
知识与数据双向驱动的多粒度认知计算
2018-09-05 01:22王国胤
西北大学学报(自然科学版) 2018年4期
王国胤,李 帅,杨 洁
(重庆邮电大学 计算智能重庆市重点实验室, 重庆 400065)
信息技术的迅猛发展开启了人类通往信息时代的大门,人类进入了大数据时代,并正在向智能时代迈进。随着信息技术的发展以及各个领域的数字化和信息化推进,每天都在不同的领域产生大量的数据,如医院、工厂、矿山、政府机构、学校、社交网站、电子商务等[1]。据估计,人类从发明文字到公元2006年之间共积累了180 EB(1EB等于10亿GB)的数据,另据互联网数据中心(IDC)估计,2011年全球数据总量已经达到0.7ZB(1ZB等于1万亿GB),2015年全球数据总量达到8.6ZB,目前全球数据的增长速度在每年40%左右,预计到2020年全球的数据总量将达到40ZB[2-4]。数据的爆炸式增长潜藏着重大的科学价值和巨大的经济利益[5]:一方面,对大数据的分析处理可以促进人类对自然世界的认识;另一方面,对大数据的挖掘利用可以转化为经济价值的来源。例如,智能交通系统中,使用先进的智能技术对地面交通网络进行实时、准确、高效的综合运输管理;医疗诊断中,建立包括患者过敏史、用药史、家族病史和基因在内的医疗大数据档案,为医生诊断提供详细的参考,帮助医生开具准确的处方;金融领域中,大数据的分析和挖掘能够帮助投资者获取新的市场机遇和预测。此外,跨行业、多领域的大数据关联分析与挖掘产生的价值更加显著,显示出了大数据强大的生命力。对大数据进行充分的挖掘与分析已经成为各国政府、金融界和学界关注的焦点:早在2007年,美国国家航空航天局(NASA)就在向美国能源部和美国国家科学基金会的建议中提到,在大规模跨领域、异构数据中有巨大的机会发现新知识,并能提供有效的新方法帮助判断和决策[6]。2012年,世界经济论坛将数据列为了与货币和黄金同等重要的一种新经济资产[7]。2016年,美国政府启动了联邦大数据研究和发展战略计划,旨在开发大数据技术,开展大数据应用,并培养下一代大数据科学家[8]。近年来,我国也逐渐加大对该领域的研究投入。2017年,国务院发布《新一代人工智能发展规划》,要求以加快人工智能与经济、社会、国防为主线,以提升新一代人工智能科技创新能力为主攻方向,构建开放协同的人工智能科技创新体系,把握人工智能技术属性和社会属性高度融合的特征,坚持人工智能研发攻关、产品应用和产业培育“三位一体”推进,全面支撑科技、经济、社会发展和国家安全[9]。随后,工信部发布《促进新一代人工智能产业发展三年行动计划(2018—2020年)》,从推动产业发展的角度,结合“中国制造2025”,以信息技术与制造技术深度融合为主线,推动新一代人工智能技术的产业化与集成应用,发展高端智能产品,夯实核心基础,提升智能制造水平,完善公共支撑体系[10]。
人工智能有三大学派:符号主义、联结主义和行为主义。人工智能诞生之初,符号主义方法以专家知识驱动,模拟人类逻辑推演,在定理证明、国际象棋等复杂的智能活动中展现了巨大优势,但由于对专家知识的过分依赖,符号主义往往只能解决特定问题,泛化能力弱,在人工智能中的主导地位逐渐被联结主义所取代。特别是进入大数据时代,随着计算能力的飞速提升,以深度学习为代表的联结主义方法广泛地应用在各领域,被认为是处理大数据的最有效方法[11]。联结主义方法认为模拟人的智能要依靠仿生学,特别是要模拟人脑建立脑模型。认知科学对这一领域的发展起到了至关重要的作用,启发了许多有效的机器学习模型。从不同层次逐级认识世界是人类固有的一种认知机制[14],在认知计算中,被称为粒计算。粒度最初是物理学的一个概念,指的是实质粒子大小的平均度量。在这里,它被用来度量从不同层次结构空间中分析和处理数据的信息量[15]。作为处理的对象,粒可以是全集中任意子集、对象、聚类和元素通过可辨识性、相似性和功能性聚集而成的单元[16]。在粒计算中,所有结构化的或其诱导出的对象都称为粒[17]。而用来表示和解释问题或系统的结构称为粒结构[18]。图1表示了一个完整的粒结构,Layerk表示最细粒度层,其中的每一个点表示数据。粒计算具有广阔的应用背景,如特征选择[19]和时间序列预测[20]等。
