
基于大数据学习分析的在线学习风险预测研究*
2018-09-04 07:58李建伟苏占玖黄赟茹
现代教育技术 2018年8期
李建伟 苏占玖 黄赟茹
基于大数据学习分析的在线学习风险预测研究*
李建伟 苏占玖 黄赟茹
(北京邮电大学 网络教育学院,北京 100088)
近年来大数据技术在全球各领域成为研究热点,越来越多的教育研究者将大数据分析方法应用到在线学习中,并且力图科学有效地分析学习过程中出现的问题。文章对国内外大数据学习分析的研究现状进行了分析,提出研究问题:如何在课程学习的过程中预测学生期末成绩不及格的风险。文章对比了四种研究二分类问题的机器学习算法,并使用真实的抽样数据对算法的性能进行了评估,最终选择了逻辑回归算法。然后,文章设计了在线学习风险预测框架,并使用北京邮电大学网络教育学院的真实学生数据,通过训练得出了学习风险预测模型。最后,文章使用真实数据对模型的准确率进行了验证,结果表明,模型能够以接近80%的正确率预测学生是否存在期末成绩不及格的学习风险,这种准确率已经达到大规模推广使用的要求,可为进一步研究个性化的学习干预打下基础。
大数据;学习分析;机器学习;风险预测
引言
近年来,大数据技术不断深入到各个领域,让许多行业都发生了改变,也让我们更加了解到数据的深层意义。美国新媒体联盟(The New Media Consortium,NMC)与北京师范大学智慧学习研究院合作的《2016 新媒体联盟中国基础教育技术展望:地平线项目区域报告》指出,大数据学习分析技术将在未来两至三年成为极具影响力的教育技术,并表明有效运用学习分析技术可以设计更好的教学活动,让学生积极主动地参与学习,准确定位处于危险中的学生群体,评估预测影响学生成功的因素[1]。
在线学习学生数量众多,学习过程行为复杂,突破了传统教学的时间、空间限制,而传统方式教师只能通过作业成绩、考试成绩等结果来评判学生,而对于学生在学习过程中的其它行为并不了解,不能及时对学生进行全面的评价。利用大数据分析方法可以对学生的在线学习数据进行全面地收集、测量和分析,理解与优化教学过程及其情境,为教学决策、学业预警提供支持,真正实现个性化学习,提高教学效果,这是大数据学习分析在教育领域的价值所在[2]。本研究在大数据分析的技术背景下,以北京邮电大学网络教育学院的真实学生数据为例,将大数据分析方法应用于在线学习结果预测中,以提高教学效果。
一 大数据分析国内外研究现状
自学习分析的概念提出后,国内外研究者就不断关注大数据学习分析,目前国内外利用大数据进行学习行为分析的研究主要包括三个方面:①用工具软件追踪和记录学习行为;②关注学习者需求和在线学习环境;③寻找学习行为和学习绩效的关系。
1 国外研究现状
