择引起的,该模型根据信息系统中多个属性子集(论域中的多个二元关系或者多个划分或者多个覆盖)构成知识多粒度空间,由属性的并或交的选择对概念进行近似和对论域进行粒化,对应地有乐观粗糙集模型和悲观粗糙集模型。
多粒度邻域粗糙集(multi-granularity neighborhood rough set)模型[21-23]:该模型以Hu等[24]提出的邻域粗糙集模型为基础,该模型认为对象的邻域半径的大小能够引起多粒度,这个模型主要针对连续属性值的数据或者信息系统,其主要思想是根据对象邻域半径的大小来对论域进行粒化,然后选择合适的粒度进行聚类或者分类。
多尺度信息系统的粗糙集数据分析模型[25]:该模型是由Wu和Leung[25]首次提出,认为对象的属性取值可以引起多粒度,数据表示形式称为多尺度信息系统(multi-scale information system),又称为多粒度标记信息系统(multi-granular labeled information system),并将传统信息系统视作单粒度标记信息系统。 其数据处理的主要思想是根据决策目标对每一个属性选择合适的尺度构成一个新的单尺度信息系统,然后在保持相同目标约束的前提下进行属性约简和决策规则提取。
下面我们分别介绍这几种多粒度粗糙集数据分析模型,并对它们进行研究展望。
2.1 多粒化粗糙集模型
多粒化粗糙集数据分析主要思想来源于投票决策机制中,若有m个专家进行投票决策,乐观的决策是只要其中一个专家表示赞同决策就获得通过,悲观的决策是只有全部m个专家都表示赞同决策才能获得通过。 将这个思想延伸到粗糙集数据分析中分别得到乐观粗糙集和悲观粗糙集模型。
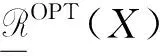


称为X关于R的乐观多粒化粗糙集的边界。X关于R的乐观多粒化粗糙集近似精度定义如下:
定义X关于R的乐观多粒化粗糙集的粗糙度为
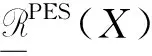
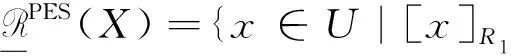

称为X关于R的悲观多粒化粗糙集的边界。X关于R的悲观多粒化粗糙集近似精度定义如下:
常爱兰知道这样的事后又将周小羽绑起来打了一顿,从那时开始,周小羽每天放学回家就上楼,然后直到他们叫他来帮忙时才下来。可是天天这样按时上楼的情况并没有让老师罢手,老师还是过个三五天就带消息来,说周小羽的作业这次又是没有完成。
定义X关于R的悲观多粒化粗糙集的粗糙度为
注1由于U上的等价关系与U上的划分是一一对应的,因此,定义5和定义6中等价关系簇R={R1,R2,…,Rm}可以被U上的m个划分来替代。相应地,x的Ri等价类[x]Ri要换成第i个划分中包含x的集合(等价类)。在具体应用上,设(U,AT)是信息系统,P1,P2,…,Pm是AT的m个属性子集簇,对于每一个属性子集可以按照1.1节的方法定义U上的一个等价关系,因此,定义5和定义6中等价关系R={R1,R2,…,Rm}也可以用属性子集簇{P1,P2,…,Pm}替代,具体见文献[18-20]。
在理论层面上,多粒化粗糙集有很多拓展模型,比如可以将等价关系推广成非等价关系得到双论域多粒化粗糙集模型等[26-28]。 将由等价关系所对应的划分拓展成覆盖,则可以得到多粒化覆盖粗糙集模型[29-31]。 更一般地,将经典二元关系拓展到模糊关系,则可以得到多粒化模糊粗糙集模型,甚至将软集或区间集与多粒化进行组合得到多粒化软粗糙集模型和多粒化区间粗糙集模型等[32-39]。另外,多粒化粗糙集模型下的多值逻辑方法也取得了重要进展[40]。将多粒化粗糙集和概念认知结合是一个很有意义的工作,并取得了一些重要进展[41-43]。
在具体应用上,各种信息系统和决策表在多粒化粗糙集模型下的粗糙近似、约简(包括系统约简和局部约简)、规则提取、代价敏感分析方面等取得了一些重要研究成果。 将完备信息系统拓展成不完备信息系统、序信息系统、模糊信息系统、区间值信息系统、形式背景等,用多粒化粗糙集方法研究这些拓展数据表中的信息粒表示、知识约简、规则提取、知识动态更新等仍是值得进一步研究的问题[44-49]。
在多粒化粗糙集模型及其应用研究中,不确定性分析及度量研究是一个重要的问题。 这方面的研究主要是针对不同的不确定性问题引入不同的度量或测度,如概率不确定性、模糊性、信息熵、证据理论中的信任度与似然度,以及包含度等[50-57]。
从本质上说,这类“多粒度”是通过多个属性选择不同的合成方式而获得的。 当然,也有人认为这种乐观和悲观的定义粗糙近似的方式过于极端,可以采取更加折中的方式定义。
2.2 多粒度邻域粗糙集模型
多粒度邻域粗糙集模型的主要思想将邻域粗糙集中的“邻域”或者“距离”动态地用多个邻域或者多个距离作为“多粒度”对论域进行粒化,根据决策或者分类任务选择合适的距离进行决策。
定义7[21-24]设(U,AT)是一个完备信息系统,对于任意x∈U和属性子集A⊆AT,x在属性子集A上邻域δA(x)定义如下:
δA(x)={y∈U|ΔA(x,y)≤δ}。
1)ΔA(x,y)≥0;
2)ΔA(x,y)=0当且仅当x=y;
3)ΔA(x,y)=ΔA(y,x);
4)ΔA(x,z)≤ΔA(x,y)+ΔA(y,z)。
需要指出的是,这里的ΔA一般是通过对象在属性子集A上取值计算得到的,比如若A={a1,a2,…,aN}⊆AT,则可以定义Minkowsky距离:
其中p≥1。当然,不同的属性上也可以选择不同类型的距离函数,在不同属性上合成U上的距离函数时也可以取加权和等。