随着数据的爆炸式增长,机器学习也面临着许多挑战[12-13]。其中,最大的问题就是如何解决大数据5V(volume,velocity,variety,value, veracity)特性导致的挑战。例如,在数据获取阶段,原始数据中就包含大量的异质数据、非结构化数据以及不确定性数据等。尤其是在处理不确定性数据方面,传统的机器学习往往认为不确定性是一个随机现象,而忽略了人类的模糊认知机制,只能挖掘到确定知识,无法对不确定知识进行概括;在处理大型数据方面,传统机器学习往往只注重对整体数据挖掘,而忽略了人类的分层认知机制,只能挖掘到底层特征,不能挖掘到对高层特征。此外,当前的机器学习研究,还没能够把不确定性这一物理世界与认知过程的基本特征作为基础问题进行深入研究,无法解决不确定性显著、数据来源和分布广泛(“独立同分布”假设不再适用)等问题。
深度学习框架提供了一个解决以上问题的新方向。首先,它通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。这种分层结构从全局上能够解释神经网络相邻层之间的关系,以提高训练效果,但不能从局部上解释每一个参数的物理意义;而在多层逻辑神经网络中,尽管局部上每一个神经元的逻辑关系都可解释,但全局上不能达到深度学习的规模。回归问题的本原,本文从粒认知计算的角度出发,融合人类智能问题求解的多粒度思维机制、人类大脑“大范围优先”的认知机制和智能控制系统中“智能计算前置”的信息处理机制,介绍一种知识与数据双向驱动的多粒度认知计算——数据驱动的粒认知计算(Data-driven granular cognitive computing,DGCC)[21-22],如图2中的三角形结构所示。它结合了人类“大范围优先”的认知机制,即“由粗到细”认知过程,和机器学习系统“由细到粗”的信息处理机制。
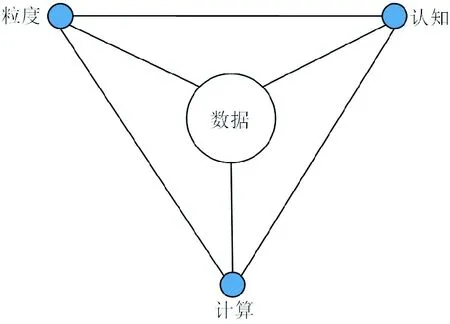
图2 DGCC的三角形结构[21-22]Fig.2 Triangular structure of DGCC[21-22]
本文组织如下:第1节介绍认知计算和粒计算的基本概念;第2节详细介绍数据驱动的粒认知计算模型(DGCC),讨论DGCC模型中需要研究的科学问题;第3节分析几个多粒度认知计算的应用案例;最后一节总结全文。
1 认知计算与粒计算
认知科学[23-24]是揭示人类智能和行为的学科,重点研究在神经系统和脑机制中,信息的表达、处理和转化。认知计算研究与人类思维方式一致的、统一的、普遍的计算方式[25],因此,认知计算可以被认为是建立在人工智能和信号处理基础之上的学科。为了处理复杂的现实世界问题,通过对一些特殊的智能现象(如思维现象、生物现象、自然现象和社会现象等)的观察,研究者开发出了许多智能计算模型和机器学习模型:模糊逻辑使得计算机能够像人类那样理解自然语言和进行逻辑推理[26];人工神经网络能够模仿人脑的机制从经验数据中学习知识[27-31];演化计算模仿自然界的选择和进化来寻找最优解[32];群体智能算法模仿生物系统通过系统内协同合作的方式寻找最优解[33];人工免疫算法模仿生物免疫机制对多峰值函数进行多峰值搜索和全局寻优[34];粒计算试图模拟人类在不同层次上对现实世界进行感知的机制[35-36]。另有一些研究者试图对人的思维模式和认知机制设计出一套统一的计算模式[25]。相较于传统系统而言,基于认知科学设计的系统能够构建知识、学习知识、理解自然语言、逻辑推理、并与人类进行更加自然地交互[37]。