国外在线学习分析研究致力于分析学生本身的数据以及在学习过程中产生的数据,激发学生的学习兴趣,优化学生的学习效率,从而改善学生的学习环境。2005年,美国佐治亚州大学的研究人员对高中学生的GPA(Grade Point Average)和SAT(Suite of Assessments)数学成绩通过判别式分析,对他们的在线通识教育课程的完成情况进行预测[3]。Campbell[4]利用因子分析和逻辑回归分析方法,对课程管理系统中的数据和学生人口统计信息数据进行分析,研究出一个能预测学生学习结果的预测模型。Romero等[5]利用数据挖掘技术,在Moodle平台上进行分类、聚类和关联规则挖掘研究。近年来,Agapito等[6]利用C4.5决策树规则,对在线学习系统中的学习不佳表现进行判别分析。2007年,普渡大学提出了通过学生的素质评价和在线学习行为数据对学生的成绩进行预测的预测模型,并在实际使用中取得了非常好的效果[7]。马利斯特学院的Sandeep[8]在2012年对普渡大学的预测模型进行了扩展研究,提出了OAAI(Open Academic Analytics Initiative)预测模型,并利用大数据分析方法对学习数据处理,进一步提升了预测的精准度。Retalis[9]设计的CoSyLMSAnalytics分析工具可以通过学生的学习行为和习惯预测学生的学习特征和规律,并根据预测结果为学习者推荐学习路线。
2 国内研究现状
武法提等[10]提出了基于学习者个性行为分析的学习结果预测框架,包括学习内容分析、学习行为分析和学习预测分析三个模块,为后面个性化学习分析工具的设计提供理论指导。李彤彤等[11]构建了基于教育大数据和学习分析的、以干预引擎为核心的“状态识别—策略匹配—干预实施—成效分析”四环节循环结构干预模型,并针对这四方面的状态水平设计了具体的干预策略、干预时机以及干预方式。赵慧琼[12]等利用多元回归分析法判定影响学生学习绩效的预警因素,在此基础上构建了干预模型,将其应用于教学实践中。
二 研究的问题与相关算法研究
本研究聚焦的问题是在某门课程的学习过程中,预测哪些学生存在期末总评成绩不及格的风险,因此关注的是一个二分类问题。基于实际情况,本研究选择了四种比较常见的分类算法进行对比:逻辑回归、支持向量机(SVM/SMO)、J48决策树和贝叶斯。
对机器学习中二分类训练模型的预测性能评估,通常会使用一些参数:真正类(True Positive,TP)、假正类(False Positive,FP)、真负类(True Negative,TN)、假负类(False Negative,FN)。单纯地用准确率或错误率来判断一个模型的表现好坏是不准确的,不能反映模型的能力,还要关注其它度量标准。如精确度(Precision),公式为P=TP/(TP+FP),反映了被分类算法判定的正例中真正的正例样本的比重;准确率(Accuracy),公式为A=(TP+TN)/(P+N)=(TP+TN)/(TP+ FN+FP+TN),反映了分类算法对整个样本的判定能力,能将正的判定为正,负的判定为负;召回率(Recall),公式为R=TP/(TP+FN),反映了被分类算法正确判定的正例占总的正例的比重;误报率(FP Rate),公式为FP Rate=1-TN/(TN+FP),反映了被分类算法错误判定的负例占总的负例的比重[8]。