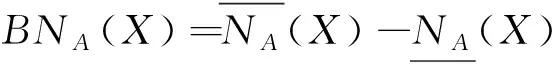
定义9[21-22]设(U,AT)是一个完备信息系统,Γ={δ1,δ2,…,δt},δk>0,k=1,2,…,t,记

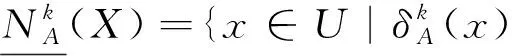

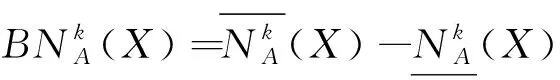
定义9将不同的邻域半径δ1,δ2,…,δt作为“粒度”定义多粒度粗糙近似集。在具体应用中,若粒度半径δ1,δ2,…,δt是事先确定的,则在决策表中如何选择合适的粒度对决策或分类的泛化最强是一个值得研究的问题。当然,若δ1,δ2,…,δt不是事先给定的,则在数据集中训练泛化能力好的粒度是一个比较重要的问题,比如,文献[21-22]将不同邻域或距离度量作为多粒度对论域进行粒化,在泛化性能优化的框架下提出了最大邻域粒间隔的粒度选择和组合方法。
多粒度邻域粗糙集数据分析可以拓展到各种复杂的信息系统与决策表中的特征选择、约简、规则提取,包括动态数据挖掘等[58-62]。 另外,在不同的属性值域中如何训练或者选择合适的距离函数也是一个值得研究的问题。在多粒度邻域粗糙集模型的应用研究中,不确定性分析及度量研究也是一个重要的问题[63],比如针对不同的不确定性问题可以引入不同的度量或测度。
多粒度邻域粗糙集模型应用限制是数据类型必须是实数值的或者可以转化为实数值的属性数据。
2.3 多尺度信息系统的粗糙集数据分析模型
在传统粗糙集数据分析的信息系统(U,AT)中,每一个对象xi在属性aj上只取一个确定的值,这是单尺度标记信息系统。 若信息系统(U,AT)中每一个对象在同一个属性上根据不同的尺度标记层面可以取不同的值,则(U,AT)是一个多尺度(标记)信息系统。 Wu和Leung在文献[25]中首次提出了多尺度信息系统的概念。
定义10[25]称(U,AT)是一个多尺度信息系统,其中U={x1,x2,…,xn}是一个非空有限对象集,称为论域,AT={a1,a2,…,am}是一个非空有限属性集,且每一个属性都是多尺度属性。
假设所有的属性都有I个相同的等级粒度,则一个多尺度信息系统可以表示为

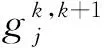

对于k∈{1,2,…,I},记

其中k=1,2,…,I。
这样的多尺度信息系统和多尺度决策系统的粗糙集数据分析模型称为Wu-Leung模型[64]。
例1[25]表1给出了一个多尺度决策系统
其中
U={x1,x2,…,x12},
C={a1,a2,a3,a4},
每个属性有3个粒度层面的标记,其中“E”,“G”,“F”,“B”,“S”,“M”,“L”,“Y”,“N”分别表示“优”、“良”、“中”、“差”、“小”、“中等”、“大”、“是”、“否”。 这样的一个系统可以分解成3个决策表,见表2~4。

表1 一个具有3个粒度层面标记的多尺度决策系统Tab.1 A multi-scale decision system with three levels of granulation

表2 表1的第一个粒度层面标记下的决策表Tab.2 The decision table with the first level of granulation of Table 1