随着人工智能和认知科学的不断发展,研究者们发现了人类智能的一个公认特点:在对现实世界问题的认知和处理时,人类往往采取从不同层次观察和分析问题的策略,从不同层面上观察和分析同一问题[38]。从哲学的观点上来看,人类在对任何事物进行认知、度量、形成概念和推理时,粒度思想都贯穿其中[38]。图灵奖、诺贝尔经济学奖获得者赫伯特·西蒙教授认为,自然世界和人类社会中,复杂任务通常以层次结构形式存在,即复杂任务由相互关联的子任务组成,每个子任务亦具有层次结构,直到最低层次的基本任务[39]。1997年,Zadeh教授就指出粒计算是模糊信息粒化、粗糙集理论和区间计算的超集,是粒数学的子集[40]。粗糙集等理论提供了具体的粒计算模型,将粒与认知计算中的分类、学习紧密联系起来,使得粒计算成为一种快速增长的智能计算范例[35]。粒计算通常被认为是在解决复杂问题中,所使用的粒化理论、方法、技术和工具的总称。Bargiela和Pedrycz将粒计算视为用于分析和设计人工智能系统的一个概念和算法平台[41]。Jankowski用粗糙近似对语法、语义等信息粒进行建模[42]。全集和邻域系统的层次结构能够诱导出多粒度结构。模仿人类在不同粒度层次上感受现实世界的能力,张铃和张钹提出了商空间理论,该理论能够为了满足特定问题的求解需要,对对象进行不同粒度层的抽象与转换[36]。形式概念分析能够从一组对象中自动推导出本体[43],概念格的粒结构是该理论中知识约简的重要手段[35,44]。姚一豫在上述研究成果基础上,将粒计算归纳为图3所示的相互补充、互为依赖的三角形关系[45-46]。基于定性概念和定量数据之间的关系,王国胤基于云模型提出了一种双向认知计算模型(BCC),用于表示和处理不确定概念的映射关系,将样本视为概念的外延,使用云模型的三个参数(期望、熵、超熵)来表示概念的内涵[47];徐计和王国胤提出了生成分层树的一种自适应聚类方[48]。
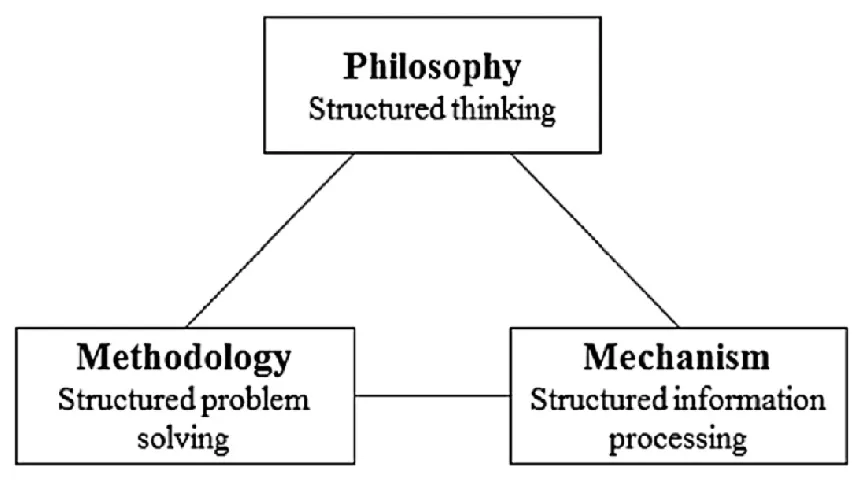
图3 粒计算的三角形结构[46]Fig.3 The granular computing triangle structure[46]
2 数据驱动的粒认知计算(DGCC)
模拟人类认知过程,使计算机具备智能处理能力,既可以依赖专家知识,使用形式化的逻辑系统进行推导,也可以从数据出发,用数学模型和算法进行计算。但人类的认知与计算机的数据计算之间不一定是完全吻合的(见图4)。因此,需要研究二者的原理与差异,融合优势,开发符合人脑认知要求(解决实际问题)的智能计算模型。
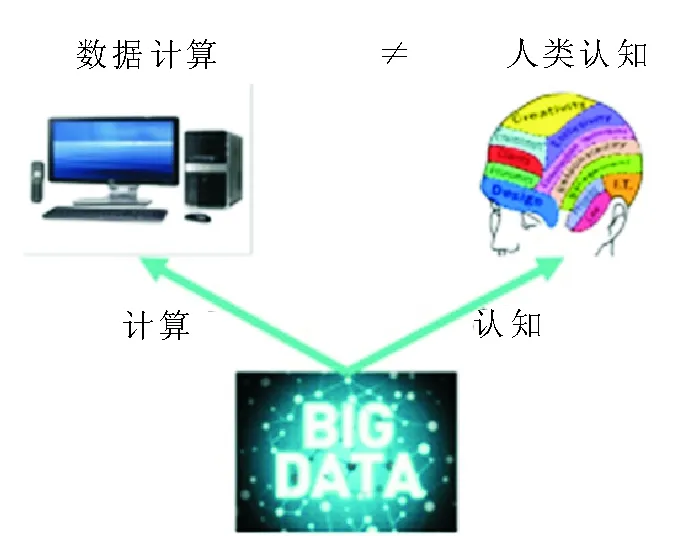
图4 计算与认知之间的不一致性Fig.4 Discordance between computing and cognition
计算机的信息处理机制与人类的粒认知机制有着巨大的不同。计算机的信息处理是以集合论、离散数学等一系列数学理论为基础的,因此经典的智能计算方法都是通过对原始数据分析和计算,提取有价值的信息,解决实际问题。如图5所示,计算机在图像识别过程中,从单个像素出发,提取图像特征,输出分类结果。从粒计算的角度来看,像素(数据)是最细粒度的,而特征(知识)是粗粒度的。传统的机器学习、数据挖掘和知识发现模型都是一个“从细粒度到粗粒度(由细到粗)”的数据、信息和知识的转变过程,存在语义代沟的缺陷。如:Olshausen使用一种稀疏编码网络模拟人脑视觉感受野V1层对人脸图片的简单特征提取。深度神经网络通过使用更复杂的网络结构和更多的连接层数解决更复杂的问题,能够学习到更高层的特征[49-51]。2015年,Google公司推出的FaceNet,通过直接学习图像到欧式空间中点的映射,进行人脸识别、人脸验证和人脸聚类,识别率高达99.63%[52]。虽然深度学习取得的效果很明显,但是其花费的代价非常高。
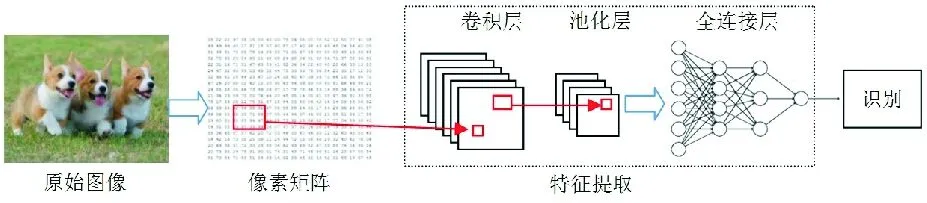