四种分类算法分别使用本次实验的25%、50%、75%、100%四种大小的样本数据以及原始训练集进行实验,通过对每个算法的准确率、误报率、精确度和召回率进行统计,得出如表1所示的算法性能比较数据。通过对表1中原始数据的机器学习结果和抽样后平衡数据的机器学习结果进行比较,本研究发现精确度和召回率有大幅度的提升,且抽样后的平衡数据相比于不平衡的原始数据训练出来的模型精确度更高、效果更好。
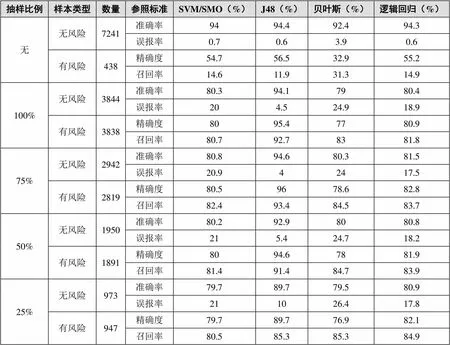
表1 算法性能比较
逻辑回归、贝叶斯和SVM/SMO在数据集总量变化时,表现稳定,指标变化很平缓;J48算法随着样本的变小,准确率下降,误报率上升,表现不够稳定,所以首先排除J48算法。另外,所有分类算法使用平衡数据集实验后的召回率都很高,几乎都超过80%,比原始不平衡数据经过实验后的比率有明显提升,但是误报率较原始不平衡数据集试验后的结果都有所上升。因此,通过重采样产生的平衡数据集有助于分类器对有风险学生的预测,但增加了对无风险学生的错误预测,在实际操作过程中,很可能将一部分无风险的学生错误地预测为有风险。
通过对四种学习算法的数据进行比较,可知:总体而言,逻辑回归优于其它算法,它具有较好的稳定性和高召回率、低误报率。因此,本实验选择逻辑回归算法来进行风险预测建模。
三 学习风险预测框架设计
基于对已有研究的综合分析,本研究提出了学习风险预测框架,如图1所示。学习风险预测框架包括数据清洗、训练模型和预测应用三个阶段:①数据清洗阶段需要对数据源进行选取。数据源包含学生的基本信息和学习行为信息,通过对数据源中的数据进行选取后提取,接着进行数据清洗,将缺失值、异常数据等进行处理,最后将输入数据分为训练数据和测试数据两种。②训练模型阶段首先将数据重抽样,使数据类型平衡,再使用机器学习算法进行训练,将得到的模型使用测试数据测试,不断地调整模型的性能,直到最终完成模型。③在预测应用阶段,对学生一段时间内的学习过程进行监控,将学生的学习数据利用模型进行预测,得到预测结果。
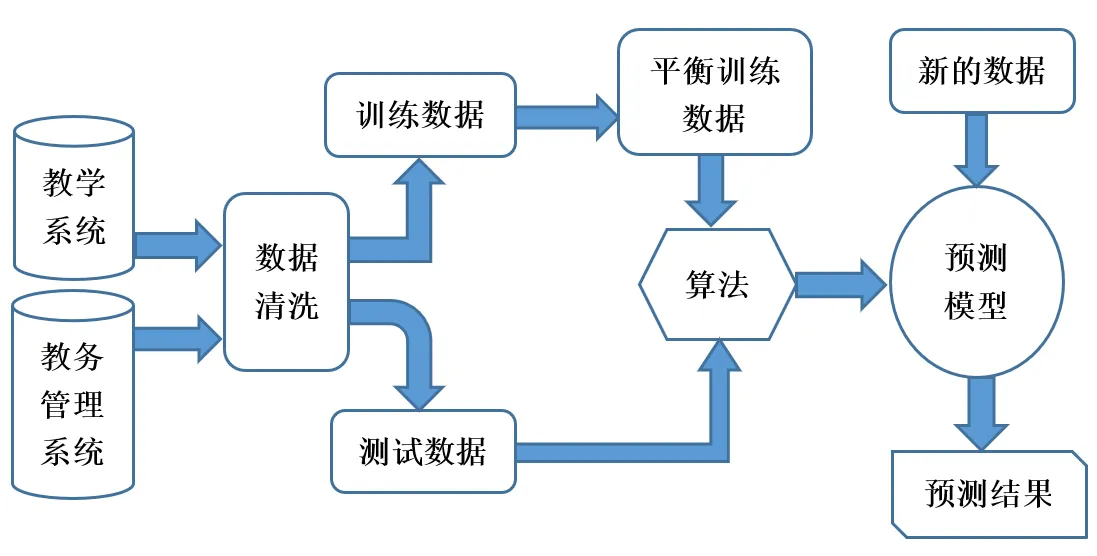
图1 学习风险预测框架
四 学习风险预测模型构建及预测效果分析
北京邮电大学网络教育学院有在读学生5万名左右,学生在学院提供的教务与教学系统上进行自主学习,并可在该系统中进行学习内容的阅读观看,完成线上测试,下载学习资料,提交作业,参加教师发起的实时远程教学答疑辅导,以及和老师、同学讨论问题。学生的期末考试均为线下考试,最终的总评成绩在教务管理系统中可以查看。