表3 表1的第二个粒度层面标记下的决策表Tab.3 The decision table with the second level of granulation of Table 1

表4 表1的第三个粒度层面标记下的决策表Tab.4 The decision table with the third level of granulation of Table 1
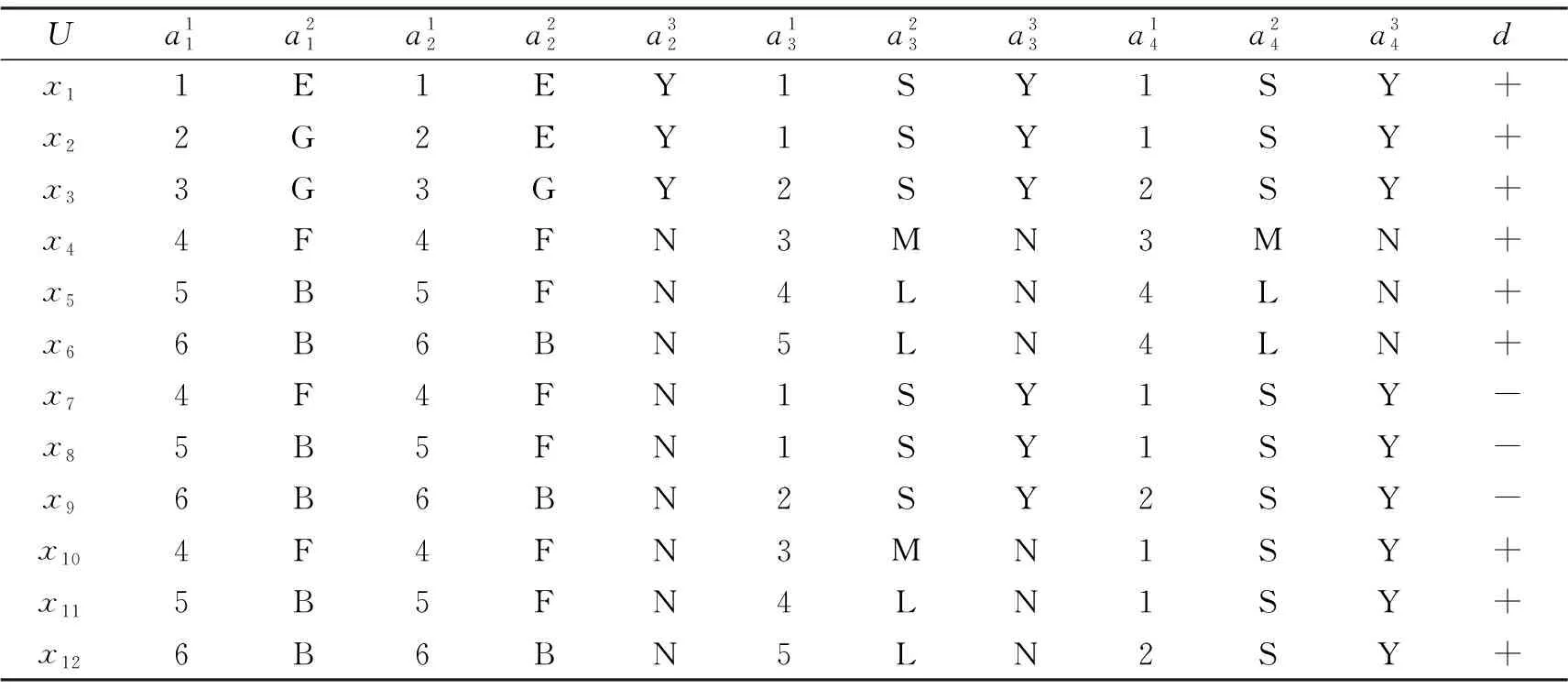
表5 一个广义多尺度决策系统Tab.5 A generalized multi-scale decision system
在Wu-Leung模型中,相当于将决策系统的条件部分看成I个尺度,在保持某种性质(可以是定性的也可以是定量的)一致的意义下选择最粗的尺度标记(也称为最优尺度选择)成为在多尺度决策系统中提取决策规则前的一个关键问题[25, 65-69]。 当然,这样得到的最优尺度我们称为系统的最优尺度(它们对应一个决策表),但是在实际问题中,有时为了获得某一个对象所对应的泛化能力强的决策规则时,则只须计算关于决策在保持某种性质(可以是定性的也可以是定量的)一致意义下的选择最粗尺度标记即可,此时获得的最优尺度称为该对象的局部最优尺度[70-71]。Wu等人研究了在多粒度标记框架下的其他数据类型的信息粒度表示和最优粒度的选择问题,包括不完备多尺度信息系统、不完备序信息系统等[72-74]。 Gu和Wu[75-77]还给出了协调的和不协调的多尺度标记决策系统中知识获取的算法。
由于以上多粒度标记信息系统都有一个共同的假设,即系统中所有的属性都具有相同的粒度标记个数,而实际生活中人们可能面对不同的属性具有不同的粒度标记个数的数据处理问题。针对这种情形,Li和Hu在文献[64]和文献[78]中提出了一种推广的多粒度标记数据分析模型(有时称为广义多尺度信息系统)。
定义12[64]称(U,AT)是一个广义多尺度信息系统,其中U={x1,x2,…,xn}是一个非空有限对象集,称为论域,AT={a1,a2,…,am}是一个非空有限属性集,且每一个属性都是多尺度属性。假设属性aj有Ij个等级粒度,则一个多尺度信息系统可以表示为:

例2表5(是表1将第4列删除得到的)给出了一个多尺度决策系统
其中
U={x1,x2,…,x12},
C={a1,a2,a3,a4},
其中a1有2个粒度层面的标记,其余属性有3个粒度层面的标记。
对于这样的一个多尺度决策系统,显然不能用例1的方法简单地将它分解成3个粒度层面的子表(a1只有2个粒度层面的标记),针对这样的系统,Li和Hu在文献[64]中引入尺度组合的概念用于解决多尺度决策系统的尺度选择问题。
定义14[64]对于广义多尺度信息系统(U,AT),若属性aj∈AT,取第lj个尺度标记(1≤lj≤Ij),j=1,2,…,m,并记K=(l1,l2,…,lm),则称K=(l1,l2,…,lm)为系统S=(U,AT)的一个尺度组合,记(U,AT)的尺度组合全体为L。

对于A⊆AT和K=(l1,l2,…,lm)∈L,记K在属性子集A上的限制为KA,定义
RAK={(x,y)∈U×U|∀al∈AKA,al(x)=al(y)},
则RAK是多尺度信息系统S在尺度组合K=(l1,l2,…,lm)下由属性集A导出的一个等价关系,特别地,对于a∈AT,记RaK=R{a}K。记
[x]AK={y∈U|(x,y)∈RAK},x∈U。
[x]AK称为对象x关于AK的等价类。记
U/RAK={[x]AK|x∈U},
则U/RAK={[x]AK|x∈U}构成了U的一个划分。
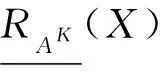
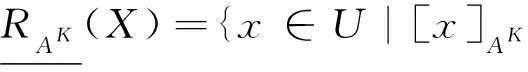
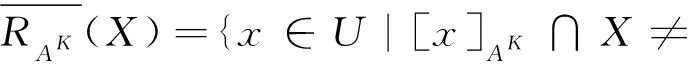

类似于单尺度决策系统有各种各样意义下的属性约简问题,探索多尺度决策系统在不同物理意义下的最优尺度组合选择(包括系统最优尺度组合选择和局部最优尺度组合选择)是多尺度决策系统中知识表示和知识获取的重要问题。当然,各种复杂数据类型在不同粒度或尺度下的决策规则提取、不确定性分析及其算法等仍是值得进一步研究的问题。
3 结 语
粒计算是大数据分析与知识发现的一个重要工具,近几年来,多粒度成为粒计算研究的一个重要方向。本文从形成多粒度的原因出发,对多粒化粗糙集模型、多粒度邻域粗糙集模型、多尺度信息系统的粗糙集数据分析模型等目前相对而言比较流行的3种多粒度粗糙集数据分析模型研究进行了回顾,并对这些模型进一步进行理论与应用研究作了初步探讨。 需要指出的是,本文只是对一些重要出版机构中的文献进行了有选择地讨论,未对所提炼的方向与问题展开详细论述,希望能对相关研究领域给出一些基本轮廓,
当然,引起多粒度的原因并非只有这3种形式,比如,在全国、省自治区、地区(地级市)、县、乡镇等不同级别的道路交通地图中,从粗粒度到细粒度的道路图变换显示中会有不断地“增加”一些级别比较低的道路,而从细粒度到粗粒度的道路图变换显示中又会不断地“删除”一些级别比较低的道路。 因此,与“并”和“交”模式不同,“增加”与“删除”是另外一种引起多粒度的原因。 针对类似数据形式如何建立多粒度计算模型是值得考虑的问题。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
农业工程学报(2022年7期)2022-07-09
粉末冶金技术(2021年3期)2021-07-28
科教导刊·电子版(2021年6期)2021-05-06
小型微型计算机系统(2020年10期)2020-10-21
自动化学报(2018年7期)2018-08-20
自动化学报(2017年4期)2017-06-15
浙江大学学报(工学版)(2016年11期)2016-06-05
现代计算机(2016年17期)2016-02-28
中国煤层气(2015年3期)2015-08-22