图5 计算机“由细到粗”的信息处理机制Fig.5 Information process mechanism of computer: from finer granularity levels to coarser levels
中国科学院生物物理研究所陈霖院士等通过实验研究发现,人类认知具有“大范围优先”的规律,视觉系统对全局拓扑特性尤为敏感[53]。“大范围优先”的人类认知规律,是一个“从粗粒度到细粒度(由粗到细)”的变换过程。如图6,人类可以通过寥寥数笔的漫画来认出一个动物。人类通常将复杂问题分解成不同粒度层次上的子问题,通过“大范围优先”的认知机制,首先在粗粒度层次上对问题求解,实现对复杂问题的整体把握,再根据问题求解的需要进行逐步的细化,逐步切换到较细粒度上进行更加深入的分析求解,这一过程称为多粒度渐进式分解求解机制。分解求解机制可以将复杂问题转化为简单问题,将抽象问题转化为具体问题,不确定性问题转化为确定性问题。复杂问题转化为简单问题,就是将一个复杂问题表示为多个相对简单问题的组合。抽象问题转化为具体问题,就是将一个问题在高层粒度空间的抽象表示,转化为在低层粒度空间的具体表示。人类的这种“由粗到细”的渐进式认知机制,是一种决策行动分解机制,即将对一个问题的认知行为分解成不同阶段,在每一个阶段都能得到一个相应的认知结果。目前,人类的这种“由粗到细”的渐进式认知机制研究,在许多领域取得了成功。Choi等人设计了一种长文档快速查询的方法,用一个快速的、粗粒度的模型找到查询的相关区域,再使用递归神经网络(RNN)详细分析,得出精确的结果[54]。Fang等人提出了一种融合全局特征和重要局部特征的多粒度框架,处理智能交通系统中车辆识别的问题,通过粗粒度特征上的车辆分类,再从细粒度特征上对车辆进行识别,提高了车辆识别的速度和准确度[55]。Pavlakos等人使用一种“由粗到细”的有监督框架,融合高维数据特征,进行迭代运算,实现单张图片预测三维人体姿态[56]。张凯兵等人提出了一种“由粗到细”的方法对单幅图像进行超分辨率重建[57]。吕健勤等人提出了一种基于粗粒度搜索的人脸对齐框架,对包含不同形状的形状空间进行粗略的搜索,并使用粗粒度结果来约束后续细粒度上的搜索方案,通过渐进式分解和自适应搜索机制,避免了优化中陷入局部最优的情况[58]。Cao等人提出了一种“由粗到细”的潜在指纹匹配算法,平衡了准确性和鲁棒性[59]。邓伟辉和王国胤等提出了一种二维高斯云的时间序列粒化表示方法,将一个复杂的时间序列相似性度量任务分解成若干个“求解一维高斯云相似性”的子任务,实现了计算复杂度低、可理解性强的复杂任务多粒度分解求解[60]。随着人工智能的发展和社会需求的不断提升,机器学习、数据挖掘和知识发现已经从处理单一的、简单的、确定的实际问题转变为处理多元的、复杂的、不确定的问题。因此,如何借鉴人类在观察、分析和求解问题时的“由粗到细”的渐进式分解求解机制,建立满足时限约束条件的逐步细化的渐进式多粒度计算模型,逐渐成为人工智能面对的关键问题。

图6 人类认知机制:“由粗到细”Fig.6 Human cognition: from coarser granularity levels to finer levels
在某些条件的限制下(如时间、经济等),人类往往不能一开始就认识到实际问题的全貌,转而从问题的某个局部出发求解,再根据限制条件的变化继续求解,最终求得全局解。这一“由局部到全局”、“由细到粗”的渐进式问题求解机制,也是人类的一种自然行为模式。例如,在医疗诊断中,医生碰到急诊病人,往往先根据初步的局部检查结果采取应急手段稳定病人病情,然后再对病人进行全面检查,准确判断病情,进一步对症下药。这一求解机制可以保证在限制条件下,得到当前的局部最优解,很大程度上降低了决策代价。生物学上的“非条件反射”、自动化领域的“智能计算前置”和机器学习中的“贪心算法”都是这类“由细到粗”的求解机制。除此之外,如果从相互不依赖的局部开始对问题进行求解,又不会影响彼此的结果,这将使得“并行计算”成为可能,从而更大限度降低决策的时间代价。