学生的数据被分为学习行为数据和综合信息数据。其中,学习行为数据包括课程学习时长、参加实时答疑次数、章测试成绩、作业成绩、论坛发帖次数等;综合信息数据则包括学生ID、课程ID、生源地、类别、入学成绩、所有已完成课程的平均成绩等。本实验选取2016年秋季学期7679个学习“数字通信原理”课程的学生数据进行实验,学生特征属性值比较如表2所示。
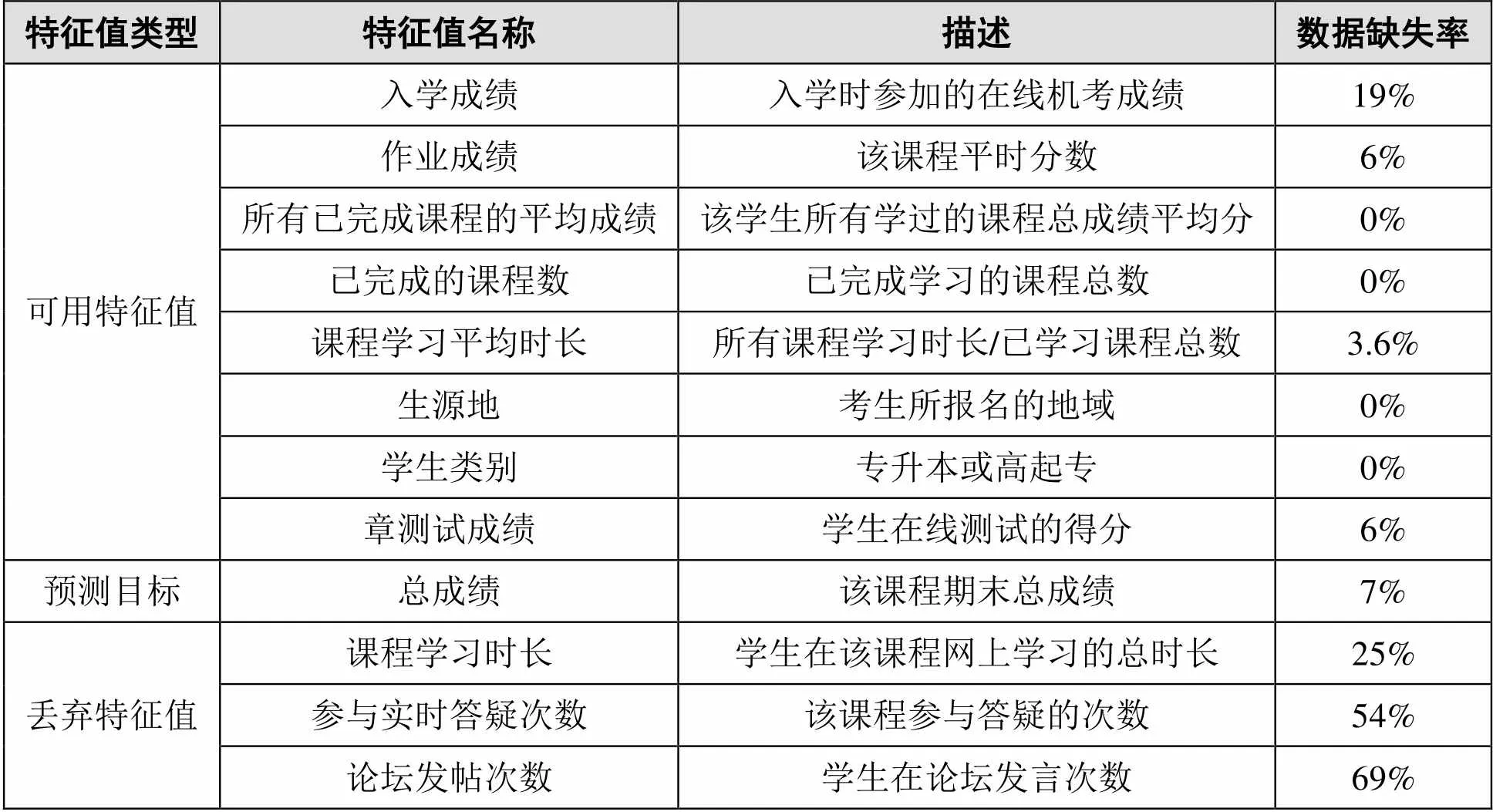
表2 学生特征属性值比较
1 学生特征属性值的选取原则
数据分析算法的好坏受到输入数据的质量影响。如果数据质量很低,即使算法比较智能,也不能产生准确的模型。在提取系统数据时,发现有一些属性的数据存在不同程度的缺失。使用20%设定为缺失数据的阀值,将丢失数据超过20%的属性进行丢弃,对于包含缺失数据的其余属性(未超过20%)进行保留。
课程学习时长、参加实时答疑次数、和论坛发帖次数三个特征值,因为学生使用的人数不足80%而被丢弃。根据调研,造成这种数据缺失结果有两个原因:一是成人教育的特点是学生的年龄范围覆盖广,学生的背景情况比较复杂,学生的自我约束力也比较差,导致参与课程在线学习的人数和频率不高;二是教学模式采用自主学习,对学生只有作业提交的强制要求,其它学习活动不是必须和强制的环节,导致学生参与率不高。如每个学期每门课程都会安排2~3次实时答疑辅导课程,但是由于没有强制要求学生必须参与,很多学生都放弃了与老师面对面交流的机会。
2 处理不平衡的数据分类
由于选取的真实数据中及格同学与不及格同学的比例相差过大——及格同学有7241个、不及格的同学有438个,导致类别不平衡,这会导致没有办法提供更多区别及格与不及格学生的信息。因此,本研究通过对训练数据集使用分层抽样的方法,平衡两种类别数据的比例,来提高预测模型在预测过程中的性能。对数据进行抽样,具体包括对类别占优的数据(及格同学数据)进行子抽样、对类别劣势的数据(不及格同学数据)进行重抽样。子抽样的过程为对及格同学的数据进行随机抽样,抽样后的样本比原先及格同学的样本少;重抽样的过程则利用 SMOTE采样方法[8],对不及格同学的数据进行采样。本实验将通过采样,分别创建训练数据的 25%、50%、75%、100%四种大小的样本数据来进行实验。
3 构建学习风险预测模型
本实验使用Weka 3.6.11版工具进行数据分析。Weka是一种Java语言编写的数据挖掘机器学习软件,是在GNU协议下分发的开源软件。它是一套完整的数据处理工具、学习算法和评价方法,包含数据可视化的图形用户界面,同时该环境还可以比较和评估不同的学习算法性能。选择75%重采样的数据集进行逻辑回归的建模,最终得到拟合方程式:
Logit(P)=-23.597+GPA_CUMULATIVE(所有已完成课程的平均成绩)×0.214+COURSECOUNT(已完成的课程数)×0.197+AREA(生源地)×0.154+STYTYPR(学生类别)×0.123+ONLINETIME(课程学习平均时长)×0.038+GB_SCORE(作业成绩)×0.014+BASESCORE(章测试成绩)×0.006+APITITUDE_SCORE(入学成绩)×0.001。