一些领域的研究工作中已经成功借鉴了“由细到粗”的粒度计算思想。Aluru用智能计算前置的思想,提出了一种适用于序列比较的平行算法,将任务分配到每个处理器上进行计算,降低了空间复杂度[61]。Marcu提出了一种数据驱动的、自下而上的文本处理方法,该方法通过修辞关系的局部一致性约束实现文本的全局一致性[62]。Ferragina提出了一种对字符串前缀编码进行渐进式匹配的预搜索算法,提高了搜索效率[63]。Oh等人提出了一种新的S3D图像质量评估算法,该算法在一个深度卷积神经网络模型中加入一个聚合层,将局部模型训练出的特征自动聚合到全局上,克服了已有方法的局限性[64]。在处理时态数据的异常检测问题中,Benkabou等人提出了一种聚类与检测同时进行的嵌入式方法,对局部聚类实例加权处理后进行异常检测,再将检测结果推广到全局[65]。徐计和王国胤等人提出了一种基于密度峰值聚类的多粒度聚类模型,为用户高效地提供当前有效解,并且提供了一种基于局部密度粒度寻优的算法,该算法的复杂度与数据集的规模呈线性关系,提高了粒度寻优的效率[66-67]。由此可见,通过这种“由局部到全局”、“由细到粗”的渐进式问题求解机制,可以在当前条件的限制下求出问题的可行解,提供决策和指导行为。面对如今快速增长的大数据环境,数据信息是不完备的、动态的,需要在一定时限下做出相应决策,及时提供满足客户需要的有效解。因此,如何借鉴这种“由细到粗”、“由局部到全局”的渐进式问题求解机制,研究满足时限约束条件的多粒度渐进式扩张计算模型,也将成为未来大数据研究的重要发展方向。
解决计算机“由细到粗”信息处理机制与人类“由粗到细”认知机制的矛盾,将是研究新型认知启发的智能计算模型需要解决的一个关键问题。数据驱动的粒认知计算(DGCC)实际上是从数据出发,以人类认知事物的分层(多粒度)机制为基础的计算框架。从认知计算来看,数据是知识的外延,知识是数据的内涵,两者之间是抽象与具象的关系;从粒计算来看,数据是知识在最细粒度上的表现,知识是数据在粗粒度上的描述,两者之间是粒度层次切换的关系,如图7所示。
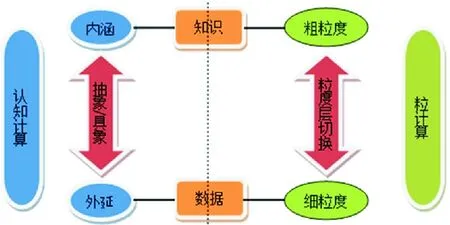
图7 数据与知识在DGCC中的关系Fig.7 The relationship between data and knowledge in DGCC
对事物认知和问题求解,人类具有定性和定量双向推理的能力,特别是对于不确定性信息的处理,人类的逻辑推理比计算机的处理更为灵活和高效。张钹院士指出[68],人类在问题求解中具有天生的知识驱动能力、对不确定性问题的处理优势和对全局整体的感知能力,传统机器学习具有在数据分析处理中的数据驱动能力、高速计算的优势以及对误差的泛化能力,二者结合是未来信息处理的发展趋势。人机系统理论创建者之一的Fitts教授对人和机器内在的优缺点进行详细分析,发现二者的优缺点呈一种互补关系,指出通过融合二者优点可以产生性能更优良的人机系统[69]。潘云鹤院士认为将数据驱动机器学习方法与人类的常识先验与隐式直觉有效结合,可以实现可解释、更鲁棒和更通用的人工智能[70]。郑南宁院士指出由于人类面临的许多问题具有不确定性、脆弱性和开放性,任何智能程度的机器都无法完全取代人类,这就需要将人的作用或人的认知模型引入到人工智能系统中,形成混合-增强智能的形态,这种形态是人工智能或机器智能的可行的、重要的成长模式[71]。早在2000年,Dubois就提出了一种处理数据与知识的双模态逻辑系统[72],并给出了完备性证明,从而实现了模糊逻辑框架下数据驱动与知识驱动的融合。Skowron提出了一种基于感知计算的交互式信息系统,建立了基于交互式粒计算(Interactive granular computing,IRGC)的不完备、不确定信息处理模型[73]。Todorovski提出了一种融合知识驱动和数据驱动的动态系统模型框架,将专家知识转化到对候选模型进行选择[74]。在电力系统检测中,Zhou将部分专家知识与配电网络数据融合,建立了一种新型的事件检测方法,将未标记数据和部分标记数据相结合,弥补了监督学习、半监督学习和学习隐藏结构之间的差距[75]。尽管人类的逻辑推演、抽象化等能力强于计算机,知识驱动能够弥补数据驱动中某些缺陷,但囿于人类的思维定势及心理状况,人类知识往往伴随一定程度的主观性(如模糊),不能全面、客观地反映数据自身所表现出的特征,因此,人机系统还应融合客观反映数据特征的知识。
人机模型中知识与数据共同驱动的认知计算与DGCC中二者的双向认知计算有本质不同。在知识与数据共同驱动的人机模型中,知识来自人类的总结,知识和数据呈现一种平行结构,二者在认知过程中是互补关系。在DGCC中,知识与数据是一种层次结构,从低粒度层次向高粒度层次的变换由数据驱动,而从高粒度层次向低粒度层次的变换由知识驱动(如图8)。
建立数据驱动的粒认知计算模型,实现数据与知识双向驱动和变换,有下述3个方面的科学问题需要研究。

图8 DGCC中知识与数据的双向驱动Fig.8 Bidirectional driven of knowledge and data in DGCC
2.1 多粒度空间的描述问题
2.1.1 数据、信息与知识的多粒度表达 在传统的多粒度认知计算模型中,数据、信息和知识是被区别对待的,数据在最底层,信息在中间层,知识在高层。而在数据驱动的粒认知计算中,将数据作为知识的一种编码格式[75],需要构造一个通用的多粒度结构对数据、信息和知识进行表达,形成一个分层的多粒度空间对三者进行编码。
2.1.2 多粒度空间中的不确定性变换 一般来说,高粒度层上的概念(信息和知识)比低粒度层上的概念(信息和知识)更具有不确定性。在大数据环境下,由于低粒度层是对对象的局部进行描述,在低粒度层数据抽象为高粒度层信息的过程中,通常伴随着不确定性的增长。反之,在从高粒度层向低粒度层变换的问题求解过程中,解的不确定性也可能相应增加。
2.1.3 多粒度信息知识空间的动态演化机制 现实世界的系统往往是动态的。智能信息系统的数据、信息和知识也是动态的。因此,需要研究多粒度知识空间中的动态演化机制来处理动态数据、信息和知识。
2.2 多粒度联合求解问题
2.2.1 多粒度联合计算模型与问题求解机制 数据、信息和知识在同一个多粒度空间中进行编码,可以并行地解决问题。例如,一个公司每天都在不同粒度层上同时作决策。对于不同粒度层上独立或者相互依赖的决策,需要构造多粒度空间联合计算和决策机制。
2.2.2 变粒度有效渐进式计算方法 通常,在高粒度层上花费较小的时间代价能够形成“较粗”的解,而在低粒度层上形成“更精确”的解则要花费较大的时间代价。因此,许多复杂问题可以首先在高粒度层上求出“较粗”的解,再在低粒度层上求出较精确解,这一有效的方法被称为变粒度渐进式计算。
2.2.3 智能计算前置 在一些实际应用中,并不是所有数据在开始时就全部可用,此时,需要根据低粒度层上仅有的部分数据做出初步的局部决策,再根据更多的数据输入,在较高粒度层上形成改善的全局决策。
2.2.4 多粒度分布式机器学习 数据、信息和知识在同一个多粒度空间中进行编码,因此,可以进行并行和分布式的学习,而不需要逐层学习。
2.3 人机认知机制融合问题
2.3.1 人类认知机制与机器信息处理机制的融合 向上算子和向下算子是数据驱动的粒认知计算中的两种基本算子,分别模拟了人类“由粗到细”的认知机制和计算机“由细到粗”的信息处理机制,作为双向认知计算的一种推广,需要设计一种融合双向算子功能、便于多粒度空间层次转换的计算模型。
2.3.2 带遗忘的多粒度联想记忆机制 计算机的信息储存机制是机械的,信息在删除后不能使用。而人脑中存在着遗忘与回忆的机制,可以通过一类双向认知计算模型实现[76]。在数据驱动的多粒度认知计算中,向上算子能够通过信息从低粒度层到高粒度层的转换来模拟人类的遗忘过程,向下算子能够通过信息从高粒度层到低粒度层的转换来模拟人类的联想回忆过程。