4 预测变量重要性分析
通常,建模工作需要专注于最重要的预测变量字段,并考虑删除或忽略那些最不重要的变量。IBM SPSS Modeler 16.0版工具可以帮助实现这一点,它在模型估计中可以计算出每个预测变量的相对重要性。预测变量的重要性与模型精确性无关,它只与每个预测变量在预测中的重要性有关,而不涉及预测是否精确。
使用IBM的SPSS工具对本次实验预测变量的重要性进行排序,得到的结果是:在所有的预测变量中,“已完成课程的平均成绩”的相关性最高,接下来依次是“作业成绩”、“已完成的课程数”、“生源地”、“学生类别”、“课程学习平均时长”、“章测试成绩”和“入学成绩”。
5 预测效果分析
最后,本研究利用一组测试数据对学习风险预测模型进行验证。这组测试数据共有学习信息数据291条,其中40个学生为有风险,251个学生为没有风险。随后,本研究将学生的学习信息带入模型后进行计算评判。
最终,结果为有风险的同学中,有10位同学被判定为无风险(FN=10),30位同学被判定为有风险(TP=30);无风险的同学中,有50位同学被判定为有风险(FP=50),201位学生判定为无风险(TN=201)。根据算法性能评估参数中准确率(Accuracy),公式为A=(TP+TN)/(P+N) = (TP+TN)/(TP+FN+FP+TN),计算得出模型的预测准确率为79.38%,即模型能够以接近80%的正确率,预测某门课程学习过程中的学生是否存在期末总评成绩不及格的学习风险。
五 结论
本研究对国内外相关的学习分析案例进行调研,探讨了如何利用大数据分析方法对在线学习展开分析;选取了四种适合分类问题解决的机器学习算法进行对比分析,并利用真实数据对学习算法的性能进行了评估;提出了基于学习分析的在线学习风险预测框架,并利用网络教育学院的教学平台和教务系统的真实数据,选取了影响在线学习结果的特征属性,构建了在线学习风险预测模型;最后,利用真实数据对模型进行了验证,得出模型能够以接近80%准确率预测学生学习结果的结论。下一步研究将根据在线学习风险预测的结果,一方面帮助教师全面了解教学中的问题,及时调整教学策略和内容,改善教学效果,为学生提供个性化的学习帮助;另一方面用雷达图等可视化的工具为学生提供全面的学习分析,帮助学生在学习过程中及时发现自己的不足,降低期末成绩不及格的风险。
[1]Johnson L, Liu D, Huang R, et al. NMC technology outlook for Chinese K-12 education: A horizon project regional report[R]. Austin, Texas: The New Media Consortium, 2016:26-27.