3 多粒度认知计算的应用案例分析
3.1 多粒度云模型
不确定性是人类认知过程的一个主要特性。云模型是一种重要的不确定性知识表示模型,它使用了3个参数(期望、熵、超熵)对知识进行描述,融合人类认知过程中随机与模糊这两种不确定性,实现知识内涵与外延的相互转换。相较于概率模型中的高斯混合模型(GMM),云模型的优势在于使用含混度刻画知识的稳定性,使得聚类过程能够仿照人类的认知,生成不同粒度层上的知识,并通过含混度的约束选择统一的、被广泛接受的知识。图9是通过云模型对ArnetMiner平台上988 645位用户年龄数据形成的多粒度概念[47]。可以看出,在第一层上形成的5个概念相互之间重叠严重、含混度高,而在第三层上形成的3个概念重叠少、含混度低,符合人类对年龄概念的认知。

图9 云模型形成的ArnetMiner用户多粒度概念[47]Fig.9 Multi-granularity concept of ArnetMiner users formed by cloud model[47]
3.2 密度峰值多粒度聚类模型
聚类是一种重要的数据粒化手段,层次聚类方法能够充分反映数据的多粒度结构,不同粒度层上的数据聚类能够模仿人类的认知模式,形成不同粒度层上的概念。密度峰值方法是一种高效的聚类算法,它通过计算数据点的局部密度和高密度点间距离的乘积,选择聚类中心点进行聚类。相较于传统聚类算法,该算法的聚类过程不需要进行迭代运算,在线性复杂度下能够实现数据的快速聚类,可以应用在流媒体图像识别、动态网络识别等许多在线学习的场景。此外,它也能对任意形状数据进行层次聚类。图10是对人工数据集5Spiral上的层次聚类结果[48],可以看出,选择不同的“阶跃”点,能够形成不同粒度层上的聚类,并且根据聚类结果能够形成新的数据点,该结果与人工聚类结果基本一致。这一过程对数据的描述本质上是“由细到粗”数据驱动的认知过程,而对知识的表达则是“由粗到细”的知识驱动认知过程。

图10 5Spiral数据集上的密度峰值多粒度聚类[48]Fig.10 DenPEHC on the dataset "5Spiral"[48]
3.3 多粒度三支聚类
三支聚类(three-way clustering)是符合人类不确定性认知的一种聚类方法。它将传统聚类问题中元素与集合的关系拓展为属于、不属于以及不确定三种情况,模仿人类在限制条件(时间、经济等)下,用不确定性聚类结果代替传统的确定性聚类结果的行为,从而提高聚类效率。从DGCC的角度看,三支聚类是一种“由细到粗”的计算方式。随着网络信息技术的发展,各行各业产生的海量高维复杂数据越来越多,属性维度的上升导致计算量呈现指数级增长,于洪等人提出了面向高维数据的动态随机投影三支聚类模型[77]。它利用动态高斯随机投影方法,将原始数据集投影到多个不同粒度子空间中进行三支聚类,再将各粒度层的聚类结果进行汇总,得到全局聚类。由于不同粒度空间中,高斯随机投影的数据聚类与全局数据聚类的误差不同,多粒度动态投影三支聚类有效地平衡不同子空间的聚类结果与聚类时间。
3.4 基于大数据的流程工业知识自动化
在工业流程管控中,企业的各级管理层时刻都要面对不同的决策问题。面对工业流程中的大量数据,各级管理者往往根据个人经验做出决策,这不仅忽视了流程中的全局信息,也使得决策过分依赖个人经验,缺乏统一标准。通过多粒度知识表达模型构建流程工业知识的多粒度结构和动态演化模型,利用多源、深度信息构建多粒度联合决策模型,可以实现不同粒度层次的协同决策,完成流程工业知识的自动化(图11)。例如,在工业电解铝过程控制中,对工业大数据的属性进行不同粒度层的约简,通过粒度寻优方法找出最优粒度层属性[78]。

图11 基于大数据的流程工业知识自动化Fig.11 Big Data-based fluid process industries knowledge automation
3.5 水质检测数据的智能预测
水质检测是衡量水资源质量的一项重要方法。依据水质检测数据预测水质变化趋势是与人类生活休戚相关的一项工程。目前,水质检测的关键数据是来自于陆、水、空等多方位检测平台,因此,水质预测是一个跨领域、多层次的系统工程。基于水质检测大数据,严胡勇等人提出多维云粗糙集混合模型对数据进行多粒度建模和预测[79]。该方法能够降低数据规模,提取定性规则,定量分析水体富营养化的平均值、均匀性和稳定性,相较于其他方法,该模型在对云贵高原湖泊富营养化的预测中获得了更准确的预测结果(图12),是水富营养化信息系统的一个很有前景的替代方案,为公用事业管理部门和操作人员提供了水质富营养化的一个定量预测方法。

图12 云贵高原湖泊营养状态云图[79]Fig.12 Nutrient status of lake in Yunnan-Guizhou plateau[79]
3.6 多粒度模糊时间序列预测
时间序列预测是一种基于历史观测数据时序统计的规律,对事物发展趋势做出预测判断的方法。在股票市场预测、天气预报和交通流量预测等领域有着广泛的运用。相较于传统时间预测模型,模糊时间预测模型能够更加方便地处理内涵模糊以及不完整数据,适应性更强。结合多粒度联合求解机制的模糊时间序列预测[80],首先通过自动聚类算法在数据的主因子和其他次要因子上形成不同长度的聚类区间,然后针对每个因子,采用模糊趋势逻辑关系类(FTLRG)构建模糊趋势矩阵预测每个粒度层上的模糊趋势。最后,使用粒子群优化(PSO)算法将每个粒度层上的趋势预测结果进行整合,得到数据的全局趋势预测。它能够在不确定性问题中得到高精度的预测结果。如图13,用多粒度模糊时间序列分别对1991年至1999年间的台湾加权股价指数(TAIEX)进行预测,其结果在目前流行的时间序列预测方法中均方根误差(RMSE)最小,最为合理。

图13 不同时间序列模型对1991年至1999年间TAIEX预测结果的RMSE比较[80]Fig.13 Comparison of the average RMSEs for different models for forecasting TAIEX from 1991 to 1999[80]
4 结 论
模仿人类的认知机制,构造智能计算模型是人工智能研究的重要方法。本文介绍了一种基于人类认知机制的知识与数据双向驱动的多粒度计算模型——数据驱动的粒认知计算模型(DGCC),将两种相互矛盾的认知机制,即“大范围优先”的人类认知机制和数据驱动的“由细到粗”的计算机信息处理机制相结合。并从3个方面分析讨论了数据与知识双向驱动、双向变换的9个科学问题。从实际应用案例分析中可以看到,对于多粒度空间描述(3.1~3.3)和联合求解(3.4~3.6)方面已经有一些较为成熟的研究结果,但对于人机认知机制结合方面仍有待进一步研究。人类认知除了具有多粒度认知机制外,还具有复杂信息转化、经验学习、概念化、直觉、联想记忆等特点,如何使智能系统具备和人类相似的认知行为能力,将是未来人工智能发展的方向。知识与数据双向驱动的多粒度认知计算为大数据的知识发现研究提供了一个有效的粒认知计算框架,目前已经应用在一些实际生活问题中,如聚类、图像处理、时间序列预测等。本文所讨论的知识与数据双向驱动的多粒度认知计算模型将有助于研究者提出新的大数据智能计算模型与系统。
猜你喜欢
汽车实用技术(2022年7期)2022-04-20
粉末冶金技术(2021年3期)2021-07-28
房地产导刊(2020年11期)2020-12-28
小型微型计算机系统(2020年10期)2020-10-21
铁道通信信号(2019年4期)2019-10-10
铁道通信信号(2019年6期)2019-10-08
制造技术与机床(2019年7期)2019-07-22
雷达学报(2017年6期)2017-03-26
浙江大学学报(工学版)(2016年11期)2016-06-05
互联网天地(2016年1期)2016-05-04