[2]赵慧琼,姜强,赵蔚,等.基于大数据学习分析的在线学习绩效预警因素及干预对策的实证研究[J].电化教育研究,2017,(1): 62-69.
[3]Libby V M, Shyan W, Catherine L F. Predicting retention in online general education courses[J]. American Journal of Distance Education, 2005,(1):23-36.
[4]Campbell J P. Utilizing student data within the course management system to determine undergraduate student academic success: An exploratory study[D]. United States of America: Purdue University, 2007:31-36.
[5]Romero C, Ventura S, Garcia E. Data mining in course management systems: Moodle case study and tutorial[J]. Computers & Education, 2008,(1):368-384.
[6]Javier B. Detecting symptoms of low performance using production rules[A].EDM’09 Group.The 2nd international conference on education data mining[C]. Spain:International Working Group on Educational Data Mining, 2009:31-40.
[7]José A, Ruipérez V. An architecture for extending the learning analytics support in the Khan Academy framework[A].ACM Group.The first international conference on technological ecosystem for enhancing multiculturality[C].Spain:International Conference on Technological Ecosystem for Enhancing Multiculturality, 2013:277-284.
[8]Sandeep M J. Early alert of academically at-risk students: An open source analytics initiative[J]. Journal of Learning Analytics, 2014,(1):6-47.
[9]Retalis S. Towards networked learning analytics——A concept and a tool[A]. Networked Learning 2006 Group.The fifth international conference on networked learning[C]. United Kingdom: Networked Learning 2006 Press, 2006:1-8.
[10]武法提,牟智佳.基于学习者个性行为分析的学习结果预测框架设计研究[J].中国电化教育,2016,(1):41-48.
[11]李彤彤,黄洛颖,邹蕊,等.基于教育大数据的学习干预模型构建[J].中国电化教育,2016,(6):16-20.
Research of Online Learning Risk Prediction based on Big Data Learning Analysis
LI Jian-wei SU Zhan-jiu HUANG Yun-ru
In recent years, big data technology has become a worldwide research hotspot in all fields. More and more educators have applied big data analysis methods to online learning, and try to more scientifically and effectively analyze the problems in the learning process. This article first analyzed the current situation of domestic and foreign big data learning and analysis research, and then put forward the research focus—How to predict the risk of failing students' final grades in the course learning process? To this end, this article selected and compared four machine-learning algorithms for dichotomous problems and evaluated the performance of the algorithm using real sample data. After that, the logistic regression algorithm was chosen and applied in our present study. Meanwhile, an online learning risk prediction framework was developed and using the real student data from the Network Education Institute of Beijing University of Posts and Telecommunications, the learning risk prediction model was obtained through training. Finally, the real data was used to verify the accuracy of the model. The results showed that the model had a rate of nearly 80% accuracy on predicting the risk of students’ final exam failure. Such accuracy has reached the requirement of large-scale application, laying the foundation of further research on personalized learning interventions.
big data; learning analysis; machine learning; risk prediction
G40-057
A
1009—8097(2018)08—0078—07
10.3969/j.issn.1009-8097.2018.08.012
本文受2015年北京邮电大学院级项目“基于大数据分析的学生在线学习评价研究”(项目编号:2015WY003)和网络系统与网络文化北京市重点实验室资助
李建伟,讲师,硕士,研究方向为学习分析和网络教学系统,邮箱为jwli321@126.com。
2018年3月23日
编辑:小西
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
民用飞机设计与研究(2020年4期)2021-01-21
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
电子制作(2018年18期)2018-11-14
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
山东工业技术(2016年15期)2016-12-01